Spatial Transformer Networks в MATLAB / Хабр
В данной статье будут подниматься темы построения пользовательских слоёв нейронных сетей, использование автоматического дифференцирования и работы со стандартными слоями глубокого обучения нейронных сетей в MATLAB на основе классификатора с использованием пространственной трансформационной сети.
Spatial Transformer Network (STN) — один из примеров дифференцируемых LEGO-модулей, на основе которых можно строить и улучшать свою нейросеть. STN, применяя обучаемое аффинное преобразование с последующей интерполяцией, лишает изображения пространственной инвариантности. Грубо говоря, задача STN состоит в том, чтобы так повернуть или уменьшить/увеличить исходное изображение, чтобы основная сеть-классификатор смогла проще определить нужный объект. Блок STN может быть помещен в сверточную нейронную сеть (CNN), работая в ней по большей части самостоятельно, обучаясь на градиентах, приходящих от основной сети (более детально с данной темой можно ознакомиться по ссылкам: Хабр и Мануал).
В нашем случае задачей является классифицировать 99 классов лобовых стёкол автомобилей, но, для начала, начнём с чего-нибудь попроще. Для того, чтобы ознакомиться с данной тематикой, возьмём базу данных MNIST из рукописных цифр и построим сеть из нейронных слоёв глубокого обучения MATLAB и пользовательского слоя аффинной трансформации изображения (ознакомиться со списком всех имеющихся слоёв и их функционалом можно по ссылке).
Для реализации пользовательского слоя трансформации мы воспользуемся шаблоном пользовательского слоя и возможностью MATLAB для автоматического дифференцирования и построения обратного распространения производной от ошибки, которая реализуется за счёт массивов глубокого обучения для пользовательских учебных циклов — dlarray (ознакомиться с шаблоном можно по ссылке , ознакомиться с dlarray структурами можно по ссылке).
Для того, чтобы реализовать возможности dlarray, нам необходимо вручную прописать аффинную трансформацию изображения так как функции MATLAB, реализующие данную возможность, не поддерживают структуры dlarray. Далее представлена написанная нами функция трансформации, весь проект доступен по ссылке.
Далее представлена написанная нами функция трансформации, весь проект доступен по ссылке.
Поскольку аффинное преобразование является обратимым, самым простым способом проверки корректности работы функции является наложение трансформации на изображение, а затем нахождение обратной матрицы и выполнение повторной трансформации. Как мы видим на представленном ниже изображении, наш алгоритм работает корректно. Слева у нас входные изображения, справа выходные, сверху — над правыми изображениями — подписана наложенная на изображение трансформация.
Также важно уточнить, какие конкретно изменения накладываются на изображения разными числами матрицы преобразования. Первая строка накладывает трансформации по оси Y, а вторая по Х. Параметры выполняют изменение размера (приближение, отдаление), поворот и смещение изображения. Более детально матрица трансформации описана в таблице.
Y | Размер | Поворот | Смещение |
Х | Поворот | Размер | Смещение |
Теперь, когда мы разобрались с теоретической составляющей, перейдём к реализации сети с использованием STN. На рисунках ниже представлены структура построенной сети и результаты обучения для базы данных MNIST.
На рисунках ниже представлены структура построенной сети и результаты обучения для базы данных MNIST.
Опираясь на результаты обучения, а именно на то, как сеть трансформирует изображение и на то, какой процент угадывания она демонстрирует, можно сделать вывод, что данный вариант сети полностью функционален.
Теперь, когда мы получили достойный результат на базе данных MNIST, можно переходить к имеющимся у нас лобовым стёклам.
Первое различие между входными данными — это то, что числа — это изображения в градиенте серого, а стёкла — изображения формата RGB, следовательно, нам необходимо изменить слой трансформации, добавив цикл. Будем применять отдельно трансформацию к каждому из слоёв изображения. Также для упрощения обучения добавим в слой трансформации веса, на которые будем домножать матрицу трансформации, и установим эти веса в 2, за исключением весов смещения изображения, их установим в 0, для того чтобы сеть училась, в первую очередь, поворачивать и изменять масштаб изображения. Также, если взять данные веса меньше, то сеть дольше будет перестраивать веса STN в поисках полезной информации, так как полезная информация у нас находится по краям изображения, а не в центре, в отличие от сети с числами. Далее нам необходимо заменить часть классификатора, так как он является слишком слабым для наших входных данных. Чтобы не изменять структуру самого STN, мы приведём изображение к виду, похожему на числа, добавив слой нормализации и dropout для уменьшения объёма входных данных в STN.
Также, если взять данные веса меньше, то сеть дольше будет перестраивать веса STN в поисках полезной информации, так как полезная информация у нас находится по краям изображения, а не в центре, в отличие от сети с числами. Далее нам необходимо заменить часть классификатора, так как он является слишком слабым для наших входных данных. Чтобы не изменять структуру самого STN, мы приведём изображение к виду, похожему на числа, добавив слой нормализации и dropout для уменьшения объёма входных данных в STN.
Сравнивая данные на входе у сети с числами и стёклами, можно увидеть, что на стёклах диапазон значений варьируется от [0;255], а в числах от [0;1], а также в числах большая часть матрицы — это нули. Примеры данных на входе показаны ниже.
Данные на входе у сети с числами.Данные на входе у сети со стёклами.Опираясь на вышеприведённые данные, нормализация будет выполняться по принципу деления входных данных на 255 и обнуления всех значений меньше 0.3 и больше 0.75, а также от трёхмерного изображения мы оставим только одно измерение. На изображении ниже видно, что подаётся на входе и что остаётся после слоя нормализации.
На изображении ниже видно, что подаётся на входе и что остаётся после слоя нормализации.
Также в связи с тем, что у нас не так много данных для тестирования и обучения сети, мы искусственно увеличим их объём за счёт аффинной трансформации, а именно поворота изображения на случайный градус в пределах [-10;10] и прибавления случайного числа к матрице изображения для изменения цветовой палитры в пределах [-50; 50]. В функции чтения мы воспользуемся стандартными функциями MATLAB, так как в ней нам не требуется оперировать dlarray структурами. Ниже представлена используемая функция чтения входных изображений.
Ниже представлены структура сети с внесёнными изменениями и результаты обучения этой сети.
Структура сети.Результаты обучения.Как мы видим, сеть выделила полезные признаки, а именно центральную часть изображения, за счёт этого, уже к концу первой эпохи достигла процента угадывания выше 90. Так как по краям изображения одинаковые, сеть обучилась на классификацию отличных признаков, и за счёт этого она увеличивает центральную часть, вынося левые и правые грани за границу изображения подаваемого на классификатор. При этом сеть поворачивает все изображения так, чтобы они не отличались по углу наклона, за счёт чего классификатору не требуется настраивать веса под разные углы наклона изображения, тем самым увеличивается точность классификации.
При этом сеть поворачивает все изображения так, чтобы они не отличались по углу наклона, за счёт чего классификатору не требуется настраивать веса под разные углы наклона изображения, тем самым увеличивается точность классификации.
Для сравнения, возьмём и протестируем сеть без использования STN, оставив только имеющийся у нас классификатор. Ниже представлены результаты обучения этой сети.
Результаты обучения.Как мы видим, сеть действительно обучается медленнее и за то же количество итераций достигает меньшей точности.
Подводя итоги, можно сделать вывод, что технология STN актуальна в современных нейронных сетях и позволяет увеличить скорость обучения и точность классификации сети.
Нейронные сети, «вредные» советы / Хабр
Исторически, искусственные нейронные сети за свою уже более чем полувековую историю испытывали как периоды стремительных взлетов и повышенного внимания общества, так и сменявшие их периоды скепсиса и равнодушия. В хорошие времена ученым и инженерам кажется, что наконец-то найдена универсальная технология, способная заменить человека в любых когнитивных задачах. Как грибы после дождя, появляются различные новые модели нейронных сетей, между их авторами, профессиональными учеными-математиками, идут напряженные споры о большей или меньшей степени биологичности предложенных ими моделей. Профессиональные ученые-биологи наблюдают эти дискуссии со стороны, периодически срываясь и восклицая «Да такого же в реальной природе не бывает!» – и без особого эффекта, поскольку нейросетевики-математики слушают биологов, как правило, только тогда, когда факты биологов согласуются с их собственными теориями. Однако, с течением времени, постепенно накапливается пул задач, на которых нейронные сети работают откровенно плохо и энтузиазм людей остывает.
В хорошие времена ученым и инженерам кажется, что наконец-то найдена универсальная технология, способная заменить человека в любых когнитивных задачах. Как грибы после дождя, появляются различные новые модели нейронных сетей, между их авторами, профессиональными учеными-математиками, идут напряженные споры о большей или меньшей степени биологичности предложенных ими моделей. Профессиональные ученые-биологи наблюдают эти дискуссии со стороны, периодически срываясь и восклицая «Да такого же в реальной природе не бывает!» – и без особого эффекта, поскольку нейросетевики-математики слушают биологов, как правило, только тогда, когда факты биологов согласуются с их собственными теориями. Однако, с течением времени, постепенно накапливается пул задач, на которых нейронные сети работают откровенно плохо и энтузиазм людей остывает.
В наши дни нейронные сети снова в зените славы благодаря изобретению метода предобучения «без учителя» на основе Ограниченных Больцмановских Машин (Restricted Bolzmann Machines, RBM), что позволяет обучать глубокие нейронные сети (т.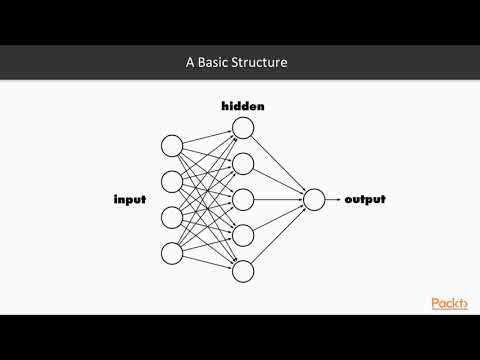 е. с экстра-большим, порядка десятков тысяч, количеством нейронов) и успехам глубоких нейронных сетей в практических задачах распознавания устной речи [1] и изображений [2]. К примеру, распознавание речи в Android реализовано именно на глубоких нейронных сетях. Как долго это продлится и насколько сильно глубокие нейронные сети оправдают возложенные на них ожидания – неизвестно.
е. с экстра-большим, порядка десятков тысяч, количеством нейронов) и успехам глубоких нейронных сетей в практических задачах распознавания устной речи [1] и изображений [2]. К примеру, распознавание речи в Android реализовано именно на глубоких нейронных сетях. Как долго это продлится и насколько сильно глубокие нейронные сети оправдают возложенные на них ожидания – неизвестно.
Между тем, параллельно всем научным спорам, течениям и тенденциям, отчетливо выделяется сообщество пользователей нейронных сетей – инженеров-программистов-практиков, которых интересует прикладной аспект нейросетей, их способность обучаться на собранных данных и решать задачи распознавания. Со многими практическими задачами классификации и прогнозирования великолепно справляются хорошо проработанные, относительно небольшие модели многослойных персептронов (Multilayer Perceptron, MLP) и сети радиальных базисных функций (Radial Basis Function network, RBF). Эти нейронные сети многократно описаны, я бы посоветовать следующие книжки, в порядке моей личной симпатии к ним: Осовский [3], Бишоп [4], Хайкин [5]; также есть хорошие курсы на Coursera и подобных ресурсах.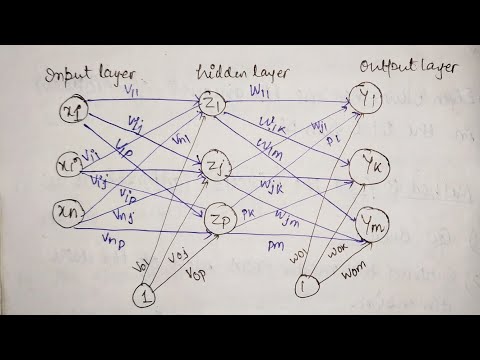
Однако, что касается общего подхода использования нейронных сетей на практике, он кардинально отличается от обычного детерминированного девелоперского подхода «запрограммировал, работает – значит, работает всегда». Нейронные сети по своей природе являются вероятностными моделями, и подход к ним должен быть совершенно иной. К сожалению, многие программисты-новички технологий машинного обучения вообще и нейронных сетей в частности делают системные ошибки при работе с ними, разочаровываются и забрасывают это дело. Идея написания настоящего трактата на Хабр возникла после общения с такими разочарованными пользователями нейронных сетей – отличными, опытными, уверенными в себе программистами.
Вот мой список правил и типичных ошибок использования нейронных сетей.
1. Если есть возможность не использовать нейронные сети – не используйте их.
Нейронные сети позволяют решить задачу в случае, если предложить алгоритм путем многократного (или очень многократного) просмотра данных глазами невозможно. Например, если данных много, они нелинейные, зашумленные и/или большой размерности.
Например, если данных много, они нелинейные, зашумленные и/или большой размерности.
2. Сложность нейронных сетей должна быть адекватна сложности задачи.
Современные персональные компьютеры (к примеру, Core i5, 8 GB RAM) позволяют за комфортное время обучать нейронные сети на выборках объемом в десятки тысяч примеров, с размерностью входных данных до сотни. Большие выборки – задача для упомянутых выше глубоких нейронных сетей, которые обучают на многопроцессорных GPU. Эти модели очень интересны, но находятся вне фокуса внимания настоящей хабр-статьи.
3. Данные для обучения должны быть репрезентативными.
Обучающая выборка должна полно и разносторонне представлять описываемый феномен, включать в себя различные возможные ситуации. Хорошо, когда данных много, но это само по себе тоже не всегда помогает. В узких кругах широко распространен анекдот, когда к распознавальщику приходит геолог, выкладывает перед ним кусок минерала и просит разработать по нему систему распознавания такого вещества.
4. Перемешивайте выборку.
После того, как входные и выходные векторы данных собраны, если измерения независимы между собой – поменяйте порядок следования векторов произвольным образом. Это критично для корректного разделения выборки на Train/Test/Validation и всех методов обучения типа «пример-за-примером» («sample-by-sample»).
5. Нормируйте и центрируйте данные.
Для многослойных персептронов, и для многих других моделей значения входных данных должны лежать в пределах [-1;1]. Перед тем, как подавать их на нейросеть, вычтите из данных среднее и поделите все значения на максимальное значение.
6. Делите выборку на Train, Test и Validation.
Основная ошибка новичков – обеспечить минимальную ошибку работы нейросети на обучающей выборке, попутно адски ее переобучив и затем желать такого же хорошего качества на новых реальных данных. Это особенно легко сделать, если данных мало (или они все «из одного куска»). Результат может очень расстроить: нейросеть максимально подстроится под выборку и потеряет работоспособность на реальных данных. Для того, чтобы контролировать обобщающие способности вашей модели – разделите все данные на три выборки соотношении 70: 20: 10. Обучайтесь на Train, периодически проверяя качество модели на Test. Для финальной непредвзятой оценки – Validation.
Это особенно легко сделать, если данных мало (или они все «из одного куска»). Результат может очень расстроить: нейросеть максимально подстроится под выборку и потеряет работоспособность на реальных данных. Для того, чтобы контролировать обобщающие способности вашей модели – разделите все данные на три выборки соотношении 70: 20: 10. Обучайтесь на Train, периодически проверяя качество модели на Test. Для финальной непредвзятой оценки – Validation.
Техника кросс-валидации, когда Train и Test несколько раз формируется по очереди произвольным способом из одних и тех же данных, может проявить коварство и дать ложное впечатление о хорошем качестве работы системы – например, если данные взяты из разных источников и это критично. Используйте правильный Validation!
7. Применяйте регуляризацию.
Регуляризация – это техника, которая позволяет избежать переобучения нейросети во время обучения, даже если данных мало. Если вы обнаружили галочку с таким словом, обязательно ее ставьте. Признак переобучившейся нейросети – большие значения весов, порядка сотен и тысяч, такая нейросеть не будет нормально работать на новых, не виденных ранее, данных
Признак переобучившейся нейросети – большие значения весов, порядка сотен и тысяч, такая нейросеть не будет нормально работать на новых, не виденных ранее, данных
8. Не нужно дообучать нейронную сеть в режиме он-лайн.
Идея дообучать нейросеть перманентно все время на новых поступающих данных – сама по себе правильная, в реальных биологических системах все именно так и происходит. Мы учимся каждый день и редко сходим с ума. Тем не менее, для обычных искусственных нейронных сетей на современном этапе технического развития такая практика является рискованной: сеть может переобучиться или подстроиться под самые последние поступившие данные данные – и потеряет свои обобщающие способности. Для того, чтобы систему можно было использовать на практике, нейросеть нужно: 1) обучить, 2) протестировать качество на тестовых и валидационных выборках, 3) выбрать удачный вариант сети, зафиксировать ее веса и 4) использовать обученную нейросеть на практике, веса в процессе использования не менять.
9. Используйте новые алгоритмы обучения: Левенберга-Марквардта, BFGS, Conjugate Gradients и др.
Я глубоко убежден, что реализовать обучение методом обратного распространения ошибки (backpropagation) – святой долг каждого, кто работает с нейронными сетями. Этот метод самый простой, относительно легко программируется и позволяет хорошо изучить процесс обучения нейронных сетей. Между тем, backpropagation был изобретен в начале 70-х и стал популярен в середине 80-х годов прошлого столетия, с тех пор появились более продвинутые методы, которые могут в разы улучшить качество обучения. Лучше используйте их.
10. Обучайте нейронные сети в MATLAB и подобных дружественных средах.
Если вы не ученый, разрабатывающий новые методы обучения нейронных сетей, а программист-практик, я бы не рекомендовал кодировать процедуру обучения нейронных сетей самостоятельно. Существует большое количество программных пакетов, в основном на MATLAB и Python, которые позволяют обучать нейронные сети, при этом контролировать процесс обучения и тестирования, используя удобные средства визуализации и отладки.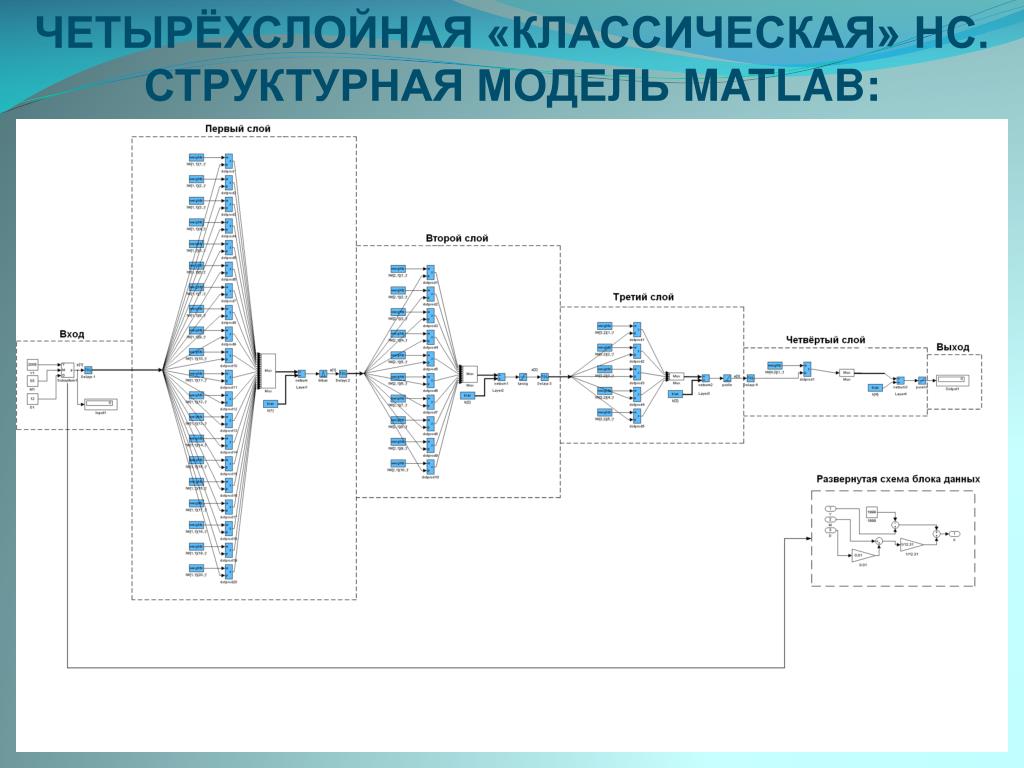 Пользуйтесь наследием человечества! Мне лично нравится подход «обучение в MATLAB хорошей библиотекой – реализация обученной модели руками», он достаточно мощный и гибкий. Исключение – пакет STATISTICA, который содержит продвинутые методы обучения нейросетей и позволяет генерировать их в виде программного кода на С, удобного для иплементации.
Пользуйтесь наследием человечества! Мне лично нравится подход «обучение в MATLAB хорошей библиотекой – реализация обученной модели руками», он достаточно мощный и гибкий. Исключение – пакет STATISTICA, который содержит продвинутые методы обучения нейросетей и позволяет генерировать их в виде программного кода на С, удобного для иплементации.
В следующей статье я планирую подробно описать реализованный на основе описанных выше принципов полный промышленный цикл подготовки нейросети, использующейся для задач распознавания в коммерческом программном продукте.
Желаю удачи!
Литература
[1] Hinton G., Deng L., Yu D., Dahl G., Mohamed A., Jaitly N., Senior A., Vanhoucke V., Nguyen P., Sainath T. and Kingsbury B. Deep Neural Networks for Acoustic Modeling in Speech Recognition, IEEE Signal Processing Magazine, Vol. 29, No. 6, 2012, pp. 82 – 97.
[2] Ciresan D., Meier U., Masci J and Schmidhuber J. Multi-column Deep Neural Network for Traffic Sign Classification.
[3] С. Осовский. Нейронные сети для обработки информации – пер. с польского. М.: Финансы и статистика, 2002. – 344с.
[4] Bishop C.M. Pattern Recognition and Machine Learning. Springer, 2006 – 738 p.
[5] С. Хайкин. Нейронные сети: полный курс. Вильямс, 2006.
Что такое нейронная сеть?
Почему нейронные сети важны?
Нейронные сети — это разновидность машинного обучения, основанная на том, как нейроны передают сигналы друг другу в человеческом мозгу. Нейронные сети особенно подходят для моделирования нелинейных отношений, и они обычно используются для распознавания образов и классификации объектов или сигналов в системах речи, зрения и управления.
Вот несколько примеров использования нейронных сетей в приложениях машинного обучения:
- Семантическая сегментация изображений и видео
- Обнаружение объектов на изображениях, включая пешеходов и велосипедистов
- Обучение двуногого робота ходить с помощью обучения с подкреплением
- Обнаружение рака путем помощи патологам в классификации опухолей как доброкачественных или злокачественных на основе однородности размера клеток, толщины скопления, митоза и других факторов.

Нейронные сети, особенно глубокие нейронные сети, стали известны благодаря своей способности работать со сложными приложениями идентификации, такими как распознавание лиц, перевод текста и распознавание голоса. Эти подходы являются ключевой технологией, стимулирующей инновации в передовых системах помощи водителю и задачах, включая классификацию полос движения и распознавание дорожных знаков.
Обзор глубокого обучения.
Обзор глубокого обучения
Глубокое обучение и традиционное машинное обучение: выбор правильного подхода
Читать электронную книгу
Как работают нейронные сети?
Вдохновленная биологическими нервными системами, нейронная сеть объединяет несколько уровней обработки, используя простые элементы, работающие параллельно. Сеть состоит из входного слоя, одного или нескольких скрытых слоев и выходного слоя. В каждом слое есть несколько узлов или нейронов, и узлы в каждом слое используют выходные данные всех узлов в предыдущем слое в качестве входных данных, так что все нейроны соединяются друг с другом через разные слои. Каждому нейрону обычно назначается вес, который корректируется в процессе обучения, и уменьшение или увеличение веса изменяет силу сигнала этого нейрона.
Каждому нейрону обычно назначается вес, который корректируется в процессе обучения, и уменьшение или увеличение веса изменяет силу сигнала этого нейрона.
4:37 Продолжительность видео 4:37.
Начало работы с нейронными сетями с использованием MATLAB
Типичная архитектура нейронной сети.
Как и другие алгоритмы машинного обучения:
- Нейронные сети можно использовать для обучения с учителем (классификация, регрессия) и обучения без учителя (распознавание образов, кластеризация)
- Параметры модели устанавливаются путем взвешивания нейронной сети посредством «обучения» на обучающих данных, обычно путем оптимизации весов для минимизации ошибки прогнозирования
Типы нейронных сетей
Первой и простейшей нейронной сетью был персептрон, представленный Фрэнком Розенблаттом в 1958 году. Он состоял из одного нейрона и, по существу, модели линейной регрессии с сигмовидной функцией активации. С тех пор исследовались все более сложные нейронные сети, что привело к сегодняшним глубоким сетям, которые могут содержать сотни слоев.
С тех пор исследовались все более сложные нейронные сети, что привело к сегодняшним глубоким сетям, которые могут содержать сотни слоев.
Глубокое обучение относится к многоуровневым нейронным сетям, тогда как нейронные сети только с двумя или тремя слоями связанных нейронов также известны как поверхностные нейронные сети. Глубокое обучение стало популярным, потому что оно избавляет от необходимости извлекать признаки из изображений, что ранее затрудняло применение машинного обучения для обработки изображений и сигналов. Однако, хотя в приложениях для обработки изображений извлечение признаков может быть исключено, некоторая форма выделения признаков по-прежнему широко применяется в задачах обработки сигналов для повышения точности модели.
Типы нейронных сетей, обычно используемых для инженерных приложений, включают:
- Нейронная сеть с прямой связью: состоит из входного слоя, одного или нескольких скрытых слоев и выходного слоя (типичная неглубокая нейронная сеть)
- Сверточная нейронная сеть (CNN): Архитектура глубокой нейронной сети, широко применяемая для обработки изображений и характеризующаяся сверточными слоями, которые сдвигают окна по входным данным с узлами, имеющими общие веса, абстрагируя входные данные (обычно изображения) для карт объектов
- Рекуррентная нейронная сеть (RNN): Архитектура нейронной сети с петлями обратной связи, которые моделируют последовательные зависимости во входных данных, таких как временные ряды, сенсорные и текстовые данные; наиболее популярным типом RNN является сеть с долговременной кратковременной памятью (LSTM) .
Подробнее о глубоком обучении можно узнать здесь:
Введение в глубокое обучение: машинное обучение и глубокое обучение (3:47)
Глубокие нейронные сети (4 видео)
Разработка нейронных сетей с помощью MATLAB
MATLAB ® предлагает специализированные наборы инструментов для машинного обучения, нейронных сетей, глубокого обучения, компьютерного зрения и автоматизированного вождения.
С помощью всего нескольких строк кода MATLAB позволяет разрабатывать нейронные сети, не будучи экспертом. Быстро приступайте к работе, создавайте и визуализируйте модели нейронных сетей, интегрируйте их в существующие приложения и развертывайте на серверах, корпоративных системах, кластерах, облаках и встроенных устройствах.
Что такое набор инструментов для глубокого обучения? (2:40)
Начало работы с нейронными сетями с помощью MATLAB (4:37)
Типовой рабочий процесс для построения нейронных сетей
Разработка приложений ИИ, в частности нейронных сетей, обычно включает следующие этапы:
1.
 Подготовка данных
Подготовка данных- Вы получаете достаточно размеченных обучающих данных, и гораздо больше требуется для обучения глубоких нейронных сетей; приложения для маркировки, такие как Image, Video и Signal, могут ускорить этот процесс
- Вы можете использовать моделирование для создания обучающих данных, особенно если сбор данных из реальных систем нецелесообразен (например, условия отказа)
- Вы можете дополнить данные, чтобы представить большую вариативность обучающих данных
2. Моделирование ИИ
- Неглубокие нейронные сети можно обучать в интерактивном режиме в Classification and Regression Learner из Statistics and Machine Learning Toolbox™ или использовать функции командной строки; это рекомендуется, если вы хотите сравнить производительность неглубоких нейронных сетей с другими традиционными алгоритмами машинного обучения, такими как деревья решений или SVM, или если у вас есть только ограниченные размеченные обучающие данные
- Укажите и обучите нейронные сети (мелкие или глубокие) в интерактивном режиме с помощью Deep Network Designer или функций командной строки из Deep Learning Toolbox™, которые особенно подходят для глубоких нейронных сетей, или если вам нужна большая гибкость в настройке сетевой архитектуры и решателей
3.
 Моделирование и тестирование
Моделирование и тестирование- Вы можете интегрировать нейронные сети в модели Simulink ® в виде блоков, что может облегчить интеграцию с более крупной системой, тестирование и развертывание на многих типах оборудования
4. Развертывание
- Создание простого кода C/C++ из неглубоких нейронных сетей, обученных в Statistics and Machine Learning Toolbox, для развертывания во встроенном оборудовании и высокопроизводительных вычислительных системах
- Создание оптимизированного кода CUDA и простого кода C/C++ из нейронных сетей, обученных в Deep Learning Toolbox, для быстрого логического вывода на графических процессорах и других типах промышленного оборудования (ARM, FPGA)
Начало работы с нейронными сетями с использованием MATLAB Video
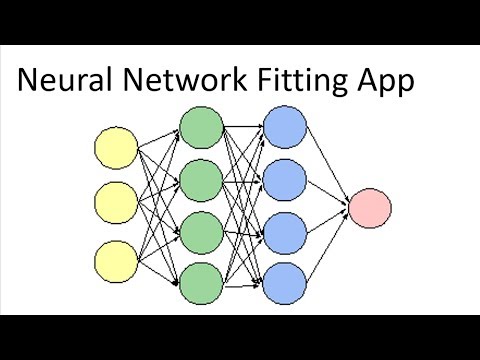
Привет и снова добро пожаловать в очередной видеоролик по MATLAB. Сегодня мы поговорим о нейронных сетях и обучим их классифицировать деятельность человека на основе данных датчиков со смартфонов.
Нейронные сети полезны во многих приложениях — их можно использовать для кластеризации, классификации, регрессии и прогнозирования временных рядов.
Нейронная сеть — это адаптивная система, которая обучается, используя взаимосвязанные узлы.
Нейронные сети состоят из одного или нескольких слоев. Они включают как минимум 3 слоя: входной слой, скрытый слой и выходной слой.
В целом, алгоритм включает ряд математических операций, которые вычисляют взвешенную сумму входных данных в каждом узле.
Каждый нейрон в слое имеет регулируемые веса для своих входов и регулируемое смещение.
Нейронная сеть работает (обучается), корректируя все эти веса и смещения и сводя к минимуму ошибку на протяжении всего этапа обучения для достижения более точных результатов.
Давайте обсудим это подробнее с демонстрацией
В этом примере используются данные датчика, содержащие измерения, полученные со смартфонов, которые носят люди, выполняя 5 различных действий — ходьба, сидение, лежание, ходьба вверх и вниз по лестнице.
Целью этого анализа является построение модели для автоматического определения типа активности на основе измерений датчика с использованием нейронной сети.
Сначала мы импортируем набор данных, который содержит метку активности и статистические измерения с датчиков.
В данном случае мы решаем задачу классификации и создадим нейронную сеть для распознавания образов.
Существуют различные функции для создания различных типов сетей. Используйте документацию, чтобы определить функцию и узнать больше о типах сетей.
Давайте создадим простую сеть распознавания образов с прямой связью со значениями по умолчанию.
Создать сеть
В данном случае мы решаем задачу классификации и создадим нейронную сеть для распознавания образов.
Существуют различные функции для создания различных типов сетей. Используйте документацию, чтобы определить функцию и узнать больше о типах сетей.
Давайте создадим простую сеть распознавания образов с прямой связью со значениями по умолчанию.
Сетевая переменная содержит информацию о параметрах и уравнениях и будет обновляться по мере обучения модели.
Вы можете визуализировать сеть. По умолчанию 10 нейронов в одном скрытом слое.
Вы можете получить доступ к информации о слоях, включая веса и смещения. В настоящее время они пусты, так как мы еще не обучили модель.
Далее мы включим соотношение для разделения данных обучения, проверки и тестирования. Сеть использует эту информацию для оценки точности и оптимизации параметров во время обучения.
Прежде чем мы сможем обучить сеть, данные должны быть подготовлены.
Сеть распознавания образов ожидает, что переменные будут располагаться вдоль строк, а наблюдения — вдоль столбцов. Мы можем просто транспонировать данные в нашем примере, чтобы добиться такого расположения.
Для этого типа сети предиктор и ответ или переменные X и Y должны быть числовыми. Вы можете использовать фиктивную переменную для представления категориальных данных, таких как активность, в виде матрицы единиц и нулей.
Теперь мы готовы обучить сеть, используя обучающие данные!
Вы можете отслеживать прогресс во время обучения сети и при необходимости останавливаться досрочно.
Теперь сеть завершила обучение и содержит обновленные значения параметров, извлеченные из данных.
Помните, что был один скрытый слой с 10 узлами и один выходной слой. Наш набор данных имеет 5 классов, поэтому есть 5 выходных узлов.
Веса и смещения были обновлены значениями, полученными в результате обучения.
Теперь мы можем протестировать сеть и предсказать активность, используя тестовые данные.
Результатом является оценка принадлежности к каждому классу.
Мы можем определить прогнозируемый класс и преобразовать числовые значения в исходные метки для сравнения.
Найдите точность и постройте матрицу путаницы для оценки классификаций.
Лежание и сидение почти все правильно классифицируются. И хотя большинство из них верны, различные типы ходьбы иногда классифицируются как один другой.
Это кажется хорошей сетью с разумными неправильными классификациями, но вы можете изучить способы еще большего улучшения.
Существует множество стратегий улучшения сети.
Мы можем попробовать обновить некоторые параметры для обучения и оценки сети. См. документацию для получения подробной информации о параметрах для различных сетей.
Здесь не так много улучшений в выводе. Мы могли бы продолжать вносить коррективы или пробовать разные типы сетей.
Например, вы можете создать сеть с большим количеством скрытых слоев или глубокую нейронную сеть. В MATLAB и ресурсах для глубокого обучения поддерживается множество типов глубоких сетей. Для получения дополнительной информации перейдите по ссылкам в описании ниже.
Всегда есть возможности для улучшения, но эта модель работает достаточно хорошо с точностью 92%. Теперь мы можем предпринять шаги, чтобы подготовиться к использованию этой модели в производственной среде или к интеграции с системой.
При развертывании вы записываете свои шаги в функцию, и вам также нужно будет сохранить сеть или создать ее заново.