Коэффициенты корреляции
Коэффициенты корреляции Содержание > Термины >Коэффициенты корреляции — меры оценки статистической (корреляциронной) взаимосвязи между парой (как правило) или большим количеством переменных. Нужный коэффициент выбирается исходя из типа шкалы переменной. Как правило коэффициент измеряется в интервале от 0 до 1 (не направленная связь для номинальных шкал) или от -1 до +1(направленная связь для порядковых и количественных шкал). Величина коэффициента (по модулю) характеризует тесноту(силу) связи. Знак направленного коэффициента — направление связи: ‘+’ - прямо-пропорциональная связь. ‘-‘ — обратная связь.
| Название коэффициента | Измеряется в интервале | Пояснение | Основное применение | Дополнительное применение |
| Юла | от 0 до 1 | Коэффициент ассоциации | для двух бинарных переменных | Нет |
| Phi | от -1 до +1 | Коэффициент сопряженности для бинарных признаков. Аналогичен коэффициенту Пирсона. Аналогичен коэффициенту Пирсона. |
для двух бинарных переменных | Нет |
| Крамера | от 0 до 1 | Основан на критерии
Хи-квадрат Крамера=корень(X2/(N*min(c-1,r-1)), где X2- Хи-квадрат, N — объем выборки (общее число ответивших на оба вопроса), r- число строк, с — число столбцов. |
для двух номинальных переменных | Все случаи, когда зависимая – номинальная, также
независимая – номинальная, зависимая – порядковая. Для
проверки криволинейности порядковой связи, оцененной по Гамма. Чем
больше Камера в сравнении с модулем Гамма тем сильнее
криволинейность. |
| Пирсона C’ | от 0 до 1 | Основан на критерии
Хи-квадрат C’=корень(X2/(X2+N))/Корень((k-1)/k) где X2- Хи-квадрат, N — объем выборки (общее число ответивших на оба вопроса), к — минимальное из r- число строк, с — число столбцов. |
для двух номинальных переменных | Коэффицент взаимной сопряженности Пирсона C’ обычно оценивает
связь сильнее чем коэффициент Крамера, применяется аналогично
коэффициенту Крамера. |
| Лямбда | от 0 до 1 | Показывает выраженное в процентах улучшение при прогнозировании значения зависимой переменной при данном значении независимой переменной | для двух номинальных переменных | Нет |
| Гамма | от -1 до +1 | Эффективный показатель связи для порядковых переменных. При
интерпретации важно учитывать, что порядок значений должен быть от
меньшего к большему. В противном случае надо менять знак на
противоположный. При
интерпретации важно учитывать, что порядок значений должен быть от
меньшего к большему. В противном случае надо менять знак на
противоположный. |
для двух порядковых переменных | В случае, когда одна из переменных — порядковая а другая — количественная |
| Эта | от 0 до 1 | Значимость проверяется при помощи F критерия Фишера. | независимая — номинальная, зависимая — количественная | Для проверки криволинейности количественной взаимосвязи. Чем больше модуль Эта по сравнению с Пирсона, тем сильнее криволинейность. |
| Пирсона | от -1 до +1 | Классический линейный коэффициент корреляции | для двух количественных переменных | Нет |
Как интерпретировать V Крамера (с примерами)
V Крамера — это мера силы связи между двумя номинальными переменными .
Он находится в диапазоне от 0 до 1, где:
- 0 указывает на отсутствие связи между двумя переменными.
- 1 указывает на идеальную связь между двумя переменными.
Он рассчитывается как:
V Крамера = √ (X 2 /n) / мин (c-1, r-1)
куда:
- X 2 : Статистика хи-квадрат
- n: общий размер выборки
- р: количество рядов
- c: количество столбцов
В следующей таблице показано, как интерпретировать V Крамера на основе степеней свободы:
| Степени свободы | Маленький | Середина | Большой | | — | — | — | — | | 1 | 0,10 | 0,30 | 0,50 | | 2 | 0,07 | 0,21 | 0,35 | | 3 | 0,06 | 0,17 | 0,29 | | 4 | 0,05 | 0,15 | 0,25 | | 5 | 0,04 | 0,13 | 0,22 |
Следующие примеры показывают, как интерпретировать V Крамера в различных ситуациях.
Мы можем использовать следующий код в R для вычисления V Крамера для этих двух переменных:
library (rcompanion) #create table data = matrix(c(6, 9, 8, 5, 12, 10), nrow= 2 ) #view table data [,1] [,2] [,3] [1,] 6 8 12 [2,] 9 5 10 #calculate Cramer's V cramerV(data) Cramer V 0.1671
V Крамера оказывается равным 0,1671 .
Степени свободы будут рассчитываться как:
- df = мин (# строк-1, # столбцов-1)
- дф = мин (1, 2)
- дф = 1
Ссылаясь на приведенную выше таблицу, мы видим, что Крамеровский V, равный 0,1671, и степени свободы = 1 указывают на небольшую (или «слабую») связь между цветом глаз и полом.
Пример 2: Интерпретация V Крамера для таблицы 3×3Предположим, мы хотим узнать, существует ли связь между цветом глаз и предпочтениями политических партий, поэтому мы опрашиваем 50 человек и получаем следующие результаты:
Мы можем использовать следующий код в R для вычисления V Крамера для этих двух переменных:
library (rcompanion) #create table data = matrix(c(8, 2, 4, 5, 8, 6, 6, 3, 8), nrow= 3 ) #view table data [,1] [,2] [,3] [1,] 8 5 6 [2,] 2 8 3 [3,] 4 6 8 #calculate Cramer's V cramerV(data) Cramer V 0.246
V Крамера оказывается равным 0,246 .
Степени свободы будут рассчитываться как:
- df = мин (# строк-1, # столбцов-1)
- дф = мин (2, 2)
- дф = 2
Ссылаясь на приведенную выше таблицу, мы видим, что коэффициент Крамера V, равный 0,246 , и степени свободы = 2 указывают на среднюю (или «умеренную») связь между цветом глаз и предпочтениями политической партии.
Дополнительные ресурсыВ следующих руководствах объясняется, как рассчитать V Крамера в различных статистических программах:
Как рассчитать V Крамера в Excel
Как рассчитать V Крамера в R
Как рассчитать V Крамера в Python
Cramer’s V — StatsTest.com
Поток StatsTest: Связь >> Две категории >> Более двух значений на переменную
Не уверены, что это правильный статистический метод? Используйте рабочий процесс Choose Your StatsTest, чтобы выбрать правильный метод.
Что такое Cramer’s V?
V Крамера используется для понимания силы взаимосвязи между двумя переменными. Чтобы использовать его, интересующие вас переменные должны быть категориальными с двумя или более уникальными значениями для каждой категории. Подробнее см. ниже.
Cramer’s V также известен как Cramer’s Phi.
Допущения для Крамера V
Каждый статистический метод имеет допущения. Предположения означают, что ваши данные должны удовлетворять определенным свойствам, чтобы результаты статистического метода были точными.
Предположения для Крамера V включают:
- Категориальные переменные
Давайте углубимся в то, что это значит.
Категориальный Для этого теста две ваши переменные должны быть категориальными. Категориальная переменная — это переменная, описывающая категорию, которая естественным образом не связана с числом. Примерами категориальных переменных являются цвет глаз, город проживания, порода собаки и т.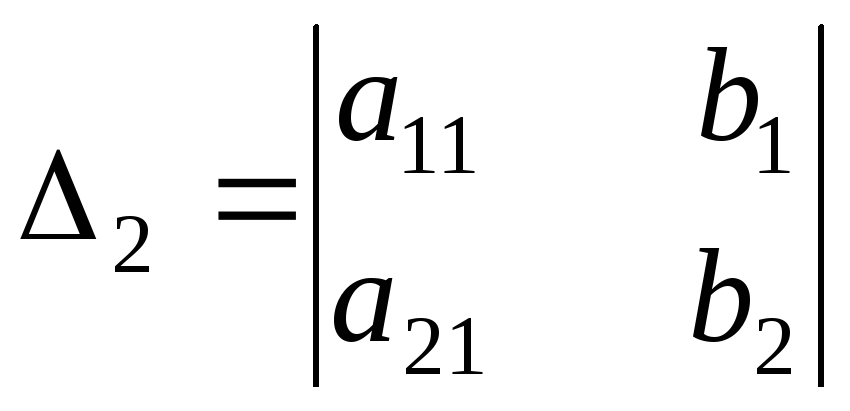 д.
д.
Когда использовать Cramer’s V?
Вы должны использовать Cramer’s V в следующем сценарии:
- Вы хотите узнать взаимосвязь между двумя переменными
- Ваши переменные являются категориальными
- У вас есть два или более уникальных значения для каждой категории
Давайте проясним их, чтобы помочь вам понять, когда использовать Cramer’s V. Другие типы анализа включают проверку различий между двумя переменными или прогнозирование одной переменной с использованием другой переменной (прогнозирование).
Категориальная Категориальная переменная — это переменная, описывающая категорию, которая естественным образом не связана с числом. Примерами категориальных переменных являются цвет глаз, город проживания, тип собаки и т. д. Если одна из ваших переменных является непрерывной, а другая — двоичной, вам следует использовать двухрядную корреляцию точек.
Для выполнения Крамера V в каждой из ваших категориальных переменных должно быть два или более уникальных значения. Если есть только два уникальных значения, то использование коэффициента V Крамера аналогично использованию коэффициента Фи .
Крамер V Пример
Переменная 1 : Политическая партия
Переменная 2 : Любимый музыкальный жанр
В этом примере нас интересует исследование взаимосвязи между политической партией и любимым музыкальным жанром. Для начала мы собираем эти данные у группы людей.
Поскольку обе эти переменные являются категориальными с двумя или более возможными значениями для каждой переменной, мы знаем, что V Крамера является подходящим тестом.
В результате анализа будет получено значение V Крамера и значение p. V Крамера варьируется от 0 до 1, где 0 указывает на отсутствие взаимосвязи, а 1 указывает на полную связь
Значение p представляет вероятность увидеть наши результаты, если между нашими переменными не было фактической связи.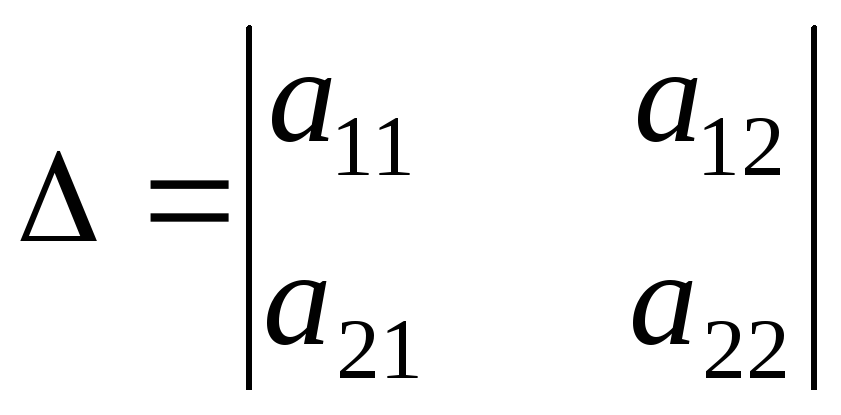 Значение p, меньшее или равное 0,05, означает, что наш результат статистически значим, и мы можем быть уверены, что разница обусловлена не только случайностью.
Значение p, меньшее или равное 0,05, означает, что наш результат статистически значим, и мы можем быть уверены, что разница обусловлена не только случайностью.
Часто задаваемые вопросы
В: Как рассчитать V Крамера в SPSS или R?
A: StatsTest помогает вам каждый раз выбирать правильный статистический метод. Существует множество доступных ресурсов, которые помогут вам понять, как запустить этот метод с вашими данными:
Статья SPSS: https://www.spss-tutorials.com/cramers-v-what-and-why/
SPSS видео: https://www.youtube.com/watch?v=kxM3a42IkE8
R статья: https://jasminedaly.com/tech-short-papers/Example_of_CramersV_Calculation.html
R видео: https://www.youtube.com/watch?v=cMysfAyDkKA
Если вы все еще не можете что-то понять, не стесняйтесь обращаться к нам.
Крамер V — Учебник для начинающих
V Крамера — это число от 0 до 1, которое указывает, насколько сильно связаны две категориальные переменные.
Крамер V — Примеры
Ученый хочет знать, связаны ли предпочтения в музыке с учебой. Он опрашивает 200 студентов, в результате чего получается таблица непредвиденных обстоятельств, показанная ниже.
Эти необработанные частоты как раз то, что нам нужно для всех видов вычислений, но они не показывают большую закономерность. Связь (если она есть) между переменными легче увидеть, если мы проверяем проценты строк вместо необработанных частот. Все становится еще яснее, если мы визуализируем наши проценты в виде гистограмм с накоплением. 92\) = 0. Согласно нашей формуле,  Это означает, что музыкальные предпочтения «ничего не говорят» о специальности. Соответствующая таблица и диаграмма поясняют это.
Это означает, что музыкальные предпочтения «ничего не говорят» о специальности. Соответствующая таблица и диаграмма поясняют это.
Обратите внимание, что частота распределения основных направлений обучения идентична в каждой группе музыкальных предпочтений. Если мы хотим предсказать чью-то специализацию, знание его музыкальных предпочтений нам ничуть не поможет. Наше лучшее предположение: всегда закон или «другое».
Cramer’s V — Умеренная ассоциация
Вторая выборка из 200 учащихся показывает другую закономерность. Проценты строк показаны ниже.
В этой таблице показана некоторая связь между музыкальными предпочтениями и специальностью обучения: частотное распределение занятий различно для групп музыкальных предпочтений. Например, 60% всех студентов, предпочитающих поп-музыку, изучают психологию. Те, кто предпочитает классическую музыку, в основном изучают право. Диаграмма ниже визуализирует нашу таблицу. 92 \приблизительно\) 113;Для расчета этого значения хи-квадрат см.
$$\phi_c = \sqrt{\frac{600}{200(3)}} = 1,$$
, что является максимально возможным значением для Cramer’s V.
Альтернативные меры
- Альтернативным показателем связи для двух номинальных переменных является коэффициент сопряженности . Однако его лучше избегать, так как его максимальное значение зависит от размерности используемой таблицы непредвиденных обстоятельств. 3,4
- Для двух порядковых переменных корреляция Спирмена или тау Кендалла предпочтительнее V Крамера.0034
- Если обе переменные являются дихотомическими (в результате получается таблица 2 на 2), используйте коэффициент фи , который представляет собой просто корреляцию Пирсона, вычисленную для дихотомических переменных.
Крамера V — SPSS
В SPSS Cramer’s V доступен по адресу A анализ D описательная статистика C росстаб. Затем заполните диалоговое окно, как показано ниже.
Затем заполните диалоговое окно, как показано ниже.
Предупреждение: для таблиц больше, чем 2 на 2, SPSS возвращает бессмысленные значения для phi без каких-либо предупреждений или ошибок. Часто они > 1, что невозможно даже для корреляций Пирсона. Как ни странно, вы не можете запросить V Крамера, не получив эти сумасшедшие значения фи.
Заключительные замечания
V Крамера также известен как фи (коэффициент) Крамера 5 . Это расширение вышеупомянутого коэффициента phi для таблиц размером более 2 на 2, поэтому его обозначение как \(\phi_c\). Было высказано предположение, что его заменили на «V», потому что старые компьютеры не могли печатать букву \(\phi\). 3
Спасибо, что прочитали.
Ссылки
- Ван ден Бринк, В.П. и Коэле, П. (2002). Statistiek, deel 3 [Статистика, часть 3]. Амстердам: Бум.
- Филд, А. (2013). Обнаружение статистики с помощью IBM SPSS Ньюбери-Парк, Калифорния: Sage.
