Опасности конструкторов / Хабр
Привет, Хабр! Представляю вашему вниманию перевод статьи «Perils of Constructors» автора Aleksey Kladov.
Один из моих любимых постов из блогов о Rust — Things Rust Shipped Without авторства Graydon Hoare. Для меня отсутствие в языке любой фичи, способной выстрелить в ногу, обычно важнее выразительности. В этом слегка философском эссе я хочу поговорить о моей особенно любимой фиче, отсутствующей в Rust — о конструкторах.
Конструкторы обычно используются в ОО языках. Задача конструктора — полностью инициализировать объект, прежде чем остальной мир увидит его. На первый взгляд, это кажется действительно хорошей идеей:
- Вы устанавливаете инварианты в конструкторе.
- Каждый метод заботится о сохранении инвариантов.
- Вместе эти два свойства значат, что можно думать об объектах как об инвариантах, а не как о конкретных внутренних состояниях.
Конструктор здесь играет роль индукционной базы, будучи единственным способом создать новый объект.
К сожалению, в этих рассуждениях есть дыра: сам конструктор наблюдает объект в незаконченном состоянии, что и создает множество проблем.
Когда конструктор инициализирует объект, он начинает с некоторого пустого состояния. Но как вы определите это пустое состояние для произвольного объекта?
Наиболее легкий способ сделать это — присвоить всем полям значения по умолчанию: false для bool, 0 для чисел, null для всех ссылок. Но такой подход требует, чтобы все типы имели значения по умолчанию, и вводит в язык печально известный null. Именно по этому пути пошла Java: в начале создания объекта все поля имеют значения 0 или null.
При таком подходе будет очень сложно избавиться от null впоследствии. Хороший пример для изучения — Kotlin. Kotlin использует non-nullable типы по умолчанию, но он вынужден работать с прежде существующей семантикой JVM. Дизайн языка хорошо скрывает этот факт и хорошо применим на практике, но несостоятелен. Иными словами, используя конструкторы, есть возможность обойти проверки на null в Kotlin.
Главная характерная черта Kotlin — поощрение создания так называемых «первичных конструкторов», которые одновременно объявляют поле и присваивают ему значение прежде, чем будет выполняться какой-либо пользовательский код:
class Person(
val firstName: String,
val lastName: String
) { ... }Другой вариант: если поле не объявлено в конструкторе, программист должен немедленно инициализировать его:
class Person(val firstName: String, val lastName: String) {
val fullName: String = "$firstName $lastName"
}Попытка использовать поле перед инициализацией запрещена статически:
class Person(val firstName: String, val lastName: String) {
val fullName: String
init {
println(fullName) // ошибка: переменная должна быть инициализирована
fullName = "$firstName $lastName"
}
}Но, имея немного креативности, любой может обойти эти проверки. Например, для этого подойдет вызов метода:
class A {
val x: Any
init {
observeNull()
x = 92
}
fun observeNull() = println(x) // выводит null
}
fun main() {
A()
}Также подойдет захват this лямбдой (которая создается в Kotlin следующим образом: { args -> body }):
class B {
val x: Any = { y }()
val y: Any = x
}
fun main() {
println(B(). x) // выводит null
}
x) // выводит null
}Примеры вроде этих кажутся нереальными в действительности (и так и есть), но я находил подобные ошибки в реальном коде (правило вероятности 0-1 Колмогорова в разработке ПО: в достаточно большой базе любой кусок кода почти гарантированно существует, по крайней мере, если не запрещен статически компилятором; в таком случае он почти точно не существует).
Причина, по которой Kotlin может существовать с этой несостоятельностью, та же, что и в случае с ковариантными массивами в Java: в рантайме все равно происходят проверки. В конце концов, я бы не хотел усложнять систему типов Kotlin, чтобы сделать вышеприведенные случаи некорректными на этапе компиляции: учитывая существующие ограничения (семантику JVM), отношение цена/польза проверок в рантайме намного лучше таковой у статических проверок.
А что, если язык не имеет разумного значения по умолчанию для каждого типа? Например, в C++, где определенные пользователем типы не обязательно являются ссылками, вы не можете просто присвоить null каждому полю и сказать, что это будет работать! Вместо этого в C++ используется специальный синтаксис для установления начальных значений полям: списки инициализации:
#include <string>
#include <utility>
class person {
person(std::string first_name, std::string last_name)
: first_name(std::move(first_name))
, last_name(std::move(last_name))
{}
std::string first_name;
std::string last_name;
};Так как это специальный синтаксис, остальная часть языка работает с ним небезупречно. Например, сложно поместить в списки инициализации произвольные операции, так как C++ не является фразированным языком (expression-oriented language) (что само по себе нормально). Чтобы работать с исключениями, возникающими в списках инициализации, необходимо использовать еще одну невразумительную фичу языка.
Например, сложно поместить в списки инициализации произвольные операции, так как C++ не является фразированным языком (expression-oriented language) (что само по себе нормально). Чтобы работать с исключениями, возникающими в списках инициализации, необходимо использовать еще одну невразумительную фичу языка.
Как намекают примеры из Kotlin, все разлетается в щепки, как только мы пытаемся вызвать метод из конструктора. В основном, методы ожидают, что объект, доступный через this, уже полностью сконструирован и корректен (соответствует инвариантам). Но в Kotlin или Java ничто не мешает вам вызывать методы из конструктора, и таким образом мы можем случайно оперировать полусконструированным объектом. Конструктор обещает установить инварианты, но в то же время это самое простое место их возможного нарушения.
Особенно странные вещи происходят, когда конструктор базового класса вызывает метод, переопределенный в производном классе:
abstract class Base {
init {
initialize()
}
abstract fun initialize()
}
class Derived: Base() {
val x: Any = 92
override fun initialize() = println(x) // выводит null!
}Просто подумайте об этом: код произвольного класса выполняется до вызова его конструктора! Подобный код на C++ приведет к еще более любопытным результатам.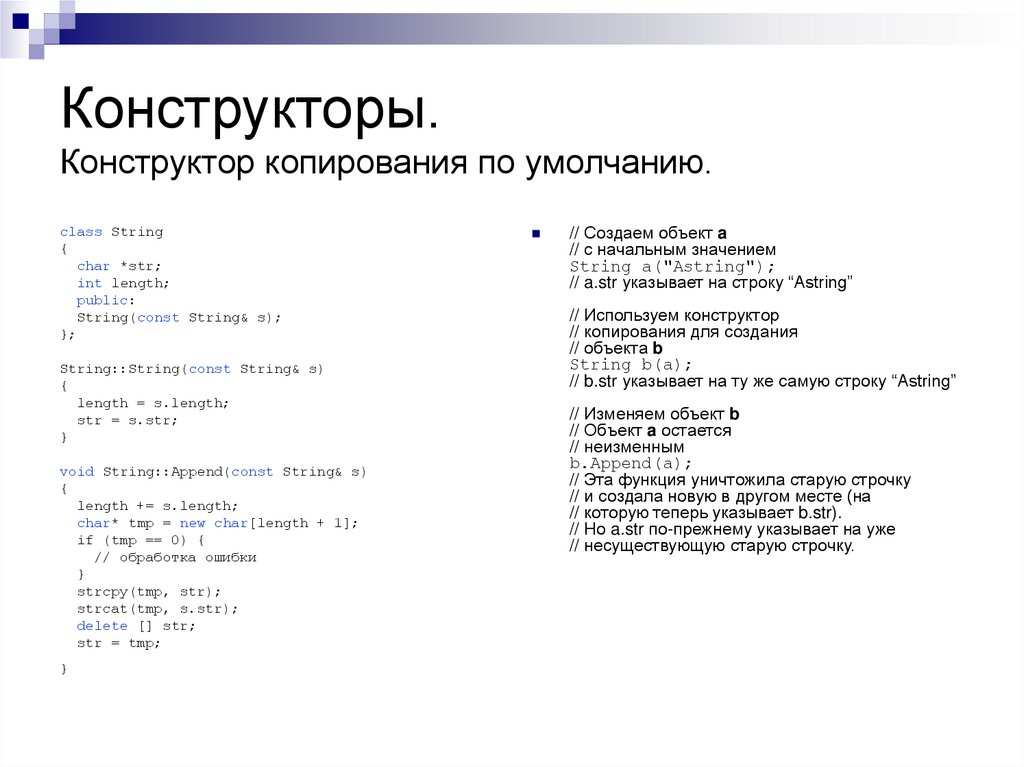
Нарушение инвариантов — не единственная проблема конструкторов. Они имеют сигнатуру с фиксированным именем (пустым) и типом возвращаемого значения (сам класс). Это делает перегрузки конструкторов сложными для понимания людьми.
Вопрос на засыпку: чему соответствует std::vector<int> xs(92, 2)?a. Вектору двоек длины 92
b. [92, 92]
c. [92, 2]
Проблемы с возвращаемым значением возникают, как правило, тогда, когда оказывается невозможно создать объект. Вы не можете просто вернуть Result<MyClass, io::Error> или null из конструктора!
Это часто используется в качестве аргумента в пользу того, что использовать C++ без исключений сложно, и что использование конструкторов вынуждает также использовать исключения.
Создайте один приватный конструктор, который принимает значения всех полей в качестве аргументов и просто присваивает их. Таким образом, такой конструктор работал бы как литерал структуры в Rust. Он также может проверять любые инварианты, но он не должен делать что-то еще с аргументами или полями.
для публичного API предоставляются публичные фабричные методы с подходящими названиями и типами возвращаемых значений.
Похожая проблема с конструкторами заключается в том, что они специфичны, и поэтому нельзя их обобщать. В C++ «есть конструктор по умолчанию» или «есть копирующий конструктор» нельзя выразить проще, чем «определенный
trait Default {
fn default() -> Self;
}
trait Clone {
fn clone(&self) -> Self;
}В Rust есть только один способ создать структуру: предоставить значения для всех полей. Фабричные функции, такие как общепринятый new, играют роль конструкторов, но, что самое важное, они не позволяют вызывать какие-либо методы до тех пор, пока у вас на руках нет хотя бы более-менее корректного экземпляра структуры.
Фабричные функции, такие как общепринятый new, играют роль конструкторов, но, что самое важное, они не позволяют вызывать какие-либо методы до тех пор, пока у вас на руках нет хотя бы более-менее корректного экземпляра структуры.
Недостаток этого подхода заключается в том, что любой код может создать структуру, так что нет единого места, такого как конструктор, для поддержания инвариантов. На практике это легко решается приватностью: если поля структуры приватные, то эта структура может быть создана только в том же модуле. Внутри одного модуля совсем нетрудно придерживаться соглашения «все способы создания структуры должны использовать метод new». Вы даже можете представить расширение языка, которое позволит помечать некоторые функции атрибутом #[constructor], чтобы синтаксис литерала структуры был доступен только в помеченных функциях. Но, опять же, дополнительные языковые механизмы мне кажутся излишними: следование локальным соглашениям требует мало усилий.
Лично я считаю, что этот компромисс выглядит точно также и для контрактного программирования в целом. Контракты вроде «не null» или «положительное значение» лучше всего кодируются в типах. Для сложных инвариантов просто писать assert!(self.validate()) в каждом методе не так уж и сложно. Между этими двумя паттернами есть немного места для #[pre] и #[post] условий, реализованных на уровне языка или основанных на макросах.
Swift — еще один интересный язык, на механизмы конструирования в котором стоит посмотреть. Как и Kotlin, Swift — null-безопасный язык. В отличие от Kotlin, проверки на null в Swift более сильные, так что в языке используются интересные уловки для смягчения урона, вызванного конструкторами.
Во-первых, в Swift используются именованные аргументы, и это немного помогает с «все конструкторы имеют одинаковое имя». В частности, два конструктора с одинаковыми типами параметров — не проблема:
Celsius(fromFahrenheit: 212.0) Celsius(fromKelvin: 273.15)
Во-вторых, для решения проблемы «конструктор вызывает виртуальный метод класса объекта, который еще не был полностью создан» Swift использует продуманный протокол двухфазной инициализации. Хотя и нет специального синтаксиса для списков инициализации, компилятор статически проверяет, чтобы тело конструктора имело правильную и безопасную форму. Например, вызов методов возможно только после того, как все поля класса и его потомков проинициализированы.
В-третьих, на уровне языка есть поддержка конструкторов, вызов которых может завершиться неудачей. Конструктор может быть обозначен как nullable, что делает результат вызова класса вариантом. Конструктор также может иметь модификатор throws, который лучше работает с семантикой двухфазной инициализации в Swift, чем с синтаксисом списков инициализации в C++.
Swift удается закрыть в конструкторах все дыры, на которые я пожаловался. Это, однако, имеет свою цену: глава, посвященная инициализации одна из самых больших в книге по Swift.
Вопреки всему я могу придумать как минимум две причины, по которым конструкторы не могут быть замещены литералами структуры, такими как в Rust.
Во-первых, наследование в той или иной степени вынуждает язык иметь конструкторы. Вы можете представить расширение синтаксиса структур с поддержкой базовых классов:
struct Base { ... }
struct Derived: Base { foo: i32 }
impl Derived {
fn new() -> Derived {
Derived {
Base::new()..,
foo: 92,
}
}
}Но это не будет работать в типичном макете объектов (object layout) ОО языка с простым наследованием! Обычно объект начинается с заголовка, за которым следуют поля классов, от базового до самого производного. Таким образом, префикс объекта производного класса является корректным объектом базового класса. Однако, чтобы такой макет работал, конструктору необходимо выделять память под весь объект за один раз. Он не может просто выделить память только под базовый класс, а затем присоединить производные поля. Но такое выделение памяти по кускам необходимо, если мы хотим использовать синтаксис создания структуры, где мы могли бы указывать значение для базового класса.
Но такое выделение памяти по кускам необходимо, если мы хотим использовать синтаксис создания структуры, где мы могли бы указывать значение для базового класса.
Во-вторых, в отличие от синтаксиса литерала структуры, конструкторы имеют ABI, хорошо работающий с размещением подобъектов объекта в памяти (placement-friendly ABI). Конструктор работает с указателем на this, который указывает на область памяти, которую должен занимать новый объект. Что самое важное, конструктор может с легкостью передавать указатель в конструкторы подобъектов, позволяя тем самым создавать сложные деревья значений «на месте». В противовес этому, в Rust конструирование структур семантически включает довольно много копий, и здесь мы надеемся на милость оптимизатора. Это не совпадение, что в Rust еще нет принятого рабочего предложения относительно размещения подобъектов в памяти!
Upd 1: исправил опечатку. Заменил «литерал записи» на «литерал структуры».
объекты, встроенные функции и атрибуты
Что такое конструктор в Python?
Конструктор в Python – это особый тип метода (функции), который используется для инициализации членов экземпляра класса.
В C ++ или Java конструктор имеет то же имя, что и его класс, в Python конструктор обрабатывается по-разному. Он используется для создания объекта.
Конструкторы бывают двух типов:
- Параметризованный конструктор
- Непараметрический конструктор
Определение конструктора выполняется, когда мы создаем объект этого класса. Конструкторы также проверяют, что у объекта достаточно ресурсов для выполнения любой задачи запуска.
Создание конструктора на Python
В Python метод __init __() имитирует конструктор класса. Этот метод вызывается при создании экземпляра класса. Он принимает ключевое слово self в качестве первого аргумента, который позволяет получить доступ к атрибутам или методу класса.
Мы можем передать любое количество аргументов во время создания объекта класса, в зависимости от определения __init __(). В основном он используется для инициализации атрибутов класса. У каждого класса должен быть конструктор, даже если он просто полагается на конструктор по умолчанию.
Рассмотрим следующий пример для инициализации атрибутов класса Employee при работе с конструкторами в Python.
Пример –
class Employee:
def __init__(self, name, id):
self.id = id
self.name = name
def display(self):
print("ID: %d nName: %s" % (self.id, self.name))
emp1 = Employee("John", 101)
emp2 = Employee("David", 102)
# accessing display() method to print employee 1 information
emp1.display()
# accessing display() method to print employee 2 information
emp2.display()
Выход:
ID: 101 Name: John ID: 102 Name: David
Подсчет количества объектов класса
Конструктор вызывается автоматически, когда мы создаем объект класса. Рассмотрим следующий пример.
class Student:
count = 0
def __init__(self):
Student. count = Student.count + 1
s1=Student()
s2=Student()
s3=Student()
print("The number of students:",Student.count)
count = Student.count + 1
s1=Student()
s2=Student()
s3=Student()
print("The number of students:",Student.count)
Выход:
The number of students: 3
Непараметрический
Непараметрический конструктор используется, когда мы не хотим манипулировать значением, или конструктором, который имеет только self в качестве аргумента. Разберем на примере.
class Student:
# Constructor - non parameterized
def __init__(self):
print("This is non parametrized constructor")
def show(self,name):
print("Hello",name)
student = Student()
student.show("John")
Параметризованный конструктор Python
У параметризованного конструктора есть несколько параметров вместе с самим собой.
Пример –
class Student:
# Constructor - parameterized
def __init__(self, name):
print("This is parametrized constructor")
self. name = name
def show(self):
print("Hello",self.name)
student = Student("John")
student.show()
name = name
def show(self):
print("Hello",self.name)
student = Student("John")
student.show()
Выход:
This is parametrized constructor Hello John
Конструктор Python по умолчанию
Когда мы не включаем конструктор в класс или забываем его объявить, он становится конструктором по умолчанию. Он не выполняет никаких задач, а инициализирует объекты. Рассмотрим пример.
class Student:
roll_num = 101
name = "Joseph"
def display(self):
print(self.roll_num,self.name)
st = Student()
st.display()
Выход:
101 Joseph
Более одного конструктора в одном классе
Давайте посмотрим на другой сценарий, что произойдет, если мы объявим два одинаковых конструктора в классе.
class Student:
def __init__(self):
print("The First Constructor")
def __init__(self):
print("The second contructor")
st = Student()
Выход:
The Second Constructor
В приведенном выше коде объект st вызвал второй конструктор, тогда как оба имеют одинаковую конфигурацию. Первый метод недоступен для объекта st. Внутренне объект класса всегда будет вызывать последний конструктор, если у класса есть несколько конструкторов.
Первый метод недоступен для объекта st. Внутренне объект класса всегда будет вызывать последний конструктор, если у класса есть несколько конструкторов.
Примечание. Перегрузка конструктора в Python запрещена.
Встроенные функции классов Python
Встроенные функции, определенные в классе, описаны в следующей таблице.
| SN | Функция | Описание |
|---|---|---|
| 1 | getattr(obj,name,default) | Используется для доступа к атрибуту объекта. |
| 2 | setattr(obj, name,value) | Она используется для установки определенного значения для определенного атрибута объекта. |
| 3 | delattr (obj, name) | Необходима для удаления определенного атрибута. |
| 4 | hasattr (obj, name) | Возвращает истину, если объект содержит определенный атрибут. |
Пример
class Student:
def __init__(self, name, id, age):
self. name = name
self.id = id
self.age = age
# creates the object of the class Student
s = Student("John", 101, 22)
# prints the attribute name of the object s
print(getattr(s, 'name'))
# reset the value of attribute age to 23
setattr(s, "age", 23)
# prints the modified value of age
print(getattr(s, 'age'))
# prints true if the student contains the attribute with name id
print(hasattr(s, 'id'))
# deletes the attribute age
delattr(s, 'age')
# this will give an error since the attribute age has been deleted
print(s.age)
name = name
self.id = id
self.age = age
# creates the object of the class Student
s = Student("John", 101, 22)
# prints the attribute name of the object s
print(getattr(s, 'name'))
# reset the value of attribute age to 23
setattr(s, "age", 23)
# prints the modified value of age
print(getattr(s, 'age'))
# prints true if the student contains the attribute with name id
print(hasattr(s, 'id'))
# deletes the attribute age
delattr(s, 'age')
# this will give an error since the attribute age has been deleted
print(s.age)
Выход:
John 23 True AttributeError: 'Student' object has no attribute 'age'
Встроенные атрибуты класса
Наряду с другими атрибутами класс Python также содержит некоторые встроенные атрибуты класса, которые предоставляют информацию о классе.
Встроенные атрибуты класса приведены в таблице ниже.
| SN | Атрибут | Описание |
|---|---|---|
| 1 | __dict__ | Предоставляет словарь, содержащий информацию о пространстве имен класса. |
| 2 | __doc__ | Содержит строку с документацией класса. |
| 3 | __name__ | Используется для доступа к имени класса. |
| 4 | __module__ | Он используется для доступа к модулю, в котором определен этот класс. |
| 5 | __bases__ | Содержит кортеж, включающий все базовые классы. |
Пример –
class Student:
def __init__(self,name,id,age):
self.name = name;
self.id = id;
self.age = age
def display_details(self):
print("Name:%s, ID:%d, age:%d"%(self.name,self.id))
s = Student("John",101,22)
print(s.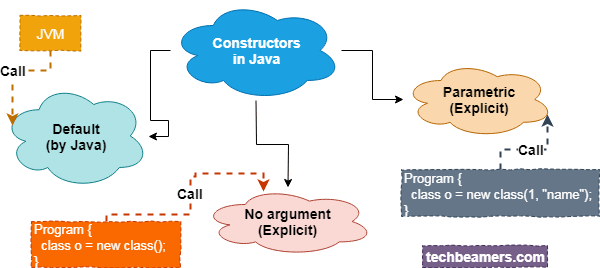 __doc__)
print(s.__dict__)
print(s.__module__)
__doc__)
print(s.__dict__)
print(s.__module__)
Выход:
None
{'name': 'John', 'id': 101, 'age': 22}
__main__
Михаил Русаков
Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
Еще для изучения:
языковой агностик — должны ли все классы иметь конструктор по умолчанию в рамках хорошего соглашения о кодировании
спросил
Изменено 9 лет, 10 месяцев назад
Просмотрено 4к раз
Из текстов, которые я прочитал до сих пор, конвенции говорят об организации конструкторы , начиная с по умолчанию , если таковые имеются. Мне интересно, должны ли все классы иметь конструктор по умолчанию
Мне интересно, должны ли все классы иметь конструктор по умолчанию в любом случае. Это, по крайней мере, поможет создать простой экземпляр класса на лету, без необходимости использовать параметризованный конструктор , который сам по себе может потребовать дополнительных импортов для определенного типа параметра.
- не зависящие от языка
- стандарты кодирования
- класс
- конструкторы
5
Вообще говоря, у вас должны быть конструкторы для классов, которые принимают достаточно параметров для правильной инициализации создаваемого объекта в допустимом состоянии. Если ваш класс может обеспечить разумные значения по умолчанию для всех полей, которые содержат допустимое состояние для объектов этого класса, то конструктор по умолчанию, скорее всего, является хорошей идеей.
Кроме того, некоторые библиотеки требуют наличия конструктора по умолчанию для определенных операций. Например, библиотеки в Java, используемые для десериализации json/xml, часто требуют вызова конструктора по умолчанию через отражение, поскольку эти библиотеки будут пытаться оценить все во время выполнения и не могут заранее знать, какие конструкторы доступны для использования, поэтому они ожидают конструктор по умолчанию. В таких случаях, если конструктор по умолчанию требуется для инструментов, но не должен вызываться ничем, что вы контролируете, или какими-либо пользователями вашего API, лучше всего использовать общую идиому вашего языка, чтобы пометить конструктор как частный (например, частный доступ в типичных статически типизированных языках).
Например, библиотеки в Java, используемые для десериализации json/xml, часто требуют вызова конструктора по умолчанию через отражение, поскольку эти библиотеки будут пытаться оценить все во время выполнения и не могут заранее знать, какие конструкторы доступны для использования, поэтому они ожидают конструктор по умолчанию. В таких случаях, если конструктор по умолчанию требуется для инструментов, но не должен вызываться ничем, что вы контролируете, или какими-либо пользователями вашего API, лучше всего использовать общую идиому вашего языка, чтобы пометить конструктор как частный (например, частный доступ в типичных статически типизированных языках).
3
Есть два случая, когда конструктор по умолчанию не имеет смысла:
Зависимость класса от его поля или свойства.
Представьте себе серию классов, которые загружают статистические данные из базы данных и отображают их на диаграмме.
 Один из классов,
Один из классов, DataTransform, нормализует данные из базы данных для использования в диаграмме. Этот класс используетIDataProvider, который передаетDataTransformнеобработанные данные.Для обеспечения возможности тестирования и взаимодействия у вас есть четыре класса, реализующих
IDataProvider: один для Oracle, один для Microsoft SQL Server, тот, который загружает данные непосредственно из XML, и, наконец, макет для использования в модульных тестах.Наличие конструктора по умолчанию заставит вас:
Проверьте почти каждый метод
DataTransform, которыйIDataProvider dataProviderполе было инициализировано,Ожидается, что любой, кто использует класс, либо вызовет параметризованный конструктор, либо вызовет конструктор по умолчанию, а затем установит поставщик данных с помощью дополнительного свойства или метода.
Это указывает на серьезную проблему в конструкции.
 Отказ от конструктора по умолчанию и наличие исключительно конструктора, который принимает поставщик данных в качестве параметра, делает класс более интуитивно понятным в использовании, а его собственный код — более простым.
Отказ от конструктора по умолчанию и наличие исключительно конструктора, который принимает поставщик данных в качестве параметра, делает класс более интуитивно понятным в использовании, а его собственный код — более простым.Неизменяемые объекты, для которых значения по умолчанию не имеют смысла.
Представьте себе неизменяемый
Person, который имеет свойстваFirstName,LastNameиBirthDate. Хотя имя и фамилия по умолчанию могут быть пустой строкой (или нулевым значением, если язык разрешает пустые строки), какой будет дата рождения? Минимальная разрешенная дата? Зачем вам вообще нужен неизменный человек, у которого нет имени и который родился 19 января0096 ст , год 1?Обратите внимание, что неизменяемость сама по себе не означает, что не должно быть конструктора по умолчанию. Например, имеет смысл иметь конструктор по умолчанию для
Point, в результате чего получитсяPoint(x = 0, y = 0); другой способ — иметь статическую константуPoint.. Другой пример: имеет смысл иметь конструктор по умолчанию для неизменной строки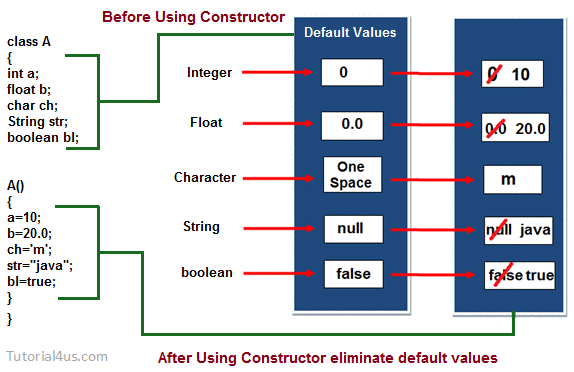 Zero
Zero String(будь то нулевая или пустая строка).
1
Причина, по которой некоторые классы предпочитают иметь только сложный конструктор, часто заключается в том, что они не могут работать с пользой, не зная основной информации об экземпляре. Возможность создать тривиальный экземпляр в этом случае не является преимуществом — скорее, это, вероятно, недостаток, потому что тогда все методы должны иметь возможность работать с объектом, в котором отсутствуют важные данные! Запрещая это, вы часто можете установить инварианты для класса, которые сэкономят много времени на кодирование и усилия во время выполнения.
Общее правило о том, какие конструкторы вам «должны» или не следует иметь, не имеет большого значения по сравнению с такими специфическими для класса соображениями. На практике единственная веская причина для применения тривиального конструктора, которую я когда-либо видел, — это если вы передаете свои объекты фреймворку, который сам требует его.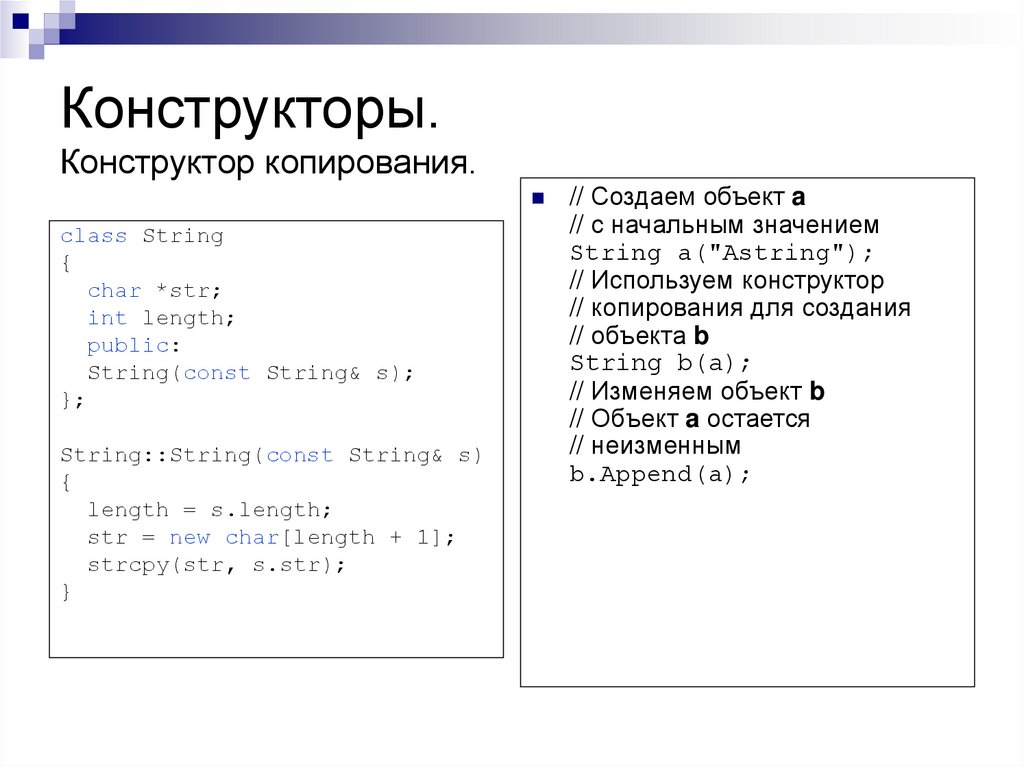 Даже тогда я, вероятно, сделаю конструктор закрытым, если мне это сойдет с рук.
Даже тогда я, вероятно, сделаю конструктор закрытым, если мне это сойдет с рук.
Абсолютно нет. Ctor по умолчанию возникает, если класс можно разумно сконструировать без какой-либо информации, поступающей извне. (Если вы ограничите вопрос этим подмножеством, ответ станет утвердительным.)
В противном случае использование ctor по умолчанию приводит к принудительной двухэтапной инициализации со всеми вытекающими отсюда недостатками. Мы выбрали ее только по очень веским причинам.
1
Зависит от вашего стиля кодирования и шаблонов, которые вы реализуете. С внедрением зависимостей (DI) вы часто обнаружите, что у вас есть конструктор по умолчанию только тогда, когда он вам действительно нужен — будь то для сериализации XML или чего-то еще. Будучи предвзятым к DI, я бы сказал, что нет, вам не нужен конструктор по умолчанию, поскольку единственная работа, которая выполняется в конструкторе, — это внедрение зависимостей класса: конструкторы становятся статической документацией зависимостей типа .
Мне не нравятся рекомендации «все или ничего». Только на этих условиях я бы сказал нет.
Рассмотрите любую практику в каждом отдельном случае. Никаких серебряных пуль.
Создавайте конструктор по умолчанию, только если он вам нужен. YAGNI — лучшее соглашение о кодировании.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
Цель сокрытия конструктора по умолчанию (Java на общем форуме в Coderanch)
Классы Pattern и Matcher не являются синглтонами, но являются примерами более общего шаблона использования фабричного метода. Шаблон singleton является частным случаем этого, который слишком часто используется и подчеркивается, и в значительной степени неуместен здесь. Игнорируя синглтоны, фабричные методы в целом имеют ряд возможных преимуществ, некоторые из которых обсуждаются в связанной статье.
Шаблон singleton является частным случаем этого, который слишком часто используется и подчеркивается, и в значительной степени неуместен здесь. Игнорируя синглтоны, фабричные методы в целом имеют ряд возможных преимуществ, некоторые из которых обсуждаются в связанной статье.
Тем не менее, я не думаю, что большинство из перечисленных пунктов применимы к Узору. Вместо этого я думаю, что основная причина использования шаблона здесь заключается в том, чтобы учесть некоторые будущие оптимизации — в частности, не всегда необходимо создавать новый объект шаблона . Будущая реализация Pattern может хранить в кэше ранее созданные объекты Pattern, и всякий раз, когда запрашивается Pattern, который соответствует ранее созданному Pattern, этот существующий объект может быть возвращен, а не создавать новый. В определенных ситуациях это может привести к существенному повышению производительности. По общему признанию, это улучшение в настоящее время является гипотетическим — текущий JDK делает , а не не делают ничего подобного. Но мог. Если бы они сделали конструктор Pattern общедоступным, то всякий раз, когда кто-то вызывал бы new Pattern(), было бы иметь для создания нового объекта Pattern. Вместо этого использование фабричного метода обеспечивает большую гибкость для будущих реализаций, даже если эта гибкость не используется в текущих реализациях.
Но мог. Если бы они сделали конструктор Pattern общедоступным, то всякий раз, когда кто-то вызывал бы new Pattern(), было бы иметь для создания нового объекта Pattern. Вместо этого использование фабричного метода обеспечивает большую гибкость для будущих реализаций, даже если эта гибкость не используется в текущих реализациях.
В конечном счете, хотя я думаю, что использование фабричного метода здесь было хорошей идеей, я думаю, что они не очень хорошо справились с этой идеей настолько, насколько могли. Тот факт, что Pattern имеет закрытый конструктор, предотвращает альтернативные реализации. Шаблон должен был быть интерфейсом, а другой класс (например, java.util.regex.Patterns) мог предоставить некоторые стандартные реализации. Идея кэширования экземпляров Pattern хороша, однако в некоторых случаях это может привести к создают проблемы. Если ваша программа регулярно запрашивает совершенно новые объекты Pattern (которые не соответствуют ни одному из предыдущих объектов), то может быть плохой идеей пытаться сохранить все ранее созданные Patterns в памяти. Таким образом, вы не хотите заставлять всех пользователей использовать реализацию, которая кэширует шаблоны таким образом. Вместо этого лучше иметь несколько доступных реализаций и позволить пользователю выбрать то, что лучше всего подходит для него.
Таким образом, вы не хотите заставлять всех пользователей использовать реализацию, которая кэширует шаблоны таким образом. Вместо этого лучше иметь несколько доступных реализаций и позволить пользователю выбрать то, что лучше всего подходит для него.
Что касается класса Matcher, обратите внимание, что вопреки тому, что было сказано в первом посте выше, он не имеет частного конструктора — у него есть конструктор пакета -elvel. В Matcher также нет статического метода matcher() — он есть в Pattern. Потому что Matcher действительно должен быть связан с Pattern; нет никакого смысла иметь Matcher без шаблона. Поэтому они поместили фабричный метод в этот класс — вам нужен шаблон, прежде чем вы сможете получить Matcher. Обратите внимание, что метод не является статическим — фабричные методы могут быть статическими или нестатическими; если они не статичны, то объекты, к которым они присоединены, называются фабриками. Это дальнейшая специализация шаблона фабричный метод.