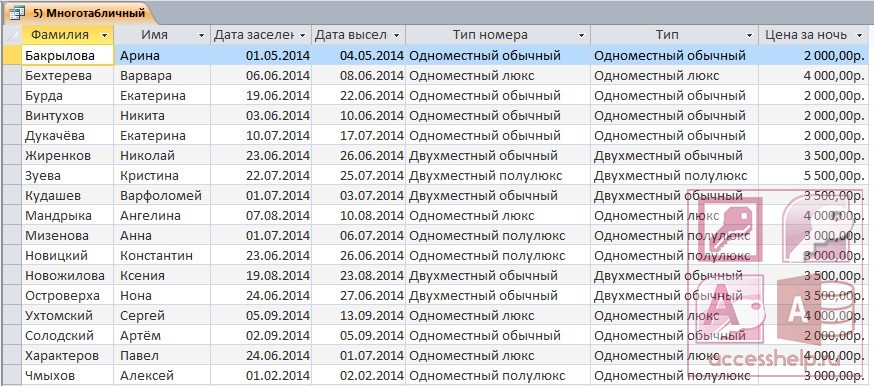
§3.4. Многотабличные базы данных | ПР 3.9 (inf_11_проф_ugr)
Планирование уроков на учебный год (по учебнику Н.Д. Угриновича, профильный уровень)
Главная | Информатика и информационно-коммуникационные технологии | Планирование уроков и материалы к урокам | 11 классы | Планирование уроков на учебный год (по учебнику Н.Д. Угриновича, профильный уровень) | §3.4. Многотабличные базы данных
Содержание урока
3.4. Многотабличные базы данных3.4.1. Связывание таблицСвязывание таблиц
Контрольные вопросы
Практическая работа 3.9 Многотабличные базы данных
Практическая работа 3.9
Многотабличные базы данных
Аппаратное и программное обеспечение. Компьютер с установленной операционной системой Windows.
Цель работы. Научиться создавать реляционные многотабличные базы данных и создавать к ним запросы в СУБД Microsoft Access 2007 в операционной системе Windows.
Задание:
• создать реляционную многотабличную базу данных «Компьютеры», в качестве основных объектов которой будут использованы три таблицы: «Комплектующие», «Поставщики» и «Цена». Таблицы «Комплектующие» и «Поставщики» должны быть связаны отношением «многие-ко-многим» с помощью таблицы «Цена»;
• создать запрос, который осуществляет отбор данных, необходимых для закупки дешевого системного блока.
Создание реляционной многотабличной базы данных с помощью СУБД Microsoft Access 2007
1. В операционной системе Windows запустить
Система управления базами данных Microsoft Access позволяет создавать многотабличные базы данных, а также обеспечивать их обработку с помощью запросов, форм и отчетов.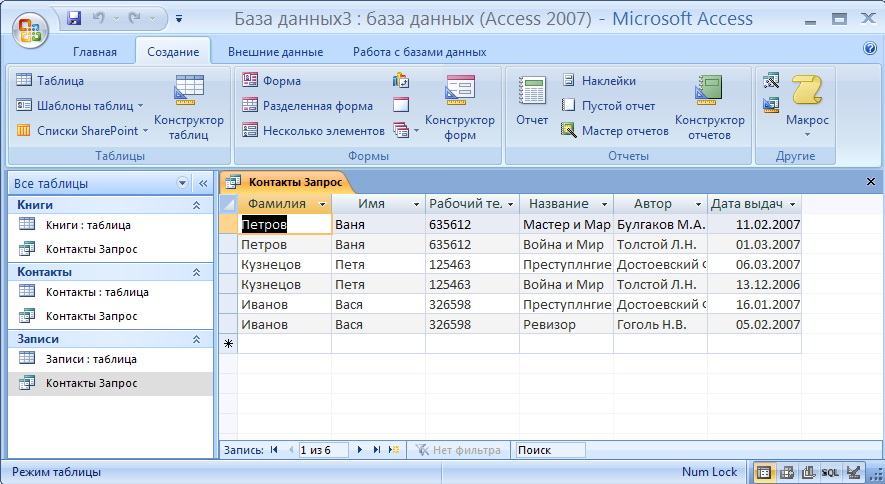
Итак, прежде всего, необходимо создать три таблицы: «Комплектующие» «Поставщики» и «Цена».
2. Щелкнуть по значку Кнопка Microsoft Office .
Создать в СУБД Microsoft Access 2007 новую базу данных с помощью команды [Создать].
В появившемся диалоговом окне в текстовом поле Имя файла: присвоить файлу базы данных имя Компьютеры.accdb.
Щелкнуть по кнопке Создать
.Таблица «Комплектующие» должна содержать три текстовых поля: Код комплектующих. Наименование и Описание.
3. В диалоговом окне Компьютеры: база данных создать таблицу «Комплектующие» и ввести данные.
4. Ввести команду [Режим-Конструктор].
В качестве первичного ключа задать поле Код комплектующих.
Таблица «Поставщики» должна содержать три текстовых поля: Код поставщика, Название фирмы и Адрес. Первичным ключом является поле Код поставщика.
Первичным ключом является поле Код поставщика.
5. Создать таблицу «Поставщики», выполнив рассмотренную выше последовательность действий. Ввести данные.
Таблица «Цена» должна содержать поля Счетчик, Код комплектующих, Код поставщика, а также
6. С помощью аналогичных действий создать таблицу «Цена» и ввести данные.
Таблицы «Комплектующие» и «Поставщики» должны быть связаны отношением «один-ко-многим» с таблицей «Цена». Таблица «Цена» содержит поля Код комплектующих и Код поставщика, являющиеся внешними ключами исходных таблиц.
Установим связи между таблицами.
7. Ввести команду [Работа с базами данных-Схема данных].
Связь в отношении «многие-ко-многим» между таблицами «Комплектующие» и «Поставщики» через таблицу «Цена» будет установлена.
Созданная многотабличная база данных «Компьютеры» состоит из трех связанных таблиц и поэтому обладает целостностью данных. Это значит, что можно создавать запросы, формы и отчеты, которые используют данные из разных таблиц.
Создадим, например, запрос, который осуществляет отбор данных, необходимых для закупки дешевого системного блока.
8. Ввести команду [Режим-Конструктор].
9. В таблице «Комплектующие» для поля Код комплектующих ввести условие равно «К1», в таблице «Поставщики» для полей Название фирмы и Адрес установить вывод на экран, в таблице «Цена» для поля Цена ввести условие < 9500.
10. Ввести команду [Режим-Режим таблицы]
Следующая страница 3.4. Многотабличные базы данных
Cкачать материалы урока
Многотабличные базы данных — презентация онлайн
Похожие презентации:
Базы данных. Многотабличные базы данных
Базы Данных (§12 — §23)
Базы данных
Базы данных Информационные системы
Таблицы. Базы данных
Базы данных. Введение
Базы данных (MS Access)
Базы данных. Информационные системы
Проектирование многотабличной базы данных
Реляционные и нереляционные базы данных
1. Базы данных
1Тема:
Многотабличные
базы
Базы данных
данных
К.Ю. Поляков, Е.А. Ерёмин, 2013
http://kpolyakov.spb.ru
2. Однотабличная БД
Базы данных, 11 класс2
Однотабличная БД
Альбомы
Код
Название
Группа
Год
Число композиций
1
Реки и мосты
Машина времени
1987
16
2
В круге света
Машина времени
1988
11
3
Группа крови
Кино
1988
11
4
Последний герой Кино
1989
10
?
Что плохо?
дублирование данных
при изменении каких-то данных, возможно,
придется менять несколько записей
нет защиты от ошибок ввода (опечаток)
К.
 Ю. Поляков, Е.А. Ерёмин, 2013
Ю. Поляков, Е.А. Ерёмин, 2013http://kpolyakov.spb.ru
3. Многотабличная БД
Базы данных, 11 класс3
Многотабличная БД
Группы
Код
Название
Год создания
1 Машина времени
1969
2 Кино
1981
Альбомы
Код
Название
Код группы
1 Реки и мосты
1
2 В круге света
1
3 Группа крови
2
4 Последний герой
2
?
К.Ю. Поляков, Е.А. Ерёмин, 2013
Год Число композиций
1987
16
1988
11
1988
11
1989
10
Что улучшилось?
http://kpolyakov.spb.ru
4. Многотабличная БД
Базы данных, 11 класс4
Многотабличная БД
Группы
Код
Название
Год создания
Альбомы
Код
Название
Код группы
Год
Число композиций
Внешний ключ – это неключевое поле таблицы,
связанное с первичным ключом другой таблицы.
убрано дублирование
изменения нужно делать в одном месте
некоторая защита от опечаток (выбор из списка)
усложнение структуры (> 40-50 таблиц – много!)
при поиске нужно «собирать» данные разных таблиц
К.
 Ю. Поляков, Е.А. Ерёмин, 2013
Ю. Поляков, Е.А. Ерёмин, 2013http://kpolyakov.spb.ru
5. Ссылочная целостность
Базы данных, 11 класс5
Ссылочная целостность
?
Удаление группы: что делать с альбомами?
СУБД:
• запретить удаление записи
• выполнить каскадное удаление (удалить все
связанные с ней записи в других таблицах)
• разрешить внести изменения
нарушится ссылочная
целостность!
К.Ю. Поляков, Е.А. Ерёмин, 2013
http://kpolyakov.spb.ru
6. Типы связей между таблицами
Базы данных, 11 класс6
Типы связей между таблицами
ключ
Группы
Код
Название
Год создания
1
Альбомы
Код
Название
Код группы
N
Год
не ключ Число композиций
Связь 1:N – с одной записью в первой таблице могут
быть связаны сколько угодно записей во второй
таблице.
К.Ю. Поляков, Е.А. Ерёмин, 2013
http://kpolyakov.spb.ru
7. Типы связей между таблицами
Базы данных, 11 класс7
Типы связей между таблицами
Связь 1:1 – с одной записью в первой таблице связана
ровно одна запись во второй таблице.

Сотрудники
Код
Фамилия
Имя
1 Иванов
Петр
2 Петров
Сидор
3 Сидоров
Иван
Отчество
Сидорович
Иванович
Петрович
Секретно
Код Зарплата
1
20 000 р.
2
30 000 р.
3
40 000 р.
ключ
Сотрудники
Код
Фамилия
Имя
Отчество
К.Ю. Поляков, Е.А. Ерёмин, 2013
1
1
ключ
Секретно
Код
Зарплата
http://kpolyakov.spb.ru
8. Типы связей между таблицами
Базы данных, 11 класс8
Типы связей между таблицами
Заказы
Номер
Дата
?
N
N
Блюда
Код
Название
Цена
Может ли быть несколько
одинаковых блюд в заказе?
?
Может ли быть одно блюдо в
нескольких заказах?
Связь N:N – с одной записью в первой таблице могут
быть связаны сколько угодно записей во второй
таблице, и наоборот.
в СУБД не
поддерживаются
К.Ю. Поляков, Е.А. Ерёмин, 2013
http://kpolyakov.spb.ru
9. Типы связей между таблицами
Базы данных, 11 класс9
Типы связей между таблицами
Связь N:N
Заказы
Номер
Дата
Заказано
Код
Номер заказа
N Код блюда
1
1
N
Блюда
Код
Название
Цена
Пример:
Заказы
Номер
Дата
1
11.
 12.12
12.122
12.12.12
Код
1
2
3
4
5
6
7
К.Ю. Поляков, Е.А. Ерёмин, 2013
Заказано
Номер
Код
заказа
блюда
1
1
1
3
1
4
2
1
2
2
2
2
2
5
Блюда
Код Название
1 борщ
2 бифштекс
3 гуляш
4 чай
5 кофе
?
Цена
80 р.
110 р.
70 р.
10 р.
50 р.
Состав заказов?
http://kpolyakov.spb.ru
10. Базы данных
10Работа
с многотабличной
Базы
данных
базой данных
К.Ю. Поляков, Е.А. Ерёмин, 2013
http://kpolyakov.spb.ru
11. Многотабличная БД
Базы данных, 11 класс11
Многотабличная БД
Заказы
Номер
Дата
Заказано
Код
Номер заказа
N Код блюда
1
1
N
Блюда
Код
Название
Цена
Пример:
Заказы
Номер
Дата
1
11.12.12
2
12.12.12
Код
1
2
3
4
5
6
7
К.Ю. Поляков, Е.А. Ерёмин, 2013
Заказано
Номер
Код
заказа
блюда
1
1
1
3
1
4
2
1
2
2
2
2
2
5
Блюда
Код Название
1 борщ
2 бифштекс
3 гуляш
4 чай
5 кофе
Цена
80 р.

110 р.
70 р.
10 р.
50 р.
http://kpolyakov.spb.ru
12. Создание таблиц
Базы данных, 11 класс12
Создание таблиц
Заказы
Номер
Дата
Заказано
Код
Номер заказа
Код блюда
INTEGER
К.Ю. Поляков, Е.А. Ерёмин, 2013
Блюда
Код
Название
Цена
DECIMAL
http://kpolyakov.spb.ru
13. Установка связей между таблицами
Базы данных, 11 класс13
Установка связей между таблицами
Сервис – Связи
добавить
все
?
Как определить,
где 1 и N?
перетащить
ЛКМ
К.Ю. Поляков, Е.А. Ерёмин, 2013
http://kpolyakov.spb.ru
14. Заполнение таблиц
Базы данных, 11 класс14
Заполнение таблиц
Заказы
Номер
Дата
1
11.04.13
2
12.04.13
3
12.04.13
Код
1
2
3
4
5
6
7
8
8
К.Ю. Поляков, Е.А. Ерёмин, 2013
Заказано
Номер
Код
заказа
блюда
1
1
1
3
1
4
2
1
2
2
2
2
2
5
3
1
3
5
Блюда
Код Название
1 борщ
2 бифштекс
3 гуляш
4 чай
5 кофе
Цена
80 р.

110 р.
70 р.
10 р.
50 р.
http://kpolyakov.spb.ru
English Русский Правила
столов | Учебное пособие по SQL Документация по data.world
Concepts/data.world Specific/
Введение в работу с несколькими таблицами.
Бывают случаи, когда данные, к которым вы хотели бы получить доступ в запросе, не сохраняются.
в одной таблице, поэтому было бы неплохо иметь возможность объединять несколько таблиц в одну
для запуска запросов ко всем данным в обоих одновременно. Как мы
видел в промежуточном разделе этих документов такую комбинацию таблиц
можно сделать с UNION , но бывают случаи, когда при использовании UNION похож на использование кувалды для забивания гвоздя. Введите data.world
несколько столов. UNION объединяет запросы; мультистолы объединяют столы. С
нескольких таблиц, вы можете легко комбинировать таблицы, если они имеют одинаковые столбцы и
затем выполните запросы к полученной таблице.
UNION можно выполнять запросы
против отдельных таблиц до того, как они будут объединены в одну таблицу СОЕДИНЕНИЕ . При использовании нескольких столов сначала объединяются столы, а затем их можно использовать.
в запросах, как и любая другая таблица.В нашем примере набора данных есть одна таблица для воронки продаж, но есть много таблиц для заказов: по одной на каждый месяц, если быть точным. Чтобы увидеть весь заказ данных за квартал можно выполнить следующий запрос с использованием нескольких таблиц:
ВЫБЕРИТЕ * ОТ [апр_2017_заказов, май_2017_заказов, июнь_2017_заказов] ORDER BY order_value DESC
siyeh/sql-crm-example-data Выполнить запрос Скопировать код
[] уникальны для мультитаблиц и используются для указания
что между ними находится список, разделенный запятыми.
Первые несколько строк результирующей таблицы будут выглядеть так:
| торговый_агент | счет | товар | значение_заказа | дата создания |
|---|---|---|---|---|
| Розалина Дитер | Грувстрит | ГТК 500 | 30 288 | 07. 06.2017 06.2017 |
| Маркита Хансен | Гудсилрон | ГТК 500 | 29 617 | 27.06.2017 |
| Элиз Глюк | Лабдрил | ГТК 500 | 27 385 | 18.06.2017 |
| Элиз Глюк | Ура | ГТК 500 | 30.06.2017 | |
| Розалина Дитер | Y-корпорация | ГТК 500 | 25 288 | 05.04.2017 |
| Элиз Глюк | Плексап | ГТК 500 | 24 949 | 28.06.2017 |
| Элиз Глюк | Лексикволакс | ГТК 500 | 23 746 | 20.04.2017 |
Если таблицы, выбранные для запроса, также имеют похожие имена (как таблицы
в приведенном выше запросе do), вы можете использовать стандартное регулярное выражение Java для
выберите, какие таблицы включить, основываясь на совпадении их имен с образцом. За
Например, чтобы выбрать из всех таблиц в наборе данных, содержащих заказы из
2017, запрос будет записан так:
За
Например, чтобы выбрать из всех таблиц в наборе данных, содержащих заказы из
2017, запрос будет записан так:
ВЫБЕРИТЕ * ОТ [/.*2017_orders/] ORDER BY order_value DESC
siyeh/sql-crm-example-data Выполнить запрос Скопировать код
В стандартном регулярном выражении Java . выступает в качестве подстановочного знака для любого
один символ, а * означает повторение всего, что было до него, любого числа
раз. В регулярном выражении .* одиночный подстановочный знак Java
повторяется, эффективно делая .* регулярное выражение работает так же
как подстановочный знак * в других местах SQL.
Первые несколько строк результатов запроса будут такими:
| торговый_агент | счет | товар | значение_заказа | дата создания |
|---|---|---|---|---|
| Розалина Дитер | Грувстрит | ГТК 500 | 30 288 | 2017-06-07 |
| Розалина Дитер | Грувстрит | ГТК 500 | 30 288 | 2017-06-07 |
| Маркита Хансен | Гудсилрон | ГТК 500 | 29 617 | 27. 06.2017 06.2017 |
| Маркита Хансен | Гудсилрон | ГТК 500 | 29 617 | 27.06.2017 |
| Элиз Глюк | Xx-холдинг | ГТК 500 | 29 220 | 04.12.2017 |
| Элиз Глюк | Xx-холдинг | ГТК 500 | 29 220 | 04.12.2017 |
| Маркита Хансен | Ура | ГТК 500 | 29 166 | 26.09.2017 |
До сих пор мы использовали предложение SELECT * для выбора столбцов, возвращаемых каждым
столов. Этот синтаксис работает, только если все столбцы имеют одинаковые имена.
Однако со временем таблицы растут и меняются, и вам может понадобиться
для сравнения таблиц, в которых есть столбцы с одинаковыми именами и форматами,
а некоторые не совпадают. Единственные столбцы, которые могут быть возвращены в
многотабличный запрос должен совпадать. Если вы хотите включить сопоставление и
несовпадающие столбцы в вашем запросе, вам нужно будет использовать СОЮЗ . Если есть
совпадающие и не совпадающие столбцы, но вы хотите запрашивать только те, которые
match вы можете указать их по имени, как в следующем запросе:
Если есть
совпадающие и не совпадающие столбцы, но вы хотите запрашивать только те, которые
match вы можете указать их по имени, как в следующем запросе:
ВЫБЕРИТЕ агента по продажам,
учетная запись,
Ценность заказа
ОТ [/.*2017_orders/](торговый_агент, учетная запись, значение_заказа)
ORDER BY order_value DESC siyeh/sql-crm-example-data Выполнить запрос Скопировать код
| агент по продажам | счет | значение_заказа |
|---|---|---|
| Розалина Дитер | Грувстрит | 30 288 |
| Маркита Хансен | Гудсилрон | 29 617 |
| Элиз Глюк | Xx-холдинг | 29 220 |
| Маркита Хансен | Ура | 29 166 |
| Элиз Глюк | Ура | 27 971 |
| Элиз Глюк | Лабдрил | 27 385 |
Мультистолы имеют еще одну полезную, уникальную функцию, которую вы можете добавить
столбец к вашим результатам, который содержит имя таблицы, из которой каждый
строка была выбрана. Этот столбец называется
Этот столбец называется имя_таблицы .
ВЫБЕРИТЕ агента по продажам,
учетная запись,
Ценность заказа,
имя_таблицы
ОТ [/.*2017_orders/] КАК заказов
ORDER BY order_value DESC siyeh/sql-crm-example-data Выполнить запрос Скопировать код
| торговый_агент | счет | значение_заказа | имя_таблицы |
|---|---|---|---|
| Розалина Дитер | Грувстрит | 30 288 | июнь_2017_заказы |
| Маркита Хансен | Гудсилрон | 29 617 | jun_2017_orders |
| Элиз Глюк | Xx-холдинг | 29 220 | dec_2017_orders |
| Маркита Хансен | Ура | 29 166 | sep_2017_orders |
| Элиз Глюк | Ура | 27 971 | окт_2017_заказы |
| Элиз Глюк | Лабдрил | 27 385 | июнь_2017_заказы |
| Розалина Дитер | Xx-холдинг | 26 186 | nov_2017_orders |
Далее: федеративные запросы
Введение в федеративные запросы.
Дизайн с одной и несколькими таблицами в Amazon DynamoDB
Это гостевой пост Алекса ДеБри, героя AWS.
Для тех, кто знакомится с Amazon DynamoDB, идея проектирования с одной таблицей является одной из самых головокружительных. В отличие от реляционного понятия наличия таблицы для каждого объекта, таблицы DynamoDB часто включают в себя несколько различных объектов в одной таблице.
Вы можете прочитать документацию DynamoDB, посмотреть доклады re:Invent или другие видеоролики или ознакомиться с моей книгой, чтобы узнать о некоторых шаблонах проектирования с однотабличным дизайном в DynamoDB. Я хочу взглянуть на эту тему на более высоком уровне, уделив особое внимание аргументам как за, так и против дизайна с одной таблицей.
В этом посте мы поговорим об однотабличном дизайне в DynamoDB. Мы начнем с некоторых важных сведений о DynamoDB, которые послужат основой для обсуждения моделирования данных. Затем мы обсудим, когда дизайн с одной таблицей может быть полезен в вашем приложении.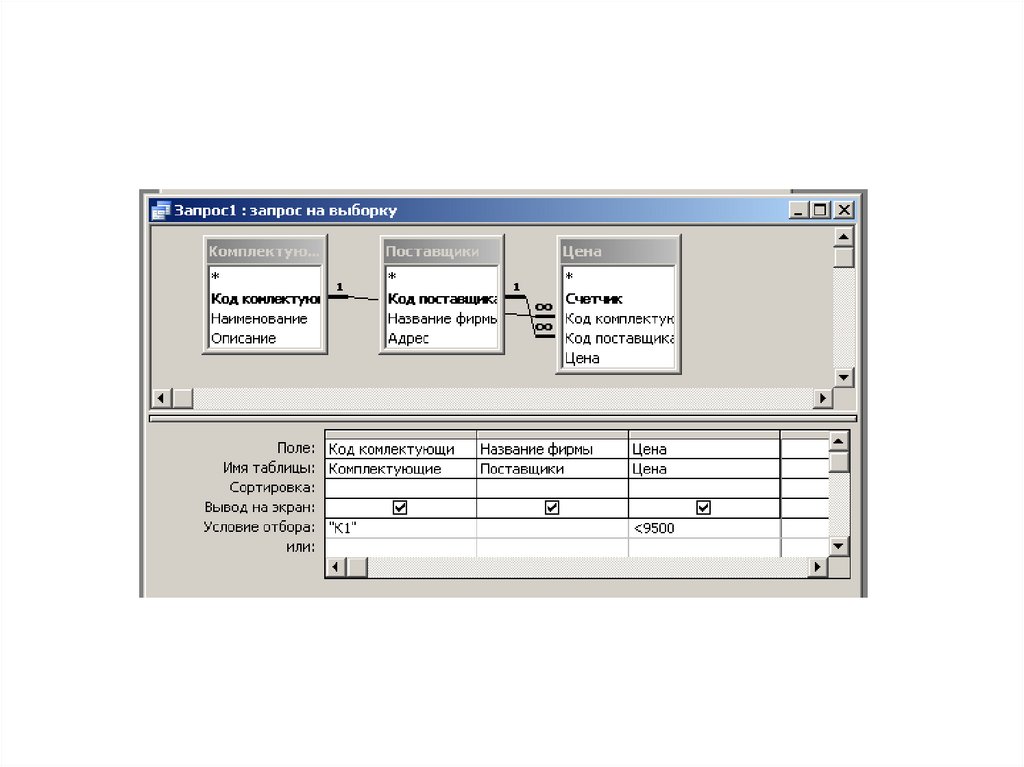 Наконец, мы закончим некоторыми случаями, когда использование нескольких таблиц в DynamoDB может оказаться для вас более предпочтительным.
Наконец, мы закончим некоторыми случаями, когда использование нескольких таблиц в DynamoDB может оказаться для вас более предпочтительным.
Прежде чем мы слишком углубимся в преимущества дизайна с одной и несколькими таблицами, давайте начнем с предыстории DynamoDB. У нас нет места, чтобы исчерпывающе охватить здесь все, но я хочу затронуть несколько моментов, которые имеют отношение к дебатам за одним или несколькими столами.
Пока мы их рассматриваем, есть одна всеобъемлющая тема, которая связывает их вместе: DynamoDB хочет показать вам реальность, чтобы вы могли принять правильное решение для нужд вашего приложения . Большинство баз данных обеспечивают абстракцию над низкоуровневыми битами. Эти абстракции облегчают вам запросы к вашим данным гибкими способами, но они также скрывают от вас важные детали. Поскольку эти детали скрыты, эти базы данных могут масштабироваться непредсказуемым образом или затруднить понимание того, сколько будет стоить ваша база данных по мере роста использования.
Имея это в виду, давайте рассмотрим некоторые отличительные особенности DynamoDB.
Использование двух основных механизмов для последовательного масштабирования
Прежде всего, DynamoDB хочет обеспечить стабильную производительность по мере масштабирования вашего приложения. Независимо от размера вашей базы данных или количества одновременных запросов, DynamoDB стремится обеспечить одинаковое время отклика в миллисекундах для всех операций.
Для этого DynamoDB использует два основных механизма: секционирование и B-дерево. Благодаря этим прочным основам DynamoDB может масштабировать таблицы до петабайт данных и миллионов одновременных запросов.
Начнем с разбиения. В традиционной реляционной базе данных все элементы хранятся на одном узле. По мере роста ваших данных или использования вы можете увеличить размер экземпляра, чтобы не отставать. Однако вертикальное масштабирование имеет свои ограничения, и часто производительность реляционных баз данных ухудшается по мере увеличения размера данных.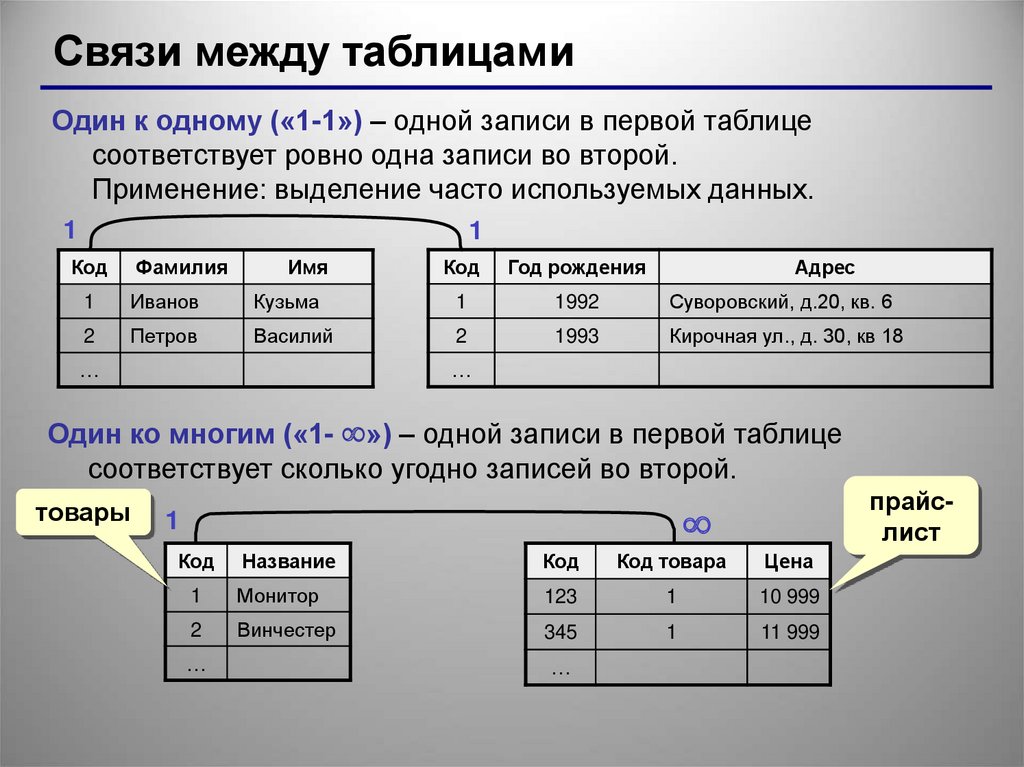
Чтобы избежать этого, DynamoDB использует секционирование для обеспечения горизонтальной масштабируемости. Каждый элемент в вашей таблице DynamoDB будет включать ключ раздела. Под капотом DynamoDB разбивает вашу базу данных на сегменты, называемые 9.0427 разделов (как показано на рисунке 1 ниже), каждый из которых содержит максимум 10 ГБ данных.
Рисунок 1. База данных DynamoDB разделена на три раздела
Когда запрос поступает в DynamoDB, уровень маршрутизатора запросов ищет расположение раздела для данного элемента и направляет запрос в соответствующий раздел для обработки, как показано на рис. 2 ниже.
Рисунок 2: Запрос перенаправлен в соответствующий раздел для обработки
По мере роста вашей таблицы DynamoDB может легко добавлять новые разделы и перераспределять ваши данные в соответствии с вашей рабочей нагрузкой. Подсистема метаданных сохраняет сопоставление диапазонов ключей разделов с узлами хранения и может быстро направить ваш запрос в соответствующий раздел.
Несмотря на то, что секционирование обеспечивает горизонтальное масштабирование, нам часто требуется получить ряд связанных элементов в одном запросе. Вот где вступает в действие второй основной механизм DynamoDB. B-дерево — это эффективный способ хранения отсортированных данных. Это полезно во многих приложениях для работы с данными, таких как сортировка имен пользователей в алфавитном порядке или сортировка заказов электронной коммерции по метке времени заказа.
DynamoDB хранит элементы в каждом разделе в B-дереве, упорядоченном в соответствии с их ключом раздела и (если используется таблицей) ключом сортировки. Это B-дерево обеспечивает логарифмическую временную сложность для поиска ключа. Такое использование B-дерева для подмножеств ваших данных позволяет выполнять высокоэффективные запросы диапазона элементов с одним и тем же ключом раздела.
Прямой доступ к структурам данных с помощью специализированного API
Разделение и B-деревья интересны, но едва ли они уникальны для DynamoDB. Каждая база данных NoSQL использует некоторую форму секционирования для горизонтального масштабирования, и каждая база данных под солнцем использует B-деревья (или близкие родственники) в операциях индексирования.
Каждая база данных NoSQL использует некоторую форму секционирования для горизонтального масштабирования, и каждая база данных под солнцем использует B-деревья (или близкие родственники) в операциях индексирования.
Большая разница между DynamoDB и другими базами данных заключается в том, как DynamoDB изначально предоставляет вам эти структуры данных. Нет планировщика запросов, чтобы разобрать ваш запрос в многоэтапный процесс чтения, объединения и агрегирования данных из разных мест на диске. Кроме того, нет никаких гибких стратегий индексации, кроме основного разделения и настройки B-дерева.
DynamoDB имеет специализированный API, который дает вам прямой доступ к вашим элементам и их базовым структурам данных. Этот API разбит на две основные категории. Существуют основные операции CRUD для отдельных элементов — PutItem, GetItem, UpdateItem и DeleteItem. Для этих операций требуется полный первичный ключ, и вы можете считать их эквивалентными простому поиску в хеш-таблице.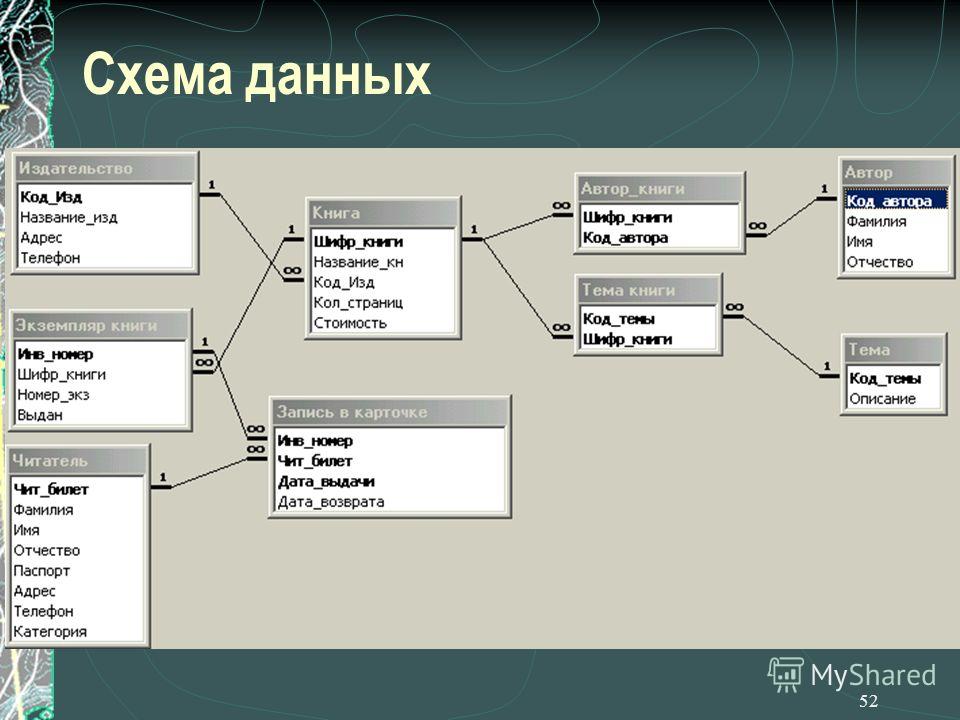
Вторая категория API DynamoDB включает операцию Query, операцию выборки многих , которая позволяет получать несколько элементов в одном запросе. Вы можете использовать это для получения всех заказов для определенного клиента или для получения самых последних показаний датчика IoT.
Но даже операция Query заблокирована, так как вы должны указать точное совпадение ключа раздела, чтобы его можно было направить в один раздел для обслуживания запроса. Он сочетает в себе быстрое нацеливание на основе ключа секции с быстрым поиском и простым последовательным чтением B-дерева, чтобы обеспечить эффективный запрос диапазона при масштабировании.
Обратите внимание на то, чего нет в DynamoDB API. Вы не можете использовать операцию JOIN для объединения нескольких таблиц, как в реляционной базе данных. Вы также не можете использовать агрегации, такие как count, sum, min или max, для сжатия большого количества записей. Эти операции непрозрачны и сильно зависят от количества записей, затронутых запросом, которое не может быть известно заранее.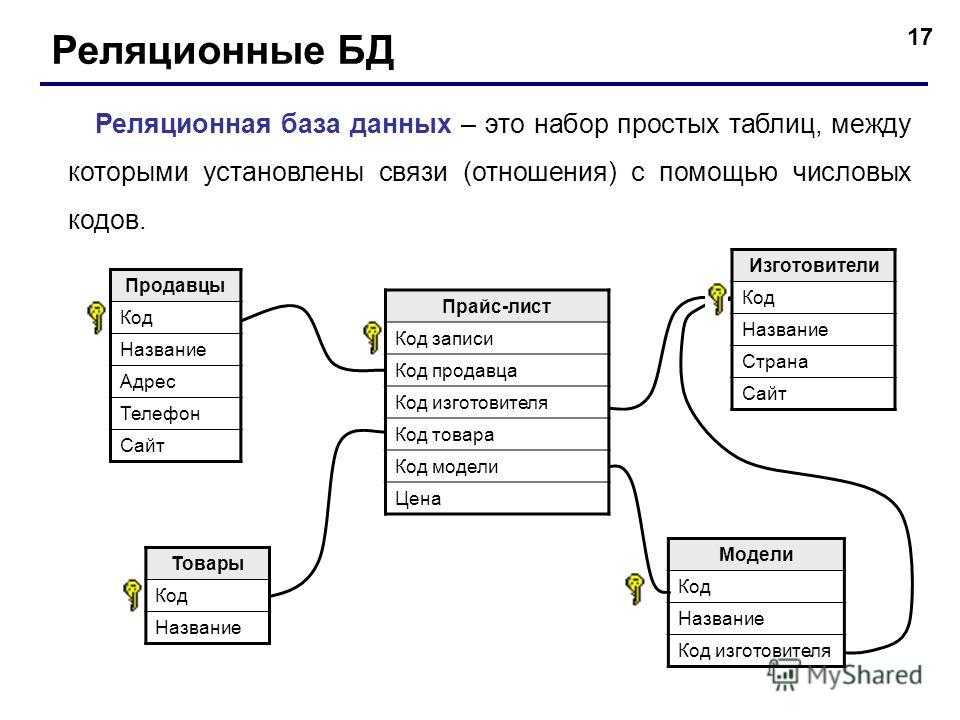 Чтобы обеспечить стабильную производительность при любом масштабе, DynamoDB удаляет конструкции более высокого уровня, такие как соединения и агрегаты, которые добавляют значительную изменчивость.
Чтобы обеспечить стабильную производительность при любом масштабе, DynamoDB удаляет конструкции более высокого уровня, такие как соединения и агрегаты, которые добавляют значительную изменчивость.
Прозрачный биллинг на основе прочитанных и записанных байтов
В предыдущем разделе мы видели, что DynamoDB делает производительность прозрачной для вас, создавая ключевые структуры данных и предоставляя их непосредственно вам. При этом он устраняет магию и непредсказуемость баз данных, использующих непрозрачные планировщики запросов.
DynamoDB делает то же самое с затратами. Запись данных на диск стоит. Стоимость обратного чтения данных с диска. И обе эти затраты увеличиваются с размером данных, которые вы читаете или записываете. DynamoDB делает эти основные расходы понятными для вас, выставляя счета непосредственно за байты, которые вы записываете и читаете из своей таблицы.
Выставление счетов DynamoDB основано на единицах емкости записи (WCU) и единицах емкости чтения (RCU).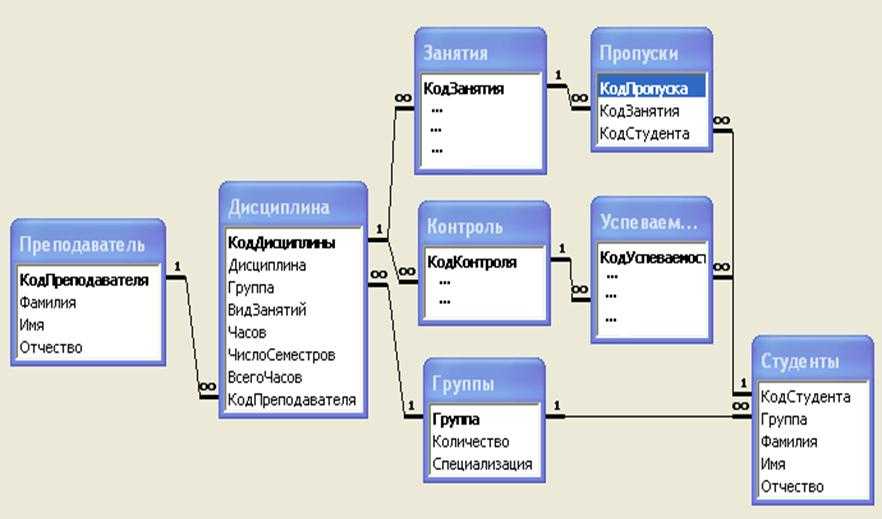 На первый взгляд, один WCU позволяет записывать 1 КБ данных, а один RCU позволяет считывать 4 КБ данных. Вы можете выделить единицы емкости для чтения и записи заранее или использовать выставление счетов по требованию для оплаты каждого запроса на чтение или запись по мере его поступления.
На первый взгляд, один WCU позволяет записывать 1 КБ данных, а один RCU позволяет считывать 4 КБ данных. Вы можете выделить единицы емкости для чтения и записи заранее или использовать выставление счетов по требованию для оплаты каждого запроса на чтение или запись по мере его поступления.
Мне нравится эта прозрачность. Одна вещь, которую я всегда говорю людям, работающим с DynamoDB, — это «посчитайте». Если у вас есть приблизительная оценка того, сколько трафика у вас будет, вы можете посчитать, во что вам это обойдется. Или, если вы выбираете между двумя подходами к моделированию данных, вы можете посчитать, какой из них дешевле.
Как мы увидим в следующем разделе, эта прозрачная модель выставления счетов является одной из причин для использования принципов проектирования с одной таблицей в моделировании данных.
Итак, теперь, когда мы знаем некоторые основы DynamoDB, давайте посмотрим, почему вы можете захотеть использовать однотабличный дизайн в своем приложении.
Прежде чем мы начнем, я хочу отметить, что рекомендация по дизайну с одной таблицей относится к одной службе. Если в вашем приложении несколько сервисов, у каждого из них должна быть своя таблица DynamoDB. Вы должны думать о таблице DynamoDB аналогично экземпляру СУБД — везде, где у вас будет отдельный экземпляр СУБД, у вас должна быть отдельная таблица DynamoDB.
Кроме того, если и существует эмпирическое правило для объединения объектов в одной таблице, то оно таково: Элементы, к которым обращаются вместе, должны храниться вместе . Если вы храните данные в двух разных таблицах СУБД и часто соединяете эти две таблицы, вам следует рассмотреть возможность их хранения в одной денормализованной таблице DynamoDB. Если нет, вы, как правило, можете разделить их, если захотите.
Существует три функциональные причины для использования однотабличной схемы с DynamoDB, а также одна нефункциональная дополнительная причина. Давайте рассмотрим их сейчас.
Использование однотабличной конструкции для реализации материализованных соединений в DynamoDB
В справочном разделе мы видели, что DynamoDB имеет специализированный API и что он удаляет распространенные операции SQL, такие как JOIN.
Но соединения полезны! Если у меня есть отношение «один ко многим» или «многие ко многим», у меня может быть шаблон доступа, при котором я извлекаю один элемент, но мне также нужна информация о связанном родительском элементе.
Когда я впервые начал работать с DynamoDB, я использовал многотабличную систему, аналогичную реляционным базам данных. Поскольку DynamoDB не предоставляет объединений по умолчанию, я просто реализовал соединения в коде своего приложения. Например, представьте, что я хочу получить как клиента, так и заказы клиента для определенного шаблона доступа. Для этого я сначала извлекаю запись о клиенте, получаю ее первичный ключ, а затем извлекаю связанные заказы с отношением внешнего ключа.
Рисунок 3: Извлечение информации из многотабличной схемы
Но это неэффективный способ обработки этого варианта использования. Ввод-вывод из моего приложения в DynamoDB — самая медленная часть обработки моего приложения, и я делаю это дважды, выполняя два отдельных последовательных запроса, как показано на предыдущем рисунке 3.
Если я знаю, что это будет распространенный шаблон доступа в моем приложении, я могу использовать основные структуры данных DynamoDB и API для его оптимизации. Вместо того, чтобы делать отдельные последовательные запросы, я могу предварительно объединить связанных элементов и материализовать объединение заранее. Если я дам элементу «Клиент» тот же ключ раздела, что и связанные элементы «Заказ», они будут расположены в том же разделе и упорядочены в соответствии с ключом сортировки. Затем я могу использовать операцию Query для получения всех элементов в одном эффективном запросе, как показано на рис. 4 ниже.
Рисунок 4: Извлечение информации из однотабличной базы данных
Это канонический пример использования схемы с одной таблицей. Мы можем обрабатывать шаблоны доступа, включающие разнородные элементы, и при этом получать стабильную производительность, ожидаемую от DynamoDB.
Использование конструкции с одной таблицей для снижения затрат на крупные изделия
Вторая причина использования принципов проектирования с одной таблицей — снижение затрат на DynamoDB.
Во многих системах NoSQL рекомендуется создавать более крупные денормализованные документы, содержащие связанные вложенные данные. Это связано с тем, что вы часто извлекаете связанные данные вместе, и более эффективно хранить данные вместе в виде одной записи, а не отдельных записей.
Хотя эта стратегия может быть хорошим советом, будьте осторожны, чтобы не зайти слишком далеко. Помните, что DynamoDB делает затраты разборчивыми для вас, а затраты на чтение и запись масштабируются в зависимости от размера элемента.
Обычно у крупного предмета есть два разных набора атрибутов: несколько больших, медленно меняющихся атрибутов в сочетании с маленькими, быстро изменяющимися атрибутами. Например, подумайте об элементе, представляющем видео на YouTube. Существует много данных о самом видео, таких как различные доступные разрешения и их расположение, описание видео, субтитры и информационные карточки. Это много информации, и она редко меняется.
Тем не менее, видео на YouTube также имеет счетчик, отображающий количество просмотров видео. Это крошечный атрибут — несколько битов данных — но он может увеличиваться тысячи раз в день. Если вы сохранили этот счетчик в том же элементе, что и метаданные видео, вы можете платить несколько WCU каждый раз, когда хотите увеличить количество просмотров. Этот шаблон показан на рисунке 5 ниже.
Рисунок 5: Увеличение атрибута ViewCount как части метаданных элемента
Вместо этого вы можете разбить этот элемент на два элемента: элемент «Видео» и элемент «ВидеоСтатистика». При записи представления вы будете увеличивать только небольшой элемент VideoStats. При отображении видео вы можете получить оба элемента с помощью операции Query, как показано на следующем рисунке 6.
При записи представления вы будете увеличивать только небольшой элемент VideoStats. При отображении видео вы можете получить оба элемента с помощью операции Query, как показано на следующем рисунке 6.
Рисунок 6: Увеличение атрибута ViewCount отдельно от метаданных
С помощью этого шаблона мы можем использовать прозрачность DynamoDB в отношении затрат и бессхемную природу для оптимизации потребностей наших приложений.
Используйте конструкцию с одним столом, чтобы снизить эксплуатационную нагрузку
Третьей причиной использования одной таблицы DynamoDB является снижение операционной нагрузки. Математика здесь проста: чем меньше вещей у вас есть, тем меньше вещей вам нужно контролировать! Логика здесь немного сложнее, особенно в свете улучшений, которые AWS внесла в DynamoDB.
Начнем с сильной версии аргумента. Хотя таблица DynamoDB имеет некоторые общие черты с таблицей в реляционной базе данных, между ними также есть ряд отличий. Самое главное, что каждая таблица DynamoDB — это отдельный элемент инфраструктуры. Эта инфраструктура требует настройки, мониторинга, аварийных сигналов и резервного копирования. Если в вашем приложении 15 различных сущностей и, следовательно, 15 разных таблиц DynamoDB, это может стать бременем.
Объединяя ваши данные в единую таблицу, логично, что ваша операционная нагрузка снижается. Вам нужно отслеживать только одну таблицу, а не 15. Кроме того, существуют ограничения AWS на количество таблиц в регионе AWS плюс количество одновременных операций плоскости управления. Если у вас большая учетная запись или вы выполняете сегментацию таблиц по клиентам, вы можете выйти за эти пределы.
Использование одной таблицы для нескольких сущностей может даже повысить общую производительность таблицы. DynamoDB обеспечивает максимальную пропускную способность на уровне раздела, что позволяет вам превысить предоставленную пропускную способность на короткие периоды с максимальной эффективностью. Если у вас таблица большего размера, ваши элементы будут распределены по большему количеству разделов и, таким образом, уменьшится потенциальный радиус дросселирования.
Наконец, часто верно, что небольшое количество ваших шаблонов доступа доминирует над возможностями чтения и записи вашего приложения. При объединении сущностей в единую таблицу шаблоны доступа, которые используются реже, могут сливаться с избыточной емкостью основного шаблона.
Тем не менее, я думаю, что этот аргумент является незначительным фактором в моем рассмотрении. Обслуживание таблицы DynamoDB довольно простое, и в основном его можно автоматизировать с помощью AWS CloudFormation или других инструментов «инфраструктура как код». Вы можете настроить автоматическое масштабирование, настроить сигналы тревоги или включить резервное копирование с помощью автоматического восстановления на определенный момент времени.
Кроме того, DynamoDB внесла ряд улучшений, которые еще больше уменьшают этот аргумент. В 2018 году DynamoDB объявила об адаптивной емкости, которая распределяет вашу резервную емкость по вашей таблице на разделы, которые в ней больше всего нуждаются. Затем, в 2019 году, DynamoDB анонсировала режим выставления счетов по требованию. Если управление вашей емкостью является бременем, вы можете переключиться в режим по требованию и платить только за те ресурсы, которые вам нужны.
Бонус: заставляет правильно думать о DynamoDB
Как человек, который любит помогать людям изучать DynamoDB и правильно его использовать, моя последняя причина (эгоистичная) касается процесса обучения, а не какого-либо конкретного приложения или эксплуатационных преимуществ. Этот аргумент выглядит следующим образом: акцент на проектировании с одной таблицей в DynamoDB помогает донести мысль о том, что моделирование с помощью DynamoDB отличается от моделирования, которое вы выполняли в реляционной базе данных.
Так много новых пользователей DynamoDB делают то же, что и я — поднимают и переносят свою реляционную модель данных в кучу таблиц DynamoDB. Затем они пишут плохую версию обработчика запросов в своем приложении, выполняя соединения и агрегации в памяти. Такой подход приводит к медленным приложениям, которые не обеспечивают масштабируемость и предсказуемость, которые может обеспечить DynamoDB.
Сообщение людям о том, что большинство служб могут использовать одну таблицу, показывает, что таблицу DynamoDB нельзя напрямую сравнивать с таблицей реляционной базы данных. Пользователи копают немного глубже и понимают, что в первую очередь им нужно сосредоточиться на шаблонах доступа, а не на абстрактной, нормализованной версии своих данных. Они изучают ключевые стратегии моделирования хранилищ данных NoSQL для оптимизации производительности.
По этому же вопросу я думаю, что изучение DynamoDB сделает вас лучшим разработчиком. Поскольку DynamoDB раскрывает вам основы, вы узнаете, что некоторые абстракции, которые вы использовали раньше, не бесплатны. Даже возвращаясь к реляционной базе данных, вы внимательнее присматриваетесь к таким функциям, как соединения и агрегации, понимая, что профиль производительности — это не то же самое, что выбор одной записи по индексированному полю.
В предыдущем разделе мы рассмотрели основные аргументы в поддержку однотабличной схемы в DynamoDB. Однако выбор между одной таблицей и несколькими таблицами имеет нюансы, и бывают ситуации, когда несколько таблиц могут быть для вас хорошим выбором. Давайте рассмотрим некоторые из них ниже.
У вас есть несколько потребностей в DynamoDB Streams
Amazon DynamoDB Streams — одна из моих любимых функций DynamoDB. Я могу получить полностью управляемый поток сбора данных об изменениях, который включает запись каждой операции записи в мою таблицу DynamoDB. Затем я могу обработать этот поток изменений с помощью бессерверных вычислений для обновления агрегаций, обмена событиями между системами или систем аналитики.
Одним из недостатков DynamoDB Streams является ограничение на количество одновременных потребителей. DynamoDB ограничивает вас не более чем двумя одновременными потребителями в потоке DynamoDB. Если у вас есть дополнительные потребители, ваши запросы на потоковую обработку будут регулироваться.
В однотабличном проекте с десятью или более сущностями это ограничение нередко превышается. Возможно, новый элемент Заказа должен инициировать рабочий процесс AWS Step Functions для обработки Заказа, а регистрация нового Клиента должна транслировать регистрацию в другие сервисы через Amazon EventBridge. В какой-то момент вам придется пойти на некоторые жесткие компромиссы, например, добавить больше логики к одному потребителю потока или подключить систему тем FIFO SNS (используя Amazon Simple Notification Service (Amazon SNS) и Amazon Simple Queue Service (Amazon SQS)). очереди для обеспечения разветвления событий при сохранении семантики упорядочения.
В этом случае может быть проще разделить одну таблицу на несколько целевых таблиц. Каждая таблица может содержать меньшее количество сущностей и иметь более сфокусированный потоковый конвейер DynamoDB.
Вы хотите упростить экспорт аналитики
DynamoDB — это система оперативной обработки транзакций (OLTP), предназначенная для большого количества одновременных обновлений отдельных записей. Подумайте об обычных взаимодействиях с пользователем — размещении заказа или комментировании ветки обсуждения. Он отлично справляется с этими рабочими нагрузками и позволяет выполнять атомарные операции, низкую задержку и транзакции ACID при работе с небольшим количеством записей в запросе.
DynamoDB, наоборот, плохо справляется с операциями оперативной аналитической обработки (OLAP). Это внутренние аналитические операции — подумайте о бизнес-аналитике, который хочет знать продажи за неделю по категориям и регионам, или о маркетинговой команде, которая хочет найти самые популярные сообщения в социальных сетях за последний год. Этим операциям не требуется высокая пропускная способность или низкая задержка, но они должны эффективно сканировать большие объемы данных и выполнять вычисления.
Для этих нужд OLAP большинство пользователей DynamoDB экспортируют свои данные во внешнюю аналитическую систему, такую как Amazon Athena или Amazon Redshift, специально созданную для крупномасштабных агрегаций. Однако механизм передачи данных из DynamoDB в вашу систему аналитики может различаться в зависимости от специфики ваших данных.
Некоторые пользователи используют описанную выше функцию DynamoDB Streams для потоковой передачи записей в свою аналитическую базу данных. Часто это предполагает использование Amazon Kinesis Data Firehose для буферизации данных в Amazon Simple Storage Service (Amazon S3) перед загрузкой в Amazon Redshift или просто использование Data Firehose для отправки в S3 для запроса Athena. Этот шаблон лучше работает для больших неизменяемых наборов данных, поскольку полный экспорт таблицы может быть неосуществим, а неизменяемый характер данных хорошо работает с системами типа OLAP.
Но некоторые наборы данных меньше и более изменчивы, и у них другие потребности. Подумайте об объектах User или Customer в приложении. Эти объекты будут важны в вашем хранилище данных для объединения с другими, более крупными таблицами, подобными событиям, чтобы придать событиям цвет. Поскольку эти сущности изменяемы, мы хотим, чтобы наше хранилище данных регулярно обновлялось до текущей версии. Хранилища данных плохо справляются со случайными обновлениями, поэтому обычно лучше экспортировать полную обновленную таблицу для загрузки в вашу систему. Обычно для этого используется либо команда Redshift COPY, либо операция экспорта DynamoDB в S3.
Если у вас есть оба типа данных в одной таблице DynamoDB, это может затруднить выполнение ваших аналитических задач. Выполнение полного экспорта таблицы будет медленнее, так как вы будете экспортировать весь большой неизменяемый набор данных вместе с меньшим изменяемым набором данных. Разделив разные данные на разные таблицы, вы можете настроить конвейер аналитики в соответствии с конкретной формой и потребностями данных.
Вам не нужны льготы, а рассуждать проще о
Последняя причина использования нескольких таблиц в основном просто отрицание случая для дизайна с одной таблицей.
Если ни одно из преимуществ дизайна с одной таблицей для вас не имеет значения — вы не настраиваете материализованные соединения для выборки разнородных элементов в одном запросе, не разбиваете элементы на отдельные части или не боитесь операционной нагрузки — тогда это хорошо пропустить дизайн с одной таблицей, если вам легче рассуждать о дизайне с несколькими таблицами.
Давайте подробнее рассмотрим первое упомянутое выше преимущество моделирования соединений в DynamoDB. Совершенно верно, что вы хотите избежать нормализованной модели, основанной на соединениях внутри приложения и множественных последовательных запросах к DynamoDB. Но это не обязательно означает, что мы должны использовать однотабличный дизайн с материализованными соединениями. Мы могли бы получить большинство тех же преимуществ, структурировав наши таблицы таким образом, чтобы получать оба набора данных параллельно, а не последовательно.
Вспомните наш пример выше, где нам нужно было делать последовательные запросы к DynamoDB — один для получения записи клиента по адресу электронной почты, а другой — для получения заказов по назначенному идентификатору клиента. При переходе на модель проектирования с одной таблицей мы дали обеим сущностям ключ раздела CustomerEmailAddress, чтобы мы могли получить их с помощью одной операции запроса.
Этот переключатель моделирования не требует двух разных таблиц. Если наша таблица Orders использует CustomerEmailAddress в качестве ключа секции, мы можем получать записи Orders одновременно с получением записи Customer.
Это немного медленнее, чем выполнение одного запроса, так как вы будете ждать возврата самого медленного из двух запросов. И вы заплатите немного больше, так как не получите преимущества агрегирования операции Query при расчете RCU. Но, скорее всего, вам все равно придется реализовать что-то подобное, даже в дизайне с одной таблицей, для экземпляров разбиения на страницы, когда клиент извлекает данные за пределы первой страницы. Если эти компромиссы приемлемы для вас и вашего приложения, вы можете выбрать дизайн с несколькими таблицами.
Обратите внимание: это не повод отказываться от изучения работы DynamoDB! Вы не должны моделировать DynamoDB как реляционную базу данных, и вы должны изучить принципы моделирования данных DynamoDB. Почти во всех моделях, которые я делал на протяжении многих лет, мы могли объединить две отдельные таблицы в одну, если это необходимо, потому что они в первую очередь фокусируются на шаблонах доступа и разрабатывают первичные ключи для обработки этих шаблонов доступа.
Заключение
В этом посте мы узнали об однотабличном дизайне DynamoDB. Во-первых, мы начали с некоторых важных сведений о DynamoDB, которые важны для обсуждения единой таблицы. Затем мы увидели несколько причин для использования однотабличного дизайна в DynamoDB. Наконец, мы рассмотрели некоторые причины, по которым вы можете захотеть использовать несколько таблиц в своем приложении.
Мой последний вывод: сначала убедитесь, что вы понимаете принципы моделирования с помощью DynamoDB. DynamoDB не является реляционной базой данных, и вы не должны использовать ее как таковую. Кривая обучения кажется крутой, но на самом деле есть только три или четыре ключевых понятия, которые вам нужно изучить, и все остальное вытекает из этого. Как только вы поймете эти основы, вы сможете принимать более обоснованные решения о том, сколько таблиц использовать в вашем приложении.
Если вы хотите разобраться в моделировании данных DynamoDB, существует множество отличных ресурсов. Я написал «Книгу DynamoDB» — подробное руководство по моделированию данных с помощью DynamoDB, в котором представлены основные концепции и примеры с практическим применением. Я также настоятельно рекомендую документацию для разработчиков DynamoDB, так как команда DynamoDB проделала большую работу, объяснив, как правильно думать о DynamoDB. Не бойтесь погрузиться и попробовать. Сообщество DynamoDB — это дружелюбное, растущее сообщество, и вы найдете много поддержки на этом пути.
Благодарю Джозефа Идзиорека, Джеффа Даффи и Амрита Кумара за их вклад и комментарии во время написания этой записи в блоге.
Об авторах
Алекс ДеБри — герой AWS и автор книги DynamoDB — подробного руководства по моделированию данных с помощью DynamoDB.