Основные сведения о типах курсоров — JDBC Driver for SQL Server
- Статья
- Чтение занимает 11 мин
Скачать драйвер JDBC
Операции в реляционной базе данных выполняются над множеством строк. Набор строк, возвращаемый инструкцией SELECT, содержит все строки, которые удовлетворяют условиям, указанным в предложении WHERE инструкции. Такой полный набор строк, возвращаемых инструкцией, называется результирующим набором. Приложения не всегда могут эффективно работать с результирующим набором, представляющим единое целое. Им нужен способ, позволяющий обрабатывать одну строку или небольшое их число за один раз. Курсоры являются расширением результирующих наборов, которые предоставляют такой механизм.
Курсоры являются расширением результирующих наборов, которые предоставляют такой механизм.
Курсоры расширяют возможности обработки результирующего набора, выполняя следующие функции:
- позиционируясь на отдельные строки результирующего набора;
- получая одну или несколько строк от текущей позиции в результирующем наборе;
- поддерживая изменение данных в строке, находящейся в текущей позиции в результирующем наборе;
- поддерживая разные уровни видимости изменений, внесенных другими пользователями в данные базы данных, представленных в результирующем наборе.
Примечание
Полное описание типов курсоров SQL Server см. в разделе Типы курсоров.
Спецификация JDBC обеспечивает поддержку однопроходных курсоров и прокручиваемых курсоров, которые могут учитывать или не учитывать изменения, выполненные другими заданиями, а также быть доступными только для чтения или допускать обновление. Эта функциональность обеспечивается классом Microsoft JDBC Driver для SQL ServerSQLServerResultSet.
Драйвер JDBC поддерживает следующие типы результирующих наборов и курсоров вместе с заданными параметрами поведения.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_FORWARD_ONLY (CONCUR_READ_ONLY) | Н/Д | Однонаправленный, только для чтения | direct | переполненные |
Приложение выполняет один (однонаправленный) проход по результирующему набору. Такой проход — это поведение по умолчанию, аналогичное поведению курсора TYPE_SS_DIRECT_FORWARD_ONLY. Драйвер считывает весь результирующий набор с сервера в память во время выполнения инструкции.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_FORWARD_ONLY (CONCUR_READ_ONLY) | Н/Д | Однонаправленный, только для чтения | direct | переполненные |
Приложение выполняет один (однонаправленный) проход по результирующему набору. Такой проход — это поведение по умолчанию, аналогичное поведению курсора TYPE_SS_DIRECT_FORWARD_ONLY. Драйвер считывает весь результирующий набор с сервера в память во время выполнения инструкции.
Такой проход — это поведение по умолчанию, аналогичное поведению курсора TYPE_SS_DIRECT_FORWARD_ONLY. Драйвер считывает весь результирующий набор с сервера в память во время выполнения инструкции.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_FORWARD_ONLY (CONCUR_READ_ONLY) | Н/Д | Однонаправленный, только для чтения | direct | adaptive |
Приложение выполняет один (однонаправленный) проход по результирующему набору. Работает аналогично курсору TYPE_SS_DIRECT_FORWARD_ONLY. Драйвер считывает строки с сервера по мере того как приложение запрашивает строки, что позволяет снизить загрузку памяти на стороне клиента.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_FORWARD_ONLY (CONCUR_READ_ONLY) | Быстрый однопроходный | Однонаправленный, только для чтения | курсор | Н/Д |
Приложение должно выполнить один (однонаправленный) проход по результирующему набору, используя серверный курсор. Работает аналогично курсору TYPE_SS_SERVER_CURSOR_FORWARD_ONLY.
Работает аналогично курсору TYPE_SS_SERVER_CURSOR_FORWARD_ONLY.
Строки извлекаются с сервера блоками, размер которых определяется размером выборки.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_FORWARD_ONLY (CONCUR_UPDATABLE) | Динамический (однопроходный) | Однопроходный, обновляемый | Недоступно | Н/Д |
Приложение должно выполнить один (однонаправленный) проход по результирующему набору, чтобы обновить одну или несколько строк.
Строки извлекаются с сервера блоками, размер которых определяется размером выборки.
По умолчанию размер выборки фиксируется, когда приложение вызывает метод setFetchSize объекта SQLServerResultSet.
Примечание
Драйвер JDBC предоставляет функцию адаптивной буферизации, которая позволяет получать результаты выполнения инструкций от SQL Server по запросу приложения, а не все сразу.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_SCROLL_INSENSITIVE | Статические | Прокручиваемый, без поддержки обновления. Внешние операции обновления, вставки и удаления строк невидимы. | Недоступно | Н/Д |
Приложению требуется моментальный снимок базы данных. Результирующий набор не поддерживает обновление. Поддерживается только CONCUR_READ_ONLY. Все остальные типы параллелизмы в случае использования с этим типом курсора вызывают исключение.
Результирующий набор не поддерживает обновление. Поддерживается только CONCUR_READ_ONLY. Все остальные типы параллелизмы в случае использования с этим типом курсора вызывают исключение.
Строки извлекаются с сервера блоками, размер которых определяется размером выборки.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_SCROLL_SENSITIVE (CONCUR_READ_ONLY) | Keyset | Прокручиваемый, только для чтения. Внешние обновления строки являются видимыми, а операции удаления отображаются как отсутствующие данные. Внешние операции вставки строк невидимы. | Недоступно | Н/Д |
Приложению должны быть видимы только измененные данные для существующих строк.
Строки извлекаются с сервера блоками, размер которых определяется размером выборки.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_SCROLL_SENSITIVE (CONCUR_UPDATABLE, CONCUR_SS_SCROLL_LOCKS, CONCUR_SS_OPTIMISTIC_CC, CONCUR_SS_OPTIMISTIC_CCVAL) | Keyset | Прокручиваемый, обновляемый. Внешние и внутренние операции обновления строк являются видимыми, а операции удаления отображаются как отсутствующие данные. Операции вставки невидимы. | Недоступно | Н/Д |
Приложение может изменять данные в существующих строках с помощью объекта ResultSet. Приложению также должны быть видимы изменения в строках, выполненные другими пользователями вне объекта ResultSet.
Строки извлекаются с сервера блоками, размер которых определяется размером выборки.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_SS_DIRECT_FORWARD_ONLY | Н/Д | Однонаправленный, только для чтения | Н/Д | Полная или адаптивная |
Целое значение = 2003. Предоставляет клиентский курсор только для чтения с полной буферизацией. Серверный курсор не создается.
Поддерживается только тип параллелизма CONCUR_READ_ONLY.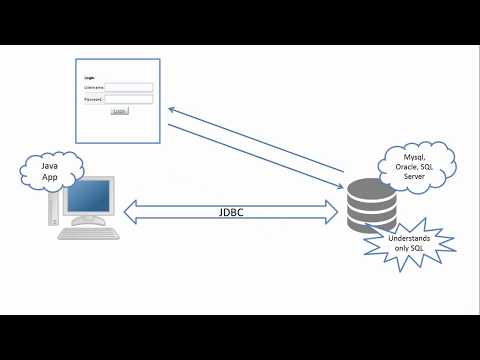 Все остальные типы параллелизмы в случае использования с этим типом курсора вызывают исключение.
Все остальные типы параллелизмы в случае использования с этим типом курсора вызывают исключение.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_SS_SERVER_CURSOR_FORWARD_ONLY | Быстрый однопроходный | Однонаправленный | Недоступно | Н/Д |
Целое значение = 2004. Быстрый режим, доступ ко всем данным осуществляется с помощью серверного курсора. В случае использования с типом параллелизма CONCUR_UPDATABLE возможно обновление.
Строки извлекаются с сервера блоками, размер которых определяется размером выборки.
Чтобы включить адаптивную буферизацию в этом случае, приложение должно явно вызвать метод setResponseBuffering объекта SQLServerStatement, указав значение типа String («adaptive» ). Пример кода можно найти в статье Пример обновления большого объема данных.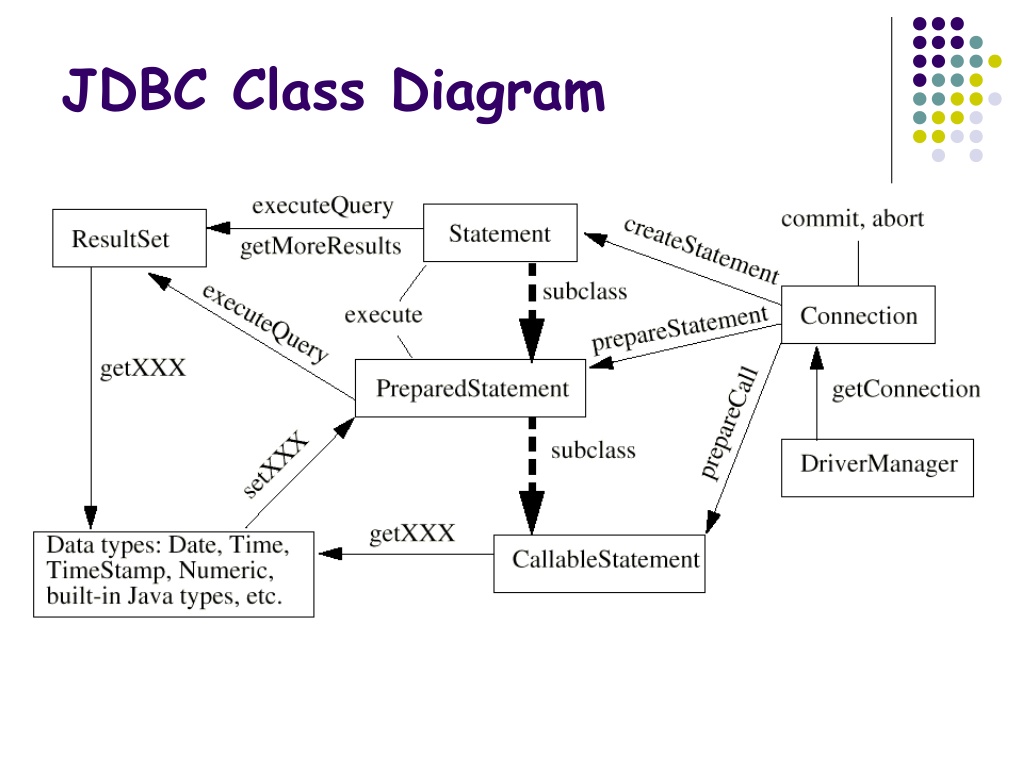
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_SS_SCROLL_STATIC | Статические | Не отражает обновления, выполненные другими пользователями. | Недоступно | Н/Д |
Целое значение = 1004. Приложению требуется моментальный снимок базы данных. Это синоним SQL Server для типа JDBC TYPE_SCROLL_INSENSITIVE, который имеет те же параметры параллелизма по умолчанию.
Строки извлекаются с сервера блоками, размер которых определяется размером выборки.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_SS_SCROLL_KEYSET (CONCUR_READ_ONLY) | Keyset | Прокручиваемый, только для чтения. Внешние обновления строки являются видимыми, а операции удаления отображаются как отсутствующие данные. Внешние операции вставки строк невидимы. | Недоступно | Н/Д |
Целое значение = 1005. Приложению должны быть видимы только измененные данные для существующих строк. Это синоним SQL Server для типа JDBC TYPE_SCROLL_SENSITIVE, который имеет те же параметры параллелизма по умолчанию.
Строки извлекаются с сервера блоками, размер которых определяется размером выборки.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_SS_SCROLL_KEYSET (CONCUR_UPDATABLE, CONCUR_SS_SCROLL_LOCKS, CONCUR_SS_OPTIMISTIC_CC, CONCUR_SS_OPTIMISTIC_CCVAL) | Keyset | Прокручиваемый, обновляемый. Внешние и внутренние операции обновления строк являются видимыми, а операции удаления отображаются как отсутствующие данные. Операции вставки невидимы. | Недоступно | Н/Д |
Целое значение = 1005. Приложение должно изменять данные, или для него должны быть видимыми измененные данные для существующих строк. Это синоним SQL Server для типа JDBC TYPE_SCROLL_SENSITIVE, который имеет те же параметры параллелизма по умолчанию.
Приложение должно изменять данные, или для него должны быть видимыми измененные данные для существующих строк. Это синоним SQL Server для типа JDBC TYPE_SCROLL_SENSITIVE, который имеет те же параметры параллелизма по умолчанию.
Строки извлекаются с сервера блоками, размер которых определяется размером выборки.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_SS_SCROLL_DYNAMIC (CONCUR_READ_ONLY) | Динамический | Прокручиваемый, только для чтения. Внешние операции обновления и вставки строк являются видимыми, а операции удаления представляются как временно отсутствующие данные в текущем буфере выборки. | Недоступно | Н/Д |
Целое значение = 1006. Приложению должны быть видимы измененные данные для существующих строк, а также вставленные и обновленные строки за время существования курсора.
Строки извлекаются с сервера блоками, размер которых определяется размером выборки.
| Тип результирующего набора (курсора) | Тип курсора SQL Server | Характеристики | Выбор метода | Режим буферизации |
|---|---|---|---|---|
| TYPE_SS_SCROLL_DYNAMIC (CONCUR_UPDATABLE, CONCUR_SS_SCROLL_LOCKS, CONCUR_SS_OPTIMISTIC_CC, CONCUR_SS_OPTIMISTIC_CCVAL) | Динамический | Прокручиваемый, обновляемый. Внешние и внутренние операции обновления и вставки строк являются видимыми, а операции удаления представляются как временно отсутствующие данные в текущем буфере выборки. | Недоступно | Н/Д |
Целое значение = 1006. Приложение может изменять данные для существующих строк, а также вставлять и удалять строки с помощью объекта ResultSet. Приложению также должны быть видимы изменения в строках, операции вставки и удаления, выполненные другими пользователями вне объекта ResultSet.
Строки извлекаются с сервера блоками, размер которых определяется размером выборки.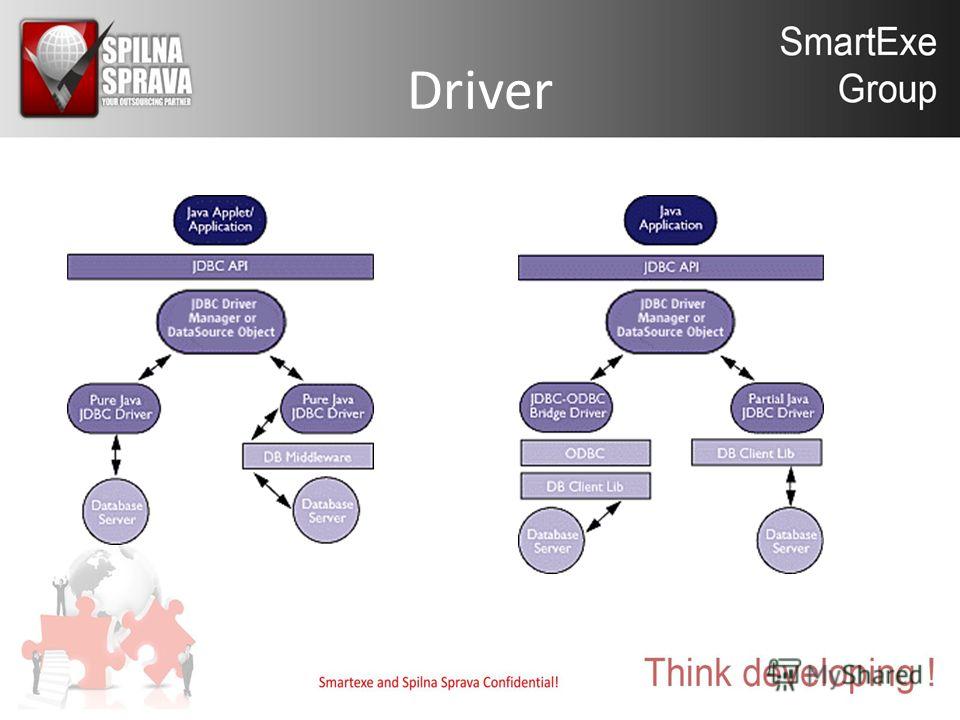
Позиционирование курсоров
Курсоры TYPE_FORWARD_ONLY, TYPE_SS_DIRECT_FORWARD_ONLY и TYPE_SS_SERVER_CURSOR_FORWARD_ONLY поддерживают только метод позиционирования next.
Курсор TYPE_SS_SCROLL_DYNAMIC не поддерживает методы absolute и getRow. Действие метода absolute можно приблизительно заменить сочетанием вызова методов first и relative для динамических курсоров.
Метод getRow поддерживается только курсорами TYPE_FORWARD_ONLY, TYPE_SS_DIRECT_FORWARD_ONLY, TYPE_SS_SERVER_CURSOR_FORWARD_ONLY, TYPE_SS_SCROLL_KEYSET и TYPE_SS_SCROLL_STATIC. Метод getRow для всех типов однопроходных курсоров возвращает количество строк, считанных в курсоре на данный момент.
Примечание
Если приложение выполняет неподдерживаемый вызов позиционирования курсора или неподдерживаемый вызов метода getRow, возникает исключение с сообщением «Запрошенная операция не поддерживается с этим типом курсора».
Доступ к удаленным строкам предоставляется только курсорами TYPE_SS_SCROLL_KEYSET и эквивалентными курсорами TYPE_SCROLL_SENSITIVE. Если курсор позиционируется в удаленной строке, то значения столбцов недоступны, а метод rowDeleted возвращает значение True. Вызовы метода get<Type> приводят к созданию исключения с сообщением «Не удается получить значение из удаленной строки». Удаленные строки нельзя обновлять. Если вызвать метод update<Type> для удаленной строки, создается исключение с сообщением «Не удается обновить удаленную строку». Курсор TYPE_SS_SCROLL_DYNAMIC работает аналогичным образом, пока не выходит за пределы текущего буфера выборки.
Если курсор позиционируется в удаленной строке, то значения столбцов недоступны, а метод rowDeleted возвращает значение True. Вызовы метода get<Type> приводят к созданию исключения с сообщением «Не удается получить значение из удаленной строки». Удаленные строки нельзя обновлять. Если вызвать метод update<Type> для удаленной строки, создается исключение с сообщением «Не удается обновить удаленную строку». Курсор TYPE_SS_SCROLL_DYNAMIC работает аналогичным образом, пока не выходит за пределы текущего буфера выборки.
Однопроходные и динамические курсоры предоставляют доступ к удаленным строкам аналогичным образом, но только при условии, что курсоры остаются доступными в буфере выборки. Для однопроходных курсоров такое поведение реализуется довольно просто. Для динамических курсоров ситуация усложняется в случае, когда размер выборки превышает 1. Приложение может перемещать курсор в обоих направлениях в пределах окна, заданного буфером выборки, однако удаленная строка будет исчезать, когда курсор будет покидать исходный буфер выборки, в котором была обновлена строка.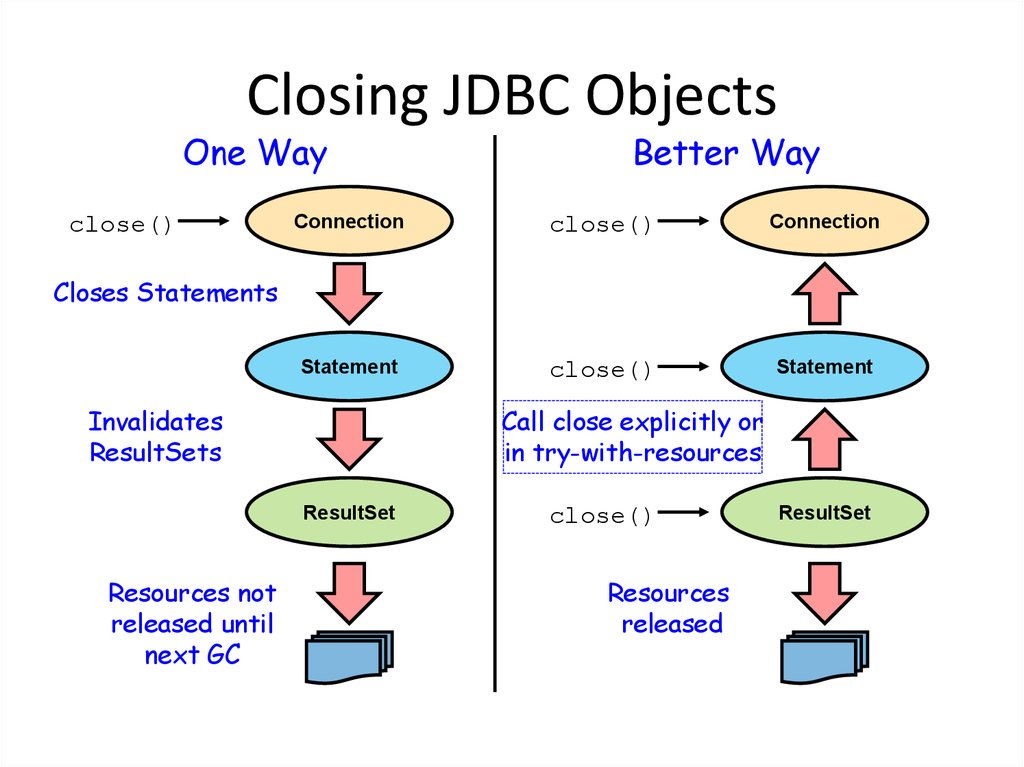 Если временно удаленные строки не должны отображаться приложению, использующему динамические курсоры, следует использовать относительную выборку (0).
Если временно удаленные строки не должны отображаться приложению, использующему динамические курсоры, следует использовать относительную выборку (0).
Если значения ключа для строки курсора TYPE_SS_SCROLL_KEYSET или TYPE_SCROLL_SENSITIVE обновляются с помощью курсора, то строка сохраняет исходную позицию в результирующем наборе независимо от того, отвечает ли обновленная строка условиям выборки курсора. Если строка обновляется вне курсора, то удаленная строка будет выводиться в исходной позиции строки, однако будет видна в курсоре только в том случае, если там ранее присутствовала другая строка с новыми значениями ключа, но затем была удалена.
Для динамических курсоров обновленные строки будут сохранять свои позиции в буфере выборки, пока курсор не покинет окно, определенное буфером выборки. Обновленные строки могут позже появляться в других позициях в результирующем наборе или полностью исчезать. Приложения, которые должны избегать временной потери согласованности в результирующем наборе, должны использовать размер выборки 1 (по умолчанию используется 8 строк для параллелизма CONCUR_SS_SCROLL_LOCKS и 128 строк для остальных режимов параллелизма).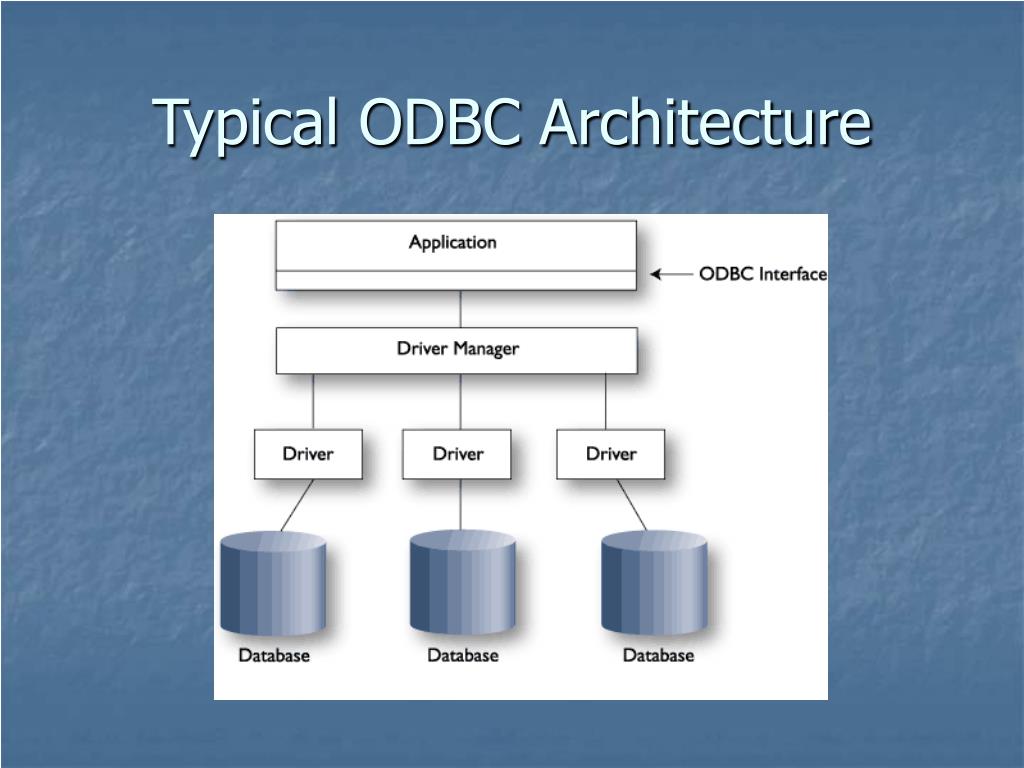
Преобразование курсоров
Иногда SQL Server может реализовать тип курсора, отличный от запрошенного. Это называется неявным преобразованием курсора (или ухудшением курсора).
В SQL Server 2000 (8.x) при обновлении данных с использованием результирующего набора с параметрами ResultSet.TYPE_SCROLL_SENSITIVE и ResultSet.CONCUR_UPDATABLE создается исключение с сообщением «Этот курсор имеет тип READ ONLY». Это исключение создается, так как SQL Server 2000 (8.x) выполнил неявное преобразование курсора для этого результирующего набора и не вернул запрошенный обновляемый курсор.
Существует два возможных решения этой проблемы.
- Убедитесь, что базовая таблица содержит первичный ключ.
- Для создания инструкции используйте SQLServerResultSet.TYPE_SS_SCROLL_DYNAMIC вместо ResultSet.TYPE_SCROLL_SENSITIVE.
Обновление курсоров
Обновления на месте поддерживаются для курсоров, если тип курсора и тип параллелизма поддерживают обновления. Если курсор не размещен в обновляемой строке в результирующем наборе (не удалось вызвать метод get<Type>), вызов метода update<Type> вызовет исключение с сообщением «В результирующем наборе отсутствует текущая строка». Спецификация JDBC указывает, что исключение возникает при вызове метода update для столбца курсора CONCUR_READ_ONLY. В ситуациях, когда строка недоступна для обновления, например из-за конфликта оптимистичного параллелизма в случае конкурирующих операций обновления или удаления, исключение может не создаваться до вызова метода insertRow, updateRow или deleteRow.
Спецификация JDBC указывает, что исключение возникает при вызове метода update для столбца курсора CONCUR_READ_ONLY. В ситуациях, когда строка недоступна для обновления, например из-за конфликта оптимистичного параллелизма в случае конкурирующих операций обновления или удаления, исключение может не создаваться до вызова метода insertRow, updateRow или deleteRow.
После вызова метода update<Type> доступ к столбцу с помощью get<Type> будет невозможен до вызова updateRow или cancelRowUpdates. Такое поведение позволяет избежать проблем, когда столбец обновляется с использованием типа, который отличается от типа, возвращаемого сервером, а последующие вызовы метода считывания могут привести к преобразованиям типа на клиентской стороне, которые дают неточные результаты. Вызовы get<Type> создают исключение с сообщением «Доступ к обновляемым столбцам невозможен до вызова метода updateRow() или cancelRowUpdates()».
Примечание
Если метод updateRow вызван, когда столбцы не обновлены, драйвер JDBC вызывает исключение с сообщением «Метод updateRow() вызван, когда столбцы не обновлены».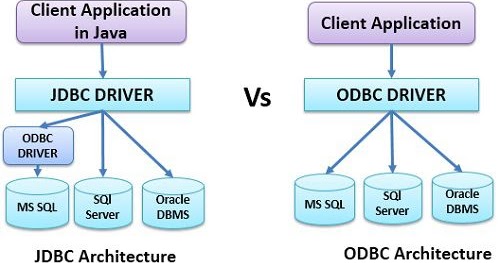
После вызова метода moveToInsertRow исключение будет создаваться в случае вызова для результирующего набора любого метода, кроме методов get<Type>, update<Type>, insertRow и методов позиционирования курсора (включая moveToCurrentRow). Метод moveToInsertRow фактически переводит результирующий набор в режим вставки, а методы позиционирования курсора отменяют режим вставки. Вызовы относительного позиционирования курсора перемещают курсор относительно позиции, в которой он находился перед вызовом moveToInsertRow. После вызова позиционирования курсора ожидаемая позиция назначения становится новой позицией курсора.
Если вызов позиционирования курсора, выполненный в режиме вставки, не завершается успешно, то позицией курсора после сбоя вызова будет исходная позиция курсора до вызова метода moveToInsetRow. Если метод insertRow завершается сбоем, то курсор остается в строке вставки в режиме вставки.
Столбцы в строке вставке первоначально находятся в неинициализированном состоянии. Вызовы метода update<Type> устанавливают инициализированное состояние столбца. Вызов метода get<Type> для неинициализированного столбца приводит к созданию исключения. Вызов метода insertRow возвращает все столбцы в строке вставки в неинициализированное состояние.
Вызовы метода update<Type> устанавливают инициализированное состояние столбца. Вызов метода get<Type> для неинициализированного столбца приводит к созданию исключения. Вызов метода insertRow возвращает все столбцы в строке вставки в неинициализированное состояние.
Если в момент вызова метода insertRow какие-либо столбцы не инициализированы, то вставляется значение по умолчанию для столбца. Если значение по умолчанию отсутствует, но столбец допускает значение NULL, то вставляется значение NULL. Если отсутствует значение по умолчанию, и столбец не допускает значения NULL, то сервер возвращает ошибку, и создается исключение.
Примечание
Вызовы метода getRow в режиме вставки возвращают значение 0.
Драйвер JDBC не поддерживает позиционированные операции обновления и удаления. В соответствии со спецификацией JDBC метод setCursorName не имеет эффекта, и в случае вызова метода getCursorName создается исключение.
Статические курсоры и курсоры, доступные только для чтения, никогда не поддерживают обновление.
SQL Server ограничивает использование серверных курсоров единственным результирующим набором. Если пакет или хранимая процедура содержит несколько инструкций, то необходимо использовать клиентский однопроходный курсор, доступный только для чтения.
См. также раздел
Управление результирующими наборами с помощью JDBC Driver
JDBC — Введение — CoderLessons.com
JDBC расшифровывается как J ava D ata base Cnectivity, который является стандартным Java API для независимой от базы данных связи между языком программирования Java и широким спектром баз данных.
Библиотека JDBC включает API для каждой из задач, упомянутых ниже, которые обычно связаны с использованием базы данных.
Создание подключения к базе данных.
Создание операторов SQL или MySQL.
Выполнение запросов SQL или MySQL в базе данных.
Просмотр и изменение полученных записей.
Создание подключения к базе данных.![]()
Создание операторов SQL или MySQL.
Выполнение запросов SQL или MySQL в базе данных.
Просмотр и изменение полученных записей.
По сути, JDBC – это спецификация, которая предоставляет полный набор интерфейсов, которые обеспечивают портативный доступ к базовой базе данных. Java может использоваться для написания различных типов исполняемых файлов, таких как –
Java-приложения
Java апплеты
Сервлеты Java
Java ServerPages (JSP)
Enterprise JavaBeans (EJB).
Все эти различные исполняемые файлы могут использовать драйвер JDBC для доступа к базе данных и использовать преимущества сохраненных данных.
JDBC предоставляет те же возможности, что и ODBC, позволяя программам на Java содержать независимый от базы данных код.
Предварительно
Прежде чем двигаться дальше, вам необходимо хорошо понять следующие две темы:
Core JAVA Программирование
База данных SQL или MySQL
Core JAVA Программирование
База данных SQL или MySQL
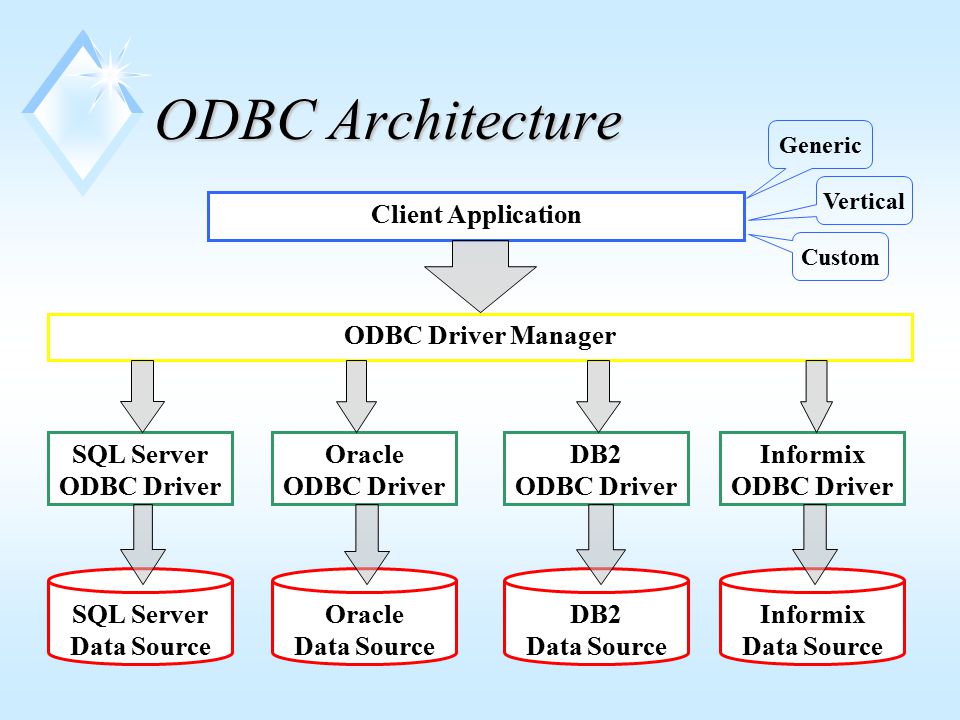
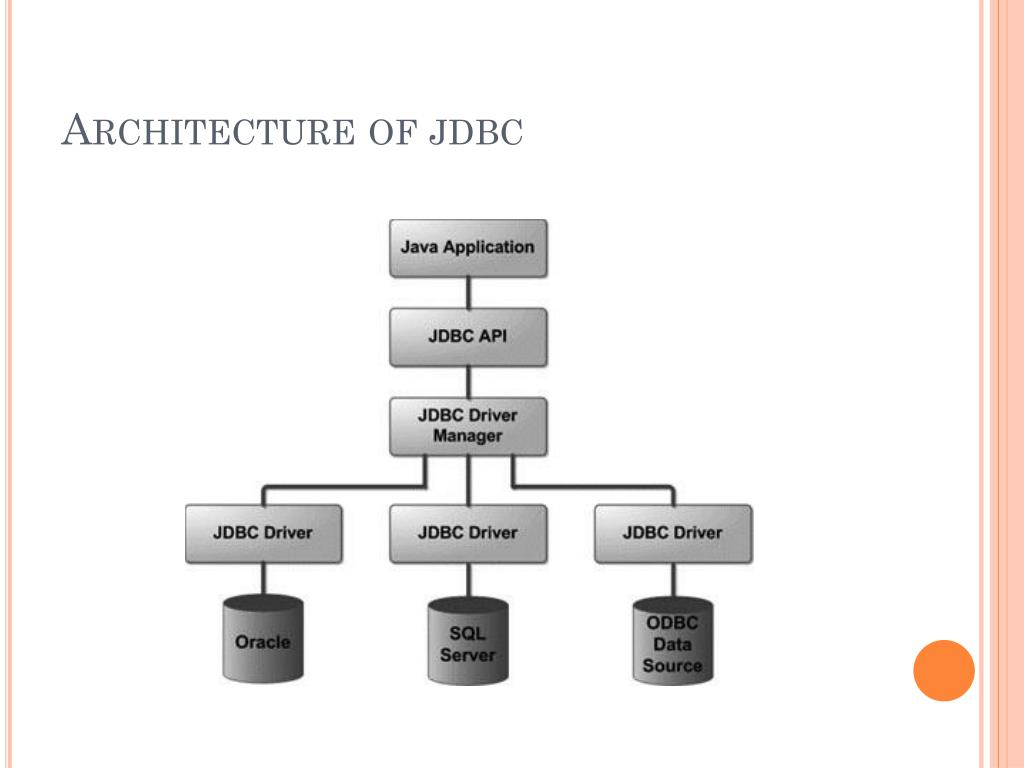
Архитектура JDBC
JDBC API поддерживает как двухуровневые, так и трехуровневые модели обработки для доступа к базе данных, но в целом архитектура JDBC состоит из двух уровней:
JDBC API: обеспечивает соединение между приложением и диспетчером JDBC.
API драйвера JDBC: это поддерживает соединение диспетчера JDBC с драйвером.
JDBC API использует диспетчер драйверов и драйверы для конкретных баз данных, чтобы обеспечить прозрачное подключение к разнородным базам данных.
Диспетчер драйверов JDBC гарантирует, что для доступа к каждому источнику данных используется правильный драйвер. Диспетчер драйверов способен поддерживать несколько одновременных драйверов, подключенных к нескольким разнородным базам данных.
Ниже приведена архитектурная схема, на которой показано расположение диспетчера драйверов относительно драйверов JDBC и приложения Java.
Общие компоненты JDBC
JDBC API предоставляет следующие интерфейсы и классы –
DriverManager: этот класс управляет списком драйверов базы данных. Сопоставляет запросы на подключение из приложения Java с соответствующим драйвером базы данных, используя субпротокольный протокол Первый драйвер, который распознает некоторый подпротокол в JDBC, будет использоваться для установления соединения с базой данных.
Драйвер: этот интерфейс обрабатывает связь с сервером базы данных. Вы будете взаимодействовать напрямую с объектами Driver очень редко. Вместо этого вы используете объекты DriverManager, которые управляют объектами этого типа. Он также раскрывает подробности, связанные с работой с объектами Driver.
Соединение: Этот интерфейс со всеми методами для связи с базой данных. Объект соединения представляет контекст связи, т. Е. Вся связь с базой данных происходит только через объект соединения.
Оператор: объекты, созданные из этого интерфейса, используются для отправки операторов SQL в базу данных. Некоторые производные интерфейсы принимают параметры в дополнение к выполнению хранимых процедур.
ResultSet: эти объекты содержат данные, извлеченные из базы данных после выполнения запроса SQL с использованием объектов Statement. Он действует как итератор, чтобы позволить вам перемещаться по его данным.
SQLException: этот класс обрабатывает любые ошибки, которые происходят в приложении базы данных.
DriverManager: этот класс управляет списком драйверов базы данных. Сопоставляет запросы на подключение из приложения Java с соответствующим драйвером базы данных, используя субпротокольный протокол Первый драйвер, который распознает некоторый подпротокол в JDBC, будет использоваться для установления соединения с базой данных.
Драйвер: этот интерфейс обрабатывает связь с сервером базы данных. Вы будете взаимодействовать напрямую с объектами Driver очень редко. Вместо этого вы используете объекты DriverManager, которые управляют объектами этого типа. Он также раскрывает подробности, связанные с работой с объектами Driver.
Соединение: Этот интерфейс со всеми методами для связи с базой данных. Объект соединения представляет контекст связи, т. Е. Вся связь с базой данных происходит только через объект соединения.
Оператор: объекты, созданные из этого интерфейса, используются для отправки операторов SQL в базу данных. Некоторые производные интерфейсы принимают параметры в дополнение к выполнению хранимых процедур.
ResultSet: эти объекты содержат данные, извлеченные из базы данных после выполнения запроса SQL с использованием объектов Statement. Он действует как итератор, чтобы позволить вам перемещаться по его данным.
SQLException: этот класс обрабатывает любые ошибки, которые происходят в приложении базы данных.
Пакеты JDBC 4.0
Java.sql и javax.sql являются основными пакетами для JDBC 4.0. Это последняя версия JDBC на момент написания данного руководства. Он предлагает основные классы для взаимодействия с вашими источниками данных.
Новые функции в этих пакетах включают изменения в следующих областях:
Автоматическая загрузка драйвера базы данных.
Улучшения обработки исключений.
Расширенная функциональность BLOB / CLOB.
Улучшения интерфейса подключения и оператора.
Поддержка национальных символов.
SQL ROWID доступ.
Поддержка типов данных SQL 2003 XML.
Аннотации.
JDBC vs JPA
В мире разработки программного обеспечения очень любят аббревиатуры. И работа с базами данных в Java — не исключение.
Наличие множества вариантов работы с БД может запутать: что же я использую на самом деле? Все используют JPA? Мне тоже стоит его использовать? Но я еще слышал о Spring Data JDBC. А как насчет Spring Data JPA?
В этой статье мы поговорим о JDBC и JPA: истории появления и некоторых особенностях.
Давным-давно был JDBC
JDBC — это Java Database Connectivity API. Это старый стандарт, уходящий корнями в 1997 год во времена Java 1.1. И этот API сослужил нам добрую службу.
Это «старые данные». Понятно?Абсолютно все библиотеки, взаимодействующие с базами данных, используют JDBC. В этом есть как преимущества, так и недостатки.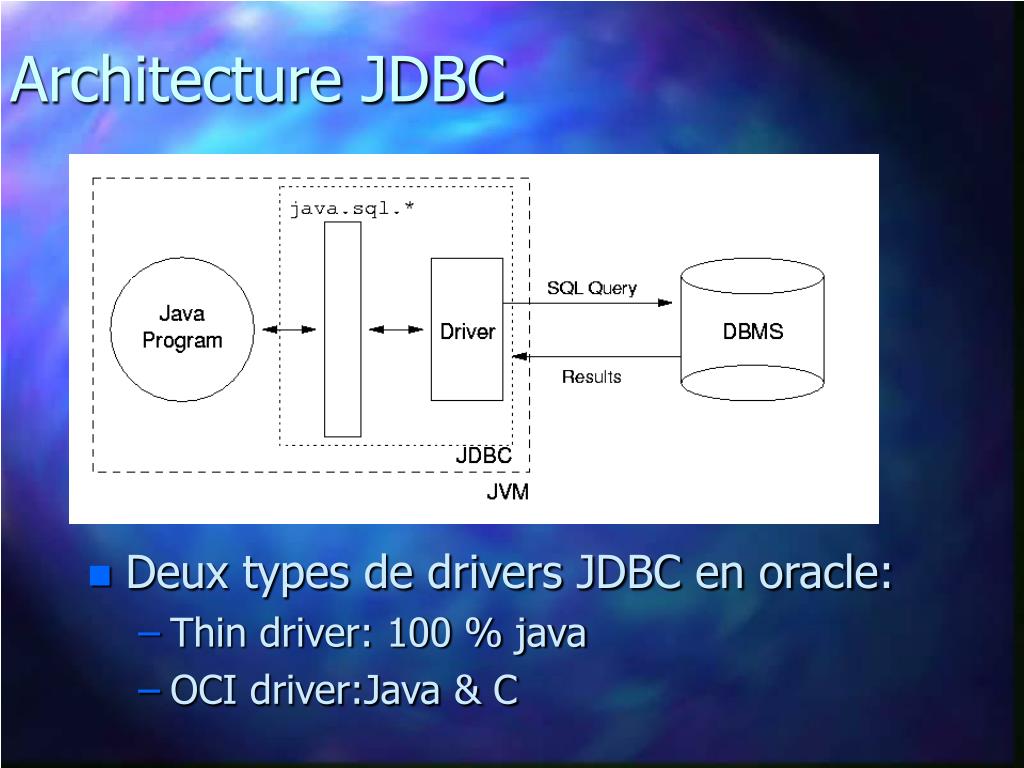 По сути, JDBC — это Java-реализация стандартного подхода к работе с базами данных, реализованного во всех подобных технологиях:
По сути, JDBC — это Java-реализация стандартного подхода к работе с базами данных, реализованного во всех подобных технологиях:
Открыть соединение.
Открыть курсор.
Отправить запрос.
Обработать набор данных.
Закрыть результирующий набор / курсор.
Закрыть соединение.
И вы наверняка сталкивались с ситуацией, когда, выполняя десятки запросов, забывали закрыть соединение. А шесть недель спустя получали ужасный стек-трейс из-за того, что каким-то образом в базе данных закончились соединения или курсоры.
Вы быстро понимали в чем дело, чинили и отправляли в релиз. Но через восемь недель — та же самая ошибка.
Разработчики Spring обратили на это внимание, и в Spring появился паттерн JdbcTemplate. Template позволил вам сосредоточиться непосредственно на запросах и их результатах.
Теперь за управление ресурсами отвечал фреймворк. Вам больше никогда не позвонят в 3 часа ночи, потому что ваша база данных/приложение упали.
Ладно, возможно, вы все еще получаете звонки среди ночи. Но не потому, что забыли закрыть соединение!
Я думаю, что после написания десятков запросов к одному и тому же объекту Item, вы задумывались: «Почему Java, зная тип объекта, не может сгенерировать запрос за меня?»
И здесь появляется Hibernate — предвестник JPA.
Hibernate
В течение многих лет мы мучились с маппингом строк таблиц БД на Java-объекты, а также с различиями между разными СУБД.
При переходе с Oracle на Postgres мне придется переписывать все запросы? Иногда, да. Потому что в каждой СУБД есть свои особенности и реализации стандарта ANSI SQL отличаются от СУБД к СУБД.
Hibernate принес унифицированный подход для персистентности Java-объектов — надо только настроить маппинг таблиц БД на Java-классы. Изначально для конфигурации маппинга использовался XML, но с появлением Java 5 перешли на аннотации!
И все понеслось с космической скоростью!
Унификация общения с разными СУБД, когда один и тот же запрос можно выполнить на любой СУБД — это действительно круто. Но осталась одна проблема, которую мы не осознавали до конца.
Но осталась одна проблема, которую мы не осознавали до конца.
Хорошо, хорошо, были те, кто понимали это, но большинство — нет.
Вы никогда не сможете по-настоящему избежать настройки маппинга реляционных таблиц. Если вы используете Hibernate, это еще не значит, что можно перестать думать в терминах реляционных баз данных.
Да, для простейших запросов проблем нет.
select i from Item i where i.description like ‘%:partialDescription%’
Это весьма простой запрос. Он может быть универсальным. Как раз в таких ситуациях Hibernate приводит в полный восторг.
В итоге Hibernate стандартизовали из-за его популярности.
Hibernate, теперь тебя зовут JPA
JPA — это Java Persistence API (аббревиатура внутри аббревиатуры). Hibernate стал основой для него. Большинство разработчиков, использующих JPA, на самом деле используют Hibernate.
JPA был настолько продуманным, что окрылял вас.
Но мы неизбежно обнаружим, что в JPA есть страшная тайна, о которой мы где-то прочитали или догадались сами: вы никогда, никогда не уйдете от концепции реляционных таблиц.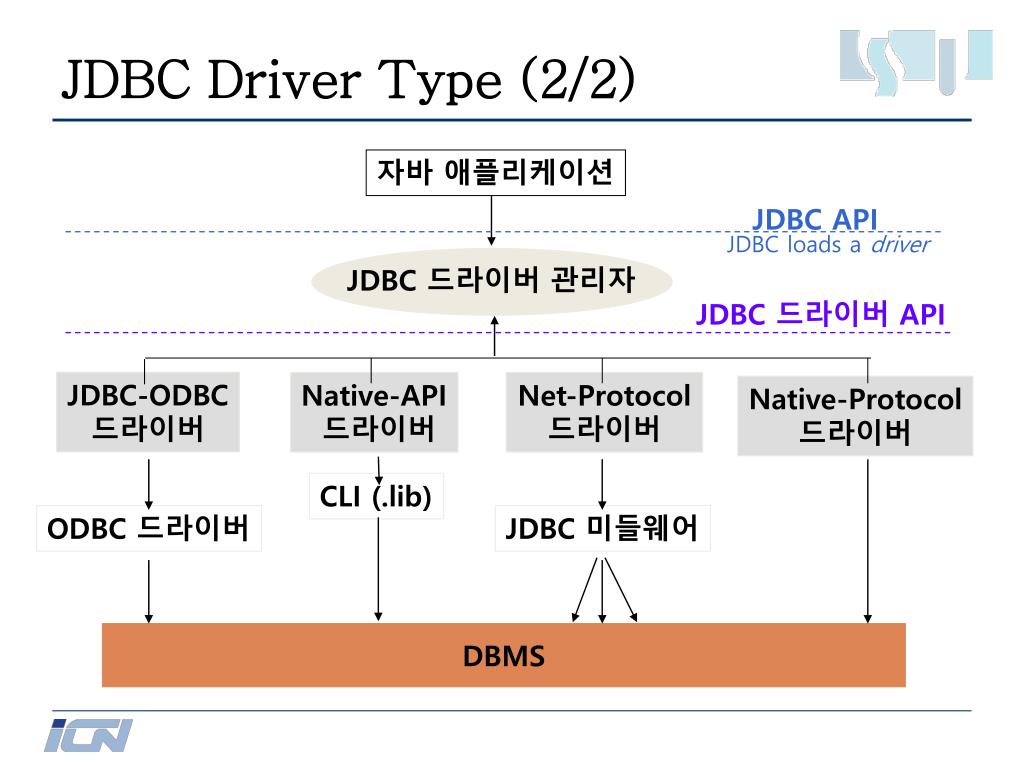 По мере написания более сложных, более запутанных и более бизнес-ориентированных запросов вы обнаружите, что Java-объекты не всегда соответствуют этой парадигме.
По мере написания более сложных, более запутанных и более бизнес-ориентированных запросов вы обнаружите, что Java-объекты не всегда соответствуют этой парадигме.
То есть вы просто променяли свои знания SQL на знания JPA.
На самом деле, он довольно мощный. Но иногда этой силе требуется небольшая помощь, поэтому и был создан Spring Data JPA.
Spring Data JPA помогает вам с простыми запросами и избавляет от необходимости работать с EntityManager из JPA.
Хотя рано или поздно вам все-равно придется писать JPQL-запросы вручную.
Но если вы думаете, что написав, сложный и тонко настроенный JPQL-запрос вы сможете каким-то образом настроить генерацию оптимального SQL-запроса, вас ждет большое разочарование.
В былые времена администраторы баз данных помогали найти медленные запросы. А проанализировав план выполнения, вы могли понять, как запрос выполняется и где тратит время.
И можно было заняться оптимизацией БД и запроса:
создать индексы;
актуализировать статистику;
переписать JOIN;
избавиться от функций вроде UPPER (или LOWER), чтобы избежать полных сканирований таблиц;
убрать десятки JOIN одной и той же таблицы (да, однажды я видел и такое).

А также использовать десяток других приемов. После оптимизации ваш двадцатиминутный запрос мог выполняться за секунду. Это было обычным делом при обслуживании баз данных/приложений.
Но с SQL-запросами, генерируемыми через JPA, вы не сможете этого сделать.
Некоторые стали называть это девятым кругом JPA.
Может для вас это допустимо, но для многих — весьма неприятно.
Поэтому многих воодушевил Spring Data JDBC, появившийся в 2017 году. На конференции SpringOne в 2018 году зал был набит людьми, жаждущими услышать новости об этом.
Spring Data JBDC делает много работы за вас, но не все, что делает старый добрый Hibernate. Предполагается, что вручную вы напишете более оптимальный запрос как во времена чистого JDBC. У вас появляется возможность видеть SQL-запросы и настраивать их в соответствии с вашими потребностями.
Теперь, имея представление об этих технологиях (JdbcTemplate, Spring Data JPA, Spring Data JDBC) вы сможете сделать осознанный выбор в отношении того, что лучше подойдет вам в вашей ситуации.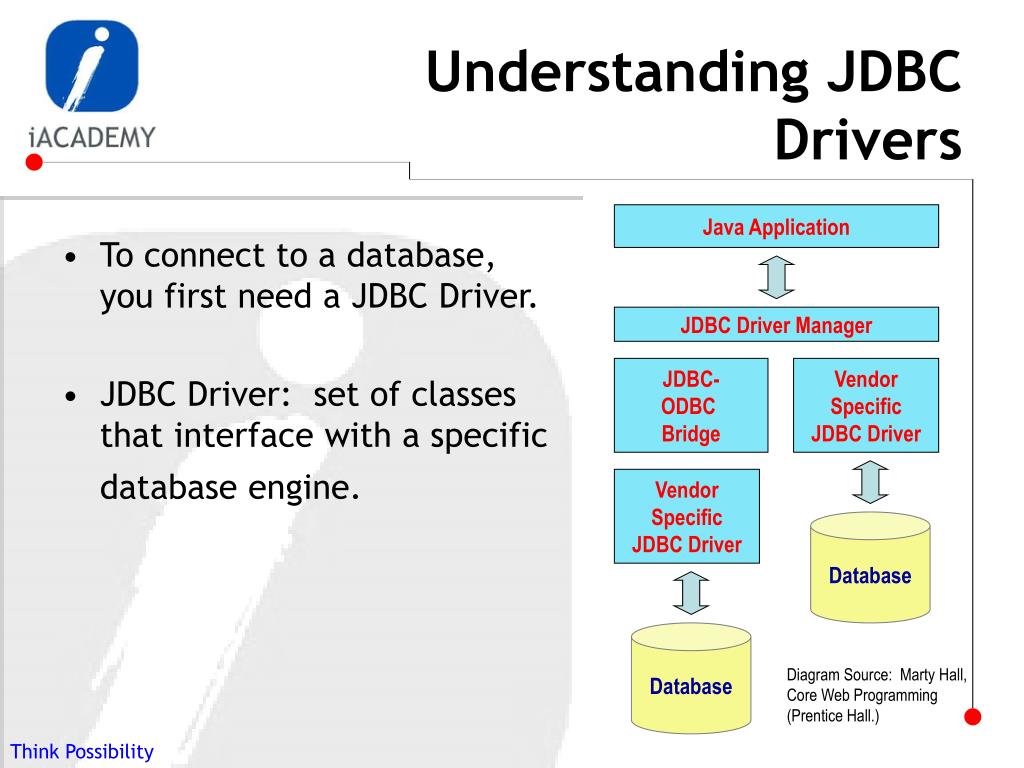
Когда говорим про память в Java, то чаще всего вспоминают Heap и Garbage Collector. Но у нас есть больше не менее интересного в памяти, о чем мы и поговорим на открытом занятии «Не хипом единым живёт Java». Приглашаем зарегистрироваться всех желающих.
вставка записей при помощи SimpleJdbcInsert — Provincial programming
Spring Framework JDBC позволяет реализовать любое взаимодействие с РСУБД при помощи JdbcOperations и его реализаций, однако это предполагает написание SQL-запросов. Но для наиболее типовых ситуаций Spring Framework JDBC предоставляет интерфейсы и классы, ориентированные на конкретные операции, позволяющие в отдельных случаях обходиться без написания SQL-кода. В этой статье речь пойдёт об интерфейсе SimpleJdbcInsertOperations и его реалилизациях, позволяющих реализовать вставку записей в таблицы без SQL-кода.
Конфигурация проекта
Для использования Spring Framework JDBC требуется только соответствующая зависимость: org. springframework:spring-jdbc или org.springframework.boot:spring-boot-starter-jdbc, если используется Spring Boot:
springframework:spring-jdbc или org.springframework.boot:spring-boot-starter-jdbc, если используется Spring Boot:
Для примеров кода в этой статье будет использоваться класс Todo, имеющий следующую структуру:
для которого в базе данных существует таблица со следующей структурой:
Создание и конфигурирование объекта SimpleJdbcInsert
Конструктор SimpleJdbcInsert принимает один аргумент, это может быть объект класса javax.sql.DataSource или org.springframework.jdbc.core.JdbcTemplate. Для выполнения запросов SimpleJdbcInsert использует именно JdbcTemplate.
Созданный объект класса SimpleJdbcInsert можно сконфигурировать следующими методами:
- withTableName — для указания используемой таблицы
- withCatalogName — для указания используемого каталога
- withSchemaName — для указания используемой схемы
- withoutTableColumnMetaDataAccess — для отключения обработки метаданных
- usingColumns — для указания списка используемых колонок
- usingGeneratedKeyColumns — для указания списка колонок с генерируемыми значениями
При помощи этих методов мы можем сконфигурировать объект SimpleJdbcInsert таким образом, чтобы, например, в запрос передавались значения колонок id, done и task, а значение колонки date_created создавалось автоматически и возвращалось в ответе:
При этом создавать объект класса SimpleJdbcInsert для каждого вызова излишне.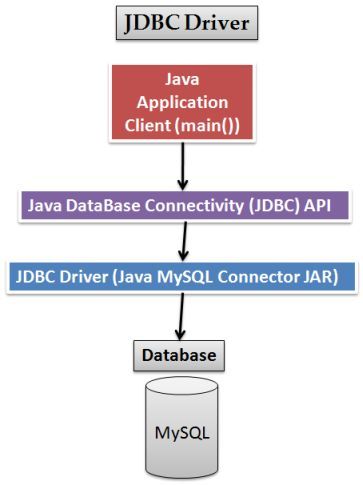 Гораздо правильнее будет создать один объект и использовать его повторно. Первый вариант — сконфигурировать компонент класса SimpleJdbcInsert в контексте приложения:
Гораздо правильнее будет создать один объект и использовать его повторно. Первый вариант — сконфигурировать компонент класса SimpleJdbcInsert в контексте приложения:
Второй вариант — создать новый класс и использовать его экземпляр:
После окончания конфигурирования можно вызвать метод compile, объявленный в org.springframework.jdbc.core.simple.AbstractJdbcInsert. Вызов этого метода предотвратит дальнейшее изменение объекта и подготовит его для выполнения запросов. Вызов этого метода опционален, так как он вызывается автоматически при запросе, если ещё не вызывался.
Выполнение запросов
Для выполнения запросов в интерфейсе SimpleJdbcInsertOperations объявлены 4 метода: execute, executeAndReturnKey, executeAndReturnKeyHolder и executeBatch.
execute
Самый простой метод, принимает в качества аргумента объект типа java.util.Map или org.springframework.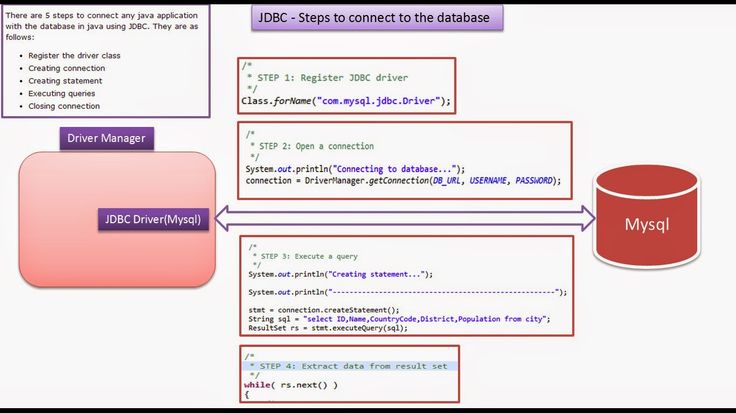 jdbc.core.namedparam.SqlParameterSource, содержащий сохраняемые значения, и возвращает количество вставленных строк.
jdbc.core.namedparam.SqlParameterSource, содержащий сохраняемые значения, и возвращает количество вставленных строк.
executeAndReturnKey
Принимает объект типа Map или SqlParameterSource в качестве аргумента и возвращает сгенерированный ключ. Данный метод применяется для получения сгенерированного значения в автоинкрементируемой колонке. Данный метод предполагает, что при конфигурировании объекта SimpleJdbcInsertOperations были указаны колонки с генерируемым значением.
executeAndReturnKeyHolder
Принимает объект типа Map или SqlParameterSource в качестве аргумента и возвращает сгенерированные ключи. Данный метод так же предполагает, что при конфигурировании объекта SimpleJdbcInsertOperations были указаны колонки с генерируемым значением. Возвращённый объект типа org.springframework.jdbc.support.KeyHolder содержит все автоматически сгенерированные зачения, среди которых могут быть не только целочисленные, но и, например, временные метки, как это было показано в одном из сниппетов.
executeBatch
Этот метод аналогичен execute, но ориентирован на выполнение сразу нескольких запросов. В качестве аргумента он принимает набор объектов Map или SqlParameterSource, содержащих значения колонок новых строк, и возвращает массив количества вставленных строк.
Полезные ссылки
Раздел официальной документации, посвящённый SimpleJdbcInsert.
Как устроен JDBC-коннектор источника Kafka Confluent и при чем здесь реестр схем | by Nick Komissarenko
Недавно мы рассматривали пример потоковой передачи данных между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Сегодня заглянем под капот такой интеграции и разберем подробнее, что именно представляет собой JDBC-коннектор источника Kafka от Confluent.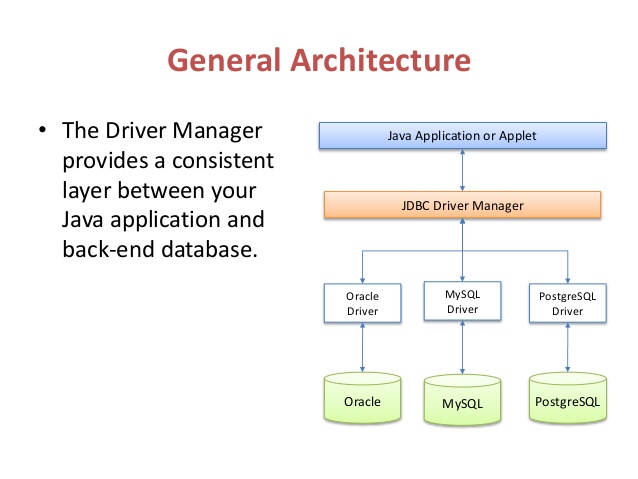
Компоненты Kafka Confluent для потоковой интеграции данных: коннекторы и реестр схем
В прошлый раз мы показали, как Kafka Connect позволяет реализовать гибкую интеграцию между разными приложениями, заменяя медленные пакетные задания точечных интеграций между отдельными сервисами на быстрые потоковые обновления по всему ИТ-ландшафту предприятия. Этот компонент платформы Confluent отвечает за масштабируемый и надежный способ перемещения данных в Apache Kafka и из нее. На практике чаще всего используется JDBC Connector (Source & Sink), который позволяет интегрировать разные СУБД через обмен данными в топиках Kafka .
Если с загруженными данными публикации не будет никаких операций, можно использовать только JDBC-коннектор, не запуская другой компонент платформы Kafka Confluent: реестр схем (Shema Registry). Однако, в реальных кейсах обычно требуется поддерживать совместимый формат данных в источниках и потребителях. Именно это и обеспечивает Shema Registry, поддерживая простое использование Avro, Protobuf и схемы JSON в качестве общих форматов данных для записей Kafka, которые коннекторы читают и записывают. Подробнее о Shema Registry мы писали здесь.
Подробнее о Shema Registry мы писали здесь.
Что особенно важно в задачах интеграции данных, JDBC-коннектор поддерживает эволюцию схемы при использовании конвертера Avro. При изменении схемы таблицы базы данных JDBC-коннектор может обнаружить это, создать новую схему Connect и зарегистрировать новую схему Avro в реестре схем. Успех этого действия зависит от уровня совместимости Shema Registry, который по умолчанию является обратным. Например, если из таблицы удалить столбец, изменение будет обратно совместимым, и соответствующая схема Avro может быть успешно зарегистрирована в реестре. Но, когда схема Avro уже зарегистрирована в реестре и изменена схема таблицы, добавление нового столбца или изменение его типа не будет отражено в Shema Registry, т.к. такие изменения не имеют обратной совместимости. Избежать такого несоответствия поможет изменение уровня совместимости реестра схем одним из следующих способов :
— Установить уровень совместимости для субъектов, которые используются коннектором, с помощью PUT/config/(string: subject). Эти субъекты имеют формат topic-keyи topic-value, где топик определяется конфигурацией prefix и именем таблицы.
Эти субъекты имеют формат topic-keyи topic-value, где топик определяется конфигурацией prefix и именем таблицы.
— Настроить реестр схем для использования другого уровня совместимости, определив compatibility.level — глобальный параметр, который применяется ко всем схемам в реестре.
Из-за ограничений JDBC API некоторые совместимые изменения схемы могут считаться несовместимыми. В частности, как мы упомянули выше, добавление столбца со значением по умолчанию — это изменение с обратной совместимостью. Но ограничения JDBC API затрудняют сопоставление этого значения со значениями правильного типа в схеме Kafka Connect, поэтому значения по умолчанию не заданы, из-за чего схема, зарегистрированная в реестре, не имеет обратной совместимости.
Подобные ограничения совместимости схемы наблюдаются при использовании JDBC-коннектора вместе с коннектором HDFS. Когда включена интеграция Hive, совместимость схемы должна быть обратной, прямой и полной, чтобы схема Apache Hive могла запрашивать все данные в топике Kafka . Эти нюансы следует учитывать в production при постоянной загрузке данных из разных СУБД в Apache Kafka и дальнейшей передаче через несколько конвейеров в другие системы, чтобы с помощью реестра схем снизить операционную сложность интеграции, обеспечив совместимость и эволюцию данных .
Эти нюансы следует учитывать в production при постоянной загрузке данных из разных СУБД в Apache Kafka и дальнейшей передаче через несколько конвейеров в другие системы, чтобы с помощью реестра схем снизить операционную сложность интеграции, обеспечив совместимость и эволюцию данных .
Как работает JDBC-коннектор Kafka Confluent
Итак, source-коннектор JDBC Kafka Connect позволяет импортировать данные из любой реляционной СУБД с драйвером JDBC в топик Apache Kafka. Данные загружаются путем периодического выполнения SQL-запроса и создания выходной записи для каждой строки в наборе результатов. По умолчанию каждая таблица из базы-источника копируется в отдельный выходной топик Kafka, а исходная СУБД непрерывно отслеживается на наличие новых или удаленных таблиц. При копировании данных из таблицы JDBC-коннектор может загружать только новые или измененные строки, указывая, какие столбцы следует использовать для их обнаружения.
Можно настроить приложения потоков Java для десериализации и приема данных несколькими способами, включая консольные продюсеры Kafka, source-коннекторы JDBC и продюсеры клиентов Java. Source-коннектор JDBC Kafka поддерживает копирование таблиц с различными типами JDBC-данных, динамическое добавление и удаление таблиц из базы, белые и черные списки, различные интервалы опроса и другие параметры, а также особенно важные для большинства пользователей настройки управления инкрементным копированием данных из СУБД.
Source-коннектор JDBC Kafka поддерживает копирование таблиц с различными типами JDBC-данных, динамическое добавление и удаление таблиц из базы, белые и черные списки, различные интервалы опроса и другие параметры, а также особенно важные для большинства пользователей настройки управления инкрементным копированием данных из СУБД.
Kafka Connect отслеживает самую последнюю запись, полученную из каждой таблицы, чтобы снова запускаться в нужном месте на следующей итерации или в случае сбоя. Коннектор источника использует эту возможность только для получения обновленных строк из таблицы или из вывода настраиваемого запроса на каждой итерации в зависимости от режима обнаружения измененных строк.
Главными функциями source-коннектора JDBC Kafka можно назвать следующие :
— семантика доставки хотя бы 1 раз (at least once), гарантируя, что записи будут доставлены в топик Kafka хотя бы один раз. Если коннектор перезапускается, в топике Kafka могут быть повторяющиеся записи.
— Выполнение только одной задачи в режиме запроса, но в ее рамках может читать сразу несколько таблиц СУБД.
— 3 режима инкрементальных запросов (Incrementing Column, Timestamp Column, Custom Query), каждый из которых отслеживает набор столбцов для обработанных, новых или измененных строк. Все эти режимы используют столбцы для обнаружения изменений, а потому требуют их индексирования для эффективного выполнения запросов. Также есть режим Bulk, который не фильтруется и не является инкрементным, а будет загружать все строки из таблицы на каждой итерации. Это полезно при периодической выгрузке всей таблицы, где записи в конечном итоге удаляются, а следующая система может безопасно обрабатывать дубликаты.
— Ключи сообщений. Поскольку сообщение в Kafka представляют собой пару ключ-значение, то для JDBC-коннектора значение как полезная нагрузка — это содержимое принимаемой строки таблицы. По умолчанию JDBC-коннектор не генерирует ключ сообщения, однако он может пригодится при настройке стратегии партиционирования, направляя сообщения в конкретный раздел. Также ключи могут поддерживать последующую обработку данных, например, в рамках JOIN-соединения. Без указания ключа, сообщения отправляются в разделы с использованием циклического распределения. Чтобы установить ключ сообщения для JDBC-коннектора, следует добавить в его конфигурацию два преобразования одного сообщения (SMT, Single Message Transformation): ValueToKey SMT и ExtractField SMT.
По умолчанию JDBC-коннектор не генерирует ключ сообщения, однако он может пригодится при настройке стратегии партиционирования, направляя сообщения в конкретный раздел. Также ключи могут поддерживать последующую обработку данных, например, в рамках JOIN-соединения. Без указания ключа, сообщения отправляются в разделы с использованием циклического распределения. Чтобы установить ключ сообщения для JDBC-коннектора, следует добавить в его конфигурацию два преобразования одного сообщения (SMT, Single Message Transformation): ValueToKey SMT и ExtractField SMT.
— Сопоставление типов столбцов с типами полей в Kafka Connect. По умолчанию коннектор сопоставляет типы SQL/JDBC для точного представления в Java, что достаточно просто для многих типов данных SQL. Например, типы SQL NUMERIC и DECIMAL чаще всего соответствуют логическому типу Connect Decimal, который использует представление Java BigDecimal. Avro сериализует десятичные типы как байты, которые могут быть трудными для использования и которые могут потребовать дополнительного преобразования в соответствующий тип данных. В таких случаях используется свойство конфигурации numeric.mapping для преобразования числовых значений к наиболее подходящему типу примитива.
В таких случаях используется свойство конфигурации numeric.mapping для преобразования числовых значений к наиболее подходящему типу примитива.
Таким образом, интеграция данных между разными СУБД с помощью source-коннектора JDBC Kafka — отличный непрерывной доставки информации без единой строчки кода. Однако, организовать потоковую передачу событий из таблиц базы данных только на нем одном с настройками по умолчанию невозможно из-за его специфических особенностей или ограничений :
— помимо обнаружения новых строк в инкрементных столбцах, может быть изменена сама схема таблицы БД, что не всегда автоматически отражается в реестре схем;
— если в столбец добавлена новая строка, в таблице должен быть дополнительный столбец с меткой времени для обнаружения этих изменений и их добавления в топик Kafka;
— в случае удаления данных в строках таблица JDBC-коннектор отстает от события DELETE, используя SQL-запросы SELECT для извлечения данных.
Поэтому необходимо тщательно настраивать конфигурационные свойства source-коннектора JDBC Kafka, о чем мы поговорим в следующий раз.
Освоить на практике эти и другие тонкости администрирования и эксплуатации Apache Kafka для разработки распределенных приложений потоковой аналитики больших данных вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
— Apache Kafka для разработчиков
— Администрирование кластера Kafka
Источники
1. https://gautambangalore.medium.com/data-ingestion-from-rdbms-by-leveraging-confluents-jdbc-kafka-connector-34a034fb841a
2. https://docs.confluent.io/kafka-connect-jdbc/current/source-connector/index.html
Что такое jdbc java
Руководство по JDBC. Введение.
Java Database Connectivity – это стандартный API для независимого соединения языка программирования Java с различными базами данных (далее – БД).
JDBC решает следующие задачи:
- Создание соединения с БД.

- Создание SQL выражений.
- Выполнение SQL – запросов.
- Просмотр и модификация полученных записей.
Если говорить в целом, то JDBC – это библиотека, которая обеспечивает целый набор интерфейсов для доступа к различным БД.
Для доступа к каждой конкретной БД необходим специальный JDBC – драйвер, который является адаптером Java – приложения к БД.
Строение JDBC
JDBC поддерживает как 2-звенную, так и 3-звенную модель работы с БД, но в общем виде, JDBC состоит из двух слоёв.
- JDBC API
Обеспечивает соединение “приложение – JDBC Manager”. - JDBC Driver API
Обеспечивает соединение “JDBC Manager – драйвер”.
JDBC API использует менеджер драйверов и специальные драйверы БД для обеспечения подключения к различным базам данных.
JBDC Manager проверяет соответствие драйвера и конкретной БД.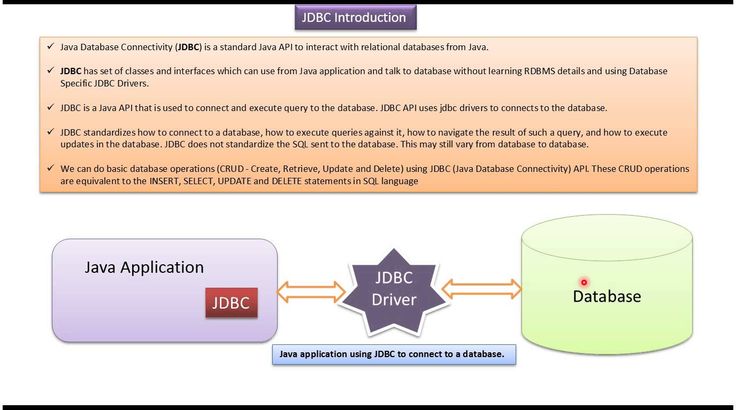 Он поддерживает возможность использования нескольких драйверов одновременно для одновременной работы с несколькими видами БД.
Он поддерживает возможность использования нескольких драйверов одновременно для одновременной работы с несколькими видами БД.
Схематично, JDBC можно представить в таком виде:
Рассмотрим элементы JDBC по отдельности.
Элементы JDBC
JDBC API состоит из следующих элементов:
- Менеджер драйверов (Driver Manager)
Этот элемент управляет списком драйверов БД. Каждой запрос на соединение требует соответствующего драйвера. Первое совпадение даёт нам соединение. - Драйвер (Driver)
Этот элемент отвечает за связь с БД. Работать с ним нам приходится крайне редко. Вместо этого мы чаще используем объекты DriverManager, которые управляют объектами этого типа. - Соединение (Connection)
Этот интерфейс обеспечивает нас методами для работы с БД. Все взаимодействия с БД происходят исключительно через Connection. - Выражение (Statement)
Для подтверждения SQL-запросов мы используем объекты, созданные с использованием этого интерфейса.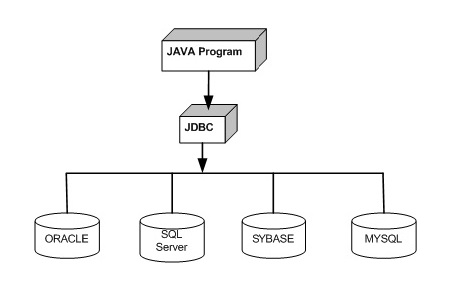
- Результат (ResultSet)
Экземпляры этого элемента содержат данные, которые были получены в результате выполнения SQL – запроса. Он работает как итератор и “пробегает” по полученным данным. - Исключения (SQL Exception)
Этот класс обрабатывает все ошибки, которые могут возникнуть при работе с БД.
Пакеты JDBC
Ключевыми пакетами JDBC являются java.sql и javax.sql. На момент написания этого руководства, текущей версией JDBC является JDBC 4.0.
С отличиями этой спецификации от предыдущих вы можете ознакомиться в JDBC Specification.
Вот основные изменения:
- Улучшенная обработка исключений.
- Автоматическая загрузка драйвера БД.
- Улучшения интерфейсов Connection и Statement.
- Поддержка национальных символов.
- Поддержка типа данных SQL 2003 XML.
- Аннотации.
- Доступ SQL ROWID.
В этом уроке мы ознакомились с основами JDBC и рассмотрели его архитектуру.
Простой пример JDBC для начинающих
Здравствуйте! В этой статье я напишу простой пример соединения с базами данных на Java.Эта статья предназначена новичкам.Здесь я опишу каждую строчку объясню что зачем.
Но для начала немного теории.
JDBC (Java DataBase Connectivity — соединение с базами данных на Java) предназначен для взаимодействия Java-приложения с различными системами управления базами данных (СУБД). Всё движение в JDBC основано на драйверах которые указываются специально описанным URL.
А теперь практика.
Для начала создаём maven проект и в pom.xml помещаем зависимость для соединения с СУБД (В моём случае СУБД будет выступать MySQL):
Должно получится так:
Дальше подключаемся к базе данных нужной вам(я пользуюсь IDEA Ultimate по этому я подключаюсь именно так).
Дальше заполняем Database, User и Password.Обязательно проверяем соединение.
Дальше мы создаём сам класс.
А теперь разберём его построчно:
В начале мы создаём три переменные url,username и password. Образец указания url:
Образец указания url:
Username по умолчанию root.Password вы должны знать сами.
После с помощью строчки Class.forName(«com.mysql.jdbc.Driver») регестрируем драйвера. Дальше устанавливаем соединение с помощью DriverManager.getConnection (ваш url, username, password).
После с помощью connection (соединения) создаём простой запрос Statement методом createStatement().
Дальше создаём экземпляр класса ResultSet и формируем запрос через statement методом executeQuery (запрос).
Дальше мы заставляем пробежаться resultSet по всей базе данных и вывести то что нам нужно. Так с помощью объекта resultSet и его методов (getString,getInt и т.д. в зависимости от типа переменных в колонке) мы выводим.Так как мой запрос был для того что бы вывести всё, мы можем вывести любую колонку.
После закрываем resultSet,statement и connection (именно в такой последовательности). В процессе он будет показывать ошибки так как будет запрашивать обработку исключений в catch.Так что пишите catch заранее.
Теперь когда практика есть на неё можно наложить более глубокую теорию.Тема правда очень большая, желаю удачи в её изучении.
Введение в JDBC
В этой статье мы рассмотрим JDBC (Подключение к базе данных Java), который представляет собой API для подключения и выполнения запросов к базе данных.
JDBC может работать с любой базой данных при условии наличия надлежащих драйверов.
2. Драйверы JDBC
Драйвер JDBC-это реализация API JDBC, используемая для подключения к определенному типу базы данных. Существует несколько типов драйверов JDBC:
- Тип 1 – содержит сопоставление с другим API доступа к данным; примером этого является драйвер JDBC-ODBC
- Тип 2 – это реализация, которая использует клиентские библиотеки целевой базы данных; также называется драйвером собственного API
- Тип 3 – использует промежуточное программное обеспечение для преобразования вызовов JDBC в вызовы, относящиеся к конкретной базе данных; также известен как драйвер сетевого протокола
- Тип 4 – прямое подключение к базе данных путем преобразования вызовов JDBC в вызовы, относящиеся к конкретной базе данных; известные как драйверы протокола базы данных или тонкие драйверы,
Наиболее часто используемый тип-тип 4, так как он имеет то преимущество, что он не зависит от платформы .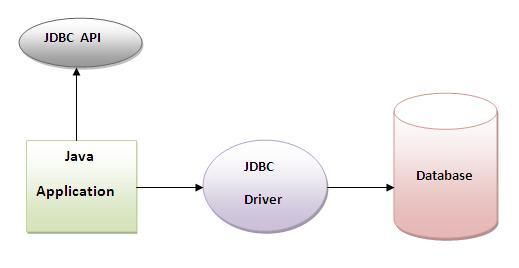 Прямое подключение к серверу баз данных обеспечивает более высокую производительность по сравнению с другими типами. Недостатком этого типа драйверов является то, что он зависит от конкретной базы данных-учитывая, что каждая база данных имеет свой собственный конкретный протокол.
Прямое подключение к серверу баз данных обеспечивает более высокую производительность по сравнению с другими типами. Недостатком этого типа драйверов является то, что он зависит от конкретной базы данных-учитывая, что каждая база данных имеет свой собственный конкретный протокол.
3. Подключение к базе данных
Чтобы подключиться к базе данных, нам просто нужно инициализировать драйвер и открыть соединение с базой данных.
3.1. Регистрация водителя
Для нашего примера мы будем использовать драйвер протокола базы данных типа 4.
Поскольку мы используем базу данных MySQL, нам нужна зависимость mysql-connector-java :
Далее давайте зарегистрируем драйвер с помощью метода Class.forName () , который динамически загружает класс драйвера:
В более старых версиях JDBC перед получением соединения нам сначала нужно было инициализировать драйвер JDBC, вызвав метод Class.forName . Начиная с JDBC 4.0 , все драйверы, найденные в пути к классам, автоматически загружаются . Поэтому нам не понадобится эта Class.forName часть в современных средах.
Поэтому нам не понадобится эта Class.forName часть в современных средах.
3.2. Создание соединения
Чтобы открыть соединение, мы можем использовать метод getConnection() класса DriverManager . Для этого метода требуется URL-адрес подключения Строка параметр:
Поскольку Соединение является автоклавируемым ресурсом, мы должны использовать его внутри попробуйте с ресурсами |/блок .
Синтаксис URL-адреса подключения зависит от типа используемой базы данных. Давайте рассмотрим несколько примеров:
Чтобы подключиться к указанной myDb базе данных, нам нужно будет создать базу данных и пользователя, а также добавить необходимый доступ:
4. Выполнение инструкций SQL
В инструкциях отправки SQL в базу данных мы можем использовать экземпляры типа Statement , PreparedStatement, или CallableStatement, которые мы можем получить с помощью объекта Connection .
4.1. Заявление
Интерфейс Оператор содержит основные функции для выполнения команд SQL.
Во-первых, давайте создадим Оператор объект:
Опять же, мы должны работать с Оператором s внутри блока try-with-resources для автоматического управления ресурсами.
В любом случае, выполнение инструкций SQL может быть выполнено с помощью трех методов:
- ExecuteQuery() для ВЫБОРА инструкций
- executeUpdate() для обновления данных или структуры базы данных
- execute() может использоваться в обоих случаях, описанных выше, когда результат неизвестен
Давайте используем метод execute() для добавления таблицы студенты в нашу базу данных:
При использовании выполнить() способ обновления данных, затем stmt.getUpdateCount() метод возвращает количество затронутых строк.
Если результат равен 0, то либо строки не были затронуты, либо это была команда обновления структуры базы данных.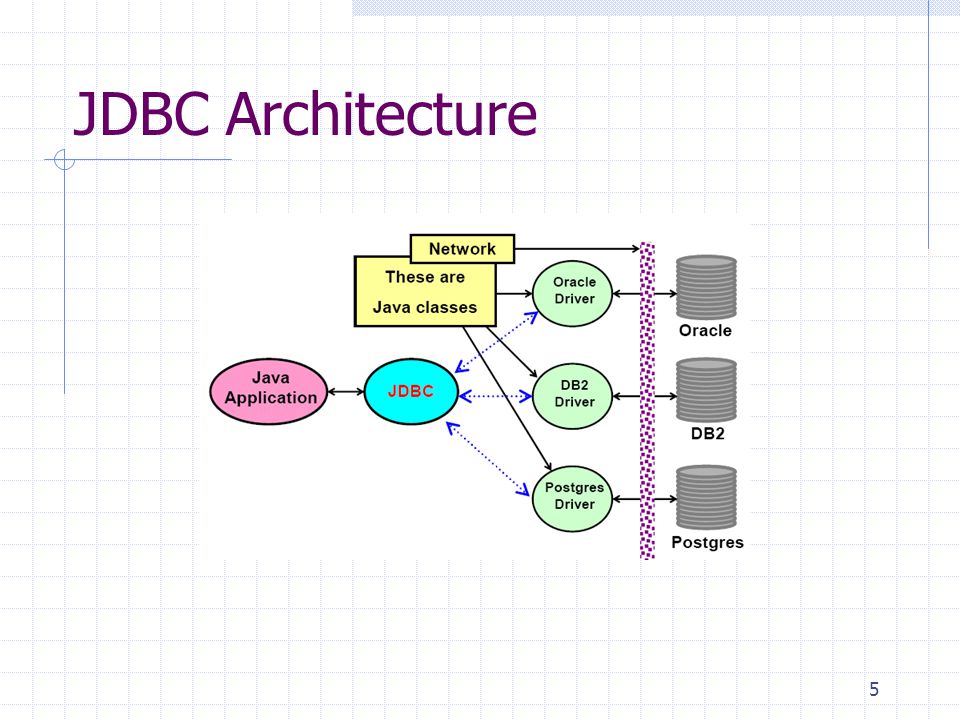
Если значение равно -1, то команда была запросом SELECT; затем мы можем получить результат с помощью stmt.getResultSet() .
Далее давайте добавим запись в нашу таблицу с помощью метода executeUpdate() :
Метод возвращает количество затронутых строк для команды, обновляющей строки, или 0 для команды, обновляющей структуру базы данных.
Мы можем извлечь записи из таблицы с помощью метода ExecuteQuery () , который возвращает объект типа ResultSet :
Мы должны обязательно закрыть экземпляры ResultSet после использования. В противном случае мы можем держать базовый курсор открытым в течение гораздо более длительного периода, чем ожидалось. Для этого рекомендуется использовать блок try-with-resources , как в нашем примере выше.
4.2. Подготовленное Заявление
Объекты PreparedStatement содержат предварительно скомпилированные последовательности SQL. Они могут иметь один или несколько параметров, обозначенных знаком вопроса.
Давайте создадим Подготовленное заявление , которое обновляет записи в таблице сотрудники на основе заданных параметров:
Чтобы добавить параметры в PreparedStatement , мы можем использовать простые задатчики – setX() – где X-тип параметра, а аргументы метода-порядок и значение параметра:
Оператор выполняется одним из тех же трех методов, описанных ранее: ExecuteQuery (), executeUpdate (), execute() без параметра SQL String :
4.3. Вызываемое утверждение
Интерфейс CallableStatement позволяет вызывать хранимые процедуры.
Для создания объекта CallableStatement мы можем использовать prepareCall() метод Подключения :
Установка значений входных параметров для хранимой процедуры выполняется так же, как в интерфейсе PreparedStatement , с использованием методов setX() :
Если хранимая процедура имеет выходные параметры, нам нужно добавить их с помощью метода registerOutParameter() :
Затем давайте выполним инструкцию и получим возвращенное значение, используя соответствующий метод getX() :
Например, для работы нам нужно создать хранимую процедуру в нашей базе данных MySQL:
Описанная выше процедура insertEmployee вставит новую запись в таблицу сотрудники с использованием заданных параметров и вернет идентификатор новой записи в параметре emp_id out.
Чтобы иметь возможность запускать хранимую процедуру с Java, пользователь подключения должен иметь доступ к метаданным хранимых процедур. Этого можно достичь, предоставив пользователю права на все хранимые процедуры во всех базах данных:
В качестве альтернативы мы можем открыть соединение со свойством noAccessToProcedureBodies , установленным в true :
Это проинформирует API JDBC о том, что у пользователя нет прав на чтение метаданных процедуры, чтобы он создал все параметры в качестве параметров INOUT String .
5. Анализ Результатов Запроса
После выполнения запроса результат представляется объектом ResultSet , который имеет структуру, аналогичную таблице, со строками и столбцами.
5.1. Интерфейс набора результатов
Результирующий набор использует метод next() для перехода к следующей строке.
Давайте сначала создадим класс Employee для хранения полученных записей:
Далее давайте пройдемся по Набору результатов и создадим объект Сотрудник для каждой записи:
Получение значения для каждой ячейки таблицы можно выполнить с помощью методов типа get X ( ), где X представляет тип данных ячейки.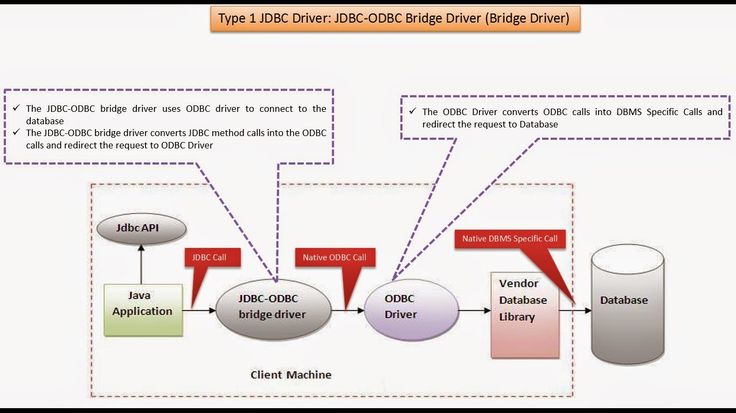
Методы getX() могут использоваться с параметром int , представляющим порядок ячейки, или параметром String , представляющим имя столбца. Последний вариант предпочтительнее в случае, если мы изменим порядок столбцов в запросе.
5.2. Обновляемый набор результатов
Неявно объект ResultSet может быть пройден только вперед и не может быть изменен.
Если мы хотим использовать Набор результатов для обновления данных и перемещения их в обоих направлениях, нам необходимо создать Оператор объект с дополнительными параметрами:
Для навигации по этому типу Результирующего набора мы можем использовать один из методов:
- first(), last(), beforeFirst(), beforeLast() – для перехода к первой или последней строке набора результатов или к строке перед этими следующий(), предыдущий()
- – для перемещения вперед и назад в наборе результатовGetRow() –
- для получения текущего номера строки moveToInsertRow(), moveToCurrentRow()
- – для перехода к новой пустой строке для вставки и возврата к текущей, если в новой строке абсолютный(int строка) –
- для перехода в указанную строку относительный(int nrRows)
- – для перемещения курсора на заданное количество строк
Обновление набора результатов может быть выполнено с использованием методов с форматом update X () , где X-тип данных ячейки.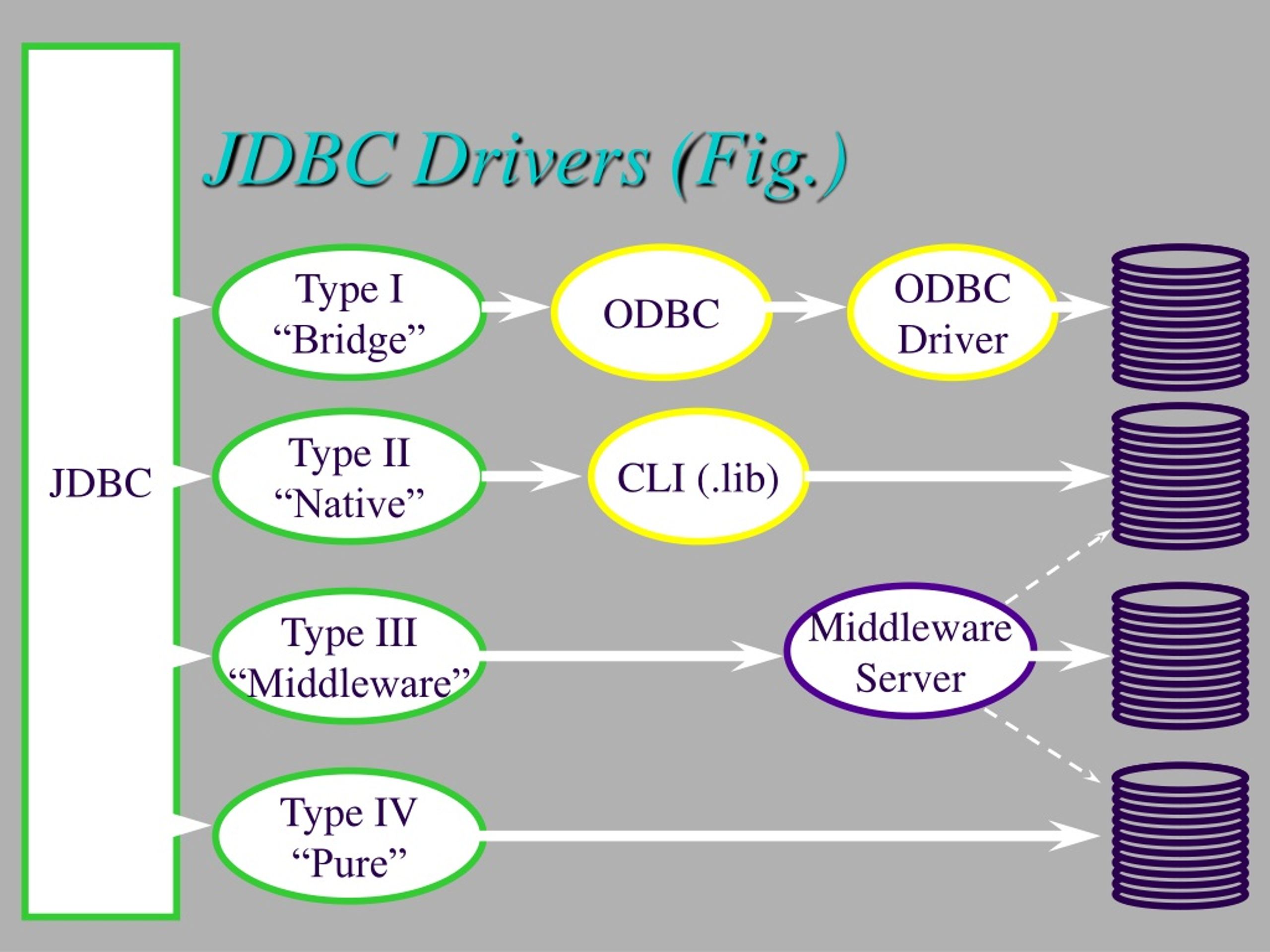 Эти методы обновляют только объект ResultSet , а не таблицы базы данных.
Эти методы обновляют только объект ResultSet , а не таблицы базы данных.
Чтобы сохранить Результирующий набор изменений в базе данных, мы должны дополнительно использовать один из методов:
- updateRow() – для сохранения изменений текущей строки в базе данных
- insertRow(), deleteRow() – для добавления новой строки или удаления текущей из базы данных
- refreshRow() – для обновления набора результатов с любыми изменениями в базе данных
- cancelRowUpdates() – для отмены изменений, внесенных в текущую строку
Давайте рассмотрим пример использования некоторых из этих методов путем обновления данных в таблице сотрудник :
6. Анализ Метаданных
API JDBC позволяет просматривать информацию о базе данных, называемую метаданными.
6.1. DatabaseMetaData
Интерфейс DatabaseMetaData может использоваться для получения общей информации о базе данных, такой как таблицы, хранимые процедуры или диалект SQL.
Давайте быстро рассмотрим, как мы можем извлекать информацию из таблиц базы данных:
6.2. ResultSetMetaData
Этот интерфейс можно использовать для поиска информации об определенном Результирующем наборе , такой как количество и название его столбцов:
7. Обработка Транзакций
По умолчанию каждая инструкция SQL фиксируется сразу после ее завершения. Однако также возможно управлять транзакциями программно .
Это может быть необходимо в тех случаях, когда мы хотим сохранить согласованность данных, например, когда мы хотим совершить транзакцию только в том случае, если предыдущая транзакция была успешно завершена.
Сначала нам нужно установить свойство autoCommit для Подключения в false , затем использовать методы commit() и rollback() для управления транзакцией.
Давайте добавим второе заявление об обновлении для столбца зарплата после обновления столбца сотрудник должность и заключим их в транзакцию.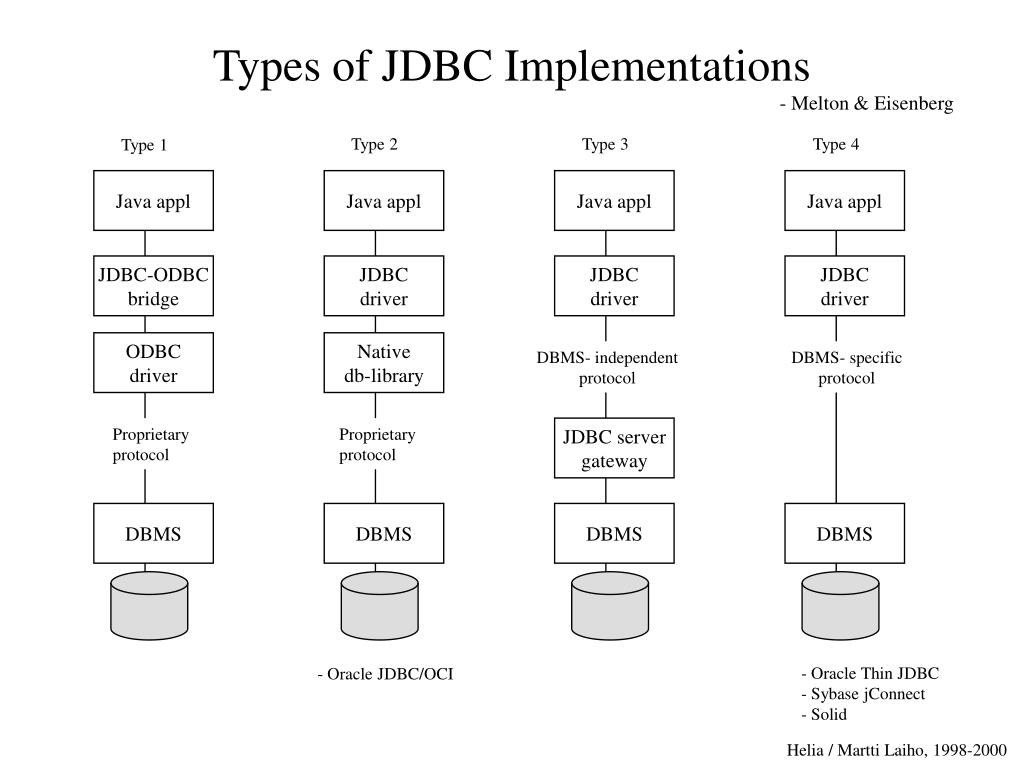 Таким образом, зарплата будет обновлена только в том случае, если должность была успешно обновлена:
Таким образом, зарплата будет обновлена только в том случае, если должность была успешно обновлена:
Для краткости мы опускаем здесь блоки try-with-resources .
8. Закрытие ресурсов
Когда мы больше не используем его, нам нужно закрыть соединение, чтобы освободить ресурсы базы данных .
Мы можем сделать это с помощью close() API:
Однако, если мы используем ресурс в блоке try-with-resources , нам не нужно явно вызывать метод close () , так как блок try-with-resources делает это за нас автоматически.
То же самое верно и для Заявление s, Подготовленное Заявление s, Вызываемое утверждение s, и Набор результатов s.
Учебное пособие по JDBC| Что такое подключение к базе данных Java (JDBC)
следующий → ← предыдущая JDBC означает подключение к базе данных Java. JDBC — это Java API для подключения и выполнения запроса к базе данных. Это часть JavaSE (стандартная версия Java).
Мы обсудили вышеупомянутые четыре драйвера в следующей главе. Мы можем использовать JDBC API для доступа к табличным данным, хранящимся в любой реляционной базе данных. С помощью JDBC API мы можем сохранять, обновлять, удалять и извлекать данные из базы данных. Это похоже на Open Database Connectivity (ODBC), предоставляемый Microsoft. Текущая версия JDBC — 4.3. Это стабильная версия с 21 сентября 2017 года. Она основана на интерфейсе уровня вызовов X/Open SQL. Пакет java.sql содержит классы и интерфейсы для JDBC API. Список популярных интерфейсов JDBC API приведен ниже:
Список популярных классов JDBC API приведен ниже:
Почему мы должны использовать JDBC До JDBC API ODBC был API базы данных для подключения и выполнения запроса к базе данных. Мы можем использовать JDBC API для обработки базы данных с помощью программы Java и можем выполнять следующие действия:
Что такое API API (интерфейс прикладного программирования) — это документ, содержащий описание всех функций продукта или программного обеспечения. Темы в Java Учебник JDBC2) Драйверы JDBC В этом учебнике JDBC мы изучим четыре типа драйверов JDBC, их преимущества и недостатки. 3) 5 шагов для подключения к базе данных В этом руководстве по JDBC мы увидим пять шагов для подключения к базе данных на Java с использованием JDBC. 4) Связь с Oracle с помощью JDBC В этом учебном пособии по JDBC мы подключим простую программу Java к базе данных Oracle. 5) Соединение с MySQL с помощью JDBC В этом руководстве по JDBC мы подключим простую программу Java к базе данных MySQL. 6) Связь с Access без DSN Давайте свяжем java приложение с базой данных Access с DSN и без. 7) Класс DriverManager В этом учебном пособии JDBC мы узнаем, что делает класс DriverManager и каковы его методы. 8) Интерфейс подключения В этом руководстве по JDBC мы узнаем, что такое интерфейс соединения и каковы его методы. 9) Интерфейс оператора В этом руководстве по JDBC мы узнаем, что такое интерфейс оператора и каковы его методы. 10) Интерфейс ResultSet В этом руководстве по JDBC мы узнаем, что такое интерфейс ResultSet и каковы его методы. Кроме того, мы узнаем, как сделать ResultSet прокручиваемым. 11) Интерфейс PreparedStatement В этом учебном пособии по JDBC мы узнаем, в чем преимущество PreparedStatement перед интерфейсом Statement. Мы увидим примеры вставки, обновления или удаления записей с использованием интерфейса PreparedStatement. 12) Интерфейс ResultSetMetaData В этом руководстве по JDBC мы узнаем, как получить метаданные таблицы. 13) Интерфейс DatabaseMetaData В этом руководстве по JDBC мы узнаем, как получить метаданные базы данных. 14) Хранение образа в Oracle Давайте узнаем, как хранить образ в базе данных Oracle с помощью JDBC. 15) Извлечение образа из Oracle Давайте рассмотрим простой пример получения изображения из базы данных Oracle с помощью JDBC. 16) Сохранение файла в Oracle Давайте рассмотрим простой пример сохранения файла в базе данных Oracle с помощью JDBC. 17) Извлечение файла из Oracle Давайте рассмотрим простой пример извлечения файла из базы данных Oracle с помощью JDBC. 18) CallableStatement Давайте посмотрим код для вызова хранимых процедур и функций с помощью CallableStatement. 19) Управление транзакциями с использованием JDBC Давайте рассмотрим простой пример использования управления транзакциями с помощью JDBC. 20) Пакетный оператор с использованием JDBC Давайте посмотрим код для выполнения пакета запросов. 21) JDBC RowSet Давайте посмотрим, как работает новый интерфейс JDBC RowSet. Следующая темаДрайвер Jdbc ← предыдущая следующий → |
 JDBC API использует драйверы JDBC для подключения к базе данных. Существует четыре типа драйверов JDBC:
JDBC API использует драйверы JDBC для подключения к базе данных. Существует четыре типа драйверов JDBC: Но ODBC API использует драйвер ODBC, написанный на языке C (т. е. зависящий от платформы и незащищенный). Вот почему Java определила свой собственный API (JDBC API), который использует драйверы JDBC (написанные на языке Java).
Но ODBC API использует драйвер ODBC, написанный на языке C (т. е. зависящий от платформы и незащищенный). Вот почему Java определила свой собственный API (JDBC API), который использует драйверы JDBC (написанные на языке Java). Он представляет классы и интерфейсы, которым программы могут следовать для связи друг с другом. API можно создать для приложений, библиотек, операционных систем и т. д.
Он представляет классы и интерфейсы, которым программы могут следовать для связи друг с другом. API можно создать для приложений, библиотек, операционных систем и т. д.

JDBC и модели данных — облачные концепции
Темный
Свет
JDBC
JDBC расшифровывается как Java Database Connectivity и представляет собой Java API, который управляет соединениями с базой данных, выдает запросы и команды для этой базы данных и обрабатывает наборы результатов, полученные из базы данных. Это также позволяет одновременно запускать несколько экземпляров и использовать одну и ту же программу.
Это также позволяет одновременно запускать несколько экземпляров и использовать одну и ту же программу.
JDBC предлагает интерфейс уровня программирования, который управляет механизмом взаимодействия Java-приложений с базой данных или RDBMS (реляционными базами данных). Интерфейс JDBC состоит из двух уровней:
- API JDBC, обеспечивающий связь между приложением Java и диспетчером JDBC.
- Драйвер JDBC, который находится внизу и обеспечивает связь между диспетчером JDBC и драйвером базы данных.
JDBC — это общий API, с которым взаимодействует код вашего приложения. Ниже находится JDBC-совместимый драйвер для используемой вами базы данных.
В Matillion есть компонент JDBC Incremental Load, который можно использовать в общих заданиях. Компонент JDBC Table Metadata to Grid извлекает метаданные из таблицы JDBC для заполнения переменной сетки.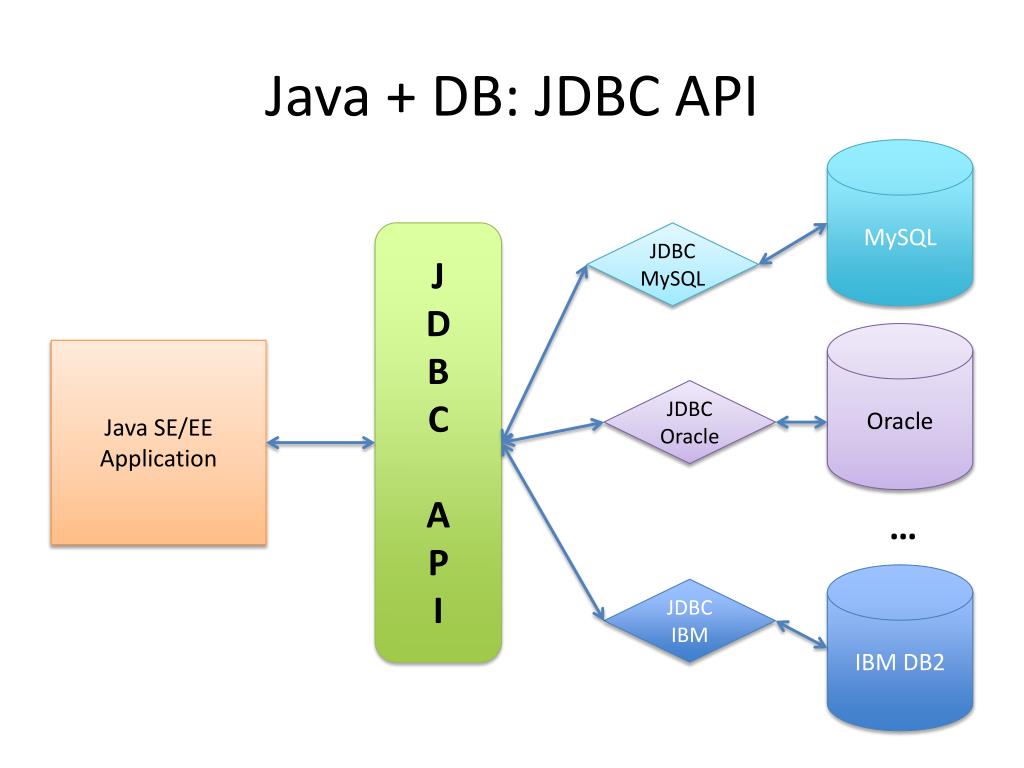 SAP Hana JDBC также поддерживается в Matillion ETL, а также с добавлением стороннего драйвера JDBC.
SAP Hana JDBC также поддерживается в Matillion ETL, а также с добавлением стороннего драйвера JDBC.
Соединения JDBC поддерживают операторы SQL для обновления и запроса, такие как CREATE, INSERT, UPDATE, DELETE и SELECT. API JDBC может получать доступ к табличным данным в базе данных и изменять записи.
Java можно использовать для Java-приложений, Java-апплетов (несуществующих небольших приложений, написанных на Java, поставляемых в байт-коде) и Java ServerPages (веб-страниц, написанных на Java). Все они используют драйвер JDBC.
Существует четыре типа драйверов JDBC:
- Мост JDBC-ODBC 9Драйвер 0242, который преобразует вызовы методов JDBC в вызовы функций ODBC (Open Database Connectivity — это API для доступа к системам управления базами данных)
- Собственный драйвер API (использует клиентские библиотеки базы данных)
- Драйвер сетевого протокола (использует серверы приложений для преобразования JDBC в протокол базы данных)
- Драйвер Thin (преобразует вызовы JDBC непосредственно в протокол базы данных)
Модели данных
Моделирование данных понимается как структура и модель базы данных: как данные соединяются вместе, обрабатываются и хранятся в системе.
Модели «сущность-связь»
В модели «сущность-связь» данные представлены в терминах сущностей и отношений в данных. Он описывает связанные «сущности» в определенной сфере знаний. Модель данных будет состоять из: сущностей и их атрибутов (дополнительная информация о сущности) и отношений между сущностями. Подобные сущности иногда группируются в наборы сущностей.
Сущность является компонентом данных. Слабый объект не имеет собственных атрибутов и полагается на свою связь с другим объектом. В модели сущность-связь сущность представлена в виде прямоугольника.
Атрибуты представлены в виде многоточия. Существует четыре типа атрибутов:
- Ключевой атрибут — идентифицирует объект из набора объектов.
- Составной атрибут — комбинация дополнительных атрибутов
- Многозначный атрибут — атрибут, который имеет несколько значений
- Производный атрибут — атрибут, выведенный из другого атрибута
Отношения представлены ромбом.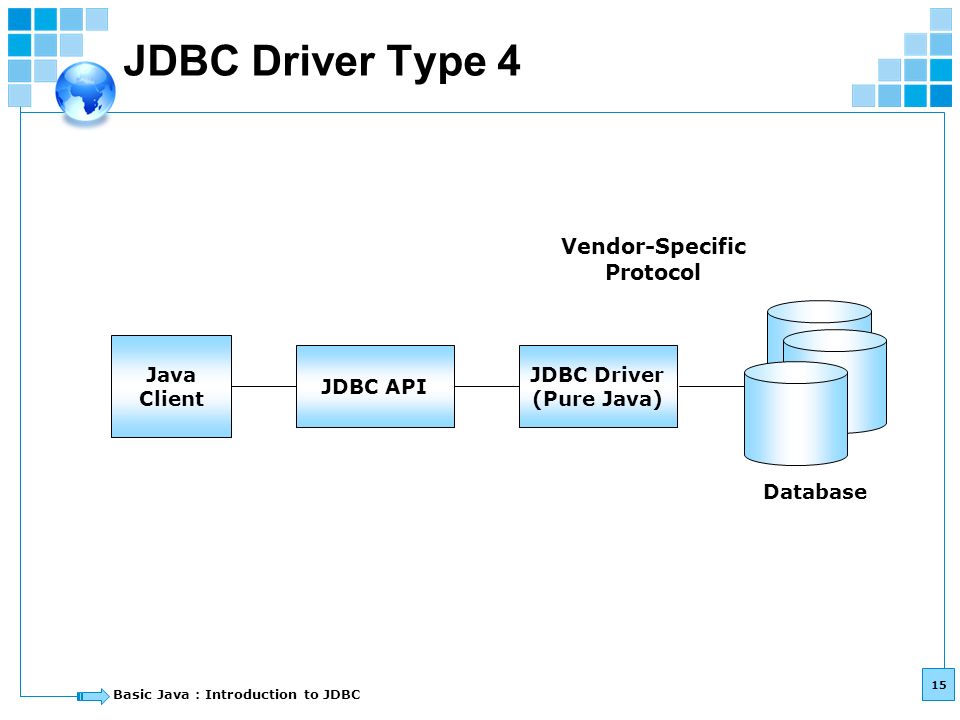 Существует четыре типа взаимосвязей:
Существует четыре типа взаимосвязей:
- One to One — когда один экземпляр сущности связан с другой одиночной сущностью (у одного пассажира один посадочный талон)
- Один ко многим — когда один экземпляр объекта связан с несколькими экземплярами другого объекта (один пассажир покупает несколько книг)
- Многие к одному — когда несколько экземпляров объекта относятся к одному объекту (много пассажиров садятся в один самолет)
- Многие ко многим — когда несколько экземпляров объекта связаны с несколькими экземплярами другого объекта (пассажиры заказывают несколько напитков)
Реляционные модели
Реляционная модель хранит данные в таблицах, называемых отношениями . Каждая строка содержит уникальное значение, а в каждом столбце хранятся значения из одного и того же домена. Данные представлены кортежами, другое имя для записи (одна строка). Отношение — это таблица значений, каждая строка которой представляет собой набор связанных значений данных. Столбцы также известны как атрибуты.
Каждая строка содержит уникальное значение, а в каждом столбце хранятся значения из одного и того же домена. Данные представлены кортежами, другое имя для записи (одна строка). Отношение — это таблица значений, каждая строка которой представляет собой набор связанных значений данных. Столбцы также известны как атрибуты.
Реляционные модели включают следующее:
- Таблицы — отношения сохраняются в табличной форме и содержат столбцы и строки
- Атрибуты — каждое отношение имеет такие свойства, как «Имя», «DOB», известные как атрибуты
- Степень — количество атрибутов
- Кортеж — одна запись/строка
- Экземпляр отношения — количество кортежей в системе РСУБД
- Мощность — количество строк в таблице
- Столбец — определяет атрибуты
- Домен атрибута — допустимые значения в атрибуте, например.
 номера в гостинице (1 — 250)
номера в гостинице (1 — 250) - Отношение ke y — атрибут(ы), присвоенный строке
Об интерфейсе JDBC —
Вы можете получить доступ к большому количеству баз данных через JDBC в Инфомейкер. В этом разделе описывается, что вам нужно знать для использования JDBC. соединения для доступа к вашим данным в InfoMaker.
Что такое JDBC?
JDBC API
Java Database Connectivity (JDBC) — стандартное приложение интерфейс программирования (API), который позволяет приложению Java получать доступ к любому база данных, поддерживающая язык структурированных запросов (SQL) в качестве стандарта язык доступа к данным.
API JDBC включает классы для общих действий с базой данных SQL.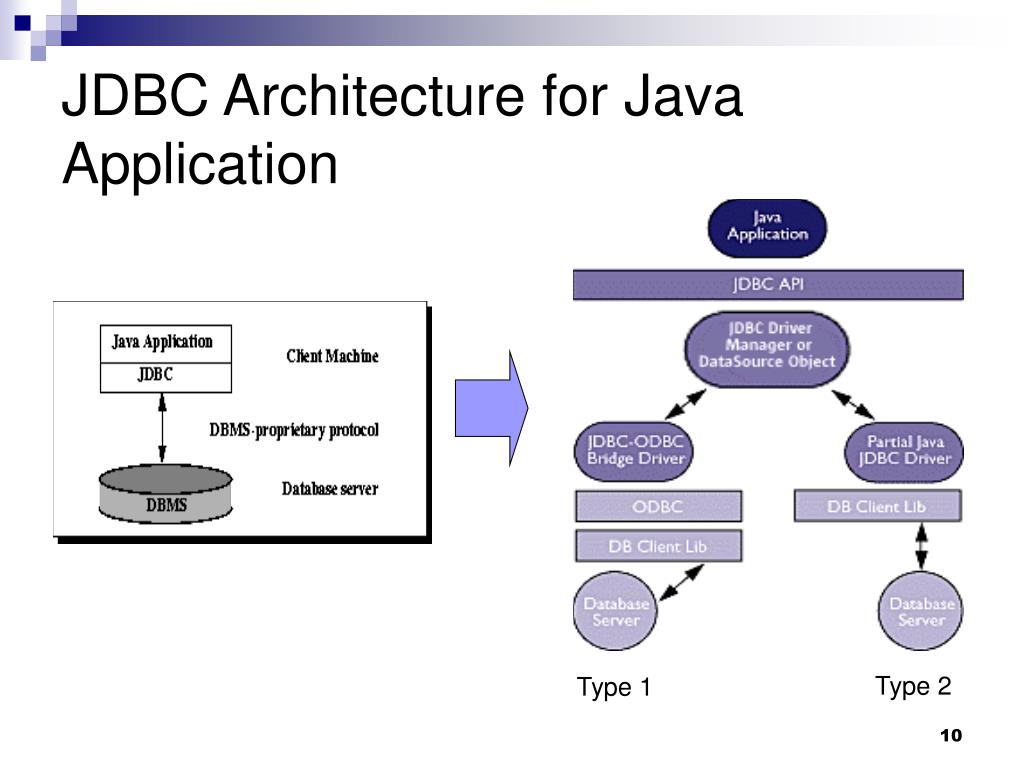 чтобы вы могли открывать подключения к базам данных, выполнять команды SQL и
результаты обработки. Следовательно, Java-программы могут использовать
знакомая модель программирования SQL для выдачи операторов SQL и
обработка полученных данных. Классы JDBC включены в Java
1.1+ и Java 2 в виде пакета java.sql.
чтобы вы могли открывать подключения к базам данных, выполнять команды SQL и
результаты обработки. Следовательно, Java-программы могут использовать
знакомая модель программирования SQL для выдачи операторов SQL и
обработка полученных данных. Классы JDBC включены в Java
1.1+ и Java 2 в виде пакета java.sql.
API JDBC определяет следующее:
Библиотека вызовов функций JDBC, которые подключаются к базе данных, выполнять операторы SQL и получать результаты
Стандартный способ подключения и входа в СУБД
Синтаксис SQL на основе интерфейса X/Open SQL Call Level или X/Open и SQL Access Group (SAG) Спецификация CAE (1992 г.
 )
)Стандартное представление для типов данных
Стандартный набор кодов ошибок
Как работают API JDBC реализовано
Реализации JDBC API делятся на две большие категории:
которые взаимодействуют с существующим драйвером ODBC (мост JDBC-ODBC) и
те, которые взаимодействуют с собственным API базы данных (драйвер JDBC, который
преобразует вызовы JDBC в протокол связи, используемый
конкретного поставщика базы данных). Реализация JDBC в InfoMaker
интерфейс может использоваться для подключения к любой базе данных, для которой
Существует JDBC-совместимый драйвер.
JDB InfoMaker интерфейс
Виртуальная машина Java (JVM) требуется для интерпретации и выполнения байт-код Java-программы. Интерфейс JDB InfoMaker поддерживает Sun Java Runtime Environment (JRE) версии 1.2 и выше.
Компоненты соединения JDBC
Как устроено соединение JDBC сделал
В InfoMaker при доступе к базе данных через JDBC интерфейс, ваше соединение проходит через несколько уровней, прежде чем достичь базу данных. Важно понимать, что каждый слой представляет собой отдельный компонент соединения, и что каждый компонент может прийти от другого поставщика.
Поскольку JDBC – это стандартный API, InfoMaker использует тот же интерфейс. для доступа к каждому JDBC-совместимому драйверу базы данных.
для доступа к каждому JDBC-совместимому драйверу базы данных.
На следующем рисунке показаны основные компоненты JDBC. связь.
Рисунок: Компоненты соединения JDBC
JDBC DLL
InfoMaker предоставляет pbjdb190.dll. Эта DLL работает с солнцем Java Runtime Environment (JRE) версии 1.1 и выше.
Пакет InfoMaker Java
InfoMaker включает небольшой пакет классов Java, который предоставляет Интерфейс JDBC уровень проверки ошибок и эффективности (SQLException catching), которые можно найти в других интерфейсах InfoMaker. Пакет называется pbjdbc12190.jar и находится в папке Appeon\Shared\PowerBuilder.
Виртуальная машина Java
Виртуальная машина Java (JVM) — это компонент разработки Java
программного обеспечения. При установке InfoMaker пакет Sun Java Development Kit
(JDK), включая Java Runtime Environment (JRE), установлен на
вашей системы в Appeon\Shared\PowerBuilder. Для InfoMaker 2017 и более поздних версий JDK 1.6
установлен. Эта версия JVM запускается при использовании JDBC.
соединение или любой другой процесс, который требует JVM и используется
на протяжении всего сеанса InfoMaker.
При установке InfoMaker пакет Sun Java Development Kit
(JDK), включая Java Runtime Environment (JRE), установлен на
вашей системы в Appeon\Shared\PowerBuilder. Для InfoMaker 2017 и более поздних версий JDK 1.6
установлен. Эта версия JVM запускается при использовании JDBC.
соединение или любой другой процесс, который требует JVM и используется
на протяжении всего сеанса InfoMaker.
Если вам нужно использовать другую JVM, см. инструкции в разделе Подготовка к использованию JDBC. интерфейс. Дополнительные сведения о том, как запускается JVM, см. главу о развертывании вашего приложения в Руководстве пользователя.
Драйверы JDBC
Интерфейс JDBC может взаимодействовать с любым JDBC-совместимым драйвером
включая SAP Sybase jConnect для JDBC и Oracle и IBM Informix
JDBC-драйверы. Эти драйверы являются полностью Java-драйверами собственного протокола.
то есть они преобразуют вызовы JDBC в синтаксис SQL, поддерживаемый
базы данных.
Эти драйверы являются полностью Java-драйверами собственного протокола.
то есть они преобразуют вызовы JDBC в синтаксис SQL, поддерживаемый
базы данных.
Доступ к данным Unicode
Используя интерфейс ODBC, InfoMaker может подключаться, сохранять и извлекать данные из баз данных ANSI/DBCS и Unicode, но не конвертировать данные между Unicode и ANSI/DBCS. Когда символьные данные или текст команды отправляется в базу данных, InfoMaker отправляет строку Unicode. Драйвер должен гарантировать, что данные сохранены как данные Unicode. правильно. Когда InfoMaker извлекает символьные данные, он предполагает, что данные является Юникод.
База данных Unicode — это база данных, для которой установлен набор символов
Формат Unicode, например UTF-8, UTF-16, UCS-2 или UCS-4. Все данные должны быть
в формате Unicode, и любые данные, сохраненные в базе данных, должны быть преобразованы
к данным Unicode неявно или явно.
Все данные должны быть
в формате Unicode, и любые данные, сохраненные в базе данных, должны быть преобразованы
к данным Unicode неявно или явно.
База данных, использующая ANSI (или DBCS) в качестве набора символов, может использовать специальные типы данных для хранения данных Unicode. Эти типы данных: NCHAR, NVARCHAR и NVARCHAR2. Столбцы с этим типом данных могут хранить только данные Unicode. Любые данные, сохраненные в таком столбце, должны быть преобразованы в Unicode явно. Это преобразование должно обрабатываться базой данных. сервер или клиент.
Записи реестра JDBC
При доступе к данным через интерфейс JDBC InfoMaker
InfoMaker использует внутренний реестр для хранения определений
Синтаксис SQL, вызовы функций, характерные для СУБД, и параметр DBParm по умолчанию. настройки серверной СУБД. Этот внутренний реестр в настоящее время
включает подстатьи для SQL Anywhere, Adaptive Server Enterprise и
Базы данных Оракл.
настройки серверной СУБД. Этот внутренний реестр в настоящее время
включает подстатьи для SQL Anywhere, Adaptive Server Enterprise и
Базы данных Оракл.
В большинстве случаев вам не нужно изменять записи JDBC. Однако, если вам нужно настроить существующие записи или добавить новые записи, вы может вносить изменения в системный реестр, редактируя реестр напрямую или выполнение файла реестра. Изменения, которые вы вносите в систему реестр переопределяет внутренние записи реестра InfoMaker. См. egreg.txt в Appeon\Shared\PowerBuilder для примера файл реестра, который вы можете выполнить, чтобы изменить настройки записи.
Поддерживаемые версии для JDBC
Интерфейс JDBC InfoMaker использует pbjdb190. dll для доступа к
базы данных через драйвер JDBC.
dll для доступа к
базы данных через драйвер JDBC.
Чтобы использовать интерфейс JDBC для доступа к драйверу jConnect, используйте jConnect версии 4.2 или выше или jConnect версии 5.2 или выше. За информацию о jConnect см. в документации по SAP.
Чтобы использовать интерфейс JDBC для доступа к драйверу JDBC Oracle, используйте Драйвер Oracle 8 JDBC версии 8.0.4 или выше. Для получения информации о Драйвер Oracle JDBC, см. документацию Oracle.
Поддерживаемые типы данных JDBC
Подобно ODBC, интерфейс JDBC компилирует, сортирует, представляет и использует список типов данных, которые являются родными для внутренней базы данных для эмуляции максимально поведение родного интерфейса.
Источник данных JDBC — Upsolver
Источник данных JDBC
В этой статье представлено введение в JDBC, а также руководство по созданию источника данных JDBC в Upsolver.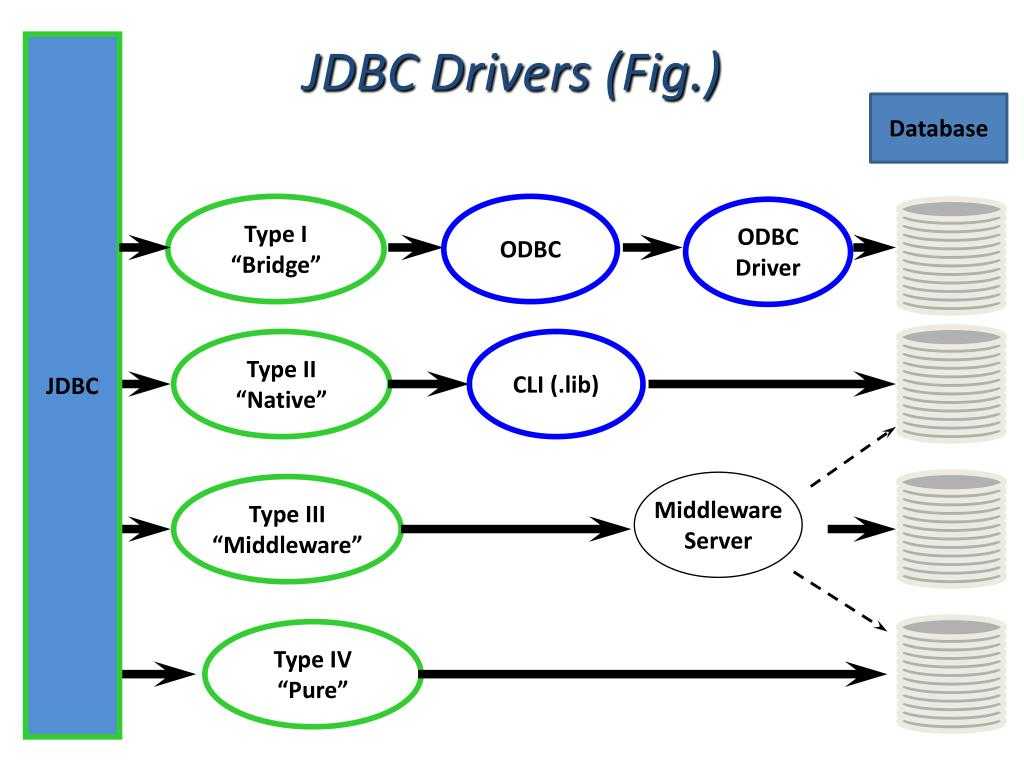
Java Database Connectivity (JDBC) — это интерфейс прикладного программирования (API) для языка программирования Java, который определяет, как клиент может получить доступ к базе данных. Это технология доступа к данным на основе Java, используемая для подключения к базе данных Java и являющаяся частью платформы Java Standard Edition корпорации Oracle.
Upsolver поддерживает загрузку данных из следующих источников JDBC:
Microsoft SQL Server
PostgreSQL
Amazon Redshift
Snowflake
Oracle
Можно также добавить другие базы данных. Пожалуйста, свяжитесь с Upsolver.
Источник данных JDBC имеет три режима работы для определения изменений.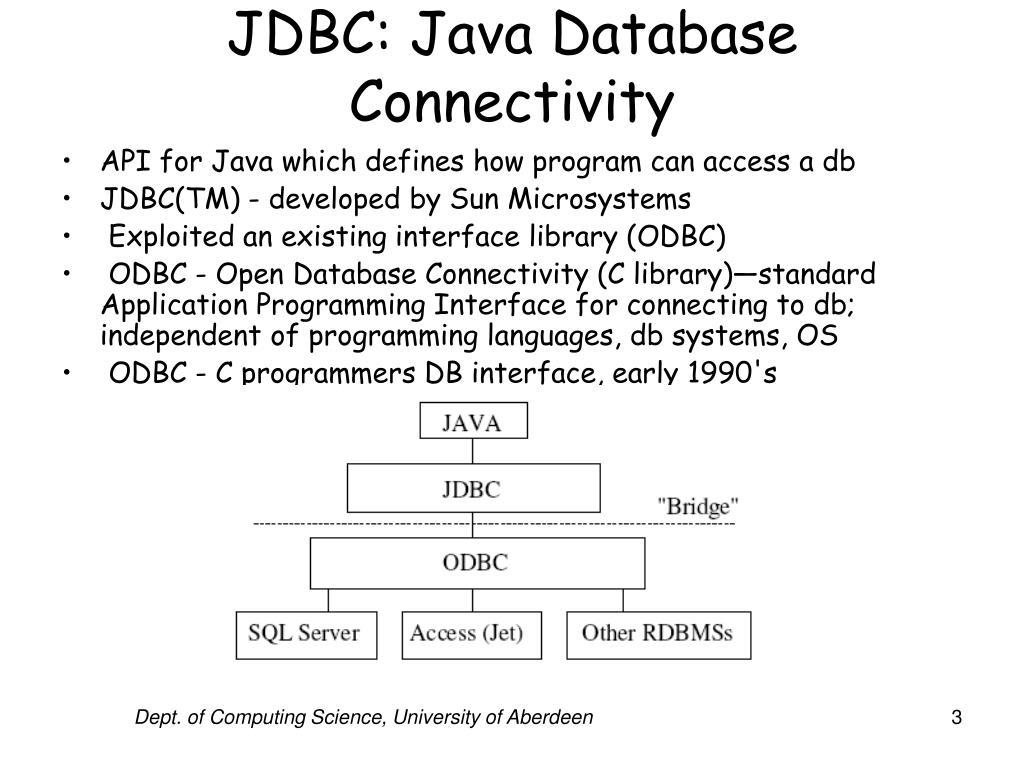
Комментарии
1
.
По столбцу
По отметке времени
Запрос по столбцу с отметкой времени , который должен быть проиндексирован. В противном случае база данных будет выполнять полное (и, возможно, дорогостоящее) сканирование данных каждую минуту.
2. С помощью ключа с автоинкрементом
Запрос данных на основе значения или ключа с автоинкрементом. Значение должно быть проиндексировано, чтобы избежать полного сканирования таблицы.
Значение должно быть проиндексировано, чтобы избежать полного сканирования таблицы.
3. Захват всей таблицы периодически
Может использоваться для периодической загрузки справочных данных.
Для режимов 1 и 2 требуется таблица, содержащая столбец, из которого Upsolver может запрашивать новые изменения. Столбец должен обновляться каждый раз, когда Upsolver считывает изменение данной строки. Комбинация режима 1 и режима 2 также может использоваться вместе.
По умолчанию источник данных JDBC выполняет полную начальную загрузку с последующими добавочными обновлениями.
1. На странице Источники данных нажмите Создать.
2. Выберите JDBC .
3. Назовите этот источник данных.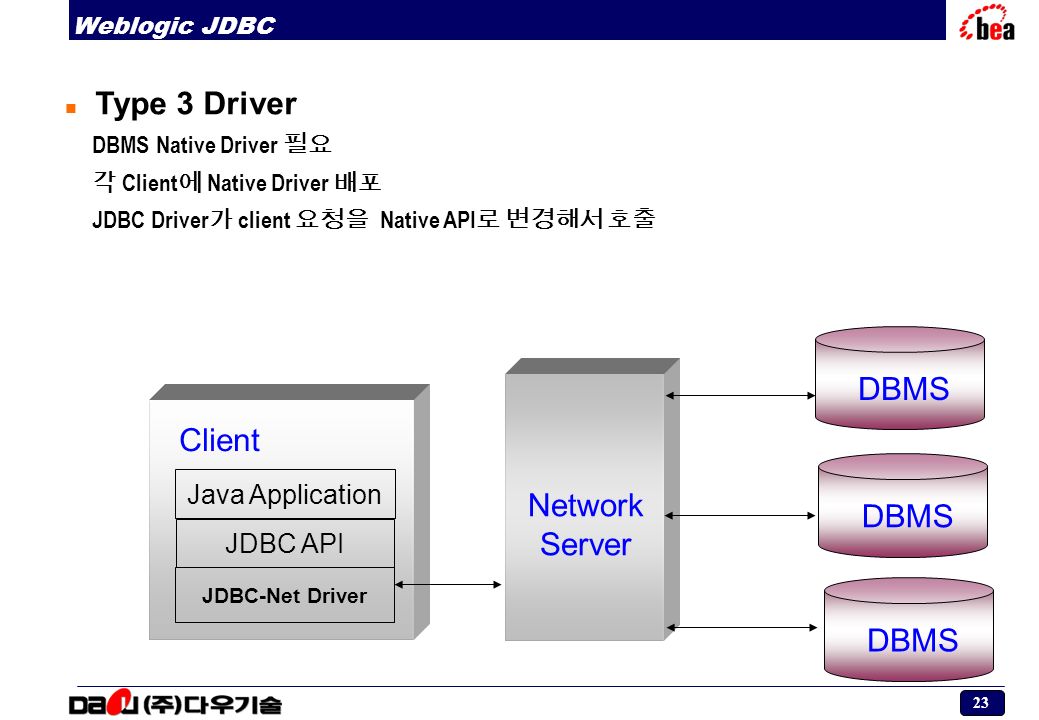
4. В раскрывающемся списке выберите вычислительный кластер (или создайте новый) для выполнения вычисления.
5. Выберите целевое подключение к хранилищу (или создайте новое), где будут храниться прочитанные данные (выходное хранилище).
6. В поле Parallelism введите количество независимых осколков для анализа данных, увеличения параллелизма и уменьшения задержки.
В большинстве случаев это значение должно оставаться равным 1 и не превышать количество осколков, используемых для чтения данных из источника.
7. Введите строку подключения JDBC .
См. : Соединения для получения дополнительной информации о формате строки для определенного типа соединения.
: Соединения для получения дополнительной информации о формате строки для определенного типа соединения.
8. (Необязательно) Настройка любых дополнительных свойства необходимые для подключения.
9. Введите в соединение имя пользователя .
10. Введите соответствующий пароль .
11. Введите имя таблицы для подключения.
12. (Необязательно) Определите столбец увеличения .
Значение этого столбца всегда увеличивается.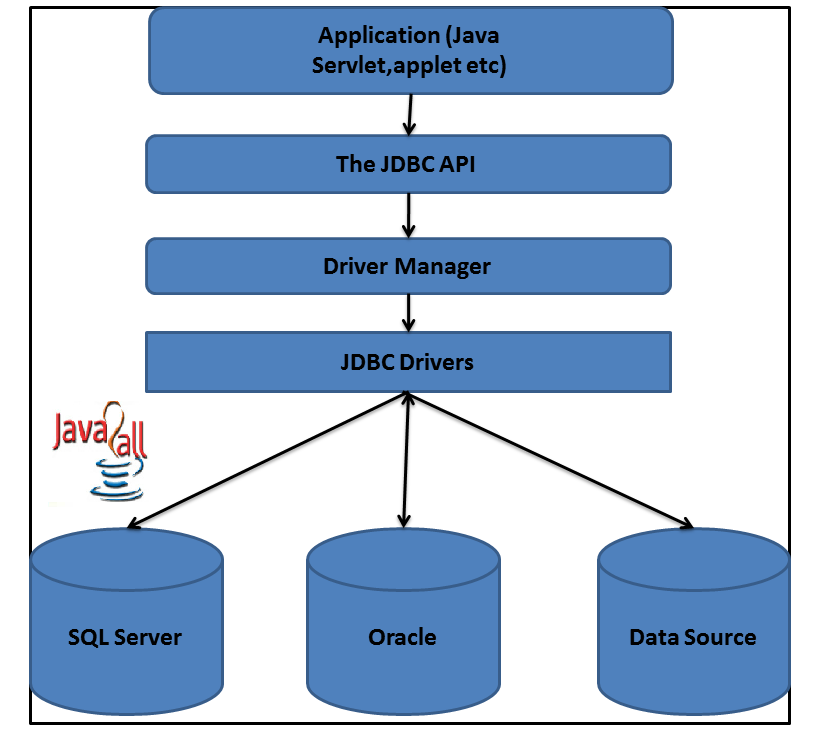
Каждый раз, когда данные загружаются, они начинаются с числа, следующего за последним загруженным числом (например, столбец идентификаторов).
Если вы не укажете увеличивающийся столбец, Upsolver автоматически попытается определить увеличивающийся столбец.
13. (Необязательно) Определите все столбцов меток времени .
Это столбец с меткой времени. Когда источник данных выполняется, он запрашивает данные для строк с более поздней отметкой времени.
Также поддерживаются несколько столбцов меток времени. Если указать несколько столбцов меток времени, запрос использует первую найденную непустую метку времени.
Примеры:
Если у вас есть два столбца
(время1, время2)и в определенной строке есть запись только в форматеtime2, это будет использоваться.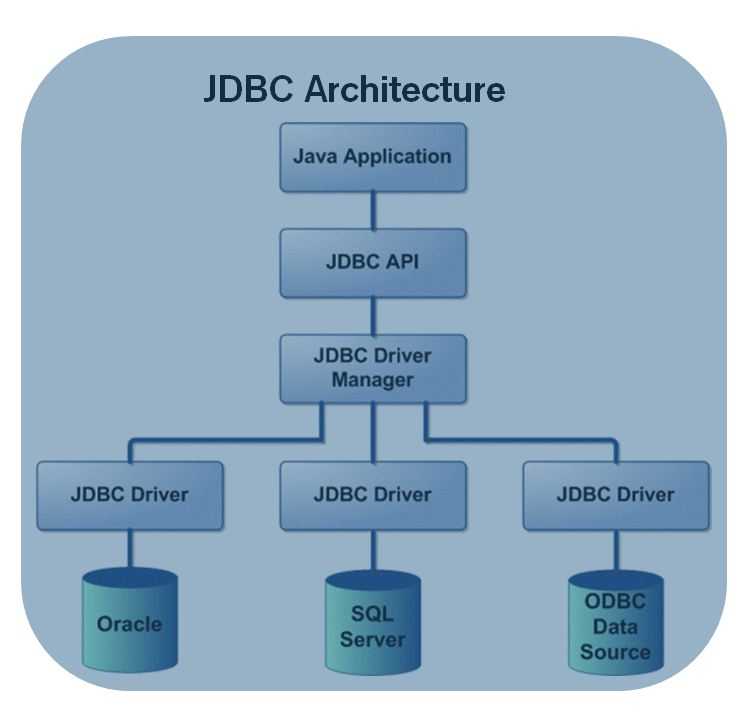
Если есть запись как в
time1, так и вtime2, используется метка времени изtime1.
Вы также можете указать столбец приращения и столбец отметки времени .
В этом случае он запрашивает данные для строк с более поздней отметкой времени или строк с ранее существовавшей отметкой времени, но с более высоким значением в увеличивающемся столбце.
14. (Необязательно) Установите задержку чтения (в секундах), чтобы обеспечить буфер для того, как далеко назад во времени можно просмотреть данные.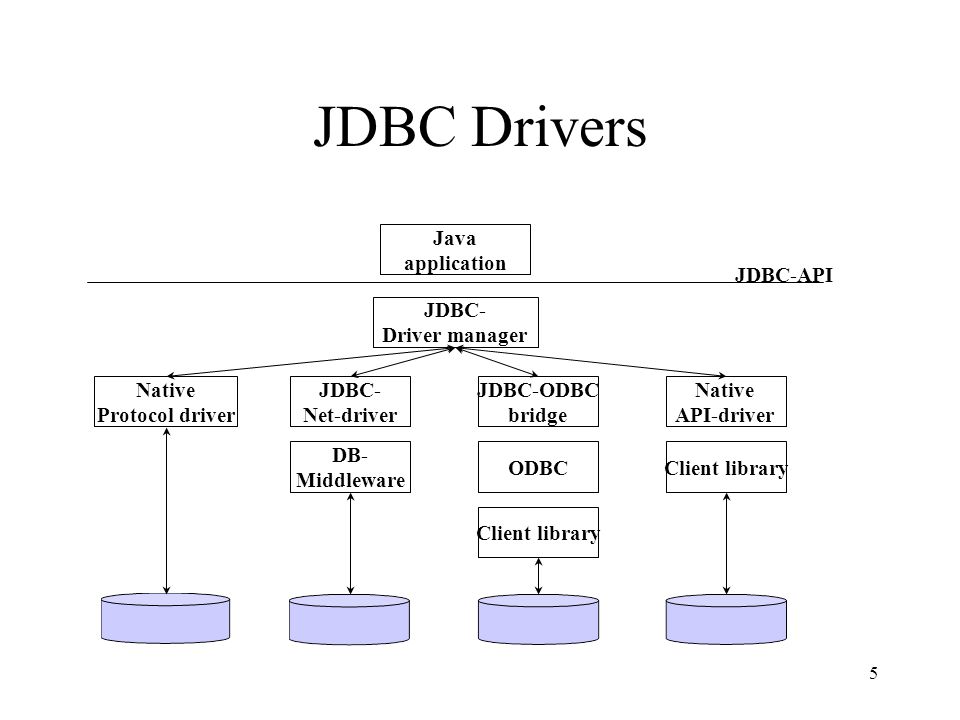
Это может быть полезно, например, когда столбец метки времени округлен до минут, задержка чтения в 30 секунд может гарантировать, что вы не пропустите ни одной важной строки.
15. (Необязательно) Введите интервал полной загрузки .
16. Щелкните Продолжить для предварительного просмотра данных и просмотра следующих показателей:
Размер выборки
СПАСИВАНИЕ Успешно
# ошибок
17.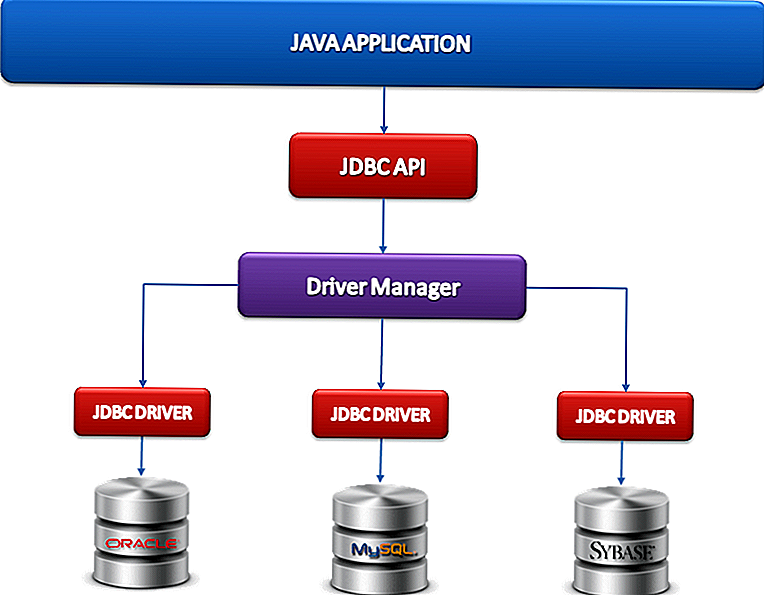 (Обязательно). Если есть ошибки, нанесите на работу.
(Обязательно). Если есть ошибки, нанесите на работу.
18. Нажмите Создать .
Теперь вы можете использовать источник данных JDBC.
Назад
Репликация базы данных PostgreSQL CDC
Далее — Подключение источников данных 9На этой странице
ScalikeJDBC — это аккуратная библиотека доступа к базе данных на основе SQL для разработчиков Scala. Эта библиотека естественным образом объединяет API-интерфейсы JDBC и предоставляет вам простые в использовании и очень гибкие API-интерфейсы. Более того, QueryDSL делает ваш код типобезопасным и пригодным для повторного использования.
ScalikeJDBC является практичным и готовым к производству. Используйте эту библиотеку для своих реальных проектов.
Работа на уровне JDBC
Нравится вам это или нет, JDBC — это стабильный стандартный интерфейс. Поскольку большинство СУБД поддерживает интерфейс JDBC, мы можем получить доступ к СУБД таким же образом. Мы никогда не выпускаем без прохождения всех модульных тестов со следующими РСУБД.
Мы никогда не выпускаем без прохождения всех модульных тестов со следующими РСУБД.
- PostgreSQL
- MySQL
- Ядро базы данных h3
- ХСКДБ
Мы считаем, что ScalikeJDBC в основном работает с любой другой СУБД (Oracle, SQL Server и т. д.).
Amazon Redshift, Facebook Presto также поддерживает JDBC
Если вы можете получить доступ к какому-либо хранилищу данных через интерфейс JDBC, это означает, что вы также можете получить к нему доступ через ScalikeJDBC.
В последнее время Amazon Redshift и Facebook Presto поддерживают интерфейс JDBC. Вы можете получить к ним доступ через ScalikeJDBC!
Мало зависимостей
Ядро ScalikeJDBC имеет так мало зависимостей, что вас не будет беспокоить ад зависимостей.
- Необходимые драйверы JDBC
- Общий ДБКП
- SLF4J API
Конечно, вы можете использовать c3p0 (или другие) вместо commons-dbcp, хотя реализация ConnectionPool для этого не предусмотрена по умолчанию.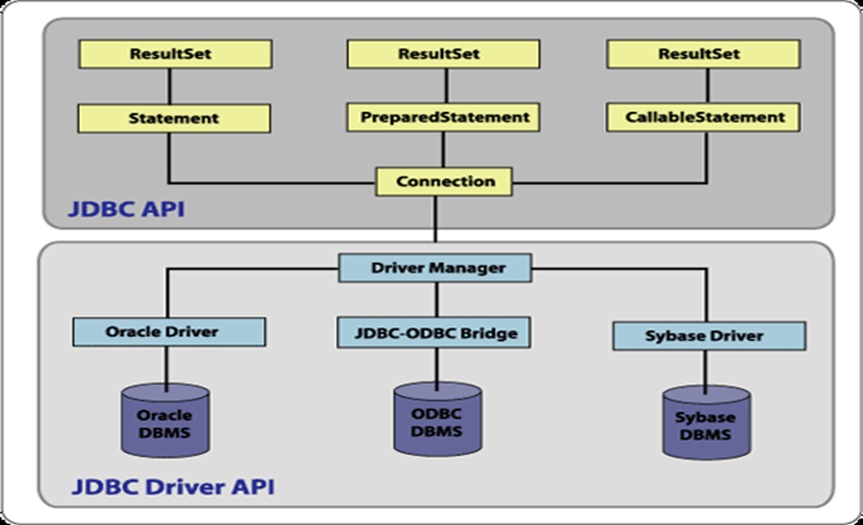
Неблокирующий?
К сожалению, нет. Действительно, драйверы JDBC блокируют ввод-вывод сокета. Таким образом, их использование для взаимодействия с СУБД в асинхронной архитектуре, управляемой событиями, может быть неуместным. Однако на самом деле большинству реальных приложений еще не нужна архитектура, управляемая событиями. JDBC по-прежнему является важной инфраструктурой для приложений на JVM.
Если вы действительно предпочитаете неблокирующий доступ к базе данных, взгляните на ScalikeJDBC-Async. Он предоставляет неблокирующие API для взаимодействия с PostgreSQL и MySQL способом JDBC.
https://github.com/scalikejdbc/scalikejdbc-async
ScalikeJDBC-Async все еще находится на стадии альфа-тестирования. Если у вас нет мотивации самостоятельно исследовать или исправлять проблемы, мы рекомендуем подождать, пока когда-нибудь не будет выпущена стабильная версия.
Часто задаваемые вопросы
См. также часто задаваемые вопросы здесь: /documentation/faq. html
html
Начало работы
Все, что вам нужно сделать, это добавить ScalikeJDBC, драйвер JDBC и реализацию slf4j.
ScalikeJDBC 4.x
ScalikeJDBC 4 требует Java SE 8 или выше. Если вам по-прежнему нужно запускать приложения на Java SE 7, продолжайте использовать ScalikeJDBC 2.5.
// Скала 2.12, 2.13 и 3 libraryDependencies ++= Seq( "org.scalikejdbc" %% "scalikejdbc" % "4.0.0", "com.h3database" % "h3" % "1.4.200", "ch.qos.logback" % "logback-classic" % "1.2.3" )
ScalikeJDBC 2.x
Подробности см. в документации ScalikeJDBC 2.x.
// Скала 2.10, 2.11, 2.12 libraryDependencies ++= Seq( "org.scalikejdbc" %% "scalikejdbc" % "2.5.2", "com.h3database" % "h3" % "1.4.200", "ch.qos.logback" % "logback-classic" % "1.2.3" )
Первый пример
Поместите вышеуказанные зависимости в ваш build.sbt и запустите консоль sbt .
импорт scalikejdbc._ // инициализируем JDBC-драйвер и пул соединений Class.forName("org.h3.Драйвер") ConnectionPool.singleton("jdbc:h3:mem:hello", "пользователь", "проход") // специальный провайдер сеанса в REPL неявный сеанс val = AutoSession // создание таблицы, вы можете запустить DDL с помощью #execute так же, как JDBC sql""" создать элементы таблицы ( id серийный номер не нулевой первичный ключ, имя varchar(64), created_at временная метка не нулевая ) """.выполнить.применить() // вставляем исходные данные Seq("Алиса", "Боб", "Крис") foreach { name => sql"вставить в элементы (имя, created_at) значения (${имя}, current_timestamp)".update.apply() } // на данный момент извлекает все данные как значение Map val entity: List[Map[String, Any]] = sql"select * frommembers".map(_.toMap).list.apply() // определяет объект сущности и экстрактор импортировать java.time._ Член класса case (id: Long, name: Option [String], createdAt: ZonedDateTime) Член объекта расширяет SQLSyntaxSupport[Member] { переопределить val tableName = "члены" def apply(rs: WrappedResultSet) = новый член( rs.
long("id"), rs.stringOpt("name"), rs.zonedDateTime("created_at")) } // найти все члены члены val: List[Member] = sql"select * frommembers".map(rs => Member(rs)).list.apply() // используем режим вставки (:paste) в Scala REPL val m = Member.syntax("m") имя = "Алиса" val alice: Option[Member] = withSQL { select.from(Член как m).where.eq(m.name, name) }.map(rs => Member(rs)).single.apply()
Как все прошло? Если вы хотите узнать больше деталей или практических примеров, см. документацию.
Краткий обзор
Использование только стандартного API Scala и SQL
Пользователям библиотек не нужно изучать так много правил и соглашений, связанных с библиотекой. Если вы уже знакомы с API стандартной библиотеки Scala и базовыми SQL, этого должно быть достаточно.
val имя = "Алиса"
// неявный сеанс представляет java.sql.Connection
val memberId: Option[Long] = DB readOnly { неявный сеанс =>
sql"выберите идентификатор из участников, где name = ${name}" // не беспокойтесь, предотвращает внедрение SQL
. map(rs => rs.long("id")) // извлекает значения из богатого java.sql.ResultSet
.single // одиночный, список, проходимый
.apply() // Побочный эффект!!! запускает SQL, используя Connection
}
map(rs => rs.long("id")) // извлекает значения из богатого java.sql.ResultSet
.single // одиночный, список, проходимый
.apply() // Побочный эффект!!! запускает SQL, используя Connection
}
Подробнее см.: /documentation/operations
Type-safe DSL
Начиная с версии 1.6, доступен QueryDSL. Это похожий на SQL и типобезопасный DSL для создания DRY SQL.
Вот пример:
val (p, c) = (Programmer.syntax("p"), Company.syntax("c"))
val программисты: Seq[Programmer] = DB.readOnly { неявный сеанс =>
с SQL {
Выбрать
.from (программист как p)
.leftJoin(Компания как c).on(p.companyId, c.id)
.where.eq(p.isDeleted, false)
.orderBy(p.createdAt)
.лимит(10)
.смещение (0)
}.map(Программист(p, c)).list.apply()
}
Подробнее см.: /documentation/query-dsl
Тестовый код: src/test/scala/scalikejdbc/QueryInterfaceSpec.scala
Гибкое управление транзакциями
ScalikeJDBC предоставляет несколько API для управления сессиями/транзакциями.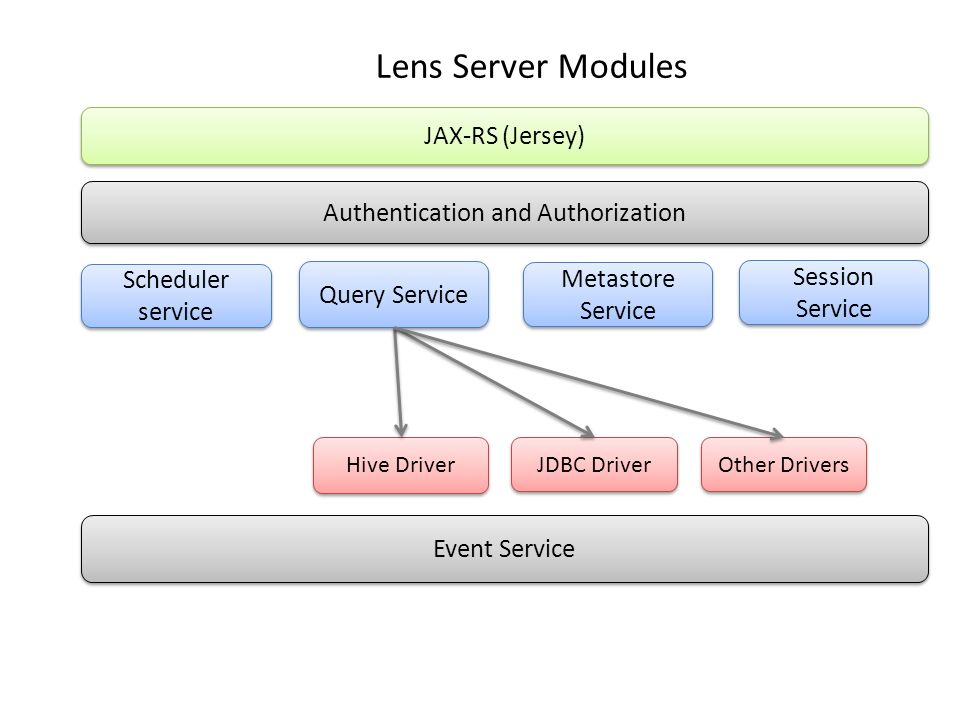
- DB autoCommit { неявный сеанс => … }
- БД localTx { неявный сеанс => … }
- БД внутри Tx { неявный сеанс => … }
- БД только для чтения { неявный сеанс => … }
Вот пример повторного использования методов как в простых вызовах, так и в транзакционных операциях.
объект Продукт {
def create(name: String, price: Long)(неявный s: DBSession = AutoSession): Long = {
sql"вставить в значения товаров (${имя}, ${цена})"
.updateAndReturnGeneratedKey.apply() // возвращает автоматически увеличивающийся идентификатор
}
def findById (id: Long) (неявный s: DBSession = AutoSession): Option[Product] = {
sql"выберите идентификатор, имя, цену, created_at из продуктов, где идентификатор = ${id}"
.map {rs => Product(rs) }.single.apply()
}
}
Product.findById(123) // заимствует соединение из пула и возвращает его после выполнения
DB localTx { неявный сеанс => // транзакционный сеанс
val id = Product.create("ScalikeJDBC Cookbook", 200) // внутри транзакции
val product = Product.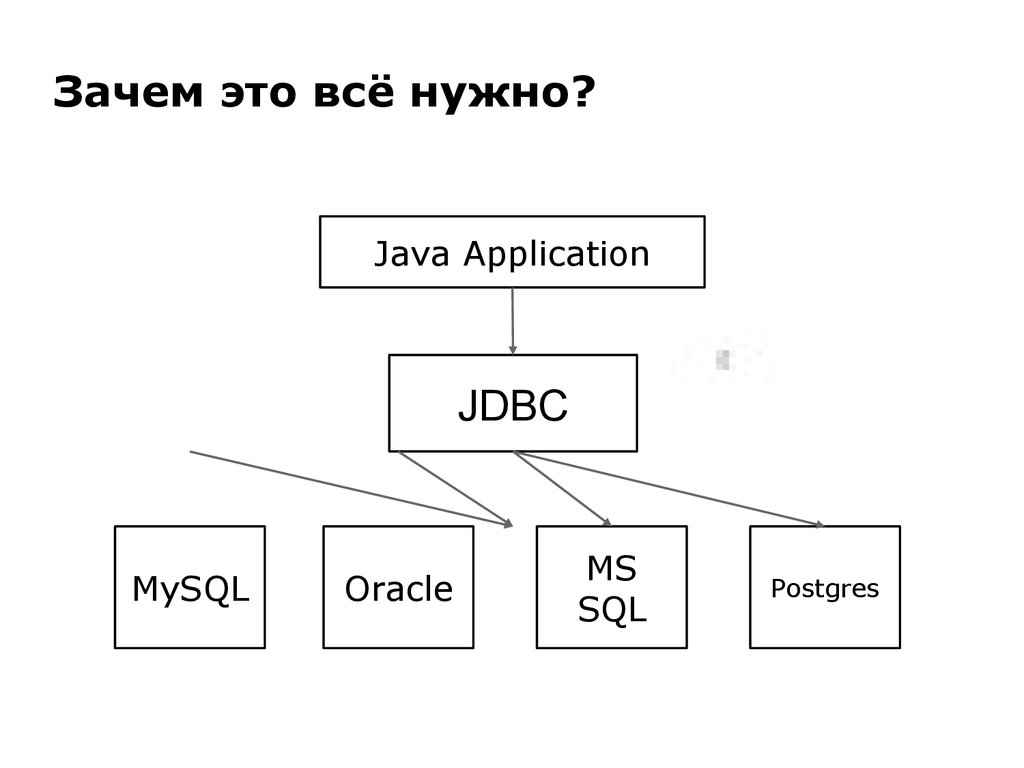 findById(id) // внутри транзакции
}
findById(id) // внутри транзакции
}
Подробнее см.: /documentation/transaction
Полезные проверки запросов
По умолчанию ScalikeJDBC показывает, какой SQL выполняется и где он находится. Мы считаем, что это весьма полезно для отладки ваших приложений. Регистрация только медленных запросов в рабочей среде, но это также помогает вам.
[отладка] s.StatementExecutor$$anon$1 — выполнение SQL завершено [Выполненный SQL] выберите идентификатор, имя от пользователей, где электронная почта = '[email protected]'; (3 мс) [Трассировки стека] ... модели.User$.findByEmail(User.scala:26) controllers.Projects$$anonfun$index$1$$anonfun$apply$1$$anonfun$apply$2.apply(Projects.scala:20) controllers.Projects$$anonfun$index$1$$anonfun$apply$1$$anonfun$apply$2.apply(Projects.scala:19) controllers.Secured$$anonfun$IsAuthenticated$3$$anonfun$apply$3.apply(Application.scala:88)
См. подробнее: /documentation/query-inspector
Поддержка тестирования
Поддержка тестирования, обеспечивающая следующие функции для ScalaTest и спецификаций2.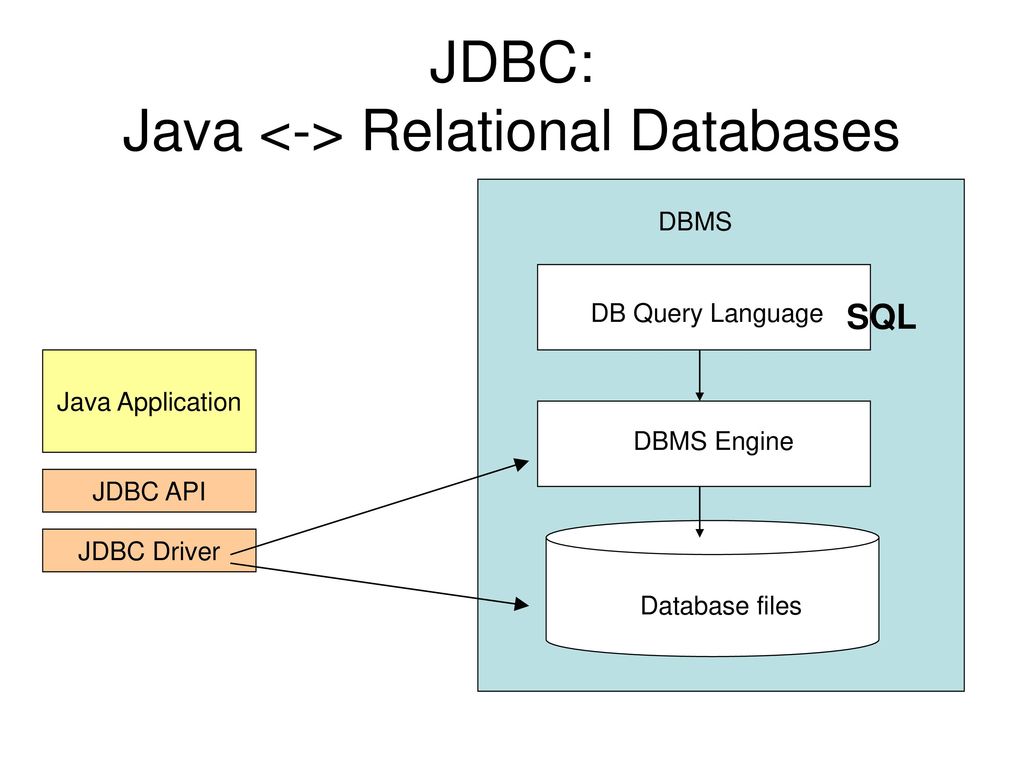
- Автоматический откат после каждого теста
- Испытание с приспособлениями
Подробнее см.: /documentation/testing
Реверс-инжиниринг
Вы можете легко получить код Scala из существующей базы данных, используя инструмент реверс-инжиниринга ScalikeJDBC.
sbt "scalikejdbcGen [имя таблицы (имя класса)]"
напр.
СБТ "Компания scalikejdbcGen" СБТ "Компания компаний scalikejdbcGen"
Подробнее см.: /documentation/reverse-engineering
Поддержка Play Framework
Вы можете беспрепятственно использовать ScalikeJDBC с Play framework 2. Мы обещаем вам, что он станет более продуктивным при использовании с scalikejdbc-mapper-generator.
Подробнее см.: /documentation/playframework-support
Поддержка Reactive Streams
ScalikeJDBC предоставляет интерфейс издателя Reactive Streams для подписки на поток из запроса к базе данных.
Подробнее: /documentation/reactivestreams-support
Мы используем ScalikeJDBC!
Многие компании уже используют ScalikeJDBC в своем бизнесе!
Подробнее.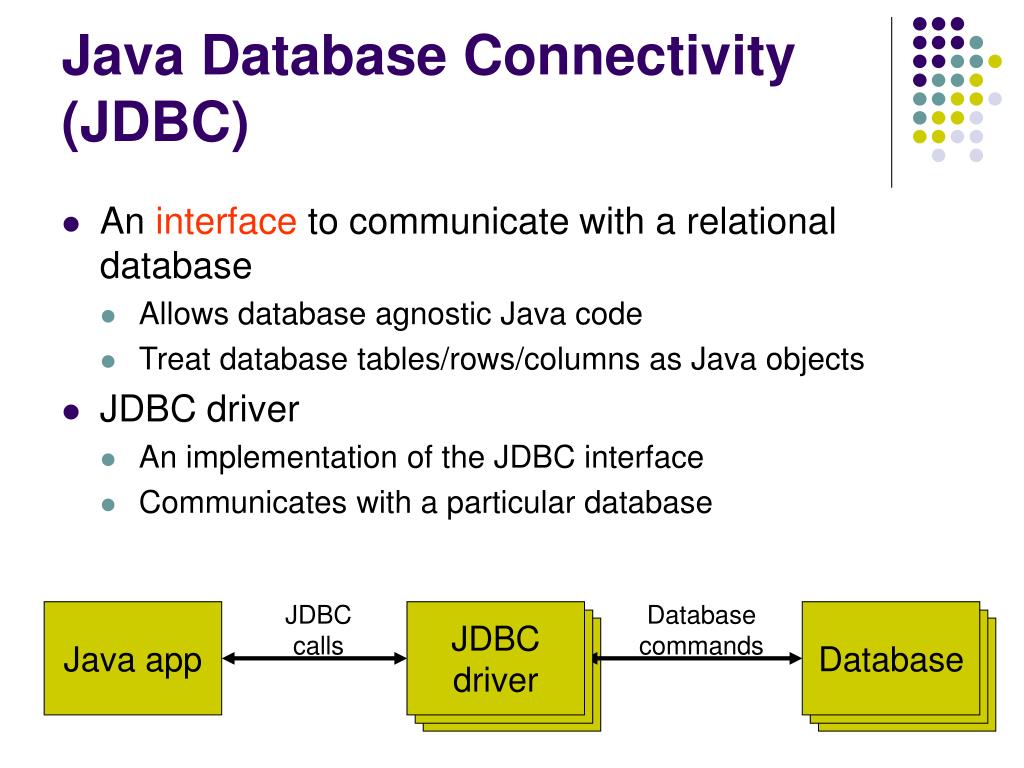 .
.
Лицензия
Опубликованные бинарные файлы имеют следующие авторские права:
Copyright scalikejdbc.org Лицензия Apache, версия 2.0 http://www.apache.org/licenses/LICENSE-2.0.html
ScalikeJDBC-Async
Расширение ScalikeJDBC: неблокирующие API в стиле JDBC.
github.com/scalikejdbc/scalikejdbc-async
ScalikeJDBC-Async предоставляет неблокирующие API для взаимодействия с PostgreSQL и MySQL способом JDBC.
Эта библиотека создана с помощью jasync-sql.
dbconsole
dbconsole — это расширенная консоль sbt для подключения к базе данных.
Mac OS X, Linux
curl -L https://git.io/dbcon | ш
Windows
https://git.io/dbcon.bat
Подробнее см.: /documentation/dbconsole
Skinny ORM
Skinny ORM — это библиотека доступа к БД по умолчанию для Skinny Framework. Skinny ORM построен на основе ScalikeJDBC.
В большинстве случаев ORM упрощает работу.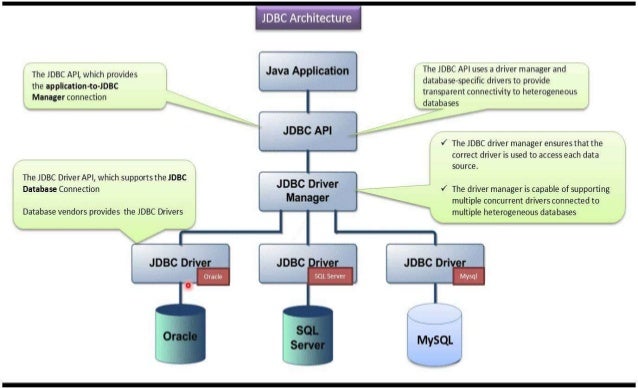
https://skinny-framework.github.io/documentation/orm.html
Если на этой веб-странице есть опечатка или что-то не так, сообщите об этом или исправьте. Как?
Соображения перед виртуализацией JDBC
поиск отменить
Рекомендации перед виртуализацией JDBC
книга
Артикул №: 10285
календарь_сегодня
Дата обновления:
Продукты
CA Continuous Application Insight (PathFinder) Виртуализация служб
Проблема/Введение
JDBC Виртуализация может быть очень мощной. Тем не менее, есть несколько областей, которые необходимо рассмотреть перед записью транзакций.
Предварительное условие: агент DevTest должен быть установлен до захвата транзакций JDBC. Если вам нужна помощь в установке агента DevTest, отправьте заявку в службу поддержки.
Виртуализация JDBC не предназначена для замены базы данных. Он предназначен для виртуализации небольшого количества вызовов относительно статической базы данных.
Предупреждения из документации DevTest:
- JDBC — это болтливый протокол. Например, несколько щелчков в пользовательском интерфейсе, извлекающем данные из базы данных, могут привести к огромному количеству вызовов JDBC API. Такое поведение может затруднить правильное моделирование. Если вы хотите захватить и виртуализировать трафик базы данных JDBC, подумайте о том, чтобы сделать это на более высоком уровне.
- Эта функция поддерживается в этом выпуске, хотя мы не рекомендуем пользователям использовать эту функцию без прямого руководства со стороны специалиста CA. Специалист CA может помочь оценить ваш конкретный вариант использования и определить наилучший метод виртуализации.
Причина
Н/Д
Окружающая среда
Все поддерживаемые платформы DevTest.
Разрешение
Конкретные вопросы, которые следует учитывать перед захватом транзакций JDBC:
- Поддерживаемые базы данных и драйверы:
Поскольку JDBC очень болтлив, поддерживаются только определенные версии баз данных и драйверов. См. документацию для конкретной версии DevTest. - Размер ResultSet:
То, как программа обрабатывает ResultSet, сильно отличается от того, как его обрабатывает агент.- Программа: Получает курсор (указатель) на ResultSet. Программа обычно обрабатывает ResultSet по одной строке за раз, используя ResultSet.next().
Требования к памяти и процессору ограничены обработкой одной строки данных. - Агент: Агент должен захватывать весь ResultSet как объект, а не только одну строку. Затем объект сериализуется и отправляется брокеру для дальнейшей обработки.
Память: Содержит две полные копии ResultSet; один для исходного объекта и один для сериализованного объекта.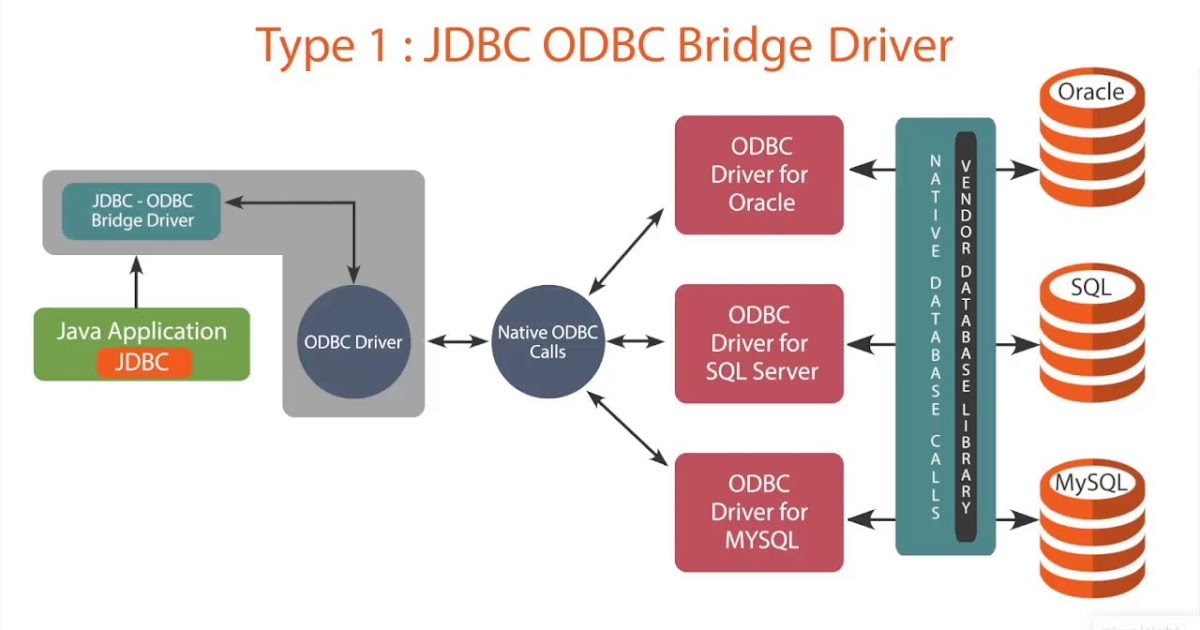 Может привести к ошибкам Out Of Memory или сборке мусора.
Может привести к ошибкам Out Of Memory или сборке мусора.
ЦП: необходимо обработать весь набор результатов, а затем сериализовать его. Может привести к перегрузке ЦП, тайм-аутам соединения и другим ошибкам.
- Программа: Получает курсор (указатель) на ResultSet. Программа обычно обрабатывает ResultSet по одной строке за раз, используя ResultSet.next().
- Типы вызовов базы данных:
Виртуализация JDBC предназначена для вызовов, которые возвращают ResultSet и могут иметь проблемы с обработкой других типов вызовов.
Операторы Select: обычно ограничиваются только размером (см. выше).
Вставка и удаление: обычно обрабатываются правильно, но чрезмерные вставки и удаления могут вызвать проблемы.
Откат и т. д.: Эти команды могут повлиять на несколько таблиц и не должны быть виртуализированы. - Виртуализация JDBC не является заменой базы данных:
База данных — это сложная программа. Виртуализация вызовов JDBC фиксирует наборы результатов, которые были возвращены во время записи. По этим причинам нельзя ожидать, что виртуализированные транзакции будут вести себя как база данных.
Банковский пример: если у вас есть начальный баланс в 500 долларов и вы вносите 100 долларов, база данных и программа знают, что баланс составляет 600 долларов. Все виртуализированные транзакции знают, что вход в размере 100 долларов США привел к возврату в размере 600 долларов США. Он не знает, как было рассчитано это значение. Использование виртуализированных транзакций со стартовым балансом 500 долларов США; внесение 200 долларов не приведет к возврату 700 долларов. - VSE
При развертывании виртуальной службы JDBC VSE уведомляет агентов о развертывании. Однако есть несколько ограничений:
- Одновременно может быть активна только одна виртуальная служба. Если развернуто несколько виртуальных служб JDBC, агент знает только о последнем развертывании.
- Все транзакции базы данных для данной комбинации агента и URL-адреса базы данных должны быть виртуализированы в одном vsi-файле. Если есть какие-либо отсутствующие транзакции, они приведут к ошибке «Совпадение не найдено».

- Все транзакции JDBC, которые видит агент, будут отправлены в VSE; независимо от URL-адреса подключения к базе данных. Любые обращения к другому URL-адресу подключения к базе данных приведут к ошибке «Соответствие не найдено».
- Расширение агента может изменить некоторые из указанных выше действий, но служба поддержки не может помочь в написании или отладке расширения. Обратитесь за помощью в CA Professional Services.
В большинстве случаев порядок записи транзакций должен совпадать с порядком, используемым при воспроизведении.
Нет возможности записывать транзакции JDBC без сохранения состояния
Альтернативы виртуализации JDBC:
Решите, что именно вы пытаетесь протестировать. Вы тестируете класс, выполняющий вызовы JDBC? Вы тестируете что-то еще?
- Виртуализация на более высоком уровне:
Если вы не тестируете класс, выполняющий вызовы JDBC, обычно вы можете двигаться вверх по стеку.