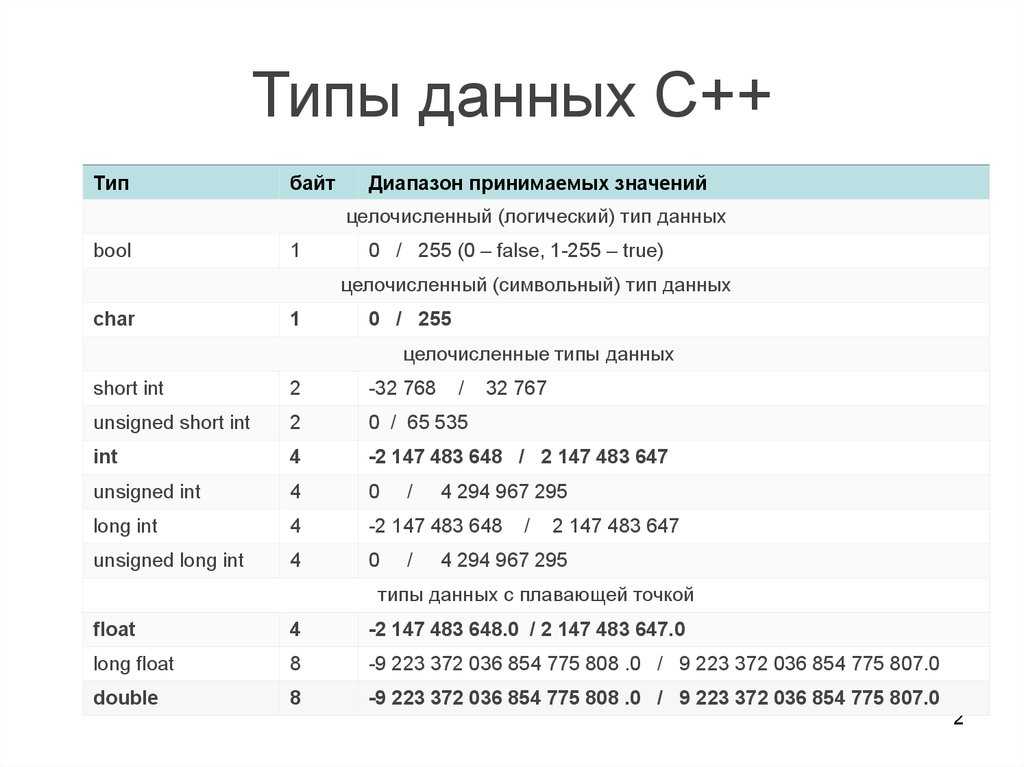
Числовые типы данных
Числа могут храниться в целом и десятичном форматах, а также в формате с плавающей запятой. Особенностью десятичных чисел является то, что они хранятся в целочисленном виде с указанием точного количества цифр после запятой. Числа с плавающей запятой вычисляются приблизительно, с той или иной точностью.
Целые числа
В представленной ниже таблице перечислены целочисленные типы данных и
соответствующие им диапазоны значений. Числа, выходящие за пределы
диапазона, преобразуются в минимальное или максимальное допустимое
значение.
| Тип | Знаковый диапазон |
Беззнаковый диапазон (Только в в MySQL) |
| TINYINT [(M)] | -27
÷ 27-1 (MySQL) 0 ÷ 2 |
0 ÷ 28-1 |
| SMALLINT[(M)] | -215 ÷ 215-1 | 0 ÷ 216-1 |
| INT[(M)] | -231 ÷ 231-1 | 0 ÷ 233-1 |
| BIGINT[(M)] | -263 ÷ 263-1 | 0 ÷ 264-1 |
Синтаксис спецификации целочисленного типа таков:
col_type ([M]) [UNSIGNED] [ZEROFILL] (Атрибуты UNSIGNED, ZEROFILL поддерживаются только в MySQL)
Как минимум, нужно указать имя типа.
Атрибут UNSIGNED обозначает беззнаковое число и исключает появление отрицательных величин. Начальным значением для такого типа будет значение 0.
Атрибут ZEROFILL говорит о том, что в случае необходимости число должно быть дополнено ведущими нулями до нужной размерности. Например, для столбца, объявленного как INT(5) ZEROFILL, величина 4 извлекается как 00004.
Числа с плавающей запятой
Числа с плавающей запятой представляют собой приблизительные значения.
Они подходят для столбцов, где хранятся дробные величины или числа,
выходящие за пределы самого крупного целочисленного диапазона (BIGINT).
Имеются два типа чисел с плавающей запятой: числа одинарной точности
(FLOAT) и числа двойной точности (DOUBLE PRECISION, REAL).
Синтаксис спецификации типа с плавающей запятой таков:
col_type ([M]) [ZEROFILL] (Атрибут ZEROFILL поддерживаются только в MySQL)
Значение параметра M (размерность) должно лежать в пределах от 1 до 53. Значением по умолчанию является 53.
Десятичные числа
Десятичные числа имеют фиксированное количество цифр после запятой. Эти
цифры вычисляются точно, в отличие от чисел с плавающей запятой и в
действительности значения данного типа хранятся в виде строк и при этом
для каждого десятичного знака используется один символ.
Синтаксис спецификации для десятичного типа таков:
DECIMAL[(M[,D])] NUMERIC [(M[,D])]
Атрибут M определяет размерность, а атрибут D — точность (количество
цифр после запятой). Если атрибут D равен 0, величины будут
представлены без десятичного знака, т.е. без дробной части.
Максимальное значение атрибута М равно 65.
Сопоставление типов данных Oracle с PostgreSQL / Хабр
the_unbridled_gooseOracle *PostgreSQL *
Перевод
Автор оригинала: David Rader
Один из самых первых и распространенных вопросов в процессе миграции базы данных с Oracle на PostgreSQL — «Как типы данных Oracle сопоставимы с типами PostgreSQL?».
 В состав встроенных типов входят JSON, массивы, UUID, IP-адреса, геометрические типы, перечисления и многое другое.
В состав встроенных типов входят JSON, массивы, UUID, IP-адреса, геометрические типы, перечисления и многое другое.| Тип данных Oracle | Тип данных PostgreSQL | Комментарии |
|---|---|---|
| Char() | Char() | |
| Char(1) | Char(1) | Если используется в качестве булевого флага, то лучше использовать тип данных boolean |
| Varchar2() | Varchar() | |
| Timestamp | Timestamptz | Вообще, мы рекомендуем хранить timestamp в качестве timestamp с часовым поясом (timestamptz), что эквивалентно timestamp Oracle с местным часовым поясом. Таким образом сохраняются все значения в UTC, даже если сервер или клиент базы данных находятся в разных часовых поясах, что позволяет избежать множества проблем. Но, возможно, какой-то код приложения должен использовать типы, имеющие информацию о часовом поясе — если это важный момент, используйте timestamp без часового пояса, чтобы минимизировать изменения миграции. |
| Date | Timestamptz | PostgreSQL тип “Date” хранит только дату и не хранит время |
| Date | Date | |
| Number() | Numeric() | |
| Number(5,0) | Integer | Integer и Bigint работают лучше, чем Number (), когда используются для joinов больших таблиц, поэтому предпочтительнее сопоставление с Int для полей первичного и внешнего ключей, обычно используемых для joinов. |
| Number(10,0) | Bigint | |
| Number( ,2) | Numeric( ,2) | PostgreSQL Numeric (, 2) идеально подходит для денежных типов, поскольку он обладает конкретной точностью (если вы не имеете дело с йеной и не нуждаетесь в типе (, 0)). Тип «money» эквивалентен типу numeric по точности, но иногда вызывает неожиданности для приложений из-за неявных предположений о форматировании. Никогда не используйте представление с плавающей запятой (float / double) из-за потенциального округления во время арифметики. Тип «money» эквивалентен типу numeric по точности, но иногда вызывает неожиданности для приложений из-за неявных предположений о форматировании. Никогда не используйте представление с плавающей запятой (float / double) из-за потенциального округления во время арифметики. |
| CLOB | Text | Text намного проще в использовании, без функций LOB, просто рассматривайте его как символьное поле. Может хранить до 1 ГБ текста. |
| Long | Text | |
| BLOB | Bytea | |
| Long raw | ||
| Raw | ||
| XMLTYPE | XML | |
| UROWID | OID | Использование OID в Postgres не эквивалентно и не обеспечивает такое же преимущество в производительности, что и ROWID, используемое в Oracle. |
Теги:
- comparison
- data type
- oracle
- postgresql
Хабы:
- Oracle
- PostgreSQL
Числовые данные: Типы и характеристики
Числовые данные: Типы и характеристики — Voxco перейти к содержанию+13236381128
+1519
+61480040096
Book a Demo
TRY A SAMPLE SURVEY
+13236381128
+1519
+61480040096
- Book demo
- Watch demo
- Pricing
- Contact
- Наши клиенты
- Истории клиентов
- Информационные бюллетени
- Ресурсы
Улучшайте процесс принятия решений, собирая данные о клиентах.
ПОДЕЛИТЕСЬ СТАТЬЕЙ ПО
Содержание
Численные данные помогут вам оценить степень удовлетворенности клиентов и впечатления от вашего бренда, продуктов, услуг и других аспектов бизнеса в цифрах, которые легко анализировать. Давайте углубимся, чтобы понять, как числовые данные полезны в исследованиях для ускорения принятия бизнес-решений.
Что такое числовые данные?
Числовые данные относятся к данным в форме чисел, а не в какой-либо языковой или описательной форме. Часто называемые количественными данными, числовые данные собираются в числовой форме и отличаются от любой формы числовых типов данных из-за их способности быть статистически и арифметически рассчитанными.
Пример : У вас есть общее количество ваших сотрудников. Вы берете количество сотрудников-мужчин и вычитаете это из общего числа сотрудников, чтобы получить количество сотрудников-женщин. Эта характеристика числовых данных, подлежащих арифметической обработке, делает их наиболее подходящими для статистического анализа данных.
Изучите все типы вопросов опроса, возможные на Voxco
Типы числовых данных
Вы увидите две формы числовых данных: дискретные данные и непрерывные данные. Оба эти варианта явно используются в статистических и исследовательских целях, и доказано, что они дают наилучшие данные с помощью методов исследования.
Давайте подробнее рассмотрим, чем они отличаются друг от друга:
- Дискретные данные
Дискретные данные используются для представления исчисляемых элементов. Он может принимать как числовые, так и категориальные формы и группировать их в список. Этот список также может быть конечным или бесконечным.
Дискретные данные обычно содержат исчисляемые числа, такие как 1, 2, 3, 4, 5 и т. д. В случае бесконечности эти числа будут продолжаться.
Пример : подсчет кубиков сахара из банки имеет конечную счетность. Но считать кубики сахара со всего мира бесконечно.
- Непрерывные данные
Как следует из названия, эта форма содержит данные в виде интервалов. Или, проще говоря, диапазоны. Непрерывные числовые данные представляют собой измерения, и их интервалы падают на числовую прямую. Следовательно, он не включает в себя подсчет предметов.
Или, проще говоря, диапазоны. Непрерывные числовые данные представляют собой измерения, и их интервалы падают на числовую прямую. Следовательно, он не включает в себя подсчет предметов.
Пример: на школьном экзамене учащиеся, набравшие 80%-100%, получают отличие, 60%-80% имеют первый класс и менее 60% — второй класс.
Непрерывные данные далее делятся на две категории: Интервал и Отношение.
- Интервальные данные – тип интервальных данных относится к данным, которые могут быть измерены только по шкале на равном расстоянии друг от друга. Числовые значения в этом типе данных могут подвергаться только операциям сложения и вычитания. Пример: температура тела может быть измерена в градусах Цельсия и Фаренгейта, и ни один из них не может быть 0.
- Данные отношения – в отличие от интервальных данных, данные отношения имеют нулевую точку. Будучи похожими на интервальные данные, единственное их отличие — нулевая точка.
 Пример: в температуре тела температура нулевой точки может быть измерена в Кельвинах.
Пример: в температуре тела температура нулевой точки может быть измерена в Кельвинах.
Переменные числовых данных
Числовая переменная — это то, что запрещает любое конечное или бесконечное значение. Подобно длине, возрасту, весу, экзаменационным баллам и т. д. числовые переменные можно назвать непрерывными переменными, если они имеют характеристики непрерывных данных.
- Интервальные переменные
Он имеет значения с интерпретируемыми различиями, но никогда не равен нулю. Эти значения можно складывать или вычитать, но нельзя умножать или делить. Интервальные переменные имеют стандартную разницу между ними и являются расширением порядковых переменных.
Интервальные переменные имеют два распределения: нормальное распределение и ненормальное распределение.
Говорят, что случайная величина, имеющая действительное значение, имеет нормальное распределение, если ее распределение неизвестно. Два разных теста проводятся на двух разных образцах, таких как;
Два разных теста проводятся на двух разных образцах, таких как;
Говорят, что случайная величина, имеющая действительное значение, имеет нормальное распределение, если ее распределение известно. Два разных теста проводятся на двух разных образцах, таких как;
- Тесты совпадающих выборок
- Критерий суммы рангов Уилкоксона: для сравнения двух групп совпадающих выборок.
- Двухфакторный дисперсионный анализ Фридмана: для сравнения различий в средних значениях для 3 или более групп.
- Критерии несовпадающих выборок
- Критерий суммы рангов Вилкоксона: когда требования к t-тесту двух несовпадающих выборок не выполняются.
- Критерий Крускала-Уоллиса: чтобы определить, начинаются ли три или более групп несовпадающих выборок с одного и того же распределения.
- Тесты совпадающих выборок
- Переменная отношения
Это расширение интервальной переменной, но разница в том, что она имеет истинное нулевое значение. Эти переменные могут подвергаться любой операции, такой как сложение, вычитание, умножение, а также деление.
Эти переменные могут подвергаться любой операции, такой как сложение, вычитание, умножение, а также деление.
Говоря о тестах, которые выполняются для переменных отношения, ссылайтесь на тесты интервальных переменных, поскольку они одинаковы.
Начните раскрывать высококачественные идеи прямо сейчас!
Анализ числовых данных
Существует два способа интерпретации данных, собранных в числовом виде. В зависимости от ваших данных и результатов, вы можете использовать следующие методы:
- Описательная статистика — наборы данных используются для описания выборки населения. Эти наборы данных собираются от самого населения. В описательной статистике используются следующие методы: среднее, медиана, мода, стандартное отклонение, дисперсия и т. д.
- Логическая статистика — этот метод включает в себя выводы или прогнозы в отношении совокупности в зависимости от данных, собранных из выборки этой совокупности. Вот некоторые способы выполнения выводной статистики:
- Анализ тенденций: для выявления тенденций и выводов путем сбора данных опроса за определенный период.

- SWOT-анализ: означает сильные и слабые стороны, возможности и угрозы. Сильные и слабые стороны выполняют внутренний анализ, тогда как возможности и угрозы выполняют внешний анализ организации.
- Совместный анализ: определяет то, как люди делают свой выбор. Это метод анализа маркетинговых исследований.
- Анализ TURF: означает общий недублированный охват и анализ частоты. Он используется для оценки рыночного потенциала комбинации продуктов.
Характеристики числовых данных
- Числовые данные имеют две категории : дискретные данные и непрерывные данные, где последние подразделяются на интервальные данные и относительные данные.
- Числовые данные являются количественными по своей природе, поскольку они принимают количественные значения для данных.
- Числовые данные позволяют нам выполнять над ними арифметических операций , таких как сложение и вычитание.
 Он также может использовать любые расчеты статистического анализа.
Он также может использовать любые расчеты статистического анализа. - Можно оценить и перечислить . Когда числовые данные точны, они либо перечисляются, либо оцениваются.
- разность интервалов между каждыми числовыми данными, помещенными на числовую шкалу, оказывается равной. Часы, термометр — прекрасные примеры для этого.
- Числовые данные могут быть проанализированы с использованием двух методов : описательного и логического анализа.
- Числовые данные позволяют легко визуализировать . Он использует методы визуализации данных, такие как диаграмма рассеяния, точечный график, точечный график с накоплением, гистограммы.
5 Примеры числовых данных
- Возраст – возраст человека учитывается в числовых данных, поскольку он может принимать исчисляемые числовые значения. Пример: ребенок 10 лет начал ходить 7 лет назад.
- Время – время является числовыми данными и является исчисляемым, конечным.
 Пример: время, за которое бегун пробегает 10 кругов по земле.
Пример: время, за которое бегун пробегает 10 кругов по земле. - Рост – рост человека может принимать любое исчисляемое значение и со временем продолжает расти. Пример: рост человека может быть измерен в метрах, дюймах, футах или сантиметрах.
- Доход – доход человека или доход семьи представляет собой числовые данные. На рынке это используется для определения покупательной способности клиентов.
- Результаты тестов – результаты тестов учащихся отмечаются цифрами, а затем ранжируются в зависимости от их результатов. Пример: учащиеся с баллами от 80 до 100 считаются отличниками. 60-80 лет — первый класс, а ученики младше 60 лет — второй класс.
Преимущества числовых данных
- Прогнозирование численности населения — исследователи могут использовать числовые данные для сбора данных о рождении новорожденных в определенный период времени, а затем использовать эти данные для прогнозирования численности населения страны.
- Маркетинг и реклама . Прежде чем приступить к реализации маркетинговых и рекламных стратегий, исследователи используют SWOT-анализ для определения внешних и внутренних переменных, которые могут повлиять на эти стратегии.
- Исследование – численные данные являются обычной практикой среди исследователей из-за простоты статистического расчета.
- Разработка продукта – исследователи используют анализ TURF на этапах разработки продукта, чтобы определить область применения нового продукта на рынке.
- Education — как приведены различные примеры выше, интервальные данные используются в школах и колледжах для оценки успеваемости учащихся на экзаменах.
- Медицина – врачи регулярно используют термометр для измерения температуры тела пациента. Это также относится к интервальным данным.
Недостатки числовых данных
- Числовые данные людей не определяют их отношение к определенным темам.

- Результаты короткие и ограниченные.
- Общие вопросы исследователей могут привести к структурным искажениям.
Заключение
Это суммирует все, что вам нужно знать о числовых данных, прежде чем вы начнете их собирать. Используете ли вы опросы или эксперименты для сбора числовых данных, это может помочь вам проверить гипотезу.
Если вы готовы начать сбор числовых данных, но не знаете, какой метод использовать или какие вопросы задать, вы можете связаться с нашими специалистами.
Подробнее
Типы и форматы данных — анализ и визуализация данных в Python для экологов
Обзор
Обучение: 20 мин.
Упражнения: 25 минВопросы
Цели
Описать, как информация хранится в кадре данных Python.
Определите два основных типа данных в Python: текстовые и числовые.
Изучите структуру DataFrame.
Изменить формат значений в DataFrame.
Опишите, как типы данных влияют на операции.
Определение, обработка и взаимное преобразование целых чисел и чисел с плавающей запятой в Python.
Анализ наборов данных с отсутствующими/нулевыми значениями (значения NaN).
Запись обработанных данных в файл.

Формат отдельных столбцов и строк повлияет на анализ, выполняемый в
набор данных считывается в Python. Например, вы не можете выполнять математические
вычисления над строкой (данные в текстовом формате). Это может показаться очевидным,
однако иногда числовые значения считываются в Python как строки. В этом
ситуации, когда вы затем пытаетесь выполнить вычисления на строковом формате
числовые данные, вы получите ошибку.
В этом уроке мы рассмотрим способы изучения и лучшего понимания структура и формат наших данных.
Типы данных
Как информация хранится в DataFrame или объект Python влияет на то, что мы можем с ним делать, и на результаты расчеты тоже. Существует два основных типа данных, которые мы рассмотрим в этот урок: числовые и текстовые типы данных.
Числовые типы данных
Типы числовых данных включают целые числа и числа с плавающей запятой. с плавающей запятой (известный как float) число имеет десятичные точки, даже если это значение десятичной точки равно 0. Для пример: 1,13, 2,0, 1234,345. Если у нас есть столбец, содержащий как целые числа, так и числа с плавающей запятой, Pandas назначит весь столбец данным с плавающей запятой введите так, чтобы десятичные точки не терялись.
Целое число никогда не будет иметь десятичной точки. Таким образом, если мы хотим сохранить 1.13 как
целое число будет сохранено как 1. Точно так же 1234,345 будет сохранено как 1234. Вы
часто встречается тип данных
Точно так же 1234,345 будет сохранено как 1234. Вы
часто встречается тип данных Int64 в Python, который означает 64-битное целое число. 64
относится к памяти, выделенной для хранения данных в каждой ячейке, которая эффективно
относится к тому, сколько цифр он может хранить в каждой «ячейке». Заблаговременное выделение места
позволяет компьютерам оптимизировать хранение и эффективность обработки.
Текстовый тип данных
Тип данныхText известен как строки в Python или объекты в Pandas. Строки могут содержать цифры и/или символы. Например, строка может быть словом, предложение или несколько предложений. Объект Pandas также может быть именем сюжета, например «участок1». Строка также может содержать числа или состоять из них. Например, «1234». может быть сохранен в виде строки, как и «10.23». Однако строки, содержащие числа нельзя использовать для математических операций !
Pandas и базовый Python используют несколько разные имена для типов данных. Подробнее об этом
находится в таблице ниже:
Подробнее об этом
находится в таблице ниже:
| Панды Тип | Собственный Python Тип | Описание |
|---|---|---|
| объект | строка | Самый общий dtype. Будет назначен вашему столбцу, если столбец имеет смешанные типы (числа и строки). |
| int64 | число | Цифровые символы. 64 относится к памяти, выделенной для хранения этого символа. |
| поплавок64 | поплавок | Числовые символы с десятичными знаками. Если столбец содержит числа и NaN (см. ниже), панды по умолчанию будут использовать float64, если ваше отсутствующее значение имеет десятичное число. |
| дата-время64, дельта-времени [нс] | Н/Д (но см. модуль datetime в стандартной библиотеке Python) | Значения, предназначенные для хранения данных о времени. Изучите их для экспериментов с временными рядами. |
Проверка формата наших данных
Теперь, когда мы вооружены базовыми знаниями о числовых и текстовых данных
типов, давайте изучим формат данных нашего опроса. Мы будем работать с
тот же набор данных Surveys.csv , который мы использовали в предыдущих уроках.
# Убедитесь, что панды загружены
импортировать панд как pd
# Обратите внимание, что pd.read_csv используется, потому что мы импортировали pandas как pd
Surveys_df = pd.read_csv("data/surveys.csv")
Помните, что мы можем проверить тип объекта следующим образом:
тип (опросы_df)
pandas.core.frame.DataFrame
Теперь давайте посмотрим на структуру данных наших опросов. В пандах мы можем проверить
тип одного столбца в DataFrame с использованием синтаксиса dataFrameName[column_name].dtype :
Surveys_df['sex'].dtype
dtype('O')
Тип «O» просто означает «объект», который в мире Pandas является строкой. (текст).
(текст).
Surveys_df['record_id'].dtype
dtype('int64')
Тип int64 говорит нам, что Python сохраняет каждое значение в этом столбце.
как 64-битное целое. Мы можем использовать команду dat.dtypes для просмотра типа данных
для каждого столбца в DataFrame (все сразу).
Surveys_df.dtypes
, который возвращает :
идентификатор_записи int64 месяц int64 день int64 год int64 plot_id int64 объект spec_id сексуальный объект задняя_длина_поплавка64 вес поплавок64 тип: объект
Обратите внимание, что большинство столбцов в наших данных Survey имеют тип int64 . Это означает
что они являются 64-битными целыми числами. Но столбец веса представляет собой значение с плавающей запятой.
что означает, что он содержит десятичные дроби. Столбцы spec_id и sex являются объектами, которые
означает, что они содержат строки.
Работа с целыми числами и числами с плавающей запятой
Итак, мы узнали, что компьютеры хранят числа одним из двух способов: как целые числа или
как числа с плавающей запятой (или числа с плавающей запятой). Целые числа — это числа, которые мы обычно считаем
с. Поплавки имеют дробные части (десятичные знаки). Далее рассмотрим, как
тип данных может повлиять на математические операции с нашими данными. Добавление,
вычитание, деление и умножение работают с числами с плавающей запятой, как мы и ожидали.
Целые числа — это числа, которые мы обычно считаем
с. Поплавки имеют дробные части (десятичные знаки). Далее рассмотрим, как
тип данных может повлиять на математические операции с нашими данными. Добавление,
вычитание, деление и умножение работают с числами с плавающей запятой, как мы и ожидали.
печать(5+5)
печать(24-4)
Если мы разделим одно целое число на другое, мы получим число с плавающей запятой. Результат на Python 3 отличается от результата на Python 2, где результатом является целое число (целочисленное деление).
печать(5/9)
0,5555555555555556
печать(10/3)
3.33333333333333335
Мы также можем преобразовать число с плавающей запятой в целое число или целое число в число с плавающей запятой. Обратите внимание, что Python по умолчанию округляет в меньшую сторону, когда преобразует из числа с плавающей запятой в целое число.
# Преобразование a в целое число а = 7,83 инт (а)
# Преобразование b в число с плавающей запятой б = 7 поплавок (б)
Работа с нашими данными съемки
Возвращаясь к нашим данным, мы можем изменить формат значений в наших данных, если
мы хотим. Например, мы могли бы преобразовать поле
Например, мы могли бы преобразовать поле record_id в число с плавающей запятой.
значения.
# Преобразование поля record_id из целого числа в число с плавающей запятой
Surveys_df['record_id'] = Surveys_df['record_id'].astype('float64')
Surveys_df['record_id'].dtype
dtype('float64')
Изменение типов
Попробуйте преобразовать столбец
plot_idв числа с плавающей запятой, используяSurveys_df.plot_id.astype ("с плавающей запятой")Далее попробуйте преобразовать
весав целое число. Что здесь не так? Что панды говорят вам? О некоторых решениях мы поговорим позже.
Отсутствующие значения данных — NaN
Что произошло в последнем испытании? Обратите внимание, что это вызывает ошибку значения: ValueError: невозможно преобразовать NA в целое число . Если мы посмотрим на колонку веса в опросах
данных мы замечаем, что есть значения NaN ( N ot a N umber).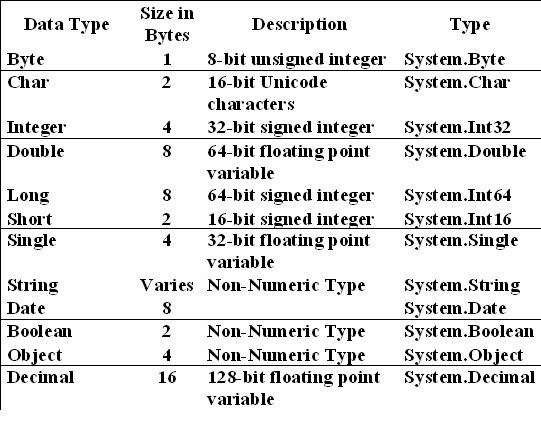 NaN значения не определены
значения, которые не могут быть представлены математически. Панды, например, будут читать
пустая ячейка в листе CSV или Excel как NaN. NaN обладают некоторыми желательными свойствами: если мы
если бы усреднить столбец
NaN значения не определены
значения, которые не могут быть представлены математически. Панды, например, будут читать
пустая ячейка в листе CSV или Excel как NaN. NaN обладают некоторыми желательными свойствами: если мы
если бы усреднить столбец с весом без замены наших NaN, Python знал бы, что нужно пропустить
над этими ячейками.
Surveys_df['вес'].mean()
42,672428212991356
Работа с отсутствующими значениями данных всегда является проблемой. Иногда трудно знаете, почему значения отсутствуют — это было из-за ошибки ввода данных? Или данные, которые кто-то не смог собрать? Должно ли значение быть 0? Нам нужно знать, как недостающие значения представлены в наборе данных для принятия правильных решений. Если нам повезет, у нас есть некоторые метаданные, которые расскажут нам больше о том, как null значения были обработаны.
Например, в некоторых дисциплинах, таких как дистанционное зондирование, отсутствующие значения данных
часто определяется как -9999. Наличие набора значений -9999 в ваших данных действительно может
изменить числовые расчеты. Часто в электронных таблицах ячейки остаются пустыми там, где их нет.
данные доступны. Pandas по умолчанию заменит эти отсутствующие значения на
NaN. Однако хорошей практикой является привычка намеренно отмечать
ячейки, в которых нет данных, без значения данных! Так что вопросов нет
в будущем, когда вы (или кто-то другой) исследуете ваши данные.
Наличие набора значений -9999 в ваших данных действительно может
изменить числовые расчеты. Часто в электронных таблицах ячейки остаются пустыми там, где их нет.
данные доступны. Pandas по умолчанию заменит эти отсутствующие значения на
NaN. Однако хорошей практикой является привычка намеренно отмечать
ячейки, в которых нет данных, без значения данных! Так что вопросов нет
в будущем, когда вы (или кто-то другой) исследуете ваши данные.
Где NaN?
Давайте подробнее рассмотрим значения NaN в наших данных. С помощью инструментов мы из урока 02, мы можем вычислить, сколько строк содержит значения NaN для масса. Мы также можем создать новое подмножество из наших данных, содержащее только строки. со значениями веса > 0 (т. е. выбрать значимые значения веса):
len(surveys_df[pd.isnull(surveys_df.weight)]) # Сколько строк имеют весовые значения? len(surveys_df[surveys_df.weight > 0])
Мы можем заменить все значения NaN нулями, используя .fillna() метод (после
делаем копию данных, чтобы не потерять нашу работу):
df1 = обзоры_df.copy() # Заполнить все значения NaN 0 df1['вес'] = df1['вес'].fillna(0)
Однако NaN и 0 дают разные результаты анализа. Среднее значение, когда NaN значения заменяются на 0 отличается от того, когда значения NaN просто выбрасываются исключены или проигнорированы.
df1['вес'].среднее()
38.751976145601844
Мы можем заполнить значения NaN любым выбранным нами значением. Код ниже заполняет все Значения NaN со средним значением для всех значений веса.
df1['вес'] = Surveys_df['вес'].fillna(surveys_df['вес'].среднее())
Мы также могли бы создать подмножество наших данных, оставив только те строки, которые не содержат значений NaN.
Суть в том, чтобы принимать осознанные решения о том, как управлять отсутствующими данными. Этот здесь мы думаем о том, как будут использоваться наши данные и как эти значения будут влияние на научные выводы, сделанные на основе данных.
Python предоставляет нам все инструменты, необходимые для решения этих проблем. Мы
просто нужно быть осторожным в отношении того, как решения, которые мы принимаем, влияют на научные
Результаты.
Мы
просто нужно быть осторожным в отношении того, как решения, которые мы принимаем, влияют на научные
Результаты.
Подсчет
Подсчитать количество пропущенных значений в столбце.
Подсказка
Метод
.count()дает вам количество наблюдений, не относящихся к NA, на столбец. Попробуйте найти метод.isnull().
Запись данных в CSV
Мы научились использовать данные для получения желаемого результата. Но мы также обсудили хранение данных, которыми манипулировали, отдельно от наших необработанных данных. Что-то, что может быть нам интересно при этом работает только с теми столбцами, которые содержат полные данные. Во-первых, давайте перезагрузим данные, чтобы мы не смешиваем все наши предыдущие манипуляции.
Surveys_df = pd.read_csv("data/surveys.csv")
Теперь давайте отбросим все строки, содержащие пропущенные значения. Мы будем использовать команду
Мы будем использовать команду dropna .
По умолчанию dropna удаляет строки, содержащие недостающие данные хотя бы для одного столбца.
df_na = обзоры_df.dropna()
Если вы сейчас наберете df_na , вы должны заметить, что результирующий DataFrame имеет 30676 строк.
и 9 столбцов, что намного меньше, чем исходное число строк 35549.
Теперь мы можем использовать 9Команда 0388 to_csv для экспорта кадра данных в формате CSV. Обратите внимание, что код
ниже по умолчанию сохранит данные в текущий рабочий каталог. Мы можем
сохраните его в другой папке, добавив имя папки и косую черту перед именем файла: df.to_csv('имя папки/out.csv') . Мы используем ‘index=False’, чтобы
pandas не включает порядковый номер для каждой строки.
# Запись DataFrame в CSV
df_na.to_csv('data_output/surveys_complete.csv', index=False)
Мы будем использовать этот файл данных позже в мастерской. Проверьте свой рабочий каталог, чтобы сделать
убедитесь, что CSV записан правильно, и что вы можете его открыть! Если хочешь, попробуй принести
обратно в Python, чтобы убедиться, что он правильно импортируется.