Как сделать таблицу в Word: пошаговая инструкция для чайников
Здравствуйте, друзья.
Набрать текст в редакторе под силу большинству из нас, даже если мы только осваиваем работу за компьютером. А вот изменить его, дополнить изображениями и таблицами, сделать отступы, поля и добавить нумерацию страниц уже сложнее. Для этого надо получить специальные знания, иначе можно долго искать нужную функцию и вникать в ее работу.
Я давно подружилась с программами Microsoft Office и хочу помочь вам в их освоении. Сегодня разберемся, как сделать таблицу в Word и Google Документе, как добавить и удалить строки и столбцы, поменять их ширину, выровнять данные в ячейках и произвести другие действия.
Все способы с пошаговыми инструкциями
Откройте программу и посмотрите на основное меню вверху экрана. Среди перечня опций нам нужна вкладка “Вставка”.
Я использую Office 365, который по интерфейсу не отличается от пакета 2016 года. Если у вас стоит более ранняя версия, не расстраивайтесь. Да, меню будет выглядеть немного иначе, но ваша задача – найти вкладку “Вставка” или “Вставить”.
Если у вас стоит более ранняя версия, не расстраивайтесь. Да, меню будет выглядеть немного иначе, но ваша задача – найти вкладку “Вставка” или “Вставить”.
Затем нажмите на слово “Таблица”. Перед вами появится выпадающий список, при помощи которого можно:
- в 1 клик начертить пустую таблицу максимального размера 10 × 8 ячеек, затем ее можно увеличить, об этом я расскажу немного позже;
- создать нужное количество строк и ячеек;
- нарисовать объект любого формата по своему желанию;
- преобразовать уже набранный текст в табличный формат;
- открыть прямо в Word редактор Excel и работать в нем, если это привычно и удобно для вас;
- воспользоваться готовыми шаблонами, предусмотренными программным продуктом, или создать свои.
Сейчас мы рассмотрим каждый из этих способов отдельно.
Быстрое создание простой таблицы
Самый легкий способ – это отметить в выпадающем меню поле, в котором квадратики по вертикали означают количество строк, а по горизонтали – столбцов.
В дальнейшем ее можно увеличить, уменьшить и изменить размеры строк и столбцов. Как это сделать, смотрите в разделе о редактировании.
Второй простой способ
Снова идем в меню и выбираем “Вставить таблицу…”.
В выпавшем окошке можно выбрать любое количество строк и столбцов, а также настроить ширину ячеек:
- фиксированную;
- по содержимому, чтобы размеры подстраивались под самый длинный текст;
- по ширине окна, тогда таблица будет занимать всю область: от левого до правого края листа.
Если вы поставите галочку внизу, то в следующий раз редактор предложит создать точно такой же объект, что удобно, если вам нужно несколько одинаковых массивов.
Рисуем таблицу
На мой взгляд, это самый трудный способ, его стоит использовать в редких случаях, когда нужно составить сложную таблицу необычной конфигурации или когда у вас уйма времени, и хочется поэкспериментировать.
Выбираем в меню соответствующий пункт.
Теперь ведем карандашом и рисуем рамку, а затем ячейки. На мой взгляд, тут удобно “чертить” вертикальные, горизонтальные и даже диагональные линии и создавать свой макет, но вы можете творить, как вам захочется.
В процессе рисования в основном меню откроется вкладка “Макет”. Опции на этой панели позволяют быстро добавлять одинаковые ячейки, объединять их или разделять. Подробнее обо всех возможностях редактирования любой таблицы в Microsoft Word я расскажу чуть позже.
Преобразование текста в таблицу
Эта функция может стать довольно удобным инструментом для тех, кто привык быстро набирать текст и не хочет тратить время на заполнение полей. Также вы можете его использовать, когда переносите данные с распечатанного листа и книги в компьютер или просто не любите таблицы, но делать их приходится.
Чтобы все получилось, содержимое каждой ячейки пишите по одному из принципов:
- с новой строки;
- через точку с запятой;
- со знаком табуляции, то есть нажимая клавишу Tab на клавиатуре;
- через любой выбранный вами символ.

Главное, не запутаться и по порядку сверху вниз и слева направо, то есть по строчкам, выписать все данные с использованием выбранного разделителя. Я чаще всего выписываю содержимое новой графы, нажимая Enter, так проще не запутаться и проконтролировать количество данных.
Затем выделяем набранный текст, идем в меню и выбираем пункт “Преобразовать в таблицу…”.
В появившемся окне выбираем нужное количество столбцов, строки программа установит сама. Затем говорим редактору, как подобрать оптимальную ширину ячеек, и какой символ отделяет их содержимое в конкретном случае. Нажимаем кнопку “ОК” и получаем готовую и уже заполненную форму.
Создаем таблицу Excel в текстовом документе
Чем интересен Excel? В нем есть формулы, возможность фильтровать и упорядочивать информацию, делать простые и сложные расчеты, рисовать графики, чего нет в Word. Поэтому если нам нужно что-то посчитать и внести данные в текстовый документ, мы открываем меню и выбирайте соответствующую опцию.
Перед нами появляется объект из 10 строк и 7 столбцов и меню редактора таблиц от компании Microsoft. Работать с ним так же легко и приятно, как с обычным массивом в Excel.
Когда вы сделали нужное редактирование данных, можете продолжать работу над документом, переключив курсов за пределы таблицы. Чтобы вернуться и изменить содержимое, нужно 2 раза нажать на объект левой кнопкой мыши.
Использование заготовок
В Word есть шаблоны, которые могут вам пригодиться. Чтобы воспользоваться ими, в меню выберите строку “Экспресс-таблицы”. Перед вами появится список заготовок, можете взять подходящую и внести свою информацию.
Но главная фишка в том, что вы можете добавить уже готовую таблицу в заготовки, чтобы использовать ее в следующий раз. Это очень удобно, когда нужно создавать однотипные объекты в разных документах.
Чтобы применить функцию, вставьте таблицу, заполните заголовки или всю информацию в зависимости от ваших целей, затем наведите курсор на пункт меню “Экспресс-таблицы” и кликните левой кнопкой мыши по самой нижней строке с рисунком дискеты слева.
Редактирование
После создания таблицы ее в любое время можно заполнить и изменить. Чтобы сделать это, кликните по ней левой кнопкой мыши и в основном меню программы зайдите в панель “Макет”.
Изменяем свойства таблицы
В самом левом углу мы видим 3 пункта:
- Выделить,
- Отобразить сетку,
- Свойства.
При помощи первой опции можно создать выделение нужной области для дальнейшего редактирования. Это может быть 1 ячейка, столбец, строка, в которой в данный момент находится курсор мыши либо вся таблица.
Сетка нужна, если вы убрали границы между элементами, а точнее, скрыли их. Вот так выглядит табличка, в которой нет линий между столбцами.
А вот так она будет отображаться с применением сетки.
Видите, появились пунктирные разделители? Теперь проще разобрать структуру данного массива.
В свойствах вы можете:
- изменить ширину таблицы, строк, столбцов и ячеек;
- настроить положение объекта на листе;
- разрешить или запретить перенос на другую страницу;
- выровнять текст по центру, верхнему или нижнему краю;
- добавить альтернативный текст, чтобы графы не были пустыми.

Удаление и добавление элементов
Это одна из самых нужных функций при работе с массивом данных. Поставьте курсор мыши на ячейку и нажмите на кнопку “Удалить”.
В выпавшем списке выберите, что именно нужно убрать:
- одну графу,
- весь столбец,
- строку,
- таблицу.
Когда вы убираете одну ячейку, то программа предлагает варианты, как это сделать:
- сдвигая данные влево или вверх;
- удаляя целиком строку или столбец.
Если вы применяете первый вариант, то в выбранной строке или столбце станет на 1 графу меньше, чем в остальных. Вот как это выглядит на практике.
Добавить одну ячейку не получится, наращивание массива происходит строками снизу или сверху и столбцами слева или справа от графы, в которой расположен курсор.
Примечание: Чтобы добавить несколько строк, выделите столько же ячеек по горизонтали или вертикали.
Другие настройки
Также вы можете:
- объединить или разделить выделенные ячейки или отделить одну часть таблицы от другой;
- настроить ширину и высоту строк и столбцов;
- выровнять текст по одному из краев ячейки или по центру;
- задать поля;
- применить сортировку или математические формулы к содержимому.

Все эти настройки перед вами, испытайте их, чтобы научиться быстро редактировать нужные параметры.
Также вы можете менять месторасположение таблицы. Для этого наведите на нее мышку и тяните за крестик в левом верхнем углу. Другой способ: выделите объект, нажмите комбинацию клавиш “Ctrl + X”, переместите курсор в нужное место и воспользуйтесь кнопками “Ctrl + V”.
Изменение внешнего вида
Вы можете не только редактировать элементы и таблицу целиком, но и изменять их внешний вид. Для этого кликните по объекту и перейдите в пункт меню “Конструктор таблиц”.
Тут вы можете:
- использовать готовые шаблоны, которые видны на скриншоте выше;
- раскрашивать ячейки в любой цвет;
- изменять внешний вид границ, добавлять и убирать их.
Сделайте свой документ еще более красивым и удобным для чтения при помощи этих функций.
Таблицы в Google Документах
А вы знаете, что есть альтернатива текстовому редактору Microsoft Word? Это Google Документы, которые хранятся в интернете. Создавать их может любой человек, у кого есть аккаунт в Google.
Создавать их может любой человек, у кого есть аккаунт в Google.
Главное удобство: работать над одним документом можно с разных компьютеров и давать доступ другим пользователям для просмотра и редактирования данных. В последнее время я пользуюсь этим редактором чаще, чем Word. Попробуйте, может, и вам понравится.
Здесь есть большинство самых востребованных функций. Чтобы вставить таблицу, нужно нажать на слово “Вставка” в верхней панели, выбрать соответствующее действие из списка и выделить желаемое количество строк и столбцов.
Заключение
Мы разобрали несколько способов сделать таблицу в Word, узнали, как заполнить ее, отредактировать и оформить. Я надеюсь, что эта инструкция помогла вам, а если возникли трудности, то напишите об этом в комментариях. Я постараюсь помочь.
Сохраняйте статью в закладки, ведь с первого раза бывает сложно запомнить последовательность действий. Подписывайтесь на новые материалы iklife.ru, вместе с нами вы легко освоите работу программ, сервисов и сайтов и станете уверенным пользователем ПК, телефона и интернета.
Всего доброго. До новых полезных встреч, друзья.
Шпаргалка по работе с таблицами
1. Как задать таблице класс или идентификатор
Если на одной странице или на сайте присутствует несколько таблиц и для них требуется установить разное стилевое оформление, то для таких таблиц добавляется атрибут class или id с соответствующим значением, например,
<table>
<tr>
<th>Comedy</th>
<th>Adventure</th>
<th>Action</th>
</tr>
<tr>
<td>Scary Movie</td>
<td>Indiana Jones</td>
<td>The Punisher</td>
</tr>
<tr>
<td>Epic Movie</td>
<td>Star Wars</td>
<td>Bad Boys</td>
</tr>
</table>
<table>
<tr>
<th>Company</th>
<th>Q1</th>
<th>Q2</th>
<th>Q3</th>
</tr>
<tr>
<td>Microsoft</td>
<td>20. 3</td>
<td>30.5</td>
<td>23.5</td>
</tr>
<tr>
<td>Google</td>
<td>50.2</td>
<td>40.63</td>
<td>45.23</td>
</tr>
</table>
3</td>
<td>30.5</td>
<td>23.5</td>
</tr>
<tr>
<td>Google</td>
<td>50.2</td>
<td>40.63</td>
<td>45.23</td>
</tr>
</table>При этом class="list" можно будет использовать для оформления других таблиц (элементов), а id="company" — только для одной таблицы.
2. Как добавить ссылки в таблицу
Ячейки таблицы могут содержать практически любые элементы. Чтобы вставить ссылку в ячейку, нужно добавить в нее элемент <a> с текстом ссылки, например,
<table>
<tr>
<th>Comedy</th>
<th>Adventure</th>
<th>Action</th>
</tr>
<tr>
<td><a href="https://ru.wikipedia.org/wiki/Очень_страшное_кино">Scary Movie</a></td>
<td>Indiana Jones</td>
<td>The Punisher</td>
</tr>
<tr>
<td>Epic Movie</td>
<td>Star Wars</td>
<td>Bad Boys</td>
</tr>
</table>Стилизовать такие ссылки можно при помощи определения table a {}, или же задав класс непосредственно для ссылки.
3. Как создать ссылки на ячейки таблицы
Ссылка на ячейку таблицы создается при помощи якоря. Для этого нужной ячейке добавляется атрибут id со значением, например,
<td>содержимое ячейки</td>.
Чтобы обеспечить переход со ссылки на эту ячейку, задаём ей соответствующее значение пути
<a href="#значение_идентификатора_ячейки">текст ссылки</a>.
Если переход осуществляется с одной страницы сайта на другую, якорь добавляется после адреса страницы, например,
<a href="https://html5book.ru/css-shrifty/#color">текст ссылки</a>.
Для наглядности результат перехода можно выделить, например, сменить цвет фона ячейки, цвет текста ячейки, добавить подчеркивание и т.д.
td:target {background: salmon;}
td:target {color: salmon;}
td:target {text-decoration: underline;}Пример
Таблица составлена на основе рейтинга зрителей. Перейдя по этой ссылке, вы узнаете какой фильм мой самый любимый.
| Фантастика | Комедия | Приключения |
|---|---|---|
| Марсианин | Самый лучший день | Миссия невыполнима: Племя изгоев |
| Мстители: Эра Альтрона | Пиксели | Агенты А.Н.К.Л. |
| Голодные игры: Сойка-пересмешница | Барашек Шон | Последние рыцари |
4. Одинаковая ширина колонок таблицы
По умолчанию ширина таблицы определяется содержимым ее ячеек. Управлять шириной столбцов (ячеек) можно следующими способами:
1) Если для таблицы задана ширина, то table {table-layout: fixed;} сделает все ячейки одинаковой ширины, исходя из ширины самой длинной ячейки.
2) Если для таблицы задана ширина table {width: 100%;}, и ширина ячеек вычисляется в %, например, td {width: 25%;}, то ширина всех ячеек будет равной.
3) Задав фиксированную ширину с помощью единиц длины, например, th {width: 200px}.
При этом не забывайте, что к ширине таблицы будет добавлена ширина границы ячеек и таблицы и внутренние отступы ячеек padding (если не установлено свойство {box-sizing:border-box}).
5. Оформление заголовка таблицы
Заголовок таблицы добавляется с помощью тега
<caption>Заголовок_таблицы</caption>, который вставляется сразу после открывающего тега <table>. По умолчанию сам заголовок расположен перед таблицей, а текст заголовка выравнен по центру.
Управлять положением заголовка можно свойством caption-side, например, caption {caption-side: bottom} поместит заголовок после таблицы.
По сути заголовок является ячейкой таблицы, поэтому для него можно задавать те же свойства, что и для ячеек таблицы, т.е.
caption {
padding: 7px;
background: silver;
font-style: italic;
text-align: right;
}6. Создание вложенных таблиц
Чтобы вложить одну таблицу в другую, нужно поместить код вложенной таблицы в выбранную ячейку основной таблицы, например:
<table>
<tr>
<th>ячейка заголовка таблицы</th>
<th>ячейка заголовка таблицы</th>
</tr>
<tr>
<td>ячейка таблицы</td>
<td>
<table>
<tr>
<th>ячейка заголовка вложенной таблицы</th>
</tr>
<tr>
<td>ячейка вложенной таблицы</td>
</tr>
</table>
</td>
</tr>
</table>| ячейка заголовка таблицы | ячейка заголовка таблицы | ||
|---|---|---|---|
| ячейка таблицы |
|
Вложенные таблицы могут содержать любое количество строк и ячеек. Для них можно устанавливать любые свойства, отличные от значений основной таблицы, размещать в ячейках изображения, а также другие таблицы.
Для них можно устанавливать любые свойства, отличные от значений основной таблицы, размещать в ячейках изображения, а также другие таблицы.
Связи между таблицами в Power BI
Что ж, давайте посмотрим, что будет в этом случае. Предположим, что у нас еще есть таблица с данными по продажам для каждого из магазинов. Таблица содержит следующие столбцы:
- ID магазина;
- номер заказа;
- дата заказа;
- количество заказанного товара;
- комментарий к платежу;
- артикул.
Чтобы изучить, как работают связи, я рекомендую вам отключить (на время!) автоопределение связей в Power BI. Делается это следующим образом (я обычно использую англоязычную версию, поэтому скрины все будут на английском):
Необходимо снять галки для отключения автоопределения связей между таблицами.
Если мы загрузим обе таблицы, то увидим такую картину:
Между таблицами нет никаких связей. Теперь, если мы захотим отфильтровать и узнать общее количество книг, проданных в том или ином магазине, то сможем сделать это с помощью визуализации:
Данный отчет похож на предыдущий, и если теперь раскрасить нашу таблицу с учетом фильтра, то получим:
Построим визуализацию по продажам в каждом из штатов:
Наблюдаем странную картину: в каждом штате продано по 493 книги. Кажется, что-то пошло не так. Фильтр не работает так, как должен. Произошло это потому, что в таблице по продажам нет информации по штату, но есть ID магазина.
При этом в самой таблице по магазинам нет информации о проданных товарах и их количестве. Но чтобы составить полноценный отчет, нам нужны обе таблицы.
Общим полем для обеих таблиц является поле stor_id, по которому мы и можем сопоставить информацию о наших филиалах и продажах в каждом из них.
Общее поле stor_idДавайте рассмотрим пример:
Магазин Barnum’s (ID 7066) находится в городе Tustin, штат КалифорнияВ другой таблице мы видим количество продаж в магазине с ID, равным 7066.
Таким образом получается, что мы можем связать обе таблицы с помощью столбца stor_id.
Нормализация баз данных – что это такое и зачем нормализовать базу данных? | Info-Comp.ru
Приветствую всех посетителей сайта Info-Comp.ru! Сегодня мы с Вами поговорим о нормализации базы данных, узнаем, что это такое, какие нормальные формы базы данных существуют и зачем вообще проводить нормализацию базы данных.
Постоянные посетители данного сайта знают, что я здесь публикую достаточно много различных материалов, связанных с языком SQL и системами управления базами данных, однако статей, связанных с теорией баз данных, на текущий момент, к сожалению, нет, поэтому я решил это исправить, и начать цикл статей, посвященных теории баз данных.
Начну я с нормализации баз данных. В этом материале мы поговорим в целом о процессе нормализации, узнаем, зачем проводить нормализацию базы данных, что такое нормальная форма базы данных, а также какие нормальные формы существуют. В следующих материалах я подробно и с примерами расскажу про каждую нормальную форму.
В следующих материалах я подробно и с примерами расскажу про каждую нормальную форму.
Реляционная база данных
В целом под базой данных можно понимать любой набор информации, которую можно найти в этой базе данных и воспользоваться ей, однако если говорить в контексте SQL, то речь будет идти, конечно, о реляционных базах данных, а что же это такое?
Реляционная база данных – это упорядоченная информация, связанная между собой определёнными отношениями.
Логически такая база данных представлена в виде таблиц, в которых и лежит вся эта информация.
Примечание! Если Вас интересует язык SQL, рекомендую пройти мой онлайн-курс по основам SQL, который ориентирован на изучение SQL как стандарта, таким образом, Вы сможете работать в любой системе управления базами данных. Курс включает много практики: онлайн-тестирование, задания и многое другое.
Нормализация баз данных
В реляционных базах данных есть такое понятия, как «Нормализация».
Нормализация – это процесс удаления избыточных данных.
Также нормализацию можно рассматривать и с позиции проектирования базы данных, в таком случае мы можем сформулировать определение нормализации следующим образом.
Нормализация – это метод проектирования базы данных, который позволяет привести базу данных к минимальной избыточности.
Избыточность устраняется, как правило, за счёт декомпозиции отношений (таблиц), т.е. разбиения одной таблицы на несколько.
Зачем нормализовать базу данных?
У Вас может возникнуть вопрос – а зачем вообще нормализовать базу данных и бороться с этой избыточностью?
Дело в том, что избыточность данных создает предпосылки для появления различных аномалий, снижает производительность, и делает управление данными не гибким и не очень удобным. Отсюда можно сделать вывод, что нормализация нужна для:
- Устранения аномалий
- Повышения производительности
- Повышения удобства управления данными
Теперь давайте поговорим о самой избыточности данных, что же это такое.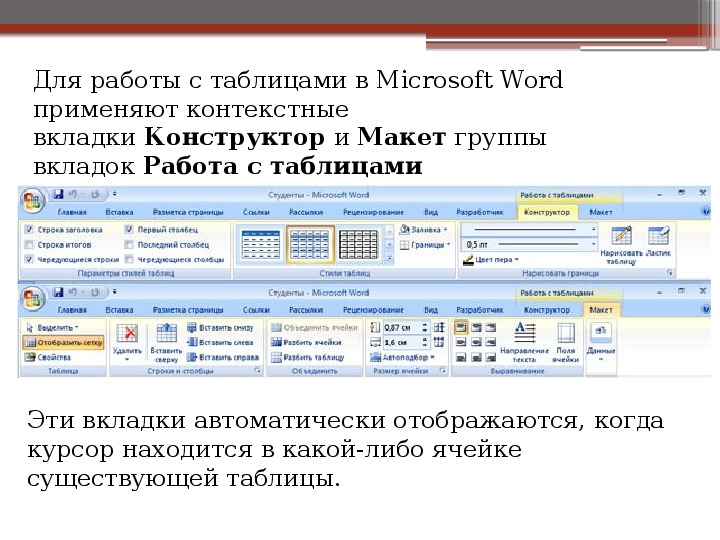
Избыточность данных – это когда одни и те же данные хранятся в базе в нескольких местах, именно это и приводит к аномалиям.
Так как в этом случае необходимо добавлять, изменять или удалять одни и те же данные в нескольких местах. Например, если не выполнить операцию в каком-нибудь одном месте, то возникает ситуация, когда одни данные не соответствуют вроде как точно таким же данным в другом месте.
Давайте рассмотрим пример. Допустим, у нас есть следующая таблица, она хранит информацию о предметах мебели, в частности наименование предмета и материал, из которого изготовлен этот предмет.
| Идентификатор предмета | Наименование предмета | Материал |
| 1 | Стул | Металл |
| 2 | Стол | Массив дерева |
| 3 | Кровать | ЛДСП |
| 4 | Шкаф | Массив дерева |
| 5 | Комод | ЛДСП |
А теперь допустим, что у нас возникла необходимость подкорректировать название материала, вместо «Массив дерева» нужно написать «Натуральное дерево», и чтобы это сделать нам необходимо внести изменения сразу в несколько строк, так как предметов, изготовленных из массива дерева, несколько, а именно 2: стол и шкаф.
А теперь представьте, что по каким-то причинам мы внесли изменения только в одну строку, в итоге в нашей таблице будет и «Массив дерева», и «Натуральное дерево».
| Идентификатор предмета | Наименование предмета | Материал |
| 1 | Стул | Металл |
| 2 | Стол | Натуральное дерево |
| 3 | Кровать | ЛДСП |
| 4 | Шкаф | Массив дерева |
| 5 | Комод | ЛДСП |
Какое из этих названий будет правильным? А если представить, что мы можем внести еще какое-то новое значение при добавлении новых записей, например, просто «Дерево».
В этом случае в нашей таблице в скором времени будет и «Массив дерева», и «Натуральное дерево», и просто «Дерево», и вообще, что угодно, ведь это просто текст.
| Идентификатор предмета | Наименование предмета | Материал |
| 1 | Стул | Металл |
| 2 | Стол | Натуральное дерево |
| 3 | Кровать | ЛДСП |
| 4 | Шкаф | Массив дерева |
| 5 | Комод | ЛДСП |
| 6 | Тумба | Дерево |
Однако по своей сути это один и тот же материал, мы просто решили или подкорректировать его название, или ошиблись при добавлении новой записи. Это и есть аномалия, когда одни данные в одном месте не соответствуют вроде как точно таким же данным в другом месте. Это всего лишь один вид аномалии, однако в процессе добавления, изменения и удаления данных может возникать много других противоречивых ситуаций, т.е. аномалий.
При этом, обязательно стоит отметить, что в нашей таблице всего 5 записей, а теперь представьте, что их миллион!
Заметка! Как создать таблицу в PostgreSQL с помощью pgAdmin 4.
Именно поэтому мы должны устранять избыточность данных в базе, т.е. проводить так называемую нормализацию базы данных.
В данном конкретном случае мы должны название материала, из которого изготовлены предметы мебели, вынести в отдельную таблицу, а в таблице с предметами сделать всего лишь ссылку на нужный материал, тем самым, соотнеся эту ссылку с исходной записью, мы будем понимать, из какого материала сделан тот или иной предмет.
Предметы мебели.
| Идентификатор предмета | Наименование предмета | Идентификатор материала |
| 1 | Стул | 2 |
| 2 | Стол | 1 |
| 3 | Кровать | 3 |
| 4 | Шкаф | 1 |
| 5 | Комод | 3 |
Материалы, из которых изготовлены предметы мебели.
| Идентификатор материала | Материал |
| 1 | Массив дерева |
| 2 | Металл |
| 3 | ЛДСП |
В этом случае когда нам потребуется изменить название материала, мы будем вносить изменение только в одном месте, т.е. править только одну строку.
Таким образом, представляя материалы в виде отдельной сущности и создавая для нее отдельную таблицу, мы устраняем описанную выше аномалию.
Другими словами, каждая сущность должна храниться отдельно, а в случае необходимости использования этой сущности в другой таблице на нее делается всего лишь ссылка, т.е. выстраивается связь.
Нормальные формы базы данных
В целом процесс нормализации базы данных выглядит следующим образом: мы, следуя определённым правилам и соблюдая определенные требования, проектируем таблицы в базе данных.
При этом все эти правила и требования можно сгруппировать в несколько наборов, и если спроектировать базу данных с соблюдением всех правил и требований, которые включаются в тот или иной набор, то база данных будет находиться в определённом состоянии, т.е. форме, и такая форма называется нормальная форма базы данных.
Иными словами, следуя определённым правилам и соблюдая определенные требования мы приводим базу данных к определенной нормальной форме.
Нормальная форма базы данных – это набор правил и критериев, которым должна отвечать база данных.
Каждая следующая нормальная форма содержит более строгие правила и критерии, тем самым приводя базу данных к определённой нормальной форме мы устраняем определённый набор аномалий.
Отсюда можно сделать вывод, что чем выше нормальная форма, тем меньше аномалий в базе будет.
Процесс нормализации – это последовательный процесс приведения базы данных к эталонному виду, т.е. переход от одной нормальной формы к следующей.
Иными словами, процесс перехода от одной нормальной формы к следующей – это усовершенствование базы данных. Так как если база данных находится в какой-то определённой нормальной форме – это означает, что в базе данных отсутствует определенный вид аномалий.
Существует 5 основных нормальных форм базы данных:
- Первая нормальная форма (1NF)
- Вторая нормальная форма (2NF)
- Третья нормальная форма (3NF)
- Четвертая нормальная форма (4NF)
- Пятая нормальная форма (5NF)
Однако выделяют еще дополнительные нормальные формы:
- Ненормализованная форма или нулевая нормальная форма (UNF)
- Нормальная форма Бойса-Кодда (BCNF)
- Доменно-ключевая нормальная форма (DKNF)
- Шестая нормальная форма (6NF)
Заметка! Установка и настройка PostgreSQL на Windows 10.
Если объединить оба этих списка и упорядочить нормальные формы от менее нормализованной до самой нормализованной, т.е. начиная с формы, при которой база данных по своей сути не является нормализованной, и заканчивая самой строгой нормальной формой, то мы получим следующий перечень:
- Ненормализованная форма или нулевая нормальная форма (UNF)
- Первая нормальная форма (1NF)
- Вторая нормальная форма (2NF)
- Третья нормальная форма (3NF)
- Нормальная форма Бойса-Кодда (BCNF)
- Четвертая нормальная форма (4NF)
- Пятая нормальная форма (5NF)
- Доменно-ключевая нормальная форма (DKNF)
- Шестая нормальная форма (6NF)
База данных считается нормализованной, если она находится как минимум в третьей нормальной форме (3NF).
В реальном мире нормализация до третьей нормальной формы (3NF) является обычной, стандартной практикой, так как 3NF устраняет достаточное количество аномалий, при этом производительность базы данных, а также удобство ее использования не снижается, что нельзя сказать о всех последующих формах.
Ситуации, при которых требуется нормализовать базу данных до четвертой нормальной формы (4NF), в реальном мире встречаются достаточно редко.
Заметка! Если Вас интересует язык SQL, рекомендую почитать мою книгу «SQL код», которая ориентирована на изучение SQL как стандарта, после прочтения книги Вы сможете писать SQL запросы в любой системе управления базами данных.
Если говорить о всех последующих нормальных формах (5NF, DKNF, 6NF), то в реальной жизни трудно даже представить ситуации, при которых потребуется нормализовать базу данных до этих форм.
Иными словами, 5NF, DKNF, 6NF – это в большей степени теоретические нормальные формы, немного отстраненные от реального мира.
Стоит отметить, что приведение базы данных к какой-то конкретной нормальной форме, обязательно требует, чтобы эта база данных уже находилась в предыдущей нормальной форме. Другими словами, если Вы хотите нормализовать базу данных до третьей нормальной формы, то база уже должна находиться во второй нормальной форме, т.е. нельзя нормализовать базу данных до третьей формы, если она еще не нормализована до второй.
Описание нормальных форм базы данных
В следующих статьях представлено подробное описание каждой нормальной формы и приведены примеры.
- Ненормализованная форма или нулевая нормальная форма (UNF)
- Первая нормальная форма (1NF)
- Вторая нормальная форма (2NF)
- Третья нормальная форма (3NF)
- Нормальная форма Бойса-Кодда (BCNF)
- Четвертая нормальная форма (4NF)
- Пятая нормальная форма (5NF)
- Доменно-ключевая нормальная форма (DKNF)
- Шестая нормальная форма (6NF)
Опрос. Какой операционной системой Вы пользуетесь?
На сегодня это все, надеюсь, материал был Вам полезен и интересен, пока!
Нравится31Не нравитсяЕсть ли смысл в таблице 12 умножений? —Блог Вольфрама
Мое правительство (я нахожусь в Великобритании) недавно заявило, что дети здесь должны выучить 12-кратную таблицу умножения к 9 годам. Я всегда считал, что причина, по которой я выучил 12-кратную таблицу умножения, — это деньги система, которая раньше была в Великобритании — 12 пенни в шиллинге. Поскольку это безумие закончилось десятичной системой через год после моего рождения, к концу 1970-х, когда мне пришлось выучить свою 12-кратную таблицу умножения, это уже казалось анахроничной тратой времени.
То, что почти 40 лет спустя ему уделяется новое внимание, показалось мне настолько странным, что я подумал, что должен исследовать его немного более математически. Вот что я пришел к выводу.
Давайте начнем с основного вопроса: почему мы вообще используем таблицы умножения? (Это тот вопрос, который я часто задаю в своей работе на computerbasedmath.org!)
Я собираюсь заявить, что есть три основных причины:
1) Чтобы напрямую знать ответ на общие вопросы умножения.
2) Включить алгоритмы умножения.
3) Включить приближенное умножение.
Давайте посмотрим на них по очереди.
1) Эта причина важна. В повседневной жизни существует множество мелких проблем с умножением, и нет никаких сомнений в том, что знание ответа на них полезно. Но знать ЛЮБОЙ ответ на ЛЮБОЙ вопрос полезно. Что такого особенного в умножении 1 на 12? Зачем останавливаться на таблице умножения на 12 — почему бы не выучить таблицы умножения на 13, 14, 15, 16 и 17? Почему бы не выучить таблицу умножения на 39? По мере того, как номер таблицы увеличивается, объем обучения увеличивается как квадрат числа, в то время как общность решения проблемы, которая использует эту таблицу, уменьшается.«Знать» ответы на все возможные вопросы — сложная задача, не стоящая усилий. В конце концов, именно поэтому была изобретена математика, чтобы мы, , не знали ответы на все возможные вычисления, а вместо этого имели способ их вычислить, когда это необходимо. Мы должны где-то провести черту, а затем перейти к более алгоритмическому подходу. Вопрос в том, где.
2) Существует множество причудливых вычислительных алгоритмов, но большинство из нас изучает «умножение по столбцам», которое включает в себя работу с одной цифрой за раз, управляя порядком расположения номера и перенося переполнение в следующий столбец.Сам до сих пор иногда пользуюсь. По определению, ему нужны таблицы умножения на 0–9 (и неявное понимание таблицы умножения на 10), поскольку он принимает только одну цифру за раз, но может появиться любая отдельная цифра. Знание таблиц умножения на 11 и 12 совершенно не важно. Если бы это было единственным соображением, у нас был бы ясный аргумент в пользу того, где провести нашу черту — в таблице 10 умножений. Вы не можете обойтись меньшим, а большее бесполезно.
3) Но есть еще один полезный алгоритм, который приближает числа к нескольким значащим цифрам.Это может послужить основанием для проведения линии выше.
Возьмем для примера 7 203 x 6 892. Если я хочу знать это точно, я беру Mathematica (или, если это абсолютно необходимо, я беру карандаш и бумагу, чтобы применить умножение в столбцах). Но часто мне просто нужен приблизительный ответ, поэтому я мысленно конвертирую его в 7000 x 7000 = 7 x 7 x 1000 x 1000 = 4
00. Более формально я преобразовываю числа в ближайшее приближение к форме k x 10 n , где k ∈ {набор чисел, для которого я знаю таблицу умножения}.Затем я использую таблицу умножения для оставшихся значащих цифр и неявно использую таблицу умножения на 10, чтобы получить правильную величину. В этом случае реальный ответ: 7203 × 6892
49643076
Выдает ошибку 1,2% — достаточно для многих приложений. Если бы я знал свою таблицу умножения на 72, я мог бы сделать это 7 200 x 6900 = 49 680 000. Только 0,07% погрешности.
Итак, теперь наш вопрос «где провести черту?» Превращается в «насколько лучше типичный приблизительный расчет, если я знаю до 12-кратной таблицы, по сравнению со знанием только моей 10-кратной таблицы?» Давайте разбираться.Сначала мне нужно автоматизировать процесс приближения с использованием заданного ведущего номера.
И распространите это на поиск наилучшего приближения, если у нас есть выбор номеров отведений.
Например, если я знаю только таблицу умножения на 4, то наилучшее приближение для 18 345 будет 20 000.
Теперь наш приблизительный продукт — это просто произведение наилучших приближений каждого числа.
И относительную ошибку можно найти по разнице по сравнению с точным ответом.
Например, вычисление 549 x 999, когда вы знаете только 10-кратную таблицу умножения, даст вам ошибку чуть более 8%.
Теперь давайте возьмем «типичное вычисление» за вычисление с равномерно распределенными числами от 1 до 1 миллиона и примем за «типичную» ошибку среднее значение 100 000 таких вычислений.
Типичная ошибка, если вы знаете таблицу умножения до 10, составляет 9,4%.
Но если вы знаете таблицу умножения на 12, то это только 8.2%.
Вот ошибка в зависимости от того, сколько таблиц умножения вы выучили.
Интересно, что большинство улучшений происходит к тому времени, когда вы знаете свою 7-кратную таблицу умножения. Странная выпуклость в 10 объясняется тем, что возможность аппроксимации неявно зависит от знания вашей 10-кратной таблицы умножения (чтобы иметь возможность обрабатывать конечные нули).
Мы можем вычислить, насколько улучшена типичная ошибка для каждой дополнительной изученной таблицы.
Таким образом, относительная выгода постепенно снижается, циклически.
Но уменьшение погрешности с 9% до 8% имеет свою цену. Знание 10-кратной таблицы умножения требует запоминания 100 фактов (хорошо, 55, если вы предполагаете симметрию). Но знание таблицы умножения на 12 — это 144 факта. Улучшение ошибки с 9,3% результата до 8,1% — это относительное улучшение размера ошибки на 12%. Но для этого нужно запомнить на 40% больше информации. Это кажется проигрышным предложением.
Давайте посмотрим на относительное улучшение результата на каждый запомненный факт.
«Окупаемость усилий» очень быстро падает до 10-кратной таблицы, а затем почти не улучшается. Это кажется довольно убедительным аргументом в пользу того, чтобы прекратить механическое обучение на 10. В самом деле, если бы таблицы умножения использовались только для оценки, мы бы получили наилучшую отдачу от каждого усилия, просто глядя на порядки величины и используя только таблицы умножения на 1 и 10. !
Конечно, числа распределены неравномерно.Если вы занимаетесь производством яиц, вам, вероятно, придется много делать с шестерками и двенадцатью, как и в случае, если вы торгуете недесятичными британскими монетами! Подобные контекстуальные проблемы сложно определить количественно, но одна общая проблема — это закон Бенфорда, который встречается во многих реальных наборах данных. В нем говорится, что если вы посмотрите на реальные наборы данных, которые охватывают несколько порядков величины (например, население сообществ, или долги людей, или размеры файлов на вашем компьютере), то числа, скорее всего, начнутся с 1, чем с 2. , и, скорее всего, начнется с 2, чем с 3, и так далее.Я не знаю, изучал ли кто-нибудь распределение вторых цифр, поэтому предполагаю, что это единообразно. Итак, вот функция, которая генерирует «реальные» числа.
Теперь мы можем повторить наш анализ этих более реалистичных чисел.
Использование этих менее единообразных чисел приводит к снижению производительности (повышая вероятность того, что вам потребуются точные вычисления, а не приближения). Улучшения по-прежнему можно добиться, зная больше таблиц, и это можно рассматривать как аргумент в пользу обучения, превышающего 12, но не тогда, когда вы принимаете во внимание отдачу на каждый дополнительный изученный факт, что является еще более сильным аргументом в пользу остановки на 10.
Если вы действительно хотите заучить наизусть, есть лучшие способы потратить свои усилия, чем изучение таблиц умножения на 11 и 12. Изучение всех перестановок от 1 до 10 вместе с 15 и 25 дает лучший средний результат, чем от 1 до 12 (поскольку они более равномерно аппроксимируют числа с ведущей цифрой 1 или 2).
Или, как предложил мне Крис Карлсон, запомните почти обратные числа 100 (2 x 50 = 100, 3 x 33 = 99, 4 x 25 = 100, 5 x 20 = 100, 6 x 17 = 102 и т. Д.), так как их много. Я ожидал, что изучение квадратов и степеней двойки также, вероятно, более полезно, чем таблицы умножения на 11 и 12.
Без перспективы возврата к системе недесятичных денег, я могу только сделать вывод, что логика этого нового приоритета проста: «Если изучение таблиц до 10 — хорошо, то изучение их до 12 — лучше». А когда вы хотите поднять стандарты в математике, тогда кто может с этим спорить? Если только вы не примените математику к вопросу!
Загрузите этот пост в формате Computable Document Format (CDF).
Обзор типов данных MySQL
Резюме : В этом руководстве вы узнаете о типах данных MySQL и о том, как эффективно их использовать при проектировании баз данных в MySQL.
Таблица базы данных содержит несколько столбцов с определенными типами данных, такими как числовые или строковые. MySQL предоставляет больше типов данных, кроме числовых и строковых. Каждый тип данных в MySQL можно определить по следующим характеристикам:
- Вид значений, которые он представляет.
- Место, которое занимает, и являются ли значения фиксированной или переменной длиной.
- Значения типа данных могут быть индексированы или нет.
- Как MySQL сравнивает значения определенного типа данных.
Загрузить Обзор типов данных MySQL
Числовые типы данных MySQL
В MySQL вы можете найти все стандартные числовые типы SQL, включая точный числовой тип данных и приблизительные числовые типы данных, включая целое число, фиксированную точку и плавающую точку.Кроме того, MySQL также имеет тип данных BIT для хранения битовых значений. Числовые типы могут быть знаковыми или беззнаковыми, за исключением типа BIT .
В следующей таблице приведена сводка числовых типов в MySQL:
Числовые типы Описание TINYINT Очень маленькое целое число SMALL целое число MEDIUMINT Целое число среднего размера INT Стандартное целое число BIGINT D2 большое целое число номер точки FLOAT Число с плавающей запятой одинарной точности DOUBLE Число с плавающей запятой двойной точности BIT
Логический тип данных MySQL
90 002 MySQL не имеет встроенного типа данных BOOLEAN или BOOL .Для представления логических значений MySQL использует наименьший целочисленный тип, которым является TINYINT (1) . Другими словами, BOOLEAN и BOOL являются синонимами TINYINT (1). MySQL Строковые типы данных
В MySQL строка может содержать что угодно, от простого текста до двоичных данных, таких как изображения или файлы. Строки можно сравнивать и искать на основе сопоставления с образцом с помощью оператора LIKE , регулярного выражения и полнотекстового поиска.
В следующей таблице показаны строковые типы данных в MySQL:
Строковые типы Описание CHAR Недвоичная (символьная) строка фиксированной длины VARCH5 Недвоичная строка переменной длины BINARY Двоичная строка фиксированной длины VARBINARY двоичная строка переменной длины очень маленький BLOB (двоичный большой объект) BLOB Маленький большой двоичный объект MEDIUMBLOB Средний BLOB LONGBLOB TINYTEXT Очень маленькая недвоичная строка 901 66 TEXT Маленькая недвоичная строка MEDIUMTEXT Недвоичная строка среднего размера LONGTEXT A большая недвоичная строка ENUM Перечисление; каждому значению столбца может быть назначен один элемент перечисления SET A set; каждому значению столбца может быть присвоено ноль или более SET members
MySQL date and time data types
MySQL предоставляет типы для даты и времени, а также комбинацию даты и времени.Кроме того, MySQL поддерживает тип данных timestamp для отслеживания изменений в строке таблицы. Если вы просто хотите хранить годы без дат и месяцев, вы можете использовать тип данных YEAR .
В следующей таблице показаны типы данных даты и времени MySQL:
Типы даты и времени Описание ДАТА Значение даты в формате CCYY-MM-DD8 ВРЕМЯ Значение времени в формате чч: мм: сс ДАТА ВРЕМЯ Значение даты и времени в формате CCYY-MM-DD чч: мм: сс TIMESTAMP Значение отметки времени в формате CCYY-MM-DD чч: мм: ss формат YEAR Годовое значение в формате CCYY или 9017 9017 901 Типы пространственных данных MySQL MySQL поддерживает множество типов пространственных данных, которые содержат различные типы геометрических и географических значений, как показано в следующей таблице:
9016 6 Типы пространственных данных Описание ГЕОМЕТРИЯ Пространственное значение любого типа ТОЧКА Точка A (пара XYTR1 9017ES) 9017ES Кривая (одно или несколько значений POINT ) POLYGON A многоугольник GEOMETRYCOLLECTION GEOMETRY GEOMETRY Коллекция LINESTRING значений MULTIPOINT Коллекция POINT значений MULTIPOLYGON Поддерживаемая Коллекция собственный JSON , начиная с версии 5.7.8, который позволяет более эффективно хранить документы JSON и управлять ими. Собственный тип данных JSON обеспечивает автоматическую проверку документов JSON и оптимальный формат хранения. В этом руководстве вы узнали о различных типах данных MySQL, которые помогут вам определить, какой тип данных следует использовать для столбцов при создании таблиц.
- Было ли это руководство полезным?
- Да Нет
Подготовка к экзамену IELTS - таблица
- Дом
- IELTS Writing
- Стол
В задании 1 по академическому письму вам необходимо
для описания некоторой визуальной информации.Эта визуальная информация может быть таблицей. Столы
содержат слова, числа или знаки или их комбинацию, отображаемую в столбцах
или коробки, чтобы проиллюстрировать набор фактов и взаимосвязь между ними.
Причины посещения занятий искусством - взрослые в Великобритании
В таблице ниже показаны результаты 20-летнего исследования того, почему взрослые в Великобритании посещают художественные мероприятия. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Независимых фильмов, выпущенных в Великобритании и Ирландии, по жанрам 2012
В таблице ниже представлена информация о независимых фильмах Великобритании. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Языки с наибольшим количеством носителей языка
В таблице ниже представлена информация о языках, на которых больше всего носителей. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Средние продажи ресторанов А в трех разных филиалах
В таблице ниже представлена информация о средних продажах ресторанов в трех разных филиалах в 2016 году. Обобщите информацию, выбрав и сообщив об основных характеристиках,
и при необходимости проведите сравнения.
[Модель ответа]
Продажи чая и ананасов с маркировкой Fairtrade (2010 и 2015 гг.)
В таблицах ниже представлена информация о продажах чая и ананасов с маркировкой Fairtrade * в 2010 и 2015 годах в пяти европейских странах. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Квалификация для учителей английского языка, полученная в 2007/8 и 2008/9, Великобритания
В таблице ниже показано количество студентов, проживающих в Великобритании, получивших квалификацию учителя английского языка в 2007/8 и 2008/9 годах, а также долю мужчин, получивших квалификацию. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Доля рынка производителей портативных компьютеров
В приведенной ниже таблице показана мировая доля рынка ноутбуков для производителей в 2006 и 2007 годах. Обобщите информацию, выбрав и сообщив об основных характеристиках,
и при необходимости проведите сравнения.
[Модель ответа]
Участие в культурных мероприятиях, до 90 лет 151
В приведенной ниже таблице показаны результаты опроса 6800 взрослых шотландцев (в возрасте 16 лет и старше), принимали ли они участие в различных культурных мероприятиях за последние 12 месяцев. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Число просмотров фильмов по странам, в миллионах
В таблице ниже показано количество просмотров фильмов по странам в миллионах. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Транспорт и использование автомобилей в Эдмонтоне
В таблице представлена информация о транспорте и использовании автомобилей в Эдмонтоне. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Количество рожденных детей, Женщины в возрасте 4044 года
В приведенной ниже таблице представлено количество детей, когда-либо рожденных женщинами в возрасте 40-44 лет в Австралии за каждый год сбора информации с 1981 года. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Ответы студентов из Великобритании на вопрос
На диаграммах показаны ответы британских студентов на вопрос о том, в какой степени
охарактеризовали бы они себя как финансово организованные. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Причины покупок в супермаркете ASDA
В таблице указаны причины для покупок в супермаркете ASDA. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Количество медалей
В таблице указано количество медалей, выигранных десятью странами,
Олимпийские игры 2012 года в Лондоне. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Средние баллы студентов из разных языковых групп
В таблице приведены средние баллы по группе студентов, говорящих на разных языках.
группы, проходящие общий тест IELTS в 2010 году. Обобщите информацию, выбрав и сообщив об основных характеристиках,
и при необходимости проведите сравнения.
[Модель ответа]
Ежемесячные расходы средней австралийской семьи
В таблице показаны ежемесячные расходы средней австралийской семьи.
в 1991 и 2001 годах. Обобщите информацию, выбрав и сообщив об основных характеристиках,
и при необходимости проведите сравнения.
[Модель ответа]
Количество выпитого пива и фруктовых соков
В таблицах представлена информация о количестве выпитого пива и фруктового сока.
на человека в год в разных странах. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Любимые развлечения в разных странах
В таблице представлена информация о любимых развлечениях в разных странах. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Связанные темы
Калькулятор ИМТ
Результат
ИМТ = 20.1 кг / м 2 ( Нормальный )
20,1
- Здоровый диапазон ИМТ: 18,5 кг / м 2 -25 кг / м 2
- Здоровый вес для роста: 59,9 кг - 81,0 кг
- Весовой индекс: 11,1 кг / м 3
Калькулятор индекса массы тела (ИМТ) может использоваться для расчета значения ИМТ и соответствующего статуса веса с учетом возраста.Используйте вкладку «Метрические единицы» для Международной системы единиц или вкладку «Другие единицы» для преобразования единиц в американские или метрические единицы. Обратите внимание, что калькулятор также вычисляет Ponderal Index в дополнение к BMI, оба из которых подробно обсуждаются ниже.
BMI введение
ИМТ - это показатель худощавости или полноты человека, основанный на его росте и весе, и предназначен для количественной оценки массы ткани. Он широко используется в качестве общего индикатора того, соответствует ли человек своему росту.В частности, значение, полученное при вычислении ИМТ, используется для классификации того, имеет ли человек недостаточный вес, нормальный вес, избыточный вес или ожирение, в зависимости от того, в какой диапазон попадает это значение. Эти диапазоны ИМТ варьируются в зависимости от таких факторов, как регион и возраст, и иногда делятся на подкатегории, такие как сильно пониженный вес или очень тяжелое ожирение. Избыточный или недостаточный вес может иметь значительные последствия для здоровья, поэтому, хотя ИМТ является несовершенным показателем здоровой массы тела, это полезный индикатор того, требуются ли какие-либо дополнительные тесты или действия.Обратитесь к таблице ниже, чтобы увидеть различные категории на основе ИМТ, которые используются калькулятором.
Таблица ИМТ для взрослых
Это рекомендованная Всемирной организацией здравоохранения (ВОЗ) масса тела на основе значений ИМТ для взрослых. Его применяют как мужчины, так и женщины в возрасте от 18 лет и старше.
Категория Диапазон ИМТ - кг / м 2 Сильная тонкость <16 Умеренная тонкость 16-17 18175 Слабая 5 Нормальный 18,5 - 25 Избыточный 25-30 Ожирение, класс I 30-35 Ожирение, класс II 9017-40be 35175 Класс III > 40
Таблица ИМТ для взрослых
Это график категорий ИМТ на основе данных Всемирной организации здравоохранения. Пунктирными линиями обозначены подразделения в рамках основной категоризации.
Таблица ИМТ для детей и подростков 2-20 лет
Центры по контролю и профилактике заболеваний (CDC) рекомендуют категоризацию ИМТ для детей и подростков в возрасте от 2 до 20 лет.
Категория Процентильный диапазон Недостаточный вес <5% Здоровый вес 5% - 85% С риском избыточного веса 85% - 95% Избыточный вес > 95%
Таблица ИМТ для детей и подростков в возрасте 2-20 лет
Центры по контролю и профилактике заболеваний (CDC) График роста процентилей ИМТ к возрасту.
График для мальчиков
График для девочек Риски, связанные с лишним весом
Избыточный вес увеличивает риск ряда серьезных заболеваний и состояний здоровья. Ниже приведен список указанных рисков по данным Центров по контролю и профилактике заболеваний (CDC):
- Высокое кровяное давление
- Более высокий уровень холестерина ЛПНП, который широко считается «плохим холестерином», более низкий уровень холестерина ЛПВП, который в умеренных количествах считается хорошим холестерином, и высокий уровень триглицеридов
- Сахарный диабет II типа
- Ишемическая болезнь сердца
- Ход
- Болезнь желчного пузыря
- Остеоартроз, разновидность заболевания суставов, вызванная разрушением суставного хряща
- Апноэ во сне и проблемы с дыханием
- Некоторые виды рака (эндометрия, груди, толстой кишки, почек, желчного пузыря, печени)
- Низкое качество жизни
- Психические заболевания, такие как клиническая депрессия, тревога и другие
- Боли в теле и трудности с некоторыми физическими функциями
- Как правило, повышенный риск смерти по сравнению с людьми со здоровым ИМТ
Как видно из приведенного выше списка, существует множество отрицательных, в некоторых случаях летальных исходов, которые могут возникнуть в результате избыточного веса.Как правило, человеку следует стремиться поддерживать ИМТ ниже 25 кг / м 2 , но в идеале следует проконсультироваться со своим врачом, чтобы определить, нужно ли ему вносить какие-либо изменения в свой образ жизни, чтобы стать более здоровым.
Риски, связанные с недостаточным весом
Недостаточный вес имеет свои риски, перечисленные ниже:
- Недоедание, авитаминоз, анемия (снижение способности переносить сосуды)
- Остеопороз, заболевание, вызывающее слабость костей, повышающее риск перелома кости
- Снижение иммунной функции
- Проблемы роста и развития, особенно у детей и подростков
- Возможные репродуктивные проблемы у женщин из-за гормонального дисбаланса, который может нарушить менструальный цикл.У женщин с недостаточным весом также выше вероятность выкидыша в первом триместре
- Возможные осложнения после операции
- Как правило, повышенный риск смерти по сравнению с людьми со здоровым ИМТ
В некоторых случаях недостаточный вес может быть признаком какого-либо основного состояния или заболевания, например нервной анорексии, которое имеет свои риски. Проконсультируйтесь с врачом, если вы считаете, что у вас или у кого-то из ваших знакомых недостаточный вес, особенно если причина недостаточного веса не кажется очевидной.
Ограничения ИМТ
Хотя ИМТ является широко используемым и полезным индикатором здоровой массы тела, у него есть свои ограничения. ИМТ - это всего лишь оценка, которая не может принимать во внимание состав тела. Из-за большого разнообразия типов телосложения, а также распределения мышечной, костной массы и жира, ИМТ следует рассматривать вместе с другими измерениями, а не использовать в качестве единственного метода для определения здоровой массы тела человека.
Для взрослых:
ИМТ не может быть полностью точным, потому что это показатель избыточной массы тела, а не избыточного жира.На ИМТ также влияют такие факторы, как возраст, пол, этническая принадлежность, мышечная масса и жировые отложения, а также уровень активности, среди прочих. Например, пожилой человек, имеющий нормальный вес, но совершенно неактивный в повседневной жизни, может иметь значительное количество лишнего жира, даже если он не тяжелый. Это будет считаться нездоровым, в то время как более молодой человек с более высоким мышечным составом и тем же ИМТ будет считаться здоровым. У спортсменов, особенно у бодибилдеров, у которых может считаться избыточный вес из-за того, что мышцы тяжелее жира, вполне возможно, что они действительно имеют здоровый вес для их состава тела.Как правило, согласно CDC:
- Пожилые люди, как правило, имеют больше жира, чем молодые люди с таким же ИМТ.
- У женщин, как правило, больше жира, чем у мужчин с таким же ИМТ.
- Мускулистые люди и хорошо тренированные спортсмены могут иметь более высокий ИМТ из-за большой мышечной массы.
У детей и подростков:
Те же факторы, которые ограничивают эффективность ИМТ для взрослых, могут также применяться к детям и подросткам.Кроме того, рост и уровень полового созревания могут влиять на ИМТ и жировые отложения у детей. ИМТ является лучшим индикатором избыточного жира у детей с ожирением, чем у детей с избыточным весом, у которых ИМТ может быть результатом повышенного уровня либо жировой, либо обезжиренной массы (всех компонентов тела, кроме жира, который включает воду, органы и т. мышцы и др.). У худых детей разница в ИМТ также может быть связана с обезжиренной массой.
При этом ИМТ является довольно показательным показателем телесного жира для 90-95% населения и может эффективно использоваться вместе с другими показателями для определения здоровой массы тела человека.
Формула ИМТ
Ниже приведены уравнения, используемые для расчета ИМТ в Международной системе единиц (SI) и обычной системе США (USC) на примере человека весом 5'10 дюймов и 160 фунтов:
USC Единицы:
ИМТ = 703 × = 703 × = 22,96
СИ, метрические единицы:
ИМТ = = = 22.90
Ponderal Index
Ponderal Index (PI) похож на BMI в том, что он измеряет худобу или полноту человека в зависимости от его роста и веса.
BIT для хранения битовых значений. Числовые типы могут быть знаковыми или беззнаковыми, за исключением типа BIT . TINYINT MEDIUMINT INT BIGINT FLOAT DOUBLE BIT LIKE , регулярного выражения и полнотекстового поиска. CHAR VARCH5 Недвоичная строка переменной длины BINARY Двоичная строка фиксированной длины VARBINARY двоичная строка переменной длины очень маленький BLOB (двоичный большой объект) BLOB Маленький большой двоичный объект MEDIUMBLOB Средний BLOB LONGBLOB TINYTEXT Очень маленькая недвоичная строка 901 66 TEXT Маленькая недвоичная строка MEDIUMTEXT Недвоичная строка среднего размера LONGTEXT A большая недвоичная строка ENUM Перечисление; каждому значению столбца может быть назначен один элемент перечисления SET A set; каждому значению столбца может быть присвоено ноль или более SET members YEAR . ДАТА CCYY-MM-DD8 ВРЕМЯ чч: мм: сс ДАТА ВРЕМЯ CCYY-MM-DD чч: мм: сс TIMESTAMP CCYY-MM-DD чч: мм: ss формат YEAR CCYY или 9017 9017 901 Типы пространственных данных MySQL MySQL поддерживает множество типов пространственных данных, которые содержат различные типы геометрических и географических значений, как показано в следующей таблице:
9016 6 Типы пространственных данных Описание ГЕОМЕТРИЯ Пространственное значение любого типа ТОЧКА Точка A (пара XYTR1 9017ES) 9017ES Кривая (одно или несколько значений POINT ) POLYGON A многоугольник GEOMETRYCOLLECTION GEOMETRY GEOMETRY Коллекция LINESTRING значений MULTIPOINT Коллекция POINT значений MULTIPOLYGON Поддерживаемая Коллекция собственный JSON , начиная с версии 5.7.8, который позволяет более эффективно хранить документы JSON и управлять ими. Собственный тип данных JSON обеспечивает автоматическую проверку документов JSON и оптимальный формат хранения. В этом руководстве вы узнали о различных типах данных MySQL, которые помогут вам определить, какой тип данных следует использовать для столбцов при создании таблиц.
- Было ли это руководство полезным?
- Да Нет
Подготовка к экзамену IELTS - таблица
- Дом
- IELTS Writing
- Стол
В задании 1 по академическому письму вам необходимо
для описания некоторой визуальной информации.Эта визуальная информация может быть таблицей. Столы
содержат слова, числа или знаки или их комбинацию, отображаемую в столбцах
или коробки, чтобы проиллюстрировать набор фактов и взаимосвязь между ними.
Причины посещения занятий искусством - взрослые в Великобритании
В таблице ниже показаны результаты 20-летнего исследования того, почему взрослые в Великобритании посещают художественные мероприятия. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Независимых фильмов, выпущенных в Великобритании и Ирландии, по жанрам 2012
В таблице ниже представлена информация о независимых фильмах Великобритании. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Языки с наибольшим количеством носителей языка
В таблице ниже представлена информация о языках, на которых больше всего носителей. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Средние продажи ресторанов А в трех разных филиалах
В таблице ниже представлена информация о средних продажах ресторанов в трех разных филиалах в 2016 году. Обобщите информацию, выбрав и сообщив об основных характеристиках,
и при необходимости проведите сравнения.
[Модель ответа]
Продажи чая и ананасов с маркировкой Fairtrade (2010 и 2015 гг.)
В таблицах ниже представлена информация о продажах чая и ананасов с маркировкой Fairtrade * в 2010 и 2015 годах в пяти европейских странах. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Квалификация для учителей английского языка, полученная в 2007/8 и 2008/9, Великобритания
В таблице ниже показано количество студентов, проживающих в Великобритании, получивших квалификацию учителя английского языка в 2007/8 и 2008/9 годах, а также долю мужчин, получивших квалификацию. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Доля рынка производителей портативных компьютеров
В приведенной ниже таблице показана мировая доля рынка ноутбуков для производителей в 2006 и 2007 годах. Обобщите информацию, выбрав и сообщив об основных характеристиках,
и при необходимости проведите сравнения.
[Модель ответа]
Участие в культурных мероприятиях, до 90 лет 151
В приведенной ниже таблице показаны результаты опроса 6800 взрослых шотландцев (в возрасте 16 лет и старше), принимали ли они участие в различных культурных мероприятиях за последние 12 месяцев. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Число просмотров фильмов по странам, в миллионах
В таблице ниже показано количество просмотров фильмов по странам в миллионах. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Транспорт и использование автомобилей в Эдмонтоне
В таблице представлена информация о транспорте и использовании автомобилей в Эдмонтоне. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Количество рожденных детей, Женщины в возрасте 4044 года
В приведенной ниже таблице представлено количество детей, когда-либо рожденных женщинами в возрасте 40-44 лет в Австралии за каждый год сбора информации с 1981 года. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Ответы студентов из Великобритании на вопрос
На диаграммах показаны ответы британских студентов на вопрос о том, в какой степени
охарактеризовали бы они себя как финансово организованные. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Причины покупок в супермаркете ASDA
В таблице указаны причины для покупок в супермаркете ASDA. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Количество медалей
В таблице указано количество медалей, выигранных десятью странами,
Олимпийские игры 2012 года в Лондоне. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Средние баллы студентов из разных языковых групп
В таблице приведены средние баллы по группе студентов, говорящих на разных языках.
группы, проходящие общий тест IELTS в 2010 году. Обобщите информацию, выбрав и сообщив об основных характеристиках,
и при необходимости проведите сравнения.
[Модель ответа]
Ежемесячные расходы средней австралийской семьи
В таблице показаны ежемесячные расходы средней австралийской семьи.
в 1991 и 2001 годах. Обобщите информацию, выбрав и сообщив об основных характеристиках,
и при необходимости проведите сравнения.
[Модель ответа]
Количество выпитого пива и фруктовых соков
В таблицах представлена информация о количестве выпитого пива и фруктового сока.
на человека в год в разных странах. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Любимые развлечения в разных странах
В таблице представлена информация о любимых развлечениях в разных странах. Обобщите информацию, выбрав и сообщив об основных функциях,
и при необходимости проведите сравнения.
[Модель ответа]
Связанные темы
Калькулятор ИМТ
Результат
ИМТ = 20.1 кг / м 2 ( Нормальный )
20,1
- Здоровый диапазон ИМТ: 18,5 кг / м 2 -25 кг / м 2
- Здоровый вес для роста: 59,9 кг - 81,0 кг
- Весовой индекс: 11,1 кг / м 3
Калькулятор индекса массы тела (ИМТ) может использоваться для расчета значения ИМТ и соответствующего статуса веса с учетом возраста.Используйте вкладку «Метрические единицы» для Международной системы единиц или вкладку «Другие единицы» для преобразования единиц в американские или метрические единицы. Обратите внимание, что калькулятор также вычисляет Ponderal Index в дополнение к BMI, оба из которых подробно обсуждаются ниже.
BMI введение
ИМТ - это показатель худощавости или полноты человека, основанный на его росте и весе, и предназначен для количественной оценки массы ткани. Он широко используется в качестве общего индикатора того, соответствует ли человек своему росту.В частности, значение, полученное при вычислении ИМТ, используется для классификации того, имеет ли человек недостаточный вес, нормальный вес, избыточный вес или ожирение, в зависимости от того, в какой диапазон попадает это значение. Эти диапазоны ИМТ варьируются в зависимости от таких факторов, как регион и возраст, и иногда делятся на подкатегории, такие как сильно пониженный вес или очень тяжелое ожирение. Избыточный или недостаточный вес может иметь значительные последствия для здоровья, поэтому, хотя ИМТ является несовершенным показателем здоровой массы тела, это полезный индикатор того, требуются ли какие-либо дополнительные тесты или действия.Обратитесь к таблице ниже, чтобы увидеть различные категории на основе ИМТ, которые используются калькулятором.
Таблица ИМТ для взрослых
Это рекомендованная Всемирной организацией здравоохранения (ВОЗ) масса тела на основе значений ИМТ для взрослых. Его применяют как мужчины, так и женщины в возрасте от 18 лет и старше.
Категория Диапазон ИМТ - кг / м 2 Сильная тонкость <16 Умеренная тонкость 16-17 18175 Слабая 5 Нормальный 18,5 - 25 Избыточный 25-30 Ожирение, класс I 30-35 Ожирение, класс II 9017-40be 35175 Класс III > 40
Таблица ИМТ для взрослых
Это график категорий ИМТ на основе данных Всемирной организации здравоохранения. Пунктирными линиями обозначены подразделения в рамках основной категоризации.
Таблица ИМТ для детей и подростков 2-20 лет
Центры по контролю и профилактике заболеваний (CDC) рекомендуют категоризацию ИМТ для детей и подростков в возрасте от 2 до 20 лет.
Категория Процентильный диапазон Недостаточный вес <5% Здоровый вес 5% - 85% С риском избыточного веса 85% - 95% Избыточный вес > 95%
Таблица ИМТ для детей и подростков в возрасте 2-20 лет
Центры по контролю и профилактике заболеваний (CDC) График роста процентилей ИМТ к возрасту.
График для мальчиков
График для девочек Риски, связанные с лишним весом
Избыточный вес увеличивает риск ряда серьезных заболеваний и состояний здоровья. Ниже приведен список указанных рисков по данным Центров по контролю и профилактике заболеваний (CDC):
- Высокое кровяное давление
- Более высокий уровень холестерина ЛПНП, который широко считается «плохим холестерином», более низкий уровень холестерина ЛПВП, который в умеренных количествах считается хорошим холестерином, и высокий уровень триглицеридов
- Сахарный диабет II типа
- Ишемическая болезнь сердца
- Ход
- Болезнь желчного пузыря
- Остеоартроз, разновидность заболевания суставов, вызванная разрушением суставного хряща
- Апноэ во сне и проблемы с дыханием
- Некоторые виды рака (эндометрия, груди, толстой кишки, почек, желчного пузыря, печени)
- Низкое качество жизни
- Психические заболевания, такие как клиническая депрессия, тревога и другие
- Боли в теле и трудности с некоторыми физическими функциями
- Как правило, повышенный риск смерти по сравнению с людьми со здоровым ИМТ
Как видно из приведенного выше списка, существует множество отрицательных, в некоторых случаях летальных исходов, которые могут возникнуть в результате избыточного веса.Как правило, человеку следует стремиться поддерживать ИМТ ниже 25 кг / м 2 , но в идеале следует проконсультироваться со своим врачом, чтобы определить, нужно ли ему вносить какие-либо изменения в свой образ жизни, чтобы стать более здоровым.
Риски, связанные с недостаточным весом
Недостаточный вес имеет свои риски, перечисленные ниже:
- Недоедание, авитаминоз, анемия (снижение способности переносить сосуды)
- Остеопороз, заболевание, вызывающее слабость костей, повышающее риск перелома кости
- Снижение иммунной функции
- Проблемы роста и развития, особенно у детей и подростков
- Возможные репродуктивные проблемы у женщин из-за гормонального дисбаланса, который может нарушить менструальный цикл.У женщин с недостаточным весом также выше вероятность выкидыша в первом триместре
- Возможные осложнения после операции
- Как правило, повышенный риск смерти по сравнению с людьми со здоровым ИМТ
В некоторых случаях недостаточный вес может быть признаком какого-либо основного состояния или заболевания, например нервной анорексии, которое имеет свои риски. Проконсультируйтесь с врачом, если вы считаете, что у вас или у кого-то из ваших знакомых недостаточный вес, особенно если причина недостаточного веса не кажется очевидной.
Ограничения ИМТ
Хотя ИМТ является широко используемым и полезным индикатором здоровой массы тела, у него есть свои ограничения. ИМТ - это всего лишь оценка, которая не может принимать во внимание состав тела. Из-за большого разнообразия типов телосложения, а также распределения мышечной, костной массы и жира, ИМТ следует рассматривать вместе с другими измерениями, а не использовать в качестве единственного метода для определения здоровой массы тела человека.
Для взрослых:
ИМТ не может быть полностью точным, потому что это показатель избыточной массы тела, а не избыточного жира.На ИМТ также влияют такие факторы, как возраст, пол, этническая принадлежность, мышечная масса и жировые отложения, а также уровень активности, среди прочих. Например, пожилой человек, имеющий нормальный вес, но совершенно неактивный в повседневной жизни, может иметь значительное количество лишнего жира, даже если он не тяжелый. Это будет считаться нездоровым, в то время как более молодой человек с более высоким мышечным составом и тем же ИМТ будет считаться здоровым. У спортсменов, особенно у бодибилдеров, у которых может считаться избыточный вес из-за того, что мышцы тяжелее жира, вполне возможно, что они действительно имеют здоровый вес для их состава тела.Как правило, согласно CDC:
- Пожилые люди, как правило, имеют больше жира, чем молодые люди с таким же ИМТ.
- У женщин, как правило, больше жира, чем у мужчин с таким же ИМТ.
- Мускулистые люди и хорошо тренированные спортсмены могут иметь более высокий ИМТ из-за большой мышечной массы.
У детей и подростков:
Те же факторы, которые ограничивают эффективность ИМТ для взрослых, могут также применяться к детям и подросткам.Кроме того, рост и уровень полового созревания могут влиять на ИМТ и жировые отложения у детей. ИМТ является лучшим индикатором избыточного жира у детей с ожирением, чем у детей с избыточным весом, у которых ИМТ может быть результатом повышенного уровня либо жировой, либо обезжиренной массы (всех компонентов тела, кроме жира, который включает воду, органы и т. мышцы и др.). У худых детей разница в ИМТ также может быть связана с обезжиренной массой.
При этом ИМТ является довольно показательным показателем телесного жира для 90-95% населения и может эффективно использоваться вместе с другими показателями для определения здоровой массы тела человека.
Формула ИМТ
Ниже приведены уравнения, используемые для расчета ИМТ в Международной системе единиц (SI) и обычной системе США (USC) на примере человека весом 5'10 дюймов и 160 фунтов:
USC Единицы:
ИМТ = 703 × = 703 × = 22,96
СИ, метрические единицы:
ИМТ = = = 22.90
Ponderal Index
Ponderal Index (PI) похож на BMI в том, что он измеряет худобу или полноту человека в зависимости от его роста и веса.