Является ли фотография персональными данными
Многочисленные споры так и не смогли однозначно установить, является ли фотография персональными данными и относится ли они к биометрической информации. Позиции регуляторов и судов часто меняются, в разных регионах складывается разная практика. Единой логики принятия решения нет – в каждом конкретном случае оно опирается на установленные законом исключения.
Когда фотография заведомо относится к ПД
Часто встречается ситуация, когда фото на пропусках на работу или на закрытую территорию многоэтажных жилых комплексов признаются ПД и за их использование без получения специально оформленного согласия организации привлекаются к ответственности. Роскомнадзор в ответ на многочисленные запросы операторов персональных данных разъяснил, что в целях применения закона «О персональных данных» к биометрическим персональным данным относятся сведения, которые характеризуют физиологические и биологические особенности человека, и на их основании непосредственно или с использованием технических решений можно установить его личность.
Позиция основывается на том, что:
- не всякое изображение относится к персональным данным;
- для принятия решения о его отнесении к этой категории оператор обязательно должен использовать фото для установления личности. Изображение человека при его использовании должно быть основой его опознания – при пропуске на работу, в школу.
Согласие на использование персональных данных обязательно оформляется, если приведенное толкование закона дает возможность отнести конкретное фото к биометрическим персональным данным. Форма письменного согласия законом не устанавливается, но она типовая для большинства случаев обработки ПД. Есть и исключения, предусмотренные федеральными законами.
Так, согласие на обработку персональных данных не требуется, если:
- ситуация связана с исполнением страной международного договора;
- изображение обрабатывается в целях отправления правосудия;
- обработка биометрических данных происходит в связи с реализацией целей обороны, борьбой с терроризмом, оперативно-розыскной деятельностью.

Помимо фото, к биометрическим персональным данным закон относит отпечатки пальцев, радужную оболочку глаз, анализы ДНК, рост, вес, метрические сведения, например, данные измерения лица, а также иные физиологические или биологические характеристики человека, отображенные, в том числе, в видео. Всегда к биометрическим персональным данным будет относиться снимок для заграничного паспорта, сделанный с использованием технических средств получения биометрического изображения. Об этом напоминает Постановление Правительства № 125, посвященное вопросам оформления заграничных паспортов.
Часто вопросы вызывает требование организации предоставить фото, особенно на фоне объекта недвижимости или с паспортом в руке для идентификации, без предварительного оформления согласия. Чаще всего так поступают банки, наниматели поденных рабочих, операторы электронных кошельков. Гражданин в каждом случае использования таких фото сам оценивает степень риска. Если она кажется ему высокой, следует обратиться за защитой – направить жалобу в Роскомнадзор с просьбой привлечь к ответственности за неправомерное требование ПД без оформления согласия.
Когда фото не относится к ПД
Основным условием отнесения фотоснимка к биометрическим данным становится использование ее оператором в целях идентификации личности. Регулятор называет несколько конкретных ситуаций, в которых снимок ни в коем случае не будет отнесен к персональным данным, оборот которых ограничен и для использования которых нужно обязательно получать согласие:
- изображение необходимо для реализации политических, государственных, общественных интересов. Равно не является незаконным использованием персональных данных размещение в газете фотокарточки политика. При этом публикация фото чужого ребенка будет отнесена к нарушениям;
- фото или видеоизображение получено в публичном, общественном месте, открытом для общего посещения: в театре, на митинге, на спортивном мероприятии. Оно может свободно размещаться в СМИ без согласия гражданина.
 Исключением является ситуация, когда оно получено с целью коммерческого использования, в этом случае требуется согласие частного лица;
Исключением является ситуация, когда оно получено с целью коммерческого использования, в этом случае требуется согласие частного лица; - фотография получена, когда гражданин позировал за денежное вознаграждение, заведомо понимая, что изображение будет использовано в рекламе или иным способом.
04.03.2020
Графическая информация
Графическая информация – это сведения, представленные в виде схем, эскизов, изображений, графиков, диаграмм, символов.
Графическая информация является разновидностью визуальной (зрительной) информации. К ней относятся: рисунки, гравюры, плакаты, схемы, географические карты, развертки, эскизы и т.д. Она состоит из точек, штрихов, линий, которые выполнены карандашом, тушью, мелом, фломастером на бумаге, картоне, классной доске и т.д.
Стоит сказать, что графическая информация сопровождает человека с момента его появления и развивается с ним одновременно. К самой ранней графической информации относятся изображения, нарисованные углем, сажей, или же процарапанные на стенах пещер и камнях. В современном мире для создания графической информации человеку на помощь пришла цифровая техника.
К самой ранней графической информации относятся изображения, нарисованные углем, сажей, или же процарапанные на стенах пещер и камнях. В современном мире для создания графической информации человеку на помощь пришла цифровая техника.
В настоящее время на экране монитора стало возможным получать рисунки, чер тежи в таком же виде, как на бумаге с помощью каранда шей, красок, чертежных инструментов. Такого рода графическая информация называется цифровой (цифровая графика). Кроме того, рисунок из памяти компьютера может быть выведен не только на экран, но и на бумагу с помощью принтера. Сегодня су ществуют принтеры цветной печати, дающие качество ри сунков на уровне фотографии.
Приложения компьютерной графики очень разнообразны. Для каждого направления создается специальное программное обеспечение, которое называют графическими програм мами, или графическими пакетами.
В зависимости от способа формирования изображений различают следующие виды компьютерной графики:
- растровая графика — применяется при разработке электронных (мультимедийных) и полиграфических изданий.

- векторная графика – используется для создания иллюстраций и в меньшей степени для их обработки. Такие средства широко используют в рекламных агентствах, дизайнерских бюро, редакциях и издательствах;
- трехмерная графика — широко используется в инженерном программировании, компьютерном моделировании физических объектов и процессов, в мультипликации, кинемотографии и компьютерных играх.
К программам для работы с растровой графикой относятся:
- Paint
- Microsoft Photo Editor
- Adobe Photo Shop
- Fractal Design Painter
- Micrografx Picture Publisher
Для работы с векторной графикой используются:
- Corel Draw
- Adobe Illustrator
- Fractal Design Expression
- Macromedia Freehand
- AutoCAD
Таким образом, в растровой графике кодирование изображения происходит путем деления изображения на маленькие точки или пиксели. Каждому пикселю присваивается код его цвета вместе. Информация о каждой такой точке содержит компьютерная видеопамять.
Каждому пикселю присваивается код его цвета вместе. Информация о каждой такой точке содержит компьютерная видеопамять.
В создании векторной графики участвуют примитивные объекты – линия, кривая, точка, прямоугольник, треугольник, окружность. Данные элементы и их объемы описываются при помощи математических формул.
Графическая информация может быть представлена по-разному. Способы представления графической информации зависят от назначения данной информации и типа устройств, для которых она предназначена.
Представление графической информации осуществляется:
- координатным способом. Данный способ основывается на представлении плоского (монохромного) изображения в виде координат прямоугольных растрэлементов;
- рецепторным способом. Разновидность координатного способа. Он основан на представлении всего поля изображения в виде прямоугольных областей, которые называются рецепторами;
- способ поэлементного представления графической информации.
 Он основан на представлении изображения в виде совокупности графических примитивов, в качестве которых могут выступать отрезок прямой линии, дуга, окружность;
Он основан на представлении изображения в виде совокупности графических примитивов, в качестве которых могут выступать отрезок прямой линии, дуга, окружность; - структурно-символический способ. Он основан на использовании для формирования изображения типовых графических элементов;
- аналитический способ. Данный способ основывается на ее представлении в виде уравнений поверхностей.
Метаданные для организации хранения фото-архива / Хабр
Привет, хабр!Наверное, не ошибусь, если скажу, что у многих пользователей хабра скопился небольшой архив фото- и видео- материалов, которые хранят воспоминания о различных моментах собственной жизни, или жизни близких людей. У некоторых этот архив, возможно, уже занимает не один жёсткий диск. Но многие ли из вас задумывались, как лучше хранить все эти фотографии, как с архивом распорядятся ваши дети? Хочу затронуть скользкую и не очень тематическую тему «организации хранения личного фото-архива», в которой много вопросов и мало ответов, много текста и мало картинок.

Предисловие
Скорее всего, у каждого в семье есть старый «побитый временем» альбом с чёрно-белыми фотографиями, который достался ещё от бабушки. Возможно, вы его уже даже оцифровали. Но насколько ценной будет свалка изображений в одной папке? Ответ — и много и мало одновременно. Всё зависит от того, насколько эта фотография «касается» вашей жизни, и на сколько она «информативна». Давайте порассуждаем относительно этих двух критериев.Фотография может касаться вас в различной степени, от «это я на изображении, и очень хорошо тут получился», до «это соседний гараж, брата двоюродной сестры друга из Питера». Естественно, вас интересует больше всего то, что касается лично вас (ваши изображения, или снимки вашего авторства), во вторую очередь, вас будут интересовать фотографии ваших близких, ведь их жизнь вам тоже важна и интересна, не так ли?
А вот на счёт информативности остановимся поподробнее.
Информативность фотографии
Что ещё несёт фотография, помимо самой картинки? Если вы сами лично её снимали, или на ней есть вы, то часто при одном только взгляде на это изображение, вы сразу вспомните (хотя бы приблизительно) множество «сопутствующей информации» к снимку: кто в кадре, когда он был сделан, в каком месте, что это было за событие. Это, конечно, всё прекрасно, но почему вся эта информация хранится в голове, отдельно от самого изображения? Именно это и является «информативностью» фотографии, и эта информативность может существенно повысить ценность снимка, если не для вас, то для других людей точно. В частности, эта информация может оказаться крайне полезной для ваших детей и внуков, к которым перейдёт ваш архив «по наследству».
Это, конечно, всё прекрасно, но почему вся эта информация хранится в голове, отдельно от самого изображения? Именно это и является «информативностью» фотографии, и эта информативность может существенно повысить ценность снимка, если не для вас, то для других людей точно. В частности, эта информация может оказаться крайне полезной для ваших детей и внуков, к которым перейдёт ваш архив «по наследству».Вы наверняка встречали в «бабушкином альбоме» множество таких фотографий, где изображены почти незнакомые вам люди, неизвестно где и неизвестно когда сделанных. Какая ценность у такого изображения для вас? Практически нулевая! В лучшем случае фотокарточки в старых альбомах подписывали коротенькими фразами, и подписывали год — это хоть немного, но увеличивало её ценность. А теперь представьте, что у вас была бы полная информация о каждом участнике на снимке и его отношении к вашим близким, подробное описание события и точная координата места? Например, «вот дедушка, и мужик с усами — двоюродный брат дедушки, в командировке, 16 мая 19xx года 12:36:00, недалеко от Архангельска, координаты xxx,yyy». Конечно, в первую очередь важно само изображение и его отношение к вам, но сопутствующая информация тоже немало в себе несёт, и порой объясняет что-то очень важное.
Конечно, в первую очередь важно само изображение и его отношение к вам, но сопутствующая информация тоже немало в себе несёт, и порой объясняет что-то очень важное.
Повышаем информативность, EXIF
Дата и время
Необходимость пометить дату на фотографии — это, наверное, первая очевидная необходимость, которая возникла перед фотографами. Дата может многое рассказать о снимке. На протяжении практически всей истории плёночных фотоаппаратов приходилось наносить её вручную, и лишь позже, практически в конце эпохи плёнки, появились аппараты, способные автоматически «выжигать» дату прямо на изображении. Более того, дату обычно наносили на задней поверхности фотокарточки, после того как полностью отсняли плёнку, и после процесса проявки плёнки и фотобумаги, поэтому её часто наносили неточно (например, «лето 2000 года»), а если и точно, то нередко были случаи ошибок на пару дней. О времени кадра практически никто тогда не беспокоился.Но даже если дата «выжигалась» — тут есть небольшой недостаток в том, что эти цифры незначительно перекрывают полезную площадь снимка. С появлением цифровых фотоаппаратов, появилась возможность хранить дату в цифровом виде, вместе с кадром. Возникла необходимость в стандарте, который бы утвердил единый способ хранения для всех производителей. Так появились стандарты метаданных: IPTC, EXIF и XMP.
С появлением цифровых фотоаппаратов, появилась возможность хранить дату в цифровом виде, вместе с кадром. Возникла необходимость в стандарте, который бы утвердил единый способ хранения для всех производителей. Так появились стандарты метаданных: IPTC, EXIF и XMP.
Сейчас даже самая простая «мыльница» и мобильный телефон умеют записывать дату кадра в EXIF, и практически все программы её считывать и использовать. Тут главное, чтобы владелец правильно выставил время на устройстве, и в дальнейшем он может практически забыть о таком параметре, как время. Практически, потому, что на Земле есть много часовых поясов, а стандарт EXIF, к сожалению, не до конца продумал этот момент. Дело в том, что стандартом не предусмотрено хранение часового пояса и времени UTC, что по сути заставляет хранить в снимке лишь местное время. Но «местное время» абсолютно не раскрывает реального времени UTC, так как для того, чтобы узнать мировое время, нужно как минимум знать смещение часового пояса. То есть, даже в текущем стандарте EXIF понятие «время» не точное, и в нём нет никаких указаний на точное мировое время. В XMP такой проблемы нет, но он крайне не распространён, в отличие от EXIF. Конечно, производители могут использовать свои поля для хранения временной зоны (или даже задействовать аттрибут GPSTimeStamp, который предназначен для геотэггинга), но к сожалению программы их не поймут.
В XMP такой проблемы нет, но он крайне не распространён, в отличие от EXIF. Конечно, производители могут использовать свои поля для хранения временной зоны (или даже задействовать аттрибут GPSTimeStamp, который предназначен для геотэггинга), но к сожалению программы их не поймут.
Подпись, комментарии, тэги
Внедрение метаданных в цифровой снимок позволило хранить в нём не только время, но и другую информацию. Более того, технически EXIF позволяет хранить в нём вообще произвольные данные (но без стандартов, эти данные могут прочитать лишь узкоспециализированные программы). В частности можно подписать фотографию, описать события происходящие в нём. Во времена плёнки, сзади карточки подпись указывали почти также часто, как и дату, но сейчас эти атрибуты практически не используются, так как обычно подписью для всего альбома фотографий обычно является название папки, в которой они находятся, а процесс этот никак не автоматизируешь.Параметры съёмки
Возможность сохранения произвольных данных в EXIF не могли не воспользоваться для хранения параметром съёмки — выдержка, диафрагменное число, чувствительность.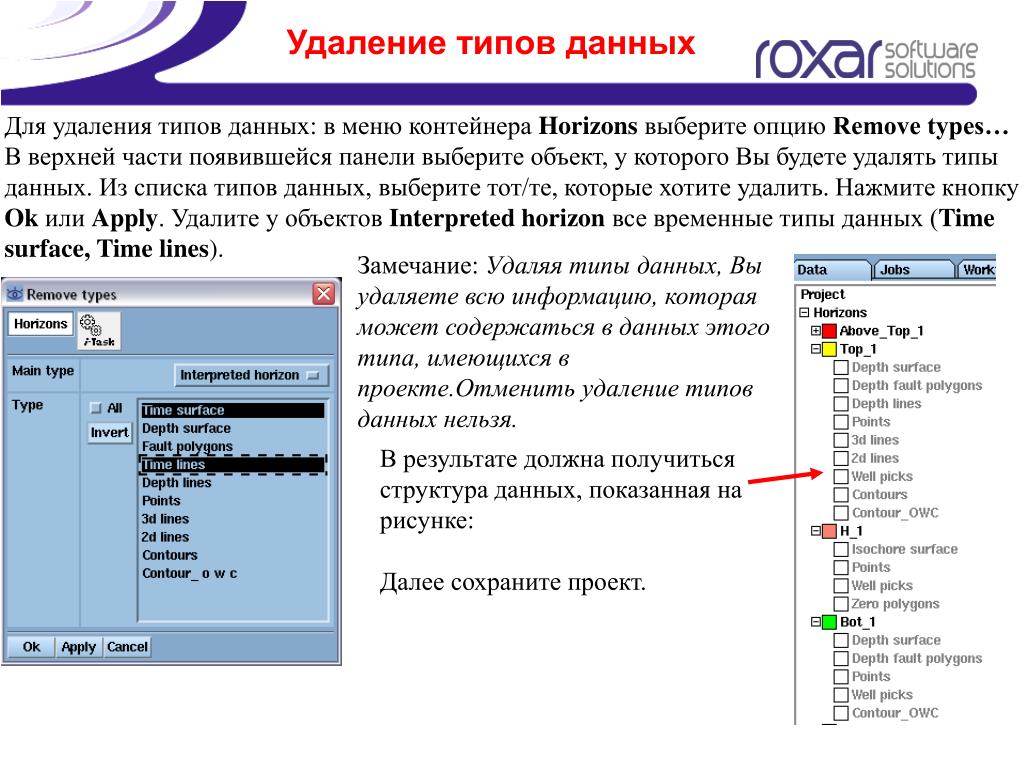 Хотя эти данные интересны в основном любителям и профессиональным фотографам, тем не менее по некоторым из этих данных можно тоже подчерпнуть некоторую информацию, например о завышенной чувствительности, и как следствие сильных шумах.
Хотя эти данные интересны в основном любителям и профессиональным фотографам, тем не менее по некоторым из этих данных можно тоже подчерпнуть некоторую информацию, например о завышенной чувствительности, и как следствие сильных шумах.Местоположение снимка
Раньше в подписи в фотокарточках могли указать город. Хотя его указывали в основном, когда человек делал снимок где-то вне родного города, т. к. родной город и дом «можно узнать и так». В наше время с появлением GPS в фотоаппаратах и смартфонах появилась возможность автоматизации привязки фотографий к карте, процесс, называемый «геотэгингом». Что это может дать? Помимо самой информации о местоположении, во-первых благодаря геотэггингу можно быстро найти все снимки в архиве, которые были сделаны в каком-то месте. Во-вторых, сейчас соц. сети умеют читать эти данные из метаданных и показывать другим местоположение на карте. В-третьих, на будущее, кто знает, может в будущем изобретут алгоритм, который по набору фотографий сможет автоматически создать модель местности, разве не интересно сейчас походить по смоделированной Москве какого-нибудь 15 века?К сожалению, даже наличие GPS в устройстве не гарантирует привязки снимка к местности, т. к. для работы GPS нужен разогрев до 10 минут (без A-GPS) на открытом небе.
к. для работы GPS нужен разогрев до 10 минут (без A-GPS) на открытом небе.
Привязка людей
Отметки о людях на фотографии — это один из самых «информационных» параметров снимка. Ведь действительно, снимают в основном людей, и ничто так не просветит, что за человек в кадре, как не подпись. Все знакомы с такими перечислениями в подписях — «На фото слева на право: Вася, Оля, Миша, Катя». В социальных сетях, эту идею активно развили, дав возможность пользователям отмечать друзей на фотографиях, более того, это, наверное, одна из самых главных функций в соц. сети, благодаря которой, они получили такое распространение. К сожалению, вне рамок социальных сетей привязкой людей к снимкам практически никто не занимается. Во-первых, из-за отсутствия в прошлом систем автоматизации; во-вторых, из-за отсутствия стандартов хранения этой информации в EXIF; ну и в третьих, обычно такая информация предполагает наличие некой «базы данных людей», а в каждый снимок базу не встроишь.После появления системы распознавания лиц в Picasa эта программа заработала огромную популярность, ведь действительно это очень удобно, когда Picasa, с небольшой вашей помощью, сама находила людей на фотографиях. В дальнейшем, эту программу очень удобно использовать для поиска снимков какого-то конкретного человека (вместо того, чтобы просматривать все фото в поисках его). Естественно, алгоритмы распознавания образов распознают людей далеко не всегда (в основном только для чётких, больших фотографий в «фас», желательно без очков), и много фотографий нужно потом отмечать вручную, но это лучше, чем ничего.
В дальнейшем, эту программу очень удобно использовать для поиска снимков какого-то конкретного человека (вместо того, чтобы просматривать все фото в поисках его). Естественно, алгоритмы распознавания образов распознают людей далеко не всегда (в основном только для чётких, больших фотографий в «фас», желательно без очков), и много фотографий нужно потом отмечать вручную, но это лучше, чем ничего.
Что всё это даёт?
Конечно, в первую очередь это даёт возможность быстро найти интересующие снимки. Если раньше плёнка вынуждала сто раз подумать, прежде чем сделать снимок, то сейчас человек практически ничем не ограничен в фотографировании. Как результат — огромные архивы снимков, где трудно что-то найти. Банальная задача — найти хорошую аватарку друга/подруги для того, чтобы поставить его в телефонную книгу на смартфоне — становится сложной. А если есть привязка людей к фотографиям, эта задача на порядок упрощается.А если данные идеально заполнены, становится возможным делать даже сложные запросы: найти все фотографии Васи и Тани Пупкиных (там, где они вместе), сделанные в Москве в период с 2005 по 2008 год.
Где хранить архив?
В век облачных технологий так и хочется дать совет — хранить всё в облаке, а лучше в нескольких. Но для рядовых пользователей это может влететь в копеечку, т. к. современный архив фотографий может занимать не одну сотню гигабайт. Поэтому для большинства скорее всего подойдёт хранение на компьютере или NAS. Главный совет — делать бэкапы, и крайне желательно его хранить где-то очень отдельно — крайне неприятно потерять весь свой архив из-за пожара или катастрофы.По поводу структуры папок, могу лишь дать совет. Разбивать все фотографии на альбомы/папки по некому смыслу, а в качестве наименования папки использовать формат «2000-12-31 Название». Такой способ отсортирует все альбомы в виде единой временной линии. Если альбомов много, то можно их дополнительно разбить на папки по годам.
Чем смотреть?
Тут очень печальная тема. Достойных программ, которых могут каталогизировать архив фотографий, использовать и редактировать все информативные параметры фотографий и имеет систему распознавания лиц — немного. Я знаю только две — Picasa и iPhoto, причём вторая работает исключительно на MacOS.
Я знаю только две — Picasa и iPhoto, причём вторая работает исключительно на MacOS.Кроме-того, крайне важно, чтобы вся информация о снимке хранилась внутри самого снимка, а не в базе данных программы. Т. к. не факт, что программу не забросят, или база данных не повредится. Google Picasa с версии 3.9 это умеет, путём установки галочки «Хранить метаданные в файлах» в настройках программы. Благодаря этому, можно не беспокоиться, что однажды привязанные люди к фотографии не исчезнут после переустановки системы, перемещении папки или вообще на чужом компьютере.
Помимо этого, Picasa имеет множество других полезных функций, например, синхронизируется с адресной книгой аккаунта Google, т. е. если вы пользуетесь Android, у вас уже будет база данных людей. Из Picasa можно легко задать аватарки для людей в этой адресной книге. Плюс куча возможностей выгрузки веб-альбомов, и многое-многое другое.
А как быть с видео?
Это ещё более печальная тема. К сожалению, для видео нет вообще никаких общепринятых единых стандартов, по типу EXIF, поэтому тут сложно что-либо советовать. И хотя Picasa умеет работать с метаданными некоторых контейнеров видео, не факт, что это будет всё работать в будущем.
И хотя Picasa умеет работать с метаданными некоторых контейнеров видео, не факт, что это будет всё работать в будущем.Рассуждения о будущем..
Как видно из данного топика, сейчас очень не хватает принятия некоторых стандартов, для универсализации и повышения информативности фотографий, а для видео вообще следовало бы, хотя бы, внедрить текущие стандарты EXIF. Например, очень необходимо решить вопросы со временем UTC в EXIF, а также, возможно, расширить поля местоположения. Например, ввести поле «Направление снимка», что позволило бы на карте отобразить не только точку, но и, собственно, куда был направлен объектив. Тем более что уже сейчас в телефонах есть электронные компасы. Так же, очень нужен стандарт в хранении меток людей внутри EXIF, тогда вполне возможно, что в будущем фотоаппараты научатся сами отмечать людей в кадре (ведь фотоаппараты уже достаточно мощные, и уже имеют системы «распознавания улыбок», а с недавних пор на них стали внедрять Android, что облегчит разработку таких алгоритмов).
Обновлено. Как сообщил мне уважаемый kraleksandr, Samsung Galaxy Camera уже умеет это делать.
Заключение
Конечно, личные фотографии в первую очередь рассчитаны на самого владельца, и вряд ли внуки, а тем более правнуки, будут хранить весь ваш фотоархив, но повышение информативности снимка, безусловно, повысит полезность хотя бы некоторых снимков для них. Кроме того, все описанные способы повышения информативности позволят облегчить пользование архивом и вам.PS. Картинки для поста любезно предоставленны сервисом Google Images.
Как устроен формат JPEG / Хабр
Изображения формата JPEG встречаются повсюду в нашей цифровой жизни, но за этим покровом осведомлённости скрываются алгоритмы, устраняющие детали, не воспринимаемые человеческим глазом. В итоге получается высочайшее визуальное качество при наименьшем размере файла – но как конкретно всё это работает? Давайте посмотрим, чего именно не видят наши глаза!
Легко принять, как само собой разумеющееся, возможность отправить фотку другу, и не волноваться по поводу того, какое устройство, браузер или операционную систему он использует – однако так было не всегда. К началу 1980-х компьютеры умели хранить и показывать цифровые изображения, однако по поводу наилучшего способа для этого существовало множество конкурирующих идей. Нельзя было просто отправить изображение с одного компьютера на другой и надеяться, что всё заработает.
К началу 1980-х компьютеры умели хранить и показывать цифровые изображения, однако по поводу наилучшего способа для этого существовало множество конкурирующих идей. Нельзя было просто отправить изображение с одного компьютера на другой и надеяться, что всё заработает.
Для решения этой проблемы в 1986 году был собран комитет экспертов со всего мира под названием «Объединённая группа экспертов по фотографии» (Joint Photographic Experts Group, JPEG), основанный в рамках совместной работы Международной организации по стандартизации (ISO) и Международной электротехнической комиссии (IEC) – двух международных организаций по стандартизации, штаб-квартира которых расположена в Женеве (Швейцария).
Группа людей под названием JPEG создала стандарт сжатия цифровых изображений JPEG в 1992 году. Любой человек, использовавший интернет, вероятно, встречался с изображениями в кодировке JPEG. Это самый распространённый способ кодирования, отправки и хранения изображений. От веб-страниц до емейла и соцсетей, JPEG используется миллиарды раз в день – практически каждый раз, когда мы смотрим изображение онлайн или отправляем его. Без JPEG веб был бы менее ярким, более медленным, и, вероятно, в нём было бы меньше фоток котиков!
Без JPEG веб был бы менее ярким, более медленным, и, вероятно, в нём было бы меньше фоток котиков!
Эта статья – о том, как декодировать JPEG изображение. Иначе говоря, о том, что требуется для преобразования сжатых данных, хранящихся на компьютере, в изображение, появляющееся на экране. Об этом стоит знать не только потому, что это важно для понимания технологии, которую мы используем ежедневно, но и потому, что раскрывая уровни сжатия, мы лучше узнаём восприятие и зрение, а также то, к каким деталям наши глаза восприимчивей всего.
Кроме того, играться с изображениями таким способом очень интересно.
Заглядывая внутрь JPEG
На компьютере всё хранится в виде последовательности двоичных чисел. Обычно эти биты, нули и единицы, группируются по восемь, составляя байты. Когда вы открываете JPEG изображение на компьютере, что-то (браузер, операционка, ещё что-то) должно декодировать байты, восстановив изначальное изображение в виде списка цветов, которые можно показать.

Если вы скачаете эту умильную фотографию кота и откроете её в текстовом редакторе, вы увидите кучу бессвязных символов.
Здесь я использую Notepad++ для изучения содержимого файла, поскольку обычные текстовые редакторы, типа Notepad из Windows, испортят двоичный файл после сохранения, и он перестанет удовлетворять формату JPEG.
Открывая изображение в текстовом редакторе, вы сбиваете компьютер с толку, точно так же, как вы сбиваете с толку свой мозг, когда потрёте глаза и начинаете видеть цветные пятна!
Эти пятна, которые вы видите, известны, как фосфены, и не являются результатом воздействия светового стимула или галлюцинациями, порождёнными разумом. Они возникают, потому что ваш мозг считает, что любые электрические сигналы в глазных нервах передают информацию о свете. Мозгу необходимо делать такие предположения, поскольку никак нельзя узнать, является ли сигнал звуком, видением или чем-то ещё. Все нервы в теле передают абсолютно одинаковые электрические импульсы. Давя на глаза, вы отправляете сигналы, не являющиеся зрительными, но активирующие рецепторы глаза, что ваш мозг интерпретирует – в данном случае, неверно – как нечто зрительное. Вы буквально способны видеть давление!
Давя на глаза, вы отправляете сигналы, не являющиеся зрительными, но активирующие рецепторы глаза, что ваш мозг интерпретирует – в данном случае, неверно – как нечто зрительное. Вы буквально способны видеть давление!
Забавно думать о том, насколько компьютеры похожи на мозг, однако это также является полезной аналогией, иллюстрирующей, насколько сильно значение данных – передаваемых по телу нервами, или хранящихся на компьютере – зависит от их интерпретации. Все двоичные данные состоят из нулей и единиц, базовых компонентов, способных передавать информацию любого вида. Ваш компьютер часто догадывается, как интерпретировать их при помощи подсказок, например, расширений файлов. А сейчас мы заставляем его интерпретировать их как текст, поскольку именно этого ожидает текстовый редактор.
Чтобы понять, как декодировать JPEG, нам нужно увидеть сами изначальные сигналы – двоичные данные. Это можно сделать при помощи шестнадцатеричного редактора, или же прямо на веб-странице оригинала статьи! Там есть изображение, рядом с которым в текстовом поле приведены все его байты (кроме заголовка), представленные в десятичном виде. Вы можете менять их, и скрипт перекодирует и выдаст новое изображение на лету.
Вы можете менять их, и скрипт перекодирует и выдаст новое изображение на лету.
Можно узнать многое, просто играясь с этим редактором. К примеру, можете ли вы сказать, в каком порядке хранятся пиксели?
В этом примере странно то, что изменение некоторых чисел вообще не влияет на изображение, а, например, если заменить число 17 на 0 в первой строке, то фотка полностью испортится!
Другие изменения, например, замена 7 на строке 1988 на число 254 изменяет цвет, но только последующих пикселей.
Возможно, наиболее странным будет то, что некоторые числа меняют не только цвет, но и форму изображения. Измените 70 в строке 12 на 2 и посмотрите на верхний ряд изображения, чтобы увидеть, что я имею в виду.
И вне зависимости от того, какое JPEG изображение вы используете, вы всегда будете находить эти загадочные шахматные последовательности при редактировании байтов.
Играясь с редактором, тяжело понять, как воссоздаётся фотка из этих байтов, поскольку JPEG сжатие состоит из трёх различных технологий, применяющихся последовательно по уровням. Мы изучим каждую из них отдельно, чтобы раскрыть наблюдаемое нами загадочное поведение.
Мы изучим каждую из них отдельно, чтобы раскрыть наблюдаемое нами загадочное поведение.
Три уровня JPEG сжатия:
- Цветовая субдискретизация.
- Дискретное косинусное преобразование и дискретизация.
- Кодирование длин серий, дельта и Хаффмана
Дабы вы могли представить себе масштабы сжатия, обратите внимание, что изображение, приведённое выше, представляет 79 819 чисел, то есть, около 79 Кб. Если бы мы хранили его без сжатия, для каждого пикселя потребовалось бы по три числа – для красной, зелёной и синей составляющей. Это составило бы 917 700 чисел, или ок. 917 Кб. В результате JPEG сжатия итоговый файл уменьшился больше чем в 10 раз!
На самом деле, это изображение можно сжать гораздо сильнее. Снизу приведены два изображения рядом – фотка справа была ужата до 16 Кб, то есть в 57 раз меньше, чем несжатая версия!
Если присмотреться, будет видно, что эти изображения не идентичны. Оба они – картинки с JPEG сжатием, однако правая гораздо меньше по объёму. Также она выглядит чуть похуже (посмотрите на квадраты цветов фона). Поэтому JPEG ещё называют сжатием с потерями; в процессе сжатия изображение меняется и теряет некоторые детали.
Также она выглядит чуть похуже (посмотрите на квадраты цветов фона). Поэтому JPEG ещё называют сжатием с потерями; в процессе сжатия изображение меняется и теряет некоторые детали.
1. Цветовая субдискретизация
Вот изображение с применением только первого уровня сжатия.
(Интерактивная версия – в оригинале статьи). Удаление одного числа рушит все цвета. Однако если удалить ровно шесть чисел, это практически не влияет на изображение.
Теперь числа чуть проще расшифровать. Это почти что простой список цветов, у которого каждый байт изменяет ровно один пиксель, но при этом он уже в два раза меньше несжатого изображения (которое занимало бы ок. 300 Кб в таком уменьшенном размере). Догадаетесь, почему?
Можно видеть, что эти числа не обозначают стандартные красную, зелёную и синюю компоненты, поскольку если заменить все числа нулями, мы получим зелёное изображение (а не белое).
Это потому, что эти байты обозначают Y (яркость),
Cb (относительная голубизна),
и Cr (относительная краснота) картинки.
Почему не использовать RGB? Ведь именно так работает большинство современных экранов. Ваш монитор может демонстрировать любой цвет, включая красный, зелёный и синий цвета с разной интенсивностью для каждого пикселя. Белый получается включением всех трёх на полную яркость, а чёрный – их отключением.
Это также очень похоже на работу человеческого глаза. Цветовые рецепторы наших глаз называются «колбочки», и делятся на три типа, каждый из которых более чувствителен либо к красному, либо к зелёному, либо к синему цветам [колбочки S-типа чувствительны в фиолетово-синей (S от англ. Short — коротковолновый спектр), M-типа — в зелено-желтой (M от англ. Medium — средневолновый), и L-типа — в желто-красной (L от англ. Long — длинноволновый) частях спектра. Наличие этих трёх видов колбочек (и палочек, чувствительных в изумрудно-зелёной части спектра) даёт человеку цветное зрение. / прим. перев.]. Палочки, другой тип фоторецепторов в наших глазах, способны улавливать только изменения в яркости, однако они гораздо более чувствительные. В наших глазах есть около 120 млн палочек и всего 6 млн колбочек.
В наших глазах есть около 120 млн палочек и всего 6 млн колбочек.
Поэтому наши глаза гораздо лучше замечают изменения в яркости, чем изменения в цвете. Если отделить цвет от яркости, можно убрать немного цвета, и никто ничего не заметит. Цветовая субдискретизация – это процесс представления цветовых компонентов изображения в меньшем разрешении по сравнению с компонентами яркости. В примере выше у каждого пикселя ровно один компонент Y, а у каждой отдельной группы из четырёх пикселей есть ровно одна компонента Cb и одна Cr. Поэтому изображение содержит в четыре раза меньше цветовой информации, чем было у оригинала.
Цветовое пространство YCbCr используется не только в JPEG. Его изначально придумали в 1938 году для телепередач. Не у всех есть цветной телевизор, поэтому разделение цвета и яркости позволило всем получать один и тот же сигнал, а телевизоры без цвета просто использовали только компонент яркости.
Поэтому удаление одного числа из редактора полностью рушит все цвета. Компоненты хранятся в виде Y Y Y Y Cb Cr (на самом деле, не обязательно в таком порядке – порядок хранения задаётся в заголовке файла). Удаление первого числа приведёт к тому, что первое значение Cb будет воспринято, как Y, Cr как Cb, и в целом получится эффект домино, переключающий все цвета картинки.
Компоненты хранятся в виде Y Y Y Y Cb Cr (на самом деле, не обязательно в таком порядке – порядок хранения задаётся в заголовке файла). Удаление первого числа приведёт к тому, что первое значение Cb будет воспринято, как Y, Cr как Cb, и в целом получится эффект домино, переключающий все цвета картинки.
Спецификация JPEG не обязывает вас использовать YCbCr. Но в большинстве файлов она используются, поскольку она даёт изображения лучшего качества после субдискретизации по сравнению с RGB. Но вам не обязательно верить мне на слово. Посмотрите сами в табличке ниже, как будет выглядеть субдискретизация каждого отдельного компонента как в RGB, так и в YCbCr.
(Интерактивная версия – в оригинале статьи).
Удаление синего не так заметно, как красного или зелёного. Всё потому, что из шести миллионов колбочек в ваших глазах около 64% чувствительны к красному, 32% к зелёному и 2% к синему.
Субдискретизация компонента Y (слева внизу) видна лучше всего. Заметно даже небольшое изменение.
Преобразование изображения из RGB в YCbCr не уменьшает размер файла, но облегчает поиск менее заметных деталей, которые можно удалить. Сжатие с потерями происходит на втором этапе. В её основе лежит идея представления данных в более сжимаемом виде.
2. Дискретное косинусное преобразование и дискретизация
Этот уровень сжатия по большей части и определяет суть JPEG. После преобразования цветов в YCbCr компоненты сжимаются по отдельности, поэтому далее мы можем сконцентрироваться только на компоненте Y. И вот как выглядят байты компонента Y после применения этого уровня.
(Интерактивная версия – в оригинале статьи). В интерактивной версии клик на пикселе прокручивает редактор на строчку, которая его обозначает. Попробуйте поудалять числа с конца или добавить несколько нулей к определённому числу.
На первый взгляд, выглядит, как очень плохое сжатие. В изображении 100 000 пикселей, и для обозначения их яркости (Y-компоненты) требуется 102 400 чисел — это хуже, чем если вообще ничего не сжимать!
Однако обратите внимание на то, что большинство этих чисел равны нулю. Более того, все эти нули в конце строк можно удалять, не меняя изображение. Остаётся порядка 26 000 чисел, а это уже почти в 4 раза меньше!
Более того, все эти нули в конце строк можно удалять, не меняя изображение. Остаётся порядка 26 000 чисел, а это уже почти в 4 раза меньше!
На этом уровне находится секрет шахматных узоров. В отличие от других эффектов, которые мы видели, появление этих узоров не является глюком. Они – строительные блоки всего изображения. В каждой строчке редактора содержится ровно 64 числа, коэффициенты дискретного косинусного преобразования (DCT), соответствующие интенсивностям 64-х уникальных узоров.
Эти узоры формируются на основе графика косинуса. Вот, как выглядят некоторые из них:
8 из 64 коэффициентов
Ниже – изображение, демонстрирующее все 64 узора.
(Интерактивная версия – в оригинале статьи).
Эти узоры имеют особое значение, поскольку они формируют базис изображений размера 8х8. Если вы незнакомы с линейной алгеброй, то это означает, что любое изображение размера 8х8 можно получить из этих 64-х узоров. DCT – это процесс разбиения изображений на блоки 8х8 и преобразования каждого блока в комбинацию из этих 64 коэффициентов.
То, что любое изображение можно составить из 64 определённых узоров, кажется волшебством. Однако это то же самое, что сказать, что любое место на Земле можно описать двумя числами – широтой и долготой [с указанием полушарий / прим. перев.]. Мы часто считаем поверхность Земли двумерной, поэтому нам требуются всего два числа. Изображение 8х8 имеет 64 измерения, поэтому нам требуются 64 числа.
Пока непонятно, как это помогает нам в смысле сжатия. Если нам нужно 64 числа для представления изображения 8х8, почему этот способ будет лучше, чем просто хранить 64 компоненты яркости? Мы делаем это по той же причине, по которой мы превратили три числа RGB в три числа YCbCr: это позволяет нам удалить незаметные детали.
Сложно увидеть, какие именно детали удаляются на этом этапе, поскольку JPEG применяет DCT к блокам 8х8. Однако никто не запрещает нам применить его к целой картинке. Вот, как выглядит DCT по компоненте Y в применении к целой картинке:
С конца можно удалить более 60 000 чисел практически без заметных изменений на фотке.
Однако отметьте, что если мы обнулим первые пять чисел, разница будет очевидной.
Числа в начале обозначают изменения низкой частоты в изображении, и наши глаза улавливают их лучше всего. Числа ближе к концу обозначают изменения высоких частот, которые сложнее заметить. Чтобы «увидеть то, что не видно глазом», мы можем изолировать эти детали высокой частоты, обнулив первые 5000 чисел.
Мы видим все области изображения, в которых происходит наибольшее изменение от пикселя к пикселю. Выделяются глаза кота, его усы, махровое одеяло и тени в нижнем левом углу. Можно пойти и дальше, обнулив первые 10 000 чисел:
20 000:
40 000:
60 000:
Эти высокочастотные детали JPEG и удаляет на этапе сжатия. Преобразование цветов в коэффициенты DCT не несёт потерь. Потери образуются на шаге дискретизации, где удаляются величины высокой частоты или близкие к нулю. Когда вы понижаете качество сохранения JPEG, программа увеличивает порог количества удаляемых значений, что даёт уменьшение размера файла, но делает картинку более пикселизированной. Поэтому изображение в первом разделе, которое было в 57 раз меньше, так выглядело. Каждый блок 8х8 представлялся гораздо меньшим количеством коэффициентов DCT по сравнению с более качественной версией.
Поэтому изображение в первом разделе, которое было в 57 раз меньше, так выглядело. Каждый блок 8х8 представлялся гораздо меньшим количеством коэффициентов DCT по сравнению с более качественной версией.
Можно сделать такой крутой эффект, как постепенная потоковая передача изображений. Можно вывести размытую картинку, которая становится всё более детализированной по мере скачивания всё большего количества коэффициентов.
Вот, просто для интереса, что получится при использовании всего 24 000 чисел:
Или всего 5000:
Очень размыто, но как будто узнаваемо!
3. Кодирование длин серий, дельта и Хаффмана
Пока что все этапы сжатия шли с потерями. Последний этап, наоборот, идёт без потерь. Он не удаляет информацию, однако значительно уменьшает размер файла.
Как можно сжать что-либо, не отбрасывая информацию? Представьте, как бы мы описали простой чёрный прямоугольник 700 х 437.
JPEG использует для этого 5000 чисел, но можно достичь гораздо лучшего результата. Можете представить себе схему кодирования, которая бы описывала подобное изображение как можно меньшим количеством байт?
Можете представить себе схему кодирования, которая бы описывала подобное изображение как можно меньшим количеством байт?
Минимальная схема, которую смог придумать я, использует четыре: три для обозначения цвета, и четвёртый – сколько пикселей имеет такой цвет. Идея представления повторяющихся значений таким сжатым способом называется кодирование длин серий. Она не имеет потерь, поскольку мы можем восстановить закодированные данные в первозданном виде.
Размер файла JPEG с чёрным прямоугольником гораздо больше 4 байт – вспомните, что на уровне DCT сжатие применяется к блокам 8х8 пикселей. Поэтому как минимум нам нужен один коэффициент DCT на каждые 64 пикселя. Один нам нужен потому, что вместо того, чтобы хранить один DCT-коэффициент, за которым идёт 63 нуля, кодирование длин серий позволяет нам хранить одно число и обозначить, что «все остальные – нули».
Дельта-кодирование – это техника, при которой каждый байт содержит отличие от какого-то значения, а не абсолютную величину. Поэтому редактирование определённых байтов изменяет цвет всех остальных пикселей. К примеру, вместо того, чтобы хранить
Поэтому редактирование определённых байтов изменяет цвет всех остальных пикселей. К примеру, вместо того, чтобы хранить
12 13 14 14 14 13 13 14
Мы могли бы начать с 12, а потом просто обозначать, сколько надо прибавить или отнять, чтобы получить следующее число. И эта последовательность в дельта-кодировании приобретает вид:
12 1 1 0 0 -1 0 1
Преобразованные данные не получаются меньше исходных, но сжимать их уже легче. Применение дельта-кодирования перед кодированием длин серий может сильно помочь, оставаясь при этом сжатием без потерь.
Дельта-кодирование – одна из немногих техник, применяемых вне блоков 8х8. Из 64 коэффициентов DCT один – просто постоянная волновая функция (сплошной цвет). Он представляет среднюю яркость каждого блока для компонент яркости, или среднюю голубизну для компонентов Cb, и так далее. Первое значение каждого DCT-блока называется DC-значением, и каждое DC-значение проходит дельта-кодирование по отношению к предыдущим. Поэтому изменение яркости первого блока повлияет на все блоки.
Остаётся последняя загадка: как изменение единственного числа полностью портит всю картинку? Пока таких свойств у уровней сжатия не было. Ответ лежит в заголовке JPEG. Первые 500 байт содержат метаданные об изображении – ширину, высоту, и проч., и пока мы с ними не работали.
Без заголовка практически невозможно (ну, или очень сложно) декодировать JPEG. Это будет выглядеть так, будто я пытаюсь описать вам картину, и начинаю изобретать слова для того, чтобы передать своё впечатление. Описание будет, вероятно, весьма сжатым, поскольку я могу изобретать слова именно с тем значением, которое я хочу передать, однако для всех остальных они не будут иметь смысла.
Звучит глупо, но именно так это и происходит. Каждое изображение JPEG сжимается с кодами, специфичными именно для него. Словарь кодов хранится в заголовке. Эта техника называется «код Хаффмана», а словарь – таблицей Хаффмана. В заголовке таблица отмечена двумя байтами – 255 и потом 196. У каждого цветового компонента может быть своя таблица.
Изменения таблиц радикально повлияют на любое изображение. Хороший пример – поменять на 15-й строке 1 на 12.
Это происходит потому, что в таблицах указывается, как нужно читать отдельные биты. Пока что мы работали только с двоичными числами в десятичном виде. Но это скрывает от нас тот факт, что если вы хотите хранить число 1 в байте, то оно будет выглядеть, как 00000001, поскольку в каждом байте должно быть ровно восемь бит, даже если нужен из них всего один.
Потенциально это большая трата места, если у вас есть много мелких чисел. Код Хаффмана – это техника, позволяющая нам ослабить это требование, по которому каждое число должно занимать восемь бит. Это значит, что если вы видите два байта:
234 115
То, в зависимости от таблицы Хаффмана, это могут быть три числа. Чтобы их извлечь, вам надо сначала разбить их на отдельные биты:
11101010 01110011
Затем обращаемся к таблице, чтобы понять, как их группировать. К примеру, это могут быть первые шесть битов, (111010), или 58 в десятичной системе, за которыми идут пять битов (10011), или 19, и наконец последние четыре бита (0011), или 3.
Поэтому очень сложно разобраться в байтах на этом этапе сжатия. Байты не представляют то, что кажется. Не буду углубляться в детали работы с таблицей в данной статье, но материалов по этому вопросу в сети достаточно.
Один из интересных трюков, которые можно проделать, зная это – отделить заголовок от JPEG и хранить его отдельно. По сути, получится, что файл сможете прочесть только вы. Facebook проделывает это, чтобы ещё сильнее уменьшать файлы.
Что ещё можно сделать – совсем немного изменить таблицу Хаффмана. Для других это будет выглядеть, как испорченная картинка. И только вы будете знать волшебный вариант её исправления.
Подведём итоги: так что же нужно для декодирования JPEG? Необходимо:
- Извлечь таблицу (таблицы) Хаффмана из заголовка и декодировать биты.
- Извлечь коэффициенты дискретного косинусного преобразования для каждого компонента цвета и яркости для каждого блока 8х8, проведя обратные преобразования кодирования длин серий и дельты.

- Скомбинировать косинусы на основе коэффициентов, чтобы получить значения пикселей для каждого блока 8х8.
- Масштабировать компоненты цветов, если проводилась субдискретизация (эта информация есть в заголовке).
- Преобразовать полученные значения YCbCr для каждого пикселя в RGB.
- Вывести изображение на экран!
Серьёзная работа для простого просмотра фотки с котиком! Однако, что мне в этом нравится – видно, насколько технология JPEG человекоцентрична. Она основана на особенностях нашего восприятия, позволяющих достичь гораздо лучшего сжатия, чем обычные технологии. И теперь, понимая, как работает JPEG, можно представить, как эти технологии можно перенести в другие области. К примеру, дельта-кодирование в видео может дать серьёзное уменьшение размера файла, поскольку там часто есть целые области, не меняющиеся от кадра к кадру (к примеру, фон).
Код, использованный в статье, открыт, и содержит инструкции по замене картинок на свои собственные.
Как я организовал хранение фотографий / Хабр
Привет Хабр! Каждый из нас хранит какую-нибудь информацию, некоторые для этого используют секретики и лайфхаки. Лично я люблю понажимать кнопку фоторужья и сегодня хотел бы поделиться своим опытом хранения информации, к которому я шёл-шёл и пришёл.Сразу предупрежу: под катом нет «серебряной пули», которая умножит на 0 проблему хаоса в файлах на ваших устройствах. И даже ни строчки про нейросети, распознавание чего-либо кем-либо и прочие нанотехнологии. Под катом — немного текста и дубовая табличка, которую ещё и заполнять придётся вручную =) Но которая работает.
Интро
Прежде чем понять, какую проблемы я хотел решить, давайте я вкратце расскажу про неё =) Я не считаю себя прям фотографом-фотографом, но всё же:
- Имею фоторужьё и фоткаю в RAW (каждая фотка весит в среднем 20-25 МБ)
- У меня встал вопрос хранения и структуризации фотографий (а точнее их исходников)
Теперь чуть более подробней.

Я использую 1-2 карты памяти по 64 ГБ (не те, что на фото ниже, хотя я знаю, что они уже попали в поле зрения)) — покупать более объёмные карты (128-256) меня поддушивает жаба. Даже не столько жаба, сколько отношение к карте как к некому расходнику, с которым в любой момент может случиться фиаско: карты я терял, гнул, а один раз её тупо спёрли прямо из фотика. Да и «все яйца в одной корзине» — не самый дальновидный подход.
Вот что бывает, когда забыл вытащить карту из ноутбука, положил его на пассажирское сиденье и резко затормозил. И на эти грабли — два раза.
64 ГБ это где-то 2000-2500 фотографий в равах. В моём случае это 4-6 фотосетов мероприятий или около 10 «гаджетных». Посмотрите мои предыдущие публикации и увидите, зачем столько много. Кто-то скажет «зачем так мучать кнопку спуска» и будет прав, но я выше написал, что я немного нуб. Более того, имею пагубную привычку делать по два кадра — если первый получится смазанным, то, возможно, второй придёт на помощь. У меня это на уровне инстинкта и пока ничего не могу с этим поделать. Это же ответ на вопрос «зачем я фоткаю в равы» — да банально чтобы исправлять потом свои же косяки, всякие там пересветы-недосветы и прочие геометрии.
У меня это на уровне инстинкта и пока ничего не могу с этим поделать. Это же ответ на вопрос «зачем я фоткаю в равы» — да банально чтобы исправлять потом свои же косяки, всякие там пересветы-недосветы и прочие геометрии.
Проблема
За долгое время я так и не смог найти программу, которая помогла бы мне в полной мере покрыть мои потребности в хранении данных. Есть каталогизаторы, есть удобная работа с мета-тегами, с распознаванием лиц и нанесением фото на карту — целый вагон крутых фич, но… раскиданных по разным приложениям. Перечислю несколько подводных камней, о которые спотыкались почти все приложения.
Проблема номер 1: вот лежит на столе карта памяти — что на ней? Никогда не знаешь. Конечно, можно поскроллить 2000 фоток на фотоаппарате, вставить в ноут или вести заметки в смартфоне, но «общей картины» это не даст. И не ответит на вопрос «а сделал ли я уже бэкап этих данных или их можно удалить безвозвратно?», если, например, срочно надо освободить место? Ведь свободных 64 ГБ может не оказаться под рукой.
Проблема номер 2: никогда не знаешь, в каком состоянии фотографии. Отсортированы? Обработаны? Можно удалять или сперва скинуть на комп? Вам же знакомы эти бесконечные папки «From SD», «SD64 LAST», «!UNSORTED», «2018 ALL», «iPhone_before_update» и прочее? =) На ноуте, на карте памяти, на внешнем диске, с кучей повторов? И это гнетущее ощущение, «надо бы порядочек во всём этом навести — вот будут свободные выходные…». А свободных выходных всё нет и нет.
Проблема 3: а как вообще быстро найти нужные фоточки? Например, недавно мне понадобилось делать коллаж из всех «первых сентябрей» за несколько лет. Хранить на ноуте? Не влезет. Шерстить по разным дискам? Ну, как вариант. Но неудобно же?..
Я буду крайне благодарен, если вы мне подскажете более функциональный и гибкий вариант, чем тот, который я методом проб и ошибок придумал для себя (ниже). Повторюсь, что речь не про просмотрщик/сортировщик фоток, а именно про удобство/наглядность/информативность.
Решение
Я решил использовать такой крутой инструмент, как таблицы в GoogleDocs =) Он бесплатный, кроссплатформенный и тэдэ — думаю, в представлении не нуждается. Перед составлением каркаса таблички, я постарался понять, какие поля мне нужны. Их можно придумать хоть сотню, но надо сделать так, чтобы ими было удобно пользоваться и не надоедало каждый раз заполнять. Ну и постараться учесть дальнейшее масштабирование: чтобы табличкой было удобно пользоваться через год-два-три.
Свои думы я остановил на следующем наборе полей:
- Категория. Я проанализировал то, что фотографирую и разбил это на категории. Получилось так:
Cars — автомобили
Events — мероприятия
Gadgets — гаджеты
Girls — ну вы поняли
Home — что-то домашнее, семейное
Life — любая движуха, не попадающая в категории выше
— =)
Travel — путешествия
Все фотосеты будут раскладываться по этим разделам. Если вы прям много-много фотографируете, то каждый раздел удобней держать на отдельном листе (внизу таблицы).
Важно: постарайтесь избежать создания категории «Other» (Разное), так как именно в ней зародится хаос, который схлопнет вселенную. Максимум — «!Temp», в которую вы будете сливать файлы для дальнейшей сортировки по другим категориям. - Название. Внутри категории у каждого фотосета есть название — надо давать такие имена, которые будет легко вспомнить или найти. Здесь удобны 2 варианта: по алфавиту или в хронологическом порядке. Я чередую оба варианта: в гаджетах удобней использовать названия устройств, в мероприятиях — маску типа «2018-03-08 — 8 марта». Если что, всегда есть CMD+F.
- Где сейчас. В этом столбце я указываю, где сейчас хранятся фотографии — на карте памяти фотика, на ноуте, на внешнем диске или в облаке. Если местоположение данных меняется, табличка обновляется. Важно указать информацию о фотосете сразу, иначе потом забудется.
- Штук до сортировки. Не всегда получается (а точнее, вообще никогда не получается) взять сразу и отсортировать гигабайты RAW-ов, обычно их просто скидываешь с карты памяти.
 И тут важно понимать, сколько фотографий в фотосете — чтобы примерно прикидывать, сколько времени уйдёт на сортировку и обработку.
И тут важно понимать, сколько фотографий в фотосете — чтобы примерно прикидывать, сколько времени уйдёт на сортировку и обработку.Лайфхак: полезным будет знать среднюю скорость сортировки и обработки фотографий, если вы этим вообще заморачиваетесь. Просто ставите таймер на 5-10 минут и потом смотрите, сколько успели облагородить. У меня в среднем уходит по 2-5 минут на фотографию (при условии, что я хорошо знаю хоткеи в фотошопе). Далее см. п. 8.
- Сортировка и обработка. Просто два столбца, ячейки которых закрашиваются либо зелёным (= «Сделано»), либо красным (= «Не сделано») цветом. Можно добавить, например, синий — если обработка не требуется. Подобная цветовая легенда наглядно покажет, что и в каком состоянии находится. Опционально в неё можно выводить циферки — скорость работы, умноженную на количество фото после сортировки (см. п. 11).
Под сортировкой я имею в виду отбор лучших кадров (удаление повторов и брака) для дальнейшей обработки, а под самой обработкой — их путь от рава до джипега (который не стыдно показать другим).
 В дальнейшем внутри каждой папки будут лежать именно обработанные джипеги, а в подпапке «Originals» — равы и *.xmp-шки от них.
В дальнейшем внутри каждой папки будут лежать именно обработанные джипеги, а в подпапке «Originals» — равы и *.xmp-шки от них. - Копия в облаке. Обычно нет смысла заливать неотсортированный пласт фоток в облако, это пустая трата времени и места. Туда есть смысл бэкапить уже отсортированные фотографии. А лучше — уже обработанные. Если я заливаю файлы в облако, то делаю кликабельную ссылку на папку — чтобы в нужное место я мог в один клик перейти из таблички, а не лазить по онлайн-файлменеджеру (которые, как правило, тормозят).
- Копия на диске. Облака принято считать надёжными, но что-то внутри подсказывает, что лучше иметь бэкап ещё и локально (хотя бы для особо важных данных). Ну либо если речь идёт о каких-то «чувствительных» данных, которые не хотелось бы загружать в инет.
- Количество, размер. Количество фотографий после сортировки, а также размер занимаемого ими места. Необязательный столбец, но сейчас попробую объяснить, зачем я его сделал.

Если я вижу некий фотосет с зелёной ячейкой «Сортировка» и красной «Обработка» — это значит, что мне просто нужно некоторое количество свободного времени для довольно тупой и однообразной механической работы. Зная количество и размер фоток, я могу запланировать это занятие. Например, в следующие выходные мне предстоит сгонять на «сапсане» из Москвы в Питер и обратно, то есть я знаю, что у меня будет ноут и 8 часов без стабильного интернета (= отличные условия для обработки фотографий). Примерно прикидываем, сколько фотографий успеем обработать за это время и заливаем нужные фотосеты на ноут. Тут-то и пригодится знание хотя бы примерной скорости обработки 1 фото. У меня на фото уходит от 2 до 5 минут, 8 часов это 480 минут, а значит вряд ли есть смысл копировать на ноут более 300 фотографий (что составляет примерно от 6 до 9 ГБ). У меня в макбуке диск на 256 ГБ, порой приходится «играть в пятнашки», но с табличкой суммарный размер фотосетов никогда не становится для меня сюрпризом.
А дальше просто нужно приехать пораньше на вокзал, чтобы успеть занять столик в вагоне-ресторане =) - Дата съёмки.
 Важный параметр, который тесно связан со следующим столбцом.
Важный параметр, который тесно связан со следующим столбцом. - На телефоне. Часто бывает так, что помимо фоторужья приходится параллельно снимать что-то на телефон. Например, если вы фоткаете динамичную сцену (гонки), а знакомого просите снять видео. Или если делаете ремонт и у вас грязные руки — доставать фотик не хочется, а снять на телефон — в самый раз. Как результат — прямо сейчас на 128-гиговом айфоне у меня 25000 фотографий. Да, там много буллшита, но и нужного хватает.
Чтобы важные телефонные фотки не жили отдельной жизнью, их будет правильней добавить в папку тематического фотосета. И вот как раз по дате искать нужное быстрее всего (хотя геометки тут тоже очень помогают). Если есть пометка «Да» в телефоне — значит мне надо отдельно скинуть фотки с телефона. Если «Нет» — значит или их не было, или они уже скинуты.
- Брак. Вряд ли вам пригодится этот столбец, но для себя я пока решил его оставить. Он отображает, какой процент брака с фотосета я удаляю — в среднем это 50%, то есть, как я и говорил, моя проблема в том, что я делаю дублирующие кадры.
 Я в целом не вижу в этом ничего плохого, shutter count мне не жалко =) но всё же для меня это некий раздражитель, который я вижу каждый раз при заходе в табличку и каждый раз я думаю «поучииииись фоткать, прокачаааай знания и умения». Однажды психану и займусь!
Я в целом не вижу в этом ничего плохого, shutter count мне не жалко =) но всё же для меня это некий раздражитель, который я вижу каждый раз при заходе в табличку и каждый раз я думаю «поучииииись фоткать, прокачаааай знания и умения». Однажды психану и займусь! - Драфт и пост. В случае, если мне надо что-то написать про фотографируемый объект (например, обзор девайса, коих в моём профиле было немало), то сначала я создаю черновик в гуглдокс, ссылку на который привязываю к слову «Тут». Зелёный цвет — черновик закончен, жёлтый — в процессе, красный — ещё не брался. То же самое с постами — добавление ссылки на пост позволяет в один клик перейти в нужный пост, без всяких там гуглений.
Сразу видно, в каком состоянии все публикации, каков размер «технического долга».
Кликабельно:
Собственно, такая табличка у меня вышла =) Довольно массивная, но я её делал под себя. Если вам понравился мой ход мыслей, то берите и адаптируйте под свои потребности, добавяйте-убирайте.
Опционально можно суммировать вес всех фотосетов, и отсчитывать % занимаемого места на носителе известной ёмкости (этакий прогресс-бар).
Кстати о носителях.
Сначала я хранил файлы только на ноуте, но место быстро кончилось. Купил внешний дисочек на 2.5″ — тот относительно скоро сдох по моей вине, так как я его постоянно таскал с собой в рюкзаке и однажды не уберёг.
Решил попробовать Я.Диск, купил 1ТБ — в целом вроде удобно, но в то же время много неудобно: скорость загрузки и скачивания, стоимость, конфиденциальность (вдруг какая-нибудь бета-версия нового алгоритма посчитает мои фотки недопустимыми и почикает весь аккаунт?) и много чего ещё.
Поэтому в итоге я остановился на версии симбиоза: взял два стационарных диска и оставил активной подписку в Я.Диске в качестве транзитного пункта и запасного колеса. В облако улетают те «нечувствительные» данные, которые потенциально могут понадобиться в самом обозримом будущем — например, фотографии девайса, о котором предстоит написать, или фотографии с детских мероприятий, которые предстоит пошарить с другими родителями (наличие зеркалки автоматически обрекает вас на эту функцию в детском саду и школе). На дисках — всё то, чему не место в облаке.
На дисках — всё то, чему не место в облаке.
В качестве стационарных накопителей в начале года взял два 3.5″ Seagate Ironwolf — серия дисочков специально для NAS-ов. В этой линейке есть модели от 1 до 14 ТБ — на 1 и 2 ТБ несерьёзно, на 6 и более — дороговато. Остановился на модели по 4 ТБ — сперва думал сделать из них JBOD на 8 ТБ, но потом посчитал и понял, что я пока ещё столько не нафоткал =) И в итоге склейл в рейд 1 — чтобы уж наверняка не кусать локти. Диски с 5900 оборотами, поэтому мало шума, особо не греются, со скоростью всё более чем ок (хотя точный замер даже не делал).
1ТБ на Я.Диске стоит 2000 ₽ в год, то есть 4 ТБ обойдутся в ежегодные 8К (лайфхак: если иметь подписку Я.Плюс за 1500 в год, на Я.Диск будет скидка 30%), из плюсов — добавить местечка можно в пару кликов. Seagate Ironwolf на 4 ТБ стоят по 7К за штуку (мне удалось урвать по 6), но зато ты их купил один раз, поставил и забыл — они могут автономно шуршать где-нибудь в шкафу и не просить денег с интервалом в год.

Ради интереса глянул тарифы в Облако@mail.ru — 1 ТБ стоит от 699 ₽ в месяц! ) То есть 8400 в год. 4 ТБ — от 2690 ₽ в месяц (32К в год).
Мне 4 ТБ для фотографий пока хватает с головой, но если вы занимаетесь монтажом видео, то будет мало. В общем, считайте сами под свои задачи =)
Важный момент, который следует учесть в расчётах. Недавно я общался с двумя свадебными фотографами — они сказали, что стараются отправить фото клиенту в течение месяца (это уже с ретушью). Потом ещё пару месяцев хранят фотки, а дальше безжалостно удаляют их, оставляя с каждого фотосета лишь пару фотографий для портфолио (и исходники для них на случай, если придётся кому-то что-то доказывать, у обоих такое бывало). Сначала я задумался о таком подходе: «Хм, а может ну его нафиг?! Ведь правда, зачем хранить все эти фотографии чужих свадеб и гаджетов, если ты никогда не будешь их смотреть?». Ждать магического «а вдруг пригодятся»? Если за последний год у вас не было такого пригождения, то поверьте, не пригодится. Но потом я подумал, что всё же есть разница между своим и чужим — да, семейные фотки и видео тоже не будешь смотреть сейчас, но будет очень приятно посмотреть через 5-10-15 лет. И вот тут-то понимаешь, что свободным местом лучше запастись.
Но потом я подумал, что всё же есть разница между своим и чужим — да, семейные фотки и видео тоже не будешь смотреть сейчас, но будет очень приятно посмотреть через 5-10-15 лет. И вот тут-то понимаешь, что свободным местом лучше запастись.
Браузерный лайфхак
Я пользуюсь Хромом и в нём есть удобная панель закладок (CMD+Shift+B). Создаём закладку таблицы с файлами, переименовываем её — присваиваем имя:
(уф, Хабр не поддерживает emoji, пришлось вставить картинкой). Если закладок много, можно сделать с разделителем, мне нравится этот — «⬝». С ним получается вот такая красота:
The end
Этой табличкой я пользуюсь уже около полугода и мне в целом всё в ней нравится, я уже привык её заполнять, пока файлики копируются. Поэтому предлагаю не тратить время на то, чтобы пытаться меня переубедить =) Но в то же время я понимаю, что она из каменного века и в ней, возможно (да не возможно, а точно!) много есть чего улучшить или автоматизировать (для чего нужно больше знаний и времени).
 Коллективный разум, давай вместе подумаем, как можно это всё улучшить/переделать/оптимизировать, добившись более крутых результатов при минимуме усилий? Любые предложения приветствуются.
Коллективный разум, давай вместе подумаем, как можно это всё улучшить/переделать/оптимизировать, добившись более крутых результатов при минимуме усилий? Любые предложения приветствуются.Ну или может быть у вас есть свои секреты разносолов хранения файлов — делитесь.
Надеюсь, был полезен =) Успехов!
Метаданные цифровых фотографий, Exif
Современные микропроцессорные средства, используемые в фотоаппаратах, позволяют организовать различные форматы хранения данных. Кроме изображения, в определённом формате, в файле может сохраняться дополнительная информация в виде метаданных. Одним из способов хранения дополнительной информации по фотографии являются “exif” данные. В статье рассмотрим вопрос: что такое Exif метаданные фотографии и как ими пользоваться.
Что такое “Exif”
Цифровые форматы хранения растровых изображений допускают на любом фотографическом файле сохранение дополнительного пакета данных. Стандарт шифрования метаданных Exif может включать в себя следующую информацию:
- Характеристики объекта съёмки;
- Параметры настроек фотоаппарата;
- Авторские права;
- Возможные изменения файла в фоторедакторе;
- GPS локацию места съёмки.

Из этих данных можно узнать марку фотоаппарата и все настройки, которые были выполнены для получения данной фотографии. Некоторые устройства могут вписывать в файл дополнительные данные, связанные с GPS информацией. При необходимости фотограф может самостоятельно заполнить все свободные поля метаданных. Часто “эксиф” данные используются для получения информации об изменении фото в фоторедакторе. Все манипуляции с файлом сохраняются в exif. Такая фотоинформация может потребоваться, чтобы выявить подделку или фотомонтаж.
Как посмотреть exif
Информационную составляющую фото можно легко посмотреть в изображениях, например, OC Windows. Для этого нужно открыть любую фотографию, кликнуть правой кнопкой мыши и выбрать пункт «Свойства». В верхней строке окна открыть вкладку «Подробно». Там вся информация разделена на следующие подзаголовки:
- Описание
- Источник
- Изображение
- Камера
- Улучшенное фото
- Файл
Часть полей автор фотокарточки может заполнить самостоятельно, а информация о параметрах настройки фотоаппарата, размере файла и использовании редактора для улучшения характеристик снимка, заполняется автоматически. Всё, что находится в этой таблице, является exif данными. Это далеко не полный список метаданных, которые могут храниться в файле с фото. Это, скорее, необходимый минимум, который покажет любая программа, предназначенная для просмотра файлов с фотографиями. Например, такая мощная программа, как Photoshop может сгенерировать таблицу «История», где будет описано, какими инструментами и с какими параметрами работал фотограф, улучшая качество базовой фотографии. После сохранения файла все “эксиф” данные в нём останутся.
Если открыть фото в этом редакторе, на любом компьютере, можно ознакомиться с протоколом редактирования. Для другой программы, типа GIMP, эта вкладка будет недоступна. Если метаданные нужно просмотреть в Photoshop, то следует одновременно нажать «Shift» + «Alt» + «Ctrl» + «I». Перед этим нужное фото должно быть открыто в этой программе. С помощью ключевых слов, записанных в exif, программа Adobe Bridge, или ей подобная, может выполнять сортировку фотографий, отбирая нужные файлы из десятков тысяч снимков.
Еxif данные могут быть изменяемыми и постоянными. Изменяемая информация делится на редактируемую вручную и программную. Первый вид можно самостоятельно вписывать в нужные поля, переписывать и удалять. Если фотография сохраняется в Фотошопе, то теги, добавляемые программой, изменить или удалить невозможно. Для редактирования этих данных существуют специальные утилиты. Постоянные данные содержат инфо о типе фотоаппарата, его настройках, разрешении и размере файла. Эти метаданные навсегда прописаны в исходнике и могут быть удалены только вместе с самой фотокарточкой. Разные форматы сохранения фотографий по-разному используют возможности exif. В файле PNG сохраняется минимальная информация, зато JPG реализует все возможности записи информации. В “эксиф”, генерируемых растровым редактором, присутствует строка IPTC. В ней указываются авторские права и возможности использования данной фотографии в СМИ, а так же ограничения накладываемые автором.
Можно ли подделать данные
Теоретически подделать данную информацию можно. Часто такие манипуляции осуществляются для того, чтобы выдать фотомонтаж за оригинальную фотографию или для нарушения чьих-то авторских прав. В любом случае это связано с определёнными нарушениями. Изменяемые данные редактировать очень легко. Поскольку поля заполняются самостоятельно, то удалить одни данные и записать другие не составляет труда. В некоторых случаях бывает, что для удаления достаточно использовать контекстное меню “свойств файла” – «Удаление свойств и личной информации».
Если фотофайлов много, то можно использовать утилиту «ExifCleaner». Она позволяет удалять индивидуальные теги или стирать полностью все данные. Плюсом является то, что программа может работать в пакетном режиме. Подделка неизменяемых строк осуществляется методом замены всего пакета метаданных на другой. При необходимости это можно сделать, используя утилиту «ShowExif». Следует иметь в виду, что при тщательном анализе фотофайла подделка свойств будет обнаружена.
Как не потерять exif данные при обработке фото
Сами по себе exif метаданные не теряются. При переносе фото с камеры на компьютер вся информация сохраняется в полном объёме. Метаданные можно потерять, например, при конвертации фотографий из одного формата в другой. Чтобы этого не произошло, в настройках фотоконвертера, нужно предусмотреть полный перенос информации с исходного файла. Это может выглядеть следующим образом. «Меню конвертера» → «Дополнительные настройки» → «EXIF» → «Копировать Exif данные из исходного файла». После этого можно начинать процесс конвертации фото. В результате все метаданные будут сохранены.
Метаданные exif являются полезным инструментом для фотографа. Если приходится часто и много снимать, организовывая фотосессии, то информация о настройках фотоаппарата бывает просто необходима. С помощью ключей можно быстро сортировать любое количество фотографий, группируя их по отдельным признакам. Недостатком “эксиф” является то, что они занимают место на диске, поэтому некоторые фотографы удаляют лишние метаданные, оставляя только самое необходимое.
DataView — JavaScript | MDN
Представление DataView обеспечивает низкоуровневый интерфейс для чтения и записи нескольких типов чисел в двоичном массиве ArrayBuffer , не заботясь о порядке байтов платформы.
Порядок байтов
Многобайтовые числовые форматы представлены в памяти по-разному в зависимости от архитектуры машины — см. Порядок байтов для объяснения. DataView Средства доступа обеспечивают явное управление доступом к данным независимо от порядка байтов на исполняющем компьютере.
var littleEndian = (function () {
var buffer = новый ArrayBuffer (2);
новый DataView (буфер) .setInt16 (0, 256, true);
вернуть новый Int16Array (буфер) [0] === 256;
}) ();
console.log (littleEndian);
64-битные целочисленные значения
Поскольку JavaScript в настоящее время не включает стандартную поддержку 64-битных целочисленных значений, DataView не предлагает встроенных 64-битных операций. В качестве обходного пути вы можете реализовать свою собственную функцию getUint64 () для получения значения с точностью до Number.MAX_SAFE_INTEGER , которого может хватить в некоторых случаях.
function getUint64 (dataview, byteOffset, littleEndian) {
const left = dataview.getUint32 (byteOffset, littleEndian);
const right = dataview.getUint32 (byteOffset + 4, littleEndian);
const в сочетании = littleEndian? влево + 2 ** 32 * вправо: 2 ** 32 * влево + вправо;
если (! Number.isSafeInteger (в сочетании))
console.warn (вместе, 'превышает MAX_SAFE_INTEGER. Точность может быть потеряна');
возврат комбинированный;
}
В качестве альтернативы, если вам нужен полный 64-битный диапазон, вы можете создать BigInt .Кроме того, хотя собственные BigInts намного быстрее, чем эквиваленты пользовательских библиотек, BigInts всегда будут намного медленнее, чем 32-битные целые числа в JavaScript из-за природы их переменного размера.
const BigInt = window.BigInt, bigThirtyTwo = BigInt (32), bigZero = BigInt (0);
function getUint64BigInt (dataview, byteOffset, littleEndian) {
const left = BigInt (dataview.getUint32 (byteOffset | 0, !! littleEndian) >>> 0);
const right = BigInt (dataview.getUint32 ((byteOffset | 0) + 4 | 0, !! littleEndian) >>> 0);
вернуть littleEndian? (right << bigThirtyTwo) | left: (left << bigThirtyTwo) | right;
} Использование DataView
var buffer = new ArrayBuffer (16);
var view = new DataView (буфер, 0);
Посмотреть.setInt16 (1, 42);
view.getInt16 (1);
Таблицы BCD загружаются только в браузере
ОписаниеExifDataView - это небольшая утилита, которая считывает и отображает данные Exif, хранящиеся в файлах изображений .jpg, созданных цифровыми камерами. Данные EXIF включают название компании, создавшей камеру, модель камеры, дату и время, когда была сделана фотография, время экспозиции, скорость ISO, информацию GPS (для цифровых камер с GPS) и многое другое.Системные требования
История версий
Начать использование ExifDataViewExifDataView не требует никакого процесса установки или дополнительных файлов dll.Для того, чтобы начать им пользоваться, просто запустите исполняемый файл - ExifDataView.exe.После запуска ExifDataView.exe вы можете открыть файл .jpg, используя опцию «Открыть файл» (Ctrl + O) или перетащив файл .jpg. из проводника в главное окно ExifDataView. После открытия файла .jpg список всех свойств Exif отображается в верхней панели ExifDataView. При выборе одного свойства Exif на верхней панели нижняя панель отображает содержимое выбранного свойства как шестнадцатеричный дамп. Вы также можете выбрать одно или несколько свойств Exif на верхней панели, а затем скопировать их в буфер обмена и вставить в Excel, или сохраните их в файл text / csv / xml / html с помощью опции «Сохранить выбранные элементы» (Ctrl + S) Параметры командной строки
Перевод ExifDataView на другие языкиЧтобы перевести ExifDataView на другой язык, следуйте инструкциям ниже:
ЛицензияЭта утилита выпущена как бесплатное ПО. Вы можете свободно распространять эту утилиту через дискеты, CD-ROM, Интернет или любым другим способом, если вы ничего за это не берете и не продавать или распространять как часть коммерческого продукта. Если вы распространяете эту утилиту, вы должны включить все файлы в дистрибутив, без каких-либо модификаций!Заявление об ограничении ответственностиПрограммное обеспечение предоставляется «КАК ЕСТЬ» без каких-либо явных или подразумеваемых гарантий, включая, но не ограничиваясь, подразумеваемые гарантии товарной пригодности и пригодности для определенной цели.Автор не несет ответственности за какие-либо особые, случайные, косвенный или косвенный ущерб из-за потери данных или по любой другой причине.Обратная связьЕсли у вас есть проблемы, предложения, комментарии или вы обнаружили ошибку в моей утилите, вы можете отправить сообщение на [email protected] ExifDataView также доступен на других языках. Чтобы изменить язык ExifDataView, загрузите zip-файл на соответствующем языке, извлеките exifdataview_lng.ini, и поместите его в ту же папку, в которой вы установили утилиту ExifDataView. |
DataViews - ADO.NET | Документы Microsoft
- 2 минуты на чтение
В этой статье
DataView позволяет создавать различные представления данных, хранящихся в DataTable, - возможность, которая часто используется в приложениях связывания данных. Используя DataView , вы можете отображать данные в таблице с разными порядками сортировки, и вы можете фильтровать данные по состоянию строки или на основе выражения фильтра.
DataView обеспечивает динамическое представление данных в базовом DataTable : содержимое, порядок и членство отражают изменения по мере их возникновения. Это поведение отличается от метода Select для DataTable , который возвращает массив DataRow из таблицы на основе определенного фильтра и / или порядка сортировки: это содержимое отражает изменения в базовой таблице, но его членство и порядок остаются статическими. . Динамические возможности DataView делают его идеальным для приложений привязки данных.
DataView предоставляет вам динамическое представление единого набора данных, во многом напоминающее представление базы данных, к которому вы можете применять различные критерии сортировки и фильтрации. Однако, в отличие от представления базы данных, DataView не может рассматриваться как таблица и не может предоставлять представление объединенных таблиц. Вы также не можете исключить столбцы, которые существуют в исходной таблице, или добавить столбцы, которые не существуют в исходной таблице, например, вычислительные столбцы.
Вы можете использовать DataViewManager для управления настройками просмотра для всех таблиц в DataSet . DataViewManager предоставляет вам удобный способ управления настройками представления по умолчанию для каждой таблицы. При привязке элемента управления к нескольким таблицам DataSet привязка к DataViewManager является идеальным выбором.
В этом разделе
Создание DataView Описывает, как создать DataView для DataTable .
Сортировка и фильтрация данных Описывает, как настроить свойства DataView для возврата подмножеств строк данных, удовлетворяющих определенным критериям фильтрации, или для возврата данных в определенном порядке сортировки.
DataRows и DataRowViews Описывает, как получить доступ к данным, предоставляемым DataView .
Поиск строк Описывает, как найти конкретную строку в DataView .
ChildViews и отношения Описывает, как создавать представления данных из родительско-дочерних отношений с помощью DataView .
Изменение представлений данных Описывает, как изменить данные в базовом DataTable через DataView , включая включение или отключение обновлений.
Обработка событий DataView Описывает, как использовать событие ListChanged для получения уведомления при обновлении содержимого или порядка DataView .
Управление представлениями данных Описывает, как использовать DataViewManager для управления настройками DataView для каждой таблицы в DataSet .
Веб-приложения ASP.NET Предоставляет обзоры и подробные пошаговые процедуры для создания приложений ASP.NET, веб-форм и веб-служб.
Приложения для Windows Предоставляет подробную информацию о работе с Windows Forms и консольными приложениями.
DataSets, DataTables и DataViews Описывает объект DataSet и способы его использования для управления данными приложения.
Таблицы данных Описывает объект DataTable и то, как вы можете использовать его для управления данными приложения отдельно или как часть DataSet .
ADO.NET Описывает архитектуру и компоненты ADO.NET, а также способы использования ADO.NET для доступа к существующим источникам данных и управления данными приложений.
См. Также
Data View - Studio Pro 9 Руководство
1 Введение
Просмотр данных - это отправная точка для отображения содержимого ровно одного объекта. Например, если вы хотите показать подробную информацию об отдельном элементе программы, вы можете использовать для этого представление данных:
В более сложном примере представление данных может содержать информацию о клиенте и контейнеры вкладок по конкретной теме (например, адреса и информацию о платеже) с вложенными сетками данных для связанных объектов:
Нижний колонтитул окна просмотра данных - это раздел внизу окна просмотра данных, который часто содержит кнопки для подтверждения или отмены изменений.
3 Недвижимости
Пример свойств представления данных представлен на изображении ниже:
Свойства представления данных состоят из следующих разделов:
3.1 Общая часть
Дополнительные сведения о свойствах в этом разделе см. В разделе «Общие» в разделе «Общие свойства » в редакторе страниц .
3.2 Источник данных Раздел
Источник данных определяет, какой объект будет отображаться в окне просмотра данных.Для получения дополнительной информации об источниках данных см. Источники данных.
Просмотр данных поддерживает следующие типы источников данных: контекст, микропоток, нанопоток и прослушивание виджета.
| Тип источника данных | Описание |
|---|---|
| Контекст | Источник данных, определяющий, что откуда бы вы ни открывали страницу, вы передаете выбранный объект. Например, когда вы добавляете действие Show Page в микропоток, вы выбираете страницу и объект для передачи.(Дополнительные сведения о микропотоках см. В разделе «Микропотоки».) Это означает, что при открытии страницы в микропотоке объект этого типа предоставляется и будет отображаться в окне просмотра данных на странице. Если представление данных вложено в другой виджет данных, можно указать путь к сущности, который начинается в объекте контекста и следует одной или нескольким ассоциациям. Дополнительные сведения об источнике контекста см. В разделе Источник контекста. |
| Микропоток | Источник данных, который запускает выбранный микропоток и отображает возвращаемое значение.Для получения дополнительной информации об источнике микропотока см. Источник микропотока. |
| Nanoflow | Источник данных, который запускает выбранный нанопоток и отображает возвращаемое значение. Для получения дополнительной информации об источнике нанопотока см. Источник нанопотока. |
| Прослушать виджет | Источник данных, позволяющий в представлении данных отображать подробную информацию об объекте в виджете списка на той же странице. Для получения дополнительной информации о прослушивании источника виджета см. Прослушивание источника виджета. |
3.3 Раздел свойств проекта
Свойства дизайна позволяют изменять интервал и выравнивание виджета и при необходимости скрывать его на телефоне, планшете или рабочем столе. Свойства дизайна могут различаться в зависимости от типа виджета. Например, для текстового виджета вы можете изменить его толщину шрифта, цвет, выравнивание и регистр букв.
3.4 Редактируемость Раздел
3.4.1 Редактируемый
Свойство editable указывает, можно ли редактировать представление данных в целом.
| Значение | Описание |
|---|---|
| Есть | Просмотр данных доступен для редактирования: каждый виджет определяется как доступный для редактирования на основе его собственного редактируемого свойства (значение по умолчанию для представлений данных вне фрагмента). |
| Унаследовано от вызова сниппета | Установите значение Да или Нет содержащим контейнером данных вызова сниппета (значение по умолчанию для представлений данных внутри сниппета). |
| № | Просмотр данных не доступен для редактирования: ни один виджет внутри окна просмотра данных не доступен для редактирования. |
3.4.2 Стиль только для чтения
Это свойство определяет, как отображаются виджеты ввода, если они доступны только для чтения.
| Значение | Описание |
|---|---|
| Control (по умолчанию) | Виджет отображается, но отключен, поэтому значение нельзя изменить. |
| Текст | Виджет заменяется текстовым представлением значения. |
Стиль только для чтения не поддерживается на собственных мобильных страницах.
3.5 Общие положения
3.5.1 Ориентация формы
С помощью этого свойства вы можете указать положение меток виджета ввода внутри окна просмотра данных. Если ориентация горизонтальная, метки будут размещены рядом с виджетами ввода. Если ориентация вертикальная, метки будут размещены над виджетами ввода.
Обратите внимание, что группы форм являются адаптивными, и надписи могут размещаться над виджетами ввода, даже если ориентация установлена горизонтально, в зависимости от размера области просмотра.Также обратите внимание, что представление данных с вертикальной ориентацией не может быть вложено в представление данных с горизонтальной ориентацией. В этом случае группы форм будут отображаться горизонтально, независимо от значения свойства ориентации.
По умолчанию: По горизонтали
3.5.2. Ширина этикетки (вес)
Если ориентация формы установлена на горизонтальную, это свойство можно использовать для указания ширины меток виджета ввода внутри окна просмотра данных. Ширина указывается с использованием веса столбцов из системы сеток Bootstrap.Для получения дополнительных сведений см. Сетка макета.
По умолчанию: 3
С помощью этого свойства вы можете указать, хотите ли вы, чтобы нижний колонтитул представления данных был видимым. Нижний колонтитул вложенных представлений данных всегда невидим, независимо от значения этого свойства.
По умолчанию: Истинно
3.5.4 Сообщение о пустом объекте
Если это сообщение указано, представление данных, которое не получает исходных данных, покажет это сообщение вместо своего содержимого.В противном случае в окне просмотра данных будет отображаться статическое содержимое и отключенные виджеты ввода. Это свойство является переводимым текстом. Дополнительные сведения см. В разделе «Меню языка».
Есть несколько способов, которыми представление данных может закончиться без исходных данных. Например, представление данных с источником данных Listen to widget останется пустым до тех пор, пока объект не будет выбран в целевой сетке. В этом сценарии Пустое сообщение объекта может использоваться, чтобы помочь пользователю выбрать элемент из сетки.
По умолчанию: пусто
3.6 Раздел видимости
Видимость определяет, отображается ли виджет для конечного пользователя как часть страницы.
Для получения дополнительных сведений о свойствах этого раздела см. Раздел «Видимость» в разделе «Свойства , Общие в редакторе страниц ».
4 Выполнение определенных действий
Чтобы выполнить действия с представлением данных, выберите его на странице и щелкните его правой кнопкой мыши. Откроется список возможных действий.Хотя некоторые действия из этого списка, такие как Выбрать источник данных , Изменить условие для видимого , являются быстрым способом установки свойств, следующие действия являются конкретными действиями, которые вы можете выполнить:
- Перейти к объекту - открывает модель предметной области и выделяет объект, который используется в качестве источника данных.