|
Решение задач на компьютере Ключевые слова:
2.1.1. Этапы решения задачи на компьютере Решение задачи с использованием компьютера включает в себя этапы, показанные на рис. 2.1. На первом этапе обычно осуществляется постановка задачи, происходит осознание её условия. При этом должно быть чётко определено, что дано (какие исходные данные известны, какие данные допустимы) и что требуется найти в решаемой задаче. На втором этапе описательная информационная модель формализуется, т.е. записывается с помощью некоторого формального языка. Решение задач на компьютере. Этап Результат Рис.2.1.Этапы решения задач на компьютере Для этого требуется:
На третьем этапе осуществляется построение алгоритма — чёткой инструкции, задающей необходимую последовательность действий для решения задачи. Алгоритм чаще всего представляется в форме блок-схемы ввиду её наглядности и универсальности. На четвёртом этапе алгоритм записывается на одном из языков программирования. На пятом этапе осуществляется отладка и тестирование программы. Этап отладки и тестирования также называют компьютерным экспериментом. Отладка программы — это процесс проверки работоспособности программы и исправления обнаруженных при этом ошибок. Ошибки могут быть связаны с нарушением правил записи программы на конкретном языке программирования. Их программисту помогает найти используемая система программирования; она выдаёт на экран сообщения о выявленных ошибках. Проверка правильности разработанной программы осуществляется с помощью тестов. Тест — это конкретный вариант значений исходных данных, для которого известен ожидаемый результат. Вопросы и задания 1.Ознакомьтесь с материалами презентации к параграфу, содержащейся в электронном приложении к учебнику. Дополняет ли презентация информацию, содержащуюся в тексте параграфа? 2.Перечислите основные этапы решения задачи с использованием компьютера. 3.Что происходит на этапе постановки задачи? Что является результатом этого этапа? 4.Что происходит на этапе формализации? Что является результатом этого этапа? 5.Что происходит на этапе алгоритмизации? Что является результатом этого этапа? 6.Что происходит на этапе программирования? Что является результатом этого этапа? 7.Что происходит на этапе компьютерного эксперимента? Что является результатом этого этапа? Самое главное Этапы решения задачи с использованием компьютера: 1. постановка задачи; 2. формализация; 3. алгоритмизация; 4. 5. компьютерный эксперимент.
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

 Вы учитесь записывать программы на языке Паскаль.
Вы учитесь записывать программы на языке Паскаль.
 программирование;
программирование;Этапы решение задачи на компьютере.
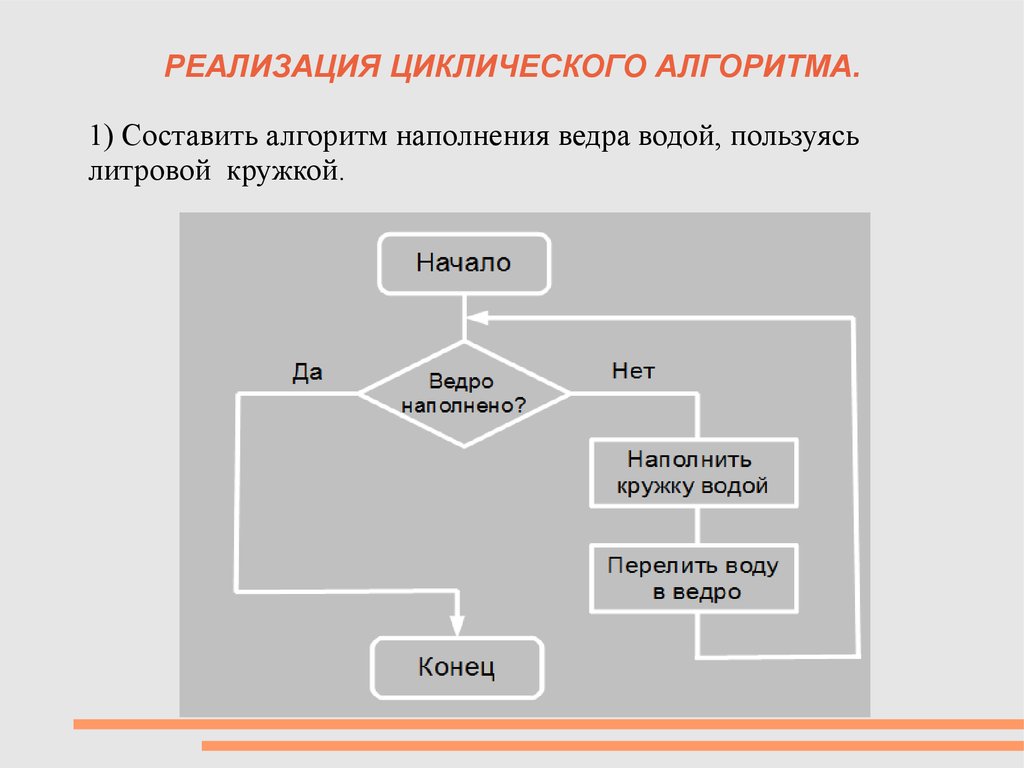 Принцип последовательного конструирования алгоритма
Принцип последовательного конструирования алгоритмаВопросы:
· Этапы решения задачи на компьютере.
· Принцип последовательного конструирования алгоритма.
Давайте подумаем, с чего начинается решение любой задачи, не обязательно связанной с компьютером. Решение любой задачи начинается с прочтения и уточнения её условия. Условия задач мы рассматривали в текстовой форме. Мы выделяли информацию, которая дана в условии – входные данные, а также информацию которую необходимо получить – выходные данные. Это начальный этап решения задачи, то есть её постановка.
После
того, как мы определили входные и выходные данные задачи, нам нужно определиться
со средствами, которые могут быть необходимы для получения выходных данных из входных.
Для этого определяются отношения между ними и записываются на каком-нибудь
формальном языке, например, с помощью математических формул. Результатом этих
действий будет информационная модель задачи, записанная на некотором формальном
языке.
После того, как мы определились со средствами решения задачи, нужно понять, что необходимо сделать для того, чтобы получить выходные данные из входных, какие действия над информацией и в каком порядке для этого нужно произвести. То есть мы составляем алгоритм решения задачи и описываем его одним из известных нам способов, например, с помощью блок-схемы или в текстовой форме. Главное, чтобы было понятно, что должна делать программа и в каком порядке. Этот этап называется созданием алгоритма.
Далее мы записывали созданный алгоритм с помощью языка программирования или других инструментов. И получали компьютерную программу для решения задачи. Этот этап имеет простое название: программирование
Получив
компьютерную программу, мы обычно проверяли правильность её работы. Сначала пробовали
запустить программу. После чего задавали несколько различных вариантов входных
данных, для которых выходные данные уже были известны, и проверяли, совпадают
ли они с теми, которые возвращает программа. Если данные совпадают – программа
работает правильно и задача решена. Если же не совпадают – на каком-то из
этапов была допущена ошибка. Этот процесс называется тестированием программы.
Если данные совпадают – программа
работает правильно и задача решена. Если же не совпадают – на каком-то из
этапов была допущена ошибка. Этот процесс называется тестированием программы.
Ошибки в программе бывают двух видов: синтаксические и логические. Синтаксические ошибки связаны с записью программы на конкретном языке программирования и, как правило, находятся и исправляются средствами среды разработки. Логические ошибки обычно допускаются на более ранних этапах. После того, как ошибка была исправлена, снова проделываются все этапы, следующие за тем, на котором допущена ошибка. Так происходит до тех пор, пока правильность работы программы не подтверждается. Этот процесс называется отладкой.
Таким
образом, мы выделили пять этапов решения задачи с помощью компьютера:
постановка задачи, формализация задачи, создание алгоритма, программирование,
тестирование и отладка. Все эти этапы мы выполняли при решении задач и раньше,
но для экономии времени часто этапы формализации задачи и создания алгоритма мы
объединяли между собой.
Но предположим, что у нас есть задача, для которой мы уже описали формальную информационную модель, однако придумать алгоритм для решения задачи у нас не выходит, потому что он получается слишком большим и сложным. Чтобы облегчить эту задачу, можно использовать
Рассмотрим
задачу. Написать программу, вычисляющую наименьшее общее кратное двух целых
положительных чисел a
и b.
Решение первой и третьей подзадач очевидно. Также ранее мы узнали, что наибольший общий делитель двух чисел можно найти, использовав усовершенствованный алгоритм Эвклида, который состоит в том, чтобы заменять большее число в паре его остатком от деления на другое до тех пор, пока одно из чисел не станет равным нулю. После этого ненулевое число будет равным наибольшему общему делителю исходных чисел.
Начнём
написание программы для решения задачи. Вначале с помощью инструкции print
выведем на экран сообщение о том, что это программа, вычисляющая наименьшее
общее кратное целых положительных чисел a
и b. С помощью следующей
инструкции print выведем на экран
запрос на ввод a без перехода на
следующую строку. Далее запишем инструкцию для считывания a.
Так как по условию задачи a
и b –
это целые числа, при считывании будем преобразовывать их значения в
целочисленный тип int.
Теперь скопируем последние две инструкции и изменим их для считывания значения
Бэ.
Вначале с помощью инструкции print
выведем на экран сообщение о том, что это программа, вычисляющая наименьшее
общее кратное целых положительных чисел a
и b. С помощью следующей
инструкции print выведем на экран
запрос на ввод a без перехода на
следующую строку. Далее запишем инструкцию для считывания a.
Так как по условию задачи a
и b –
это целые числа, при считывании будем преобразовывать их значения в
целочисленный тип int.
Теперь скопируем последние две инструкции и изменим их для считывания значения
Бэ.
Далее
вычислим произведение a
и b в переменной p.
Таким образом, первая подзадача будет решена. Далее вычислим наибольший общий
делитель a и b.
Для этого запишем цикл while,
который будет повторяться, пока a
≠
0
и b ≠ 0.
Тело цикла будет содержать ветвление, определяющее, какое из чисел наибольшее. Его
условием будет: a
> b. Если это условие
выполняется, то число a
на этом шаге цикла наибольшее и согласно алгоритму Эвклида, мы заменим его
остатком от деления a
на b. Если же условие
ветвления не выполняется, то наибольшим числом на этом шаге цикла является b,
и мы заменим его остатком от деления b
на a. Когда одно из чисел a
или b станет равным 0, цикл завершит
свою работу и мы вычислим наибольший общий делитель исходных чисел в переменной
nod как сумму текущих
значений a и b.
Таким образом мы решили вторую подзадачу.
Его
условием будет: a
> b. Если это условие
выполняется, то число a
на этом шаге цикла наибольшее и согласно алгоритму Эвклида, мы заменим его
остатком от деления a
на b. Если же условие
ветвления не выполняется, то наибольшим числом на этом шаге цикла является b,
и мы заменим его остатком от деления b
на a. Когда одно из чисел a
или b станет равным 0, цикл завершит
свою работу и мы вычислим наибольший общий делитель исходных чисел в переменной
nod как сумму текущих
значений a и b.
Таким образом мы решили вторую подзадачу.
Теперь,
чтобы вычислить наименьшее общее кратное введённых чисел, присвоим переменной nok
значение переменной p,
делённое на значение переменной nod.
Так как наименьшее общее кратное – целое число, используем для этого операцию
целочисленного деления. Таким образом мы решили третью подзадачу. С помощью
инструкции print выведем на экран
поясняющее сообщение о том, что наибольшее общее кратное a
и b равно
значению переменной nok.
Таким образом мы решили третью подзадачу. С помощью
инструкции print выведем на экран
поясняющее сообщение о том, что наибольшее общее кратное a
и b равно
значению переменной nok.
print (‘Программа, вычисляющая НОК a и b.’)
print (‘a = ‘, end = »)
a = int (input ())
print (‘b = ‘, end = »)
b = int (input ())
p = a * b
while a != 0 and b != 0:
if a > b:
a = a % b
else:
b = b % a
nod = a + b
nok = p // nod
print (‘НОК введённых чисел:’, nok)
Сохраним
написанную программу и протестируем её. Запустим программу на выполнение и
зададим числа 2 и 3. Действительно, наименьшее число, которое без остатка
делится и на 2, и на 3 – 6. Снова запустим программу и зададим числа 6 и 8.
Действительно, наименьшее число, которое без остатка делится и на 6, и на 8 – 24. Программа работает правильно. Задача решена.
Программа работает правильно. Задача решена.
Рассмотрим ещё одну задачу. Выпуклый четырёхугольник задан положительными длинами своих сторон: a, b, c и d. Написать программу для вычисления его площади, если известно, что между сторонами a и b прямой угол.
Изобразим
условие этой задачи в виде рисунка. Соединим противоположные концы сторон a
и b отрезком, длину которого
обозначим t. Таким образом мы
разделили четырёхугольник на два треугольника со сторонами a, b, t
и c, d, t
соответственно. Площадь четырёхугольника равна сумме их
площадей. Так как между сторонами a
и b прямой угол, то площадь
первого треугольника можно вычислить как полупроизведение a
и b, а t
– как гипотенузу первого треугольника. Зная значения c,
d и t,
мы можем вычислить площадь второго треугольника по формуле Герона. Таким
образом, мы записали формулы, необходимые для решения задачи, получив
математическую модель.
Таким
образом, мы записали формулы, необходимые для решения задачи, получив
математическую модель.
Также мы разобьём задачу на несколько подзадач. Вначале мы вычислим площадь первого треугольника, после чего определим длину стороны t. Далее мы вычислим площадь второго треугольника и в конце рассчитаем площадь четырёхугольника как сумму площадей треугольников, из которых он состоит. Так мы составили алгоритм решения задачи.
Начнём
написание программы. Вначале с помощью инструкции print
выведем на экран сообщение о том, что это программа, вычисляющая площадь
четырёхугольника по длинам его сторон. Угол между сторонами a
и b прямой. С помощью
следующей инструкции print
выведем на экран запрос на ввод a
без перехода на следующую строку. Запишем инструкции для считывания значения a.
Так как в условии задачи не сказано, что длины сторон – целые числа, при
считывании мы будем преобразовывать их значения в вещественный тип float. Скопируем последние две инструкции три раза и изменим их для считывания
значений переменных b,
c и d.
После того как мы рассчитали длины сторон четырёхугольника, вычислим площадь
первого треугольника в переменной s1.
Для этого присвоим ей значение a
* b / 2.
Так как для вычисления длины гипотенузы треугольника нам потребуется извлечь
квадратный корень, загрузим эту функцию из модуля math
в описываемый модуль. После этого вычислим длину гипотенузы первого
треугольника в переменной t.
Для этого присвоим ей значение квадратного корня из суммы квадратов a
и b. Теперь вычислим
полупериметр второго треугольника в переменной p.
Для этого присвоим ей значение полусуммы c,
d и t.
Далее вычислим по формуле Герона площадь второго треугольника в переменной s2.
Для этого присвоим ей значение квадратного корня из произведения p
* (p
–
c) * (p
– d) * (p
– t).
Скопируем последние две инструкции три раза и изменим их для считывания
значений переменных b,
c и d.
После того как мы рассчитали длины сторон четырёхугольника, вычислим площадь
первого треугольника в переменной s1.
Для этого присвоим ей значение a
* b / 2.
Так как для вычисления длины гипотенузы треугольника нам потребуется извлечь
квадратный корень, загрузим эту функцию из модуля math
в описываемый модуль. После этого вычислим длину гипотенузы первого
треугольника в переменной t.
Для этого присвоим ей значение квадратного корня из суммы квадратов a
и b. Теперь вычислим
полупериметр второго треугольника в переменной p.
Для этого присвоим ей значение полусуммы c,
d и t.
Далее вычислим по формуле Герона площадь второго треугольника в переменной s2.
Для этого присвоим ей значение квадратного корня из произведения p
* (p
–
c) * (p
– d) * (p
– t). И, наконец, вычислим площадь четырёхугольника в переменной s,
присвоив ей значение суммы s1
и s2.
С помощью инструкции print
выведем на экран сообщение о том, что площадь четырёхугольника равна значению
переменной s. Будем выводить s
с точностью в четыре знака после запятой.
И, наконец, вычислим площадь четырёхугольника в переменной s,
присвоив ей значение суммы s1
и s2.
С помощью инструкции print
выведем на экран сообщение о том, что площадь четырёхугольника равна значению
переменной s. Будем выводить s
с точностью в четыре знака после запятой.
print (‘Программа, вычисляющая площадь четырёхугольника по длинам его сторон. Угол между a и b прямой.’)
print (‘a = ‘, end = »)
a = float (input ())
print (‘b = ‘, end = »)
b = float (input ())
print (‘c = ‘, end = »)
c = float (input ())
print (‘d = ‘, end = »)
d = float (input ())
s1 = a * b / 2
from math import sqrt
t = sqrt (a ** 2 + b ** 2)
p = (c + d + t) / 2
s2 = sqrt (p * (p — c) * (p — d) * (p — t))
s = s1 + s2
print (‘Площадь
заданного четырёхугольника:’, ‘{:0. 4f}’.format
(s))
4f}’.format
(s))
Сохраним описанный модуль и протестируем его. Сначала в качестве четырёхугольника зададим квадрат со стороной, равной 5. Его площадь действительно равна 25. Снова запустим программу на выполнение и зададим четырёхугольник с длинами сторон: 3, 4, 12 и 13. Очевидно, что площадь первого треугольника равна 6, а его гипотенуза – 5. По формуле Герона площадь второго треугольника равна 30. Значит площадь четырёхугольника равна 36. Программа вывела сообщение об этом, это значит, что она работает верно и задача решена.
Мы узнали:
· Решение любой задачи с помощью компьютера состоит из пяти этапов: постановка задачи, её формализация, создание алгоритма, программирование, тестирование и отладка.
· Если
алгоритм решения задачи сложно придумать сразу, то для этого можно использовать
метод последовательного конструирования алгоритма, где задача
разбивается на несколько более простых подзадач, каждая из которых также может
делиться на подзадачи. Так происходит до тех пор, пока нам не станет понятно,
каким образом решить все подзадачи. После этого решения всех подзадач
соединяются воедино, образуя алгоритм решения исходной задачи.
Так происходит до тех пор, пока нам не станет понятно,
каким образом решить все подзадачи. После этого решения всех подзадач
соединяются воедино, образуя алгоритм решения исходной задачи.
Алгоритмизация платежей. Как алгоритмы изменят… | Дуэйн Джеффери
Как алгоритмы изменят индустрию платежей
Алгоритмы…Не так давно генеральные директора и крупные банки были убеждены, что для обслуживания их клиентов всегда будут необходимы банковские отделения. Однако за последние десять лет мы стали свидетелями появления цифровых банков, которые никогда не имели и, вероятно, никогда не будут владеть физическим местоположением, но тем не менее смогли расширить свою пользовательскую базу и добавить дополнительные услуги, включая страхование, ипотеку и кредиты.
В индустрии платежей уже более сорока лет доминируют такие компании, как Chase и First Data. Однако точно так же, как оцифровка банковского дела вынудила действующих операторов изменить свои стратегии, оцифровка платежей позволила таким компаниям, как WorldPay, Vantiv, а в последнее время даже Stripe, PayPal/Braintree и Adyen занять большую часть рынка, не сосредоточившись на традиционных бизнеса, но сосредоточив внимание на стартапах, которые затмили, а иногда даже обанкротили традиционные предприятия. Подумайте о Blockbuster и Netflix, Taxi и Uber, традиционных магазинах и Amazon.
Подумайте о Blockbuster и Netflix, Taxi и Uber, традиционных магазинах и Amazon.
Но по мере того, как все больше и больше компаний понимают, что цифровые технологии — это новая традиция, я часто задаюсь вопросом, что будет дальше с индустрией платежей?
Точно так же, как компании, которые были открыты для внедрения компьютеров и баз данных в 1970-х и 1980-х, или компании, которые поняли, что Интернет изменит правила игры еще в 1990-х и после того, как пузырь доткомов лопнул в 2000-х, я верю что компании, которые понимают, что алгоритмизация изменит отрасли, и активно инвестируют в нее, скорее всего, выживут из 2010-х и 2020-х годов.
Оцифровка процессов
Чтобы понять, что такое алгоритмизация, нам нужно сделать два шага назад к традиционным бизнес-процессам. В течение сотен лет традиционные бизнес-процессы состояли из труда людей, создающих продукты или предоставляющих услуги, и поддерживающих бизнес-процессов, которые их сопровождали.
Например, у врача, оказывающего медицинские услуги, есть рабочие часы, когда пациенты могут прийти или записаться на прием. Традиционно процесс регистрации пациентов, обновления их файлов или выписки рецепта выполнялся от руки на бумаге. С оцифровкой этих процессов в кабинете врача появились компьютеры, файлы хранились в цифровом виде, встречи записывались в цифровом календаре, а рецепты отправлялись фармацевту по электронной почте.
Даже по сей день компании все еще улучшают оцифровку процессов, разрабатывая мобильные приложения или предоставляя клиентам облачные решения для лучшего доступа или хранения данных, полученных из реальных бизнес-процессов.
Алгоритмизация
Когда мы говорим об алгоритмизации, мы говорим о процессе использования оцифрованных помеченных данных, которые хранятся в виде набора данных в базе данных, и использовании автоматизированных процессов для создания аналитики, из которой пользователи могут получать информацию. Процесс, через который большинство компаний уже прошли, но это только первые шаги в алгоритмизации. Всякий раз, когда набор данных (N) можно использовать для создания аналитики, из которой пользователи извлекают информацию, следующим шагом будет использование машинного обучения и искусственного интеллекта для создания нового процесса (N=N+1), который сам по себе обеспечивает новый процесс. Набор данных завершает цикл алгоритмизации.
Всякий раз, когда набор данных (N) можно использовать для создания аналитики, из которой пользователи извлекают информацию, следующим шагом будет использование машинного обучения и искусственного интеллекта для создания нового процесса (N=N+1), который сам по себе обеспечивает новый процесс. Набор данных завершает цикл алгоритмизации.
Пример поставщика платежных услуг
Для иллюстрации представьте поставщика платежных услуг, который обрабатывает миллионы транзакций в день. Каждая транзакция, отправленная продавцом, содержит связанную с транзакцией информацию, такую как PAN (номер личного счета), CVC (код подтверждения карты), дату истечения срока действия, имя клиента и адрес электронной почты. Через браузер PSP может собирать дополнительные данные, такие как дата и время, отпечаток пальца устройства, тип и версия браузера, IP-адрес и некоторые другие точки данных (N).
По мере обработки транзакции сохраняются в базе данных. Большинство PSP будут использовать эти данные для предоставления своим продавцам стандартного отчета о транзакциях за определенный день. Некоторые могут даже дойти до агрегирования данных, чтобы предоставить сводку данных. Если они хотят быть действительно модными, они разрабатывают информационные панели и графики, доступные через пользовательский интерфейс, чтобы показать, как транзакции продвигаются с течением времени.
Некоторые могут даже дойти до агрегирования данных, чтобы предоставить сводку данных. Если они хотят быть действительно модными, они разрабатывают информационные панели и графики, доступные через пользовательский интерфейс, чтобы показать, как транзакции продвигаются с течением времени.
Благодаря достижениям в области вычислительной мощности, облачных вычислений и технологий распределенного хранения многие компании, включая PSP, экспериментируют со способами улучшения существующих процессов. Так, например, упомянутый выше PSP может решить изучить, может ли большой набор исторических данных помочь им предотвратить мошенничество с входящими транзакциями. Используя машинное обучение и искусственный интеллект, специалисты по данным могут создать алгоритм, способный использовать множество переменных, являющихся частью транзакций, и прогнозировать вероятность того, что вновь отправленная транзакция будет мошеннической.
Преимущество карточных платежей в том, что держатели карт могут оспаривать транзакции в течение определенного периода времени. Всякий раз, когда сообщается о мошеннической транзакции, эмитент отправляет в схему сообщение о возврате транзакции. Всякий раз, когда PSP получает эту информацию, они также могут хранить ее в своей базе данных. Это дает им возможность узнать точность своего первоначального прогноза. Используя искусственный интеллект, они могли адаптировать исходный алгоритм для улучшения оценки, увеличивая или уменьшая веса, присваиваемые переменным, учитываемым алгоритмом, фактически создавая новый процесс (N=N+1).
Всякий раз, когда сообщается о мошеннической транзакции, эмитент отправляет в схему сообщение о возврате транзакции. Всякий раз, когда PSP получает эту информацию, они также могут хранить ее в своей базе данных. Это дает им возможность узнать точность своего первоначального прогноза. Используя искусственный интеллект, они могли адаптировать исходный алгоритм для улучшения оценки, увеличивая или уменьшая веса, присваиваемые переменным, учитываемым алгоритмом, фактически создавая новый процесс (N=N+1).
Как алгоритмизация повлияет на платежи?
Приведенный выше пример был лишь одним из вариантов использования алгоритмизации для улучшения существующих процессов. Самое забавное в приведенном выше примере то, что именно так многие решения для борьбы с мошенничеством решали эту проблему на протяжении многих лет. однако и мошенники стали умнее, а значит мошенничество все же происходит.
Платежи — это гораздо больше, чем просто предотвращение мошенничества. Затраты, конверсия, подключение, выставление счетов и выплаты — вот некоторые из областей, в которых новые PSP могут использовать алгоритмизацию, чтобы изменить ситуацию. Поскольку все больше и больше компаний привыкают к коммерциализации PSP, единственный способ оставаться успешным в качестве PSP — это не сосредоточиться на борьбе с мошенничеством или снижении стоимости каждой транзакции, а показать ценность PSP, которая способна генерировать вам больше бизнеса.
Поскольку все больше и больше компаний привыкают к коммерциализации PSP, единственный способ оставаться успешным в качестве PSP — это не сосредоточиться на борьбе с мошенничеством или снижении стоимости каждой транзакции, а показать ценность PSP, которая способна генерировать вам больше бизнеса.
Причина, по которой продавцов ценят больше, чем финансовый отдел, заключается в том, что получение большего дохода равнозначно росту, а снижение затрат может увеличить прибыль, но не увеличить доход.
Интеллектуальная маршрутизация эквайринга
Те же транзакционные данные могут использоваться для оптимизации маршрута эквайринга на основе производительности, функциональности или цены. Отличным способом является реализация алгоритма многоруких бандитов, который представляет собой «умную» или более сложную версию A/B-тестирования, использующую алгоритмы машинного обучения для динамического распределения трафика между вариантами, которые работают хорошо, при этом выделяя меньше трафика вариантам, которые работают хуже. неэффективны. Подключив несколько эквайеров, PSP могут улучшить результаты своих продавцов, направляя транзакции эквайеру, который обеспечивает им наилучший результат для этого продавца, будь то производительность, цена или функциональность.
неэффективны. Подключив несколько эквайеров, PSP могут улучшить результаты своих продавцов, направляя транзакции эквайеру, который обеспечивает им наилучший результат для этого продавца, будь то производительность, цена или функциональность.
Dynamic 3D Secure
С дополнительными мерами двухэтапной проверки, такими как Verified by Visa или 3DSecure от Mastercard, многие PSP по-прежнему сталкиваются с высокими показателями отказов из-за того, что эмитенты требуют обязательной двухэтапной проверки транзакций. Используя обучение дереву принятия решений, поставщики услуг могут прогнозировать, нужно ли перенаправлять транзакцию на страницу 3DSecure для дополнительной двухэтапной проверки или переход к традиционному потоку приведет к успешной транзакции.
Не ограничивайтесь чужим воображением
Конечно, существует много других способов использования транзакционных данных, доступных в платежах, для повышения эффективности продавца. Это будут PSP, которые смогут брать одни и те же данные, которые генерировались десятилетиями, и думать, как они могут улучшить процессы, используя инструменты, доступные им сегодня, чтобы создать PSP, который лучше подходит для продавцов и бизнес-моделей, которые не еще даже не существует.
Спасибо за прочтение 😉 , если вам понравилось, нажмите кнопку аплодисментов ниже, это будет много значить для меня, и это поможет другим увидеть историю. Дайте мне знать, что вы думаете, связавшись с Twitter или Linkedin.
Жизненный цикл проекта машинного обучения: какие этапы?
Что такое машинное обучение и его жизненный цикл? Вы получите разные ответы от разных людей.
- Программисты могут сказать, что речь идет о программировании на Python и сложных математических алгоритмах.
- Заинтересованные лица бизнеса обычно связывают машинное обучение с данными и примесью тайны.
- Инженеры по машинному обучению обычно говорят об обучении моделей и обработке данных.
Так кто же прав? Каждый.
Машинное обучение основано на данных — никакой лжи. Нет машинного обучения без приличного количества данных, на которых машина может учиться. Объем доступных данных растет в геометрической прогрессии, что делает разработку машинного обучения проще, чем когда-либо.
Связь между машинным обучением и алгоритмами также актуальна. Действительно, существуют сложные математические методы, которые заставляют машины учиться. Нет математики — нет машинного обучения.
Наконец, обучение модели и подготовка данных действительно являются основой каждого проекта машинного обучения. Инженеры по машинному обучению тратят значительное количество времени на обучение моделей и подготовку наборов данных. Вот почему это первое, о чем думают инженеры машинного обучения.
Машинное обучение — это разработка, обработка данных и моделирование. Все эти отдельные части вместе образуют жизненный цикл проекта машинного обучения , и именно об этом мы поговорим в этой статье.
Высокоуровневое представление жизненного цикла машинного обучения
Жизненный цикл проекта машинного обучения можно представить как многокомпонентный поток, где каждый последующий шаг влияет на остальную часть потока. Давайте посмотрим на шаги в потоке на очень высоком уровне:
- Понимание проблемы (также известное как понимание бизнеса).

- Сбор данных.
- Аннотация данных.
- Обработка данных.
- Разработка моделей, обучение и оценка.
- Развертывание и обслуживание модели в производственной среде.
Как видите, весь цикл состоит из 6 последовательных шагов. Каждый шаг уникален, со своей природой. Эти различия приводят к различиям в ресурсах, времени и членах команды, необходимых для выполнения каждого шага. Давайте подробно рассмотрим каждый компонент в жизненном цикле и посмотрим, что это такое.
Узнать больше
Лучшие инструменты для управления проектами машинного обучения
Жизненный цикл машинного обучения в деталях
Шаг 1. Понимание проблемы
Каждый проект начинается с проблемы, которую нужно решить. В идеале четкое определение проблемы должно быть численно описано. Числа не только дают возможность узнать, где находится ваша отправная точка, но и позволяют отслеживать эффект от изменений позже.
Например, в компании, где я работаю, есть расчеты, которые показывают, сколько каждая ручная операция обходится бизнесу. Этот подход помогает нам стратифицировать наши операции и расставлять приоритеты в зависимости от того, сколько нам нужно потратить.
Этот подход помогает нам стратифицировать наши операции и расставлять приоритеты в зависимости от того, сколько нам нужно потратить.
Наше руководство недавно запустило новый проект по машинному обучению, целью которого является автоматизация конкретной ручной операции, которая в настоящее время занимает первое место в нашем списке расходов. Команда также провела исследование, сравнив затраты на эту операцию с нашими конкурентами.
Результат оказался неутешительным: аналогичные ручные операции до 20% дешевле для других компаний нашей отрасли. Чтобы успешно конкурировать на рынке, мы должны снизить наши затраты. Именно поэтому мы запустили проект автоматизации.
Это все, что нужно для решения нашей проблемы? Не совсем. Знание затрат не означает, что мы можем передать эту проблему нашей команде машинного обучения и ожидать, что они решат ее.
До сих пор мы только определяли проблему с точки зрения бизнеса. Прежде чем произойдет какое-либо машинное обучение, нам нужно перейти от денежных единиц к другим ключевым показателям эффективности, понятным нашей команде машинного обучения.
См. также
Как создавать команды машинного обучения, которые работают
Для этого наше руководство выяснило, что если мы хотим снизить затраты на данную ручную операцию на 20 %, мы должны уменьшить количество ручных операций со 100 % как минимум до 70 %. Это означает, что 30% всех операций должны выполняться автоматически. Знание этого может помочь нам сузить рамки проекта, позволяя нам понять, что нам нужно сосредоточиться только на части проблемы, а не на всей проблеме.
Затем ручная операция, на которую мы хотели ориентироваться, была разложена на части. Зная, сколько стоит каждая часть с точки зрения времени (и денег), команда смогла составить список предложений по задачам, которые можно было бы автоматизировать.
Обсуждая этот список с командой машинного обучения, они выбрали несколько задач, которые можно решить с помощью контролируемых алгоритмов машинного обучения, если доступны соответствующие данные.
Наконец, понимание проблемы завершено : каждая команда в компании знает, на что они нацелены и почему. Проект можно начинать.
Проект можно начинать.
Этап 2: Сбор данных
Данные — это сила. Когда проблема ясна и установлен соответствующий подход к машинному обучению, пришло время собирать данные.
Данные могут поступать из нескольких источников. У вас может быть внутренняя база данных, которую можно запросить для получения соответствующих данных. Вы можете попросить инженеров данных извлечь данные для вас или использовать существующие сервисы, такие как Amazon Mturk, или, возможно, сделать это самостоятельно.
Другие получают данные от своих клиентов. Обычно это происходит, когда вы работаете над проблемой клиента бок о бок. Клиент заинтересован в конечном результате и готов поделиться активами данных.
Еще один вариант, который стоит рассмотреть, — покупка данных у сторонних поставщиков. Хороший пример — Nielsen Media Research. Основное внимание уделяется рынку FMCG (товары повседневного спроса). Они проводят множество исследований, собирая данные с разных рыночных групп. Компании, которые продают быстрорастущие потребительские товары, всегда изучают своих клиентов и их предпочтения, чтобы использовать новые тенденции для получения прибыли. Сторонние поставщики, такие как NMR, могут быть отличным источником ценных данных.
Компании, которые продают быстрорастущие потребительские товары, всегда изучают своих клиентов и их предпочтения, чтобы использовать новые тенденции для получения прибыли. Сторонние поставщики, такие как NMR, могут быть отличным источником ценных данных.
Существуют также наборы данных с открытым исходным кодом. Они особенно удобны, если вы работаете над общей проблемой, которая может возникнуть во многих компаниях и отраслях. Велика вероятность того, что нужный вам набор данных уже есть где-то в Интернете. Некоторые наборы данных поступают от государственных организаций, некоторые — от государственных компаний и университетов.
Что еще круче, общедоступные наборы данных обычно сопровождаются аннотациями (если применимо), поэтому вы и ваша команда можете избежать выполнения ручных операций, которые занимают значительное количество времени и средств проекта. Считайте эти статьи руководством, которое поможет вам найти подходящий общедоступный набор данных для вашего проекта:
- Лучшие общедоступные наборы данных для машинного обучения и науки о данных: источники и советы по выбору.

- Где найти лучшие наборы данных для машинного обучения.
- 25 отличных открытых наборов данных для машинного обучения.
Ваша цель — собрать как можно больше важных данных. Обычно это подразумевает получение данных за большой промежуток времени, если мы говорим о табличных данных. Помните: чем больше у вас будет образцов, тем лучше будет ваша будущая модель.
Позже в жизненном цикле вы пройдете этап подготовки данных, который может значительно уменьшить количество выборок в вашем наборе данных (чуть позже я объясню почему). Поэтому крайне важно сейчас, в самом начале жизненного цикла проекта, накопить как можно больше данных.
Если вы собрали недостаточно, у вас есть два альтернативных варианта:
- Расширение данных
Расширение данных внесет дополнительные изменения в существующий набор данных, улучшая обобщение модели. На самом деле он не добавляет больше сэмплов, он просто манипулирует текущими данными, чтобы извлечь из них максимальную пользу.
По личному опыту могу сказать, что вам следует внимательно отнестись к типам аугментации данных, которые вы применяете. Вам нужно только искать дополнение, отражающее реальную производственную среду, в которой будет использоваться модель. Нет необходимости «учить» модель быть готовой к случаям, которые, как вы точно знаете, никогда не произойдут в реальной жизни. Позже в этой статье мы рассмотрим исследовательский анализ данных (EDA), который может показать, с какими данными вы работаете и какой тип дополнения подходит.
- Генерация синтетических данных
С другой стороны, наборы синтетических данных — это новые выборки, которые можно использовать в качестве входных данных для вашей модели. Это совершенно новые данные, которые вы можете генерировать искусственно, используя либо неконтролируемое глубокое обучение (например, генеративно-состязательные сети), либо библиотеки, работающие с изображениями (например, в Python вы можете подумать об OpenCV или PIL).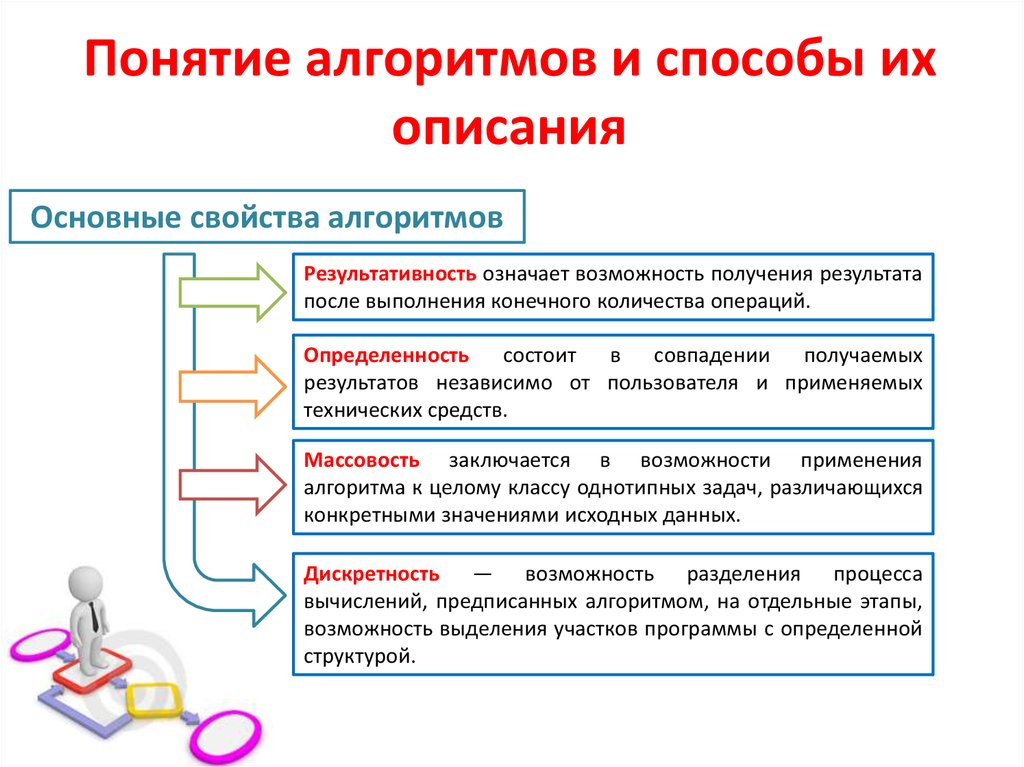
Генеративно-состязательные сети (GAN) генерируют новые примеры из существующих. В качестве отличного примера можно привести индустрию компьютерного зрения, где инженеры используют этот тип архитектуры для создания новых уникальных изображений из существующих, обычно небольших, наборов данных. Лично я могу сказать, что изображения, сгенерированные GAN, довольно хороши по качеству и весьма полезны для аннотирования (шаг 4 жизненного цикла проекта ML) и дальнейшего обучения нейронной сети (шаг 5 жизненного цикла).
Этап 3: Подготовка данных
Собранные данные беспорядочны. Есть много проблем, с которыми сталкиваются инженеры по машинному обучению при работе с необработанными данными. Вот наиболее распространенные проблемы:
- Соответствующие данные должны быть отфильтрованы. Нерелевантные данные должны быть очищены;
- Шумовые, ошибочные и ошибочные выборки должны быть идентифицированы и удалены;
- Выбросы должны быть распознаны и устранены;
- Отсутствующие значения должны быть обнаружены и либо удалены, либо заменены надлежащими методами;
- Данные должны быть преобразованы в соответствующие форматы.

Как видите, инженер по машинному обучению может столкнуться с множеством проблем при работе с необработанными данными. Каждый набор данных уникален с точки зрения проблем, которые он приносит. Не существует эмпирического правила о том, как подходить к предварительной обработке данных. Этот процесс творческий и многогранный.
Рассмотрим пропущенные значения. Это довольно распространенная проблема, которая есть у большинства наборов данных. Инженеры машинного обучения могут просто отбросить эти значения и работать только с действительными записями в наборе данных.
В качестве альтернативы вы можете использовать вменение и заполнить записи NaN. Ищете эмпирическое правило снова? К сожалению, здесь тоже нет. Вменение может быть выполнено несколькими способами на основе различных выбранных вами критериев. Математические алгоритмы вменения также различаются, и снова у вас есть несколько вариантов для рассмотрения.
Создание новых функций из существующих — еще один вариант, который следует рассмотреть инженерам по машинному обучению. Этот процесс называется инженерией данных. Отличным примером инженерии данных, который я лично использую довольно часто, является уменьшение размерности с помощью анализа главных компонентов (PCA). PCA уменьшает количество признаков в наборе данных, оставляя только те из них, которые наиболее ценны для будущего принятия решений.
Этот процесс называется инженерией данных. Отличным примером инженерии данных, который я лично использую довольно часто, является уменьшение размерности с помощью анализа главных компонентов (PCA). PCA уменьшает количество признаков в наборе данных, оставляя только те из них, которые наиболее ценны для будущего принятия решений.
Как только вы закончите основную часть подготовки данных, вы можете перейти к обработке данных. Предварительная обработка данных — это шаг, который делает ваши данные пригодными для обработки нейронной сетью или алгоритмом, который вы обучаете. Обычно это подразумевает нормализацию данных, стандартизацию и масштабирование.
Статья по теме
Подробное руководство по предварительной обработке данных
Как правило, этап подготовки данных сопровождается исследовательским анализом данных (EDA), который дополняет общий процесс подготовки. EDA помогает инженерам ознакомиться с данными, с которыми они работают. Обычно это подразумевает построение некоторых графиков, которые могут помочь с данными с разных точек зрения.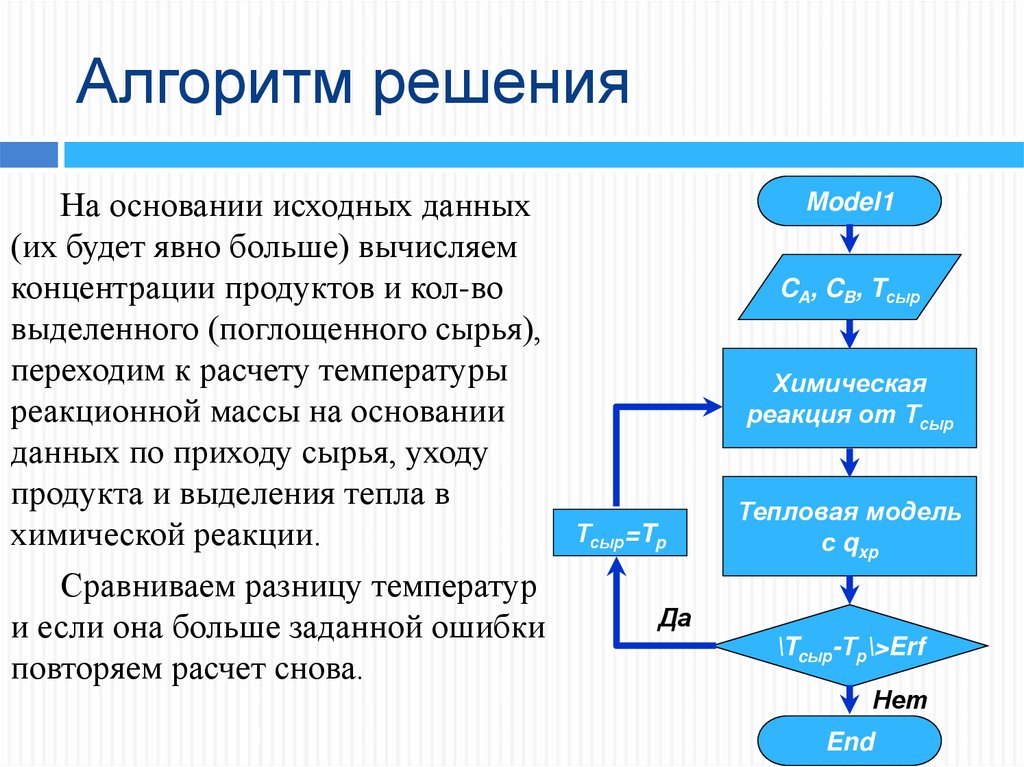 Интуиция, которую инженеры получают от такого анализа, помогает в дальнейшем в поиске правильных методов и инструментов для подготовки данных, выбора архитектуры/алгоритмов модели (шаг 5.2 жизненного цикла ML-проекта) и, конечно же, правильного выбора метрик (шаг 5.4 жизненный цикл проекта).
Интуиция, которую инженеры получают от такого анализа, помогает в дальнейшем в поиске правильных методов и инструментов для подготовки данных, выбора архитектуры/алгоритмов модели (шаг 5.2 жизненного цикла ML-проекта) и, конечно же, правильного выбора метрик (шаг 5.4 жизненный цикл проекта).
Подготовка данных (также известная как обработка данных) — один из наиболее трудоемких шагов, но один из самых важных, поскольку он напрямую влияет на качество данных, которые будут отправлены в сеть.
Я обычно заканчиваю этап предварительной обработки данных, разделяя обработанные данные на три отдельных подмножества: данные для обучения, проверки и тестирования. Для небольших наборов данных я выделяю не более 30 % и на валидацию, и на тестирование, выделяя остальные данные на обучение. Для больших наборов данных (более 10 тыс., я инженер по компьютерному зрению, поэтому работаю с изображениями) моя личная практика привела меня к следующему коэффициенту разделения:
- 10 % на тесты,
- 10 % на проверку во время обучения,
- 80 % на обучение.

Стратегия разделения, которую я настоятельно рекомендую, — это стратифицированное разделение, которое помогает поддерживать равные пропорции классов в каждом наборе данных. Это важно для правильной оценки производительности.
Шаг 4. Аннотации к данным
Если ваша работа относится к области контролируемого обучения, вам потребуется метка для каждого образца в вашем наборе данных. Процесс присвоения меток образцам данных называется аннотацией данных или маркировкой данных.
Аннотирование данных — это ручная операция, занимающая довольно много времени и довольно часто выполняемая третьими лицами. Редкий случай, когда над маркировкой работают сами инженеры по машинному обучению. Учитывая тот факт, что вы и ваша команда, скорее всего, не будете заниматься процессом аннотирования самостоятельно, ваша главная цель на этом этапе — разработать всеобъемлющее руководство по аннотированию.
Инструкции помогут комментаторам узнать, что делать. Вот почему крайне важно разработать всестороннее руководство, которое будет охватывать наиболее важные аспекты работы с аннотациями. Не забывайте о крайних случаях, которые могут возникнуть во время маркировки. Ваша команда аннотаторов должна быть готова к каждому возможному сценарию, с которым они могут столкнуться. В работе аннотации нет места предположениям. Все должно быть четко и прозрачно. Вы также должны назначить человека, который будет помогать команде аннотаций. Если вы не можете обработать конкретный пример, аннотаторы должны знать, к кому обращаться для решения своих вопросов.
Не забывайте о крайних случаях, которые могут возникнуть во время маркировки. Ваша команда аннотаторов должна быть готова к каждому возможному сценарию, с которым они могут столкнуться. В работе аннотации нет места предположениям. Все должно быть четко и прозрачно. Вы также должны назначить человека, который будет помогать команде аннотаций. Если вы не можете обработать конкретный пример, аннотаторы должны знать, к кому обращаться для решения своих вопросов.
Может вас заинтересовать
Руководство по глубокому обучению: выбор инструмента для аннотирования данных
Существует несколько замечательных примеров, которые можно использовать для создания собственных руководств по аннотированию. Подумайте о том, чтобы прочитать эту исследовательскую статью, если вам интересно, как аннотации могут повлиять на общий жизненный цикл машинного обучения. Имейте в виду, что качество ваших аннотаций данных напрямую влияет на то, как будет работать ваша конечная модель. Не ограничивайте время работы над рекомендациями по аннотации. Сделайте его простым в использовании и достаточно подробным. Примеры всегда полезны и обычно очень приветствуются комментаторами. Время, затрачиваемое на аннотацию руководств, — это инвестиции в качество конечного результата.
Сделайте его простым в использовании и достаточно подробным. Примеры всегда полезны и обычно очень приветствуются комментаторами. Время, затрачиваемое на аннотацию руководств, — это инвестиции в качество конечного результата.
Шаг 5: Моделирование
К этому шагу у вас должен быть полный набор данных, готовый для ввода в модель. Что дальше? Пришло время принять решение о будущей модели, и собрать ее.
5.1. Попробуйте решить свою проблему с помощью трансферного обучения
Инженеры по машинному обучению не создают модели с нуля. Они, как правило, повторно используют модели, которые уже показали достойную производительность на больших общедоступных наборах данных. Эти предварительно обученные модели можно использовать для точной настройки. Этот подход получил широкое распространение в глубоком обучении. Например, в компьютерном зрении точная настройка работает хорошо, потому что функции низкого уровня, которые извлекают CNN, унифицированы для широкого круга задач.
Места, где вы можете найти общедоступные предварительно обученные модели, называются модельными зоопарками. Github — отличный источник предварительно обученных моделей с сотнями доступных вариантов. Вам просто нужно найти модель данной архитектуры и фреймворка, с которыми вы работаете.
Например, TensorFlow — это платформа машинного обучения, которая предоставляет возможность импортировать предварительно обученные модели. Вот пример зоопарка с моделями обнаружения, созданный TensorFlow. Эти модели можно использовать для трансферного обучения в компьютерном зрении.
Вы всегда должны искать предварительно обученную модель для своего проекта, чтобы начать работу с ней. Это сэкономит ваше время, вычислительные ресурсы и даже улучшит качество конечного результата.
5.2. Настройте архитектуру модели соответствующим образом
Важно отметить, что предварительно обученную модель, которую мы импортируем, необходимо изменить, чтобы она отражала конкретную задачу, которую мы выполняем.
Если вы занимаетесь компьютерным зрением, вы, вероятно, помните, что количество классов, которые может идентифицировать классификационная модель, зависит от верхней части архитектуры модели. В последнем плотном слое должно быть количество единиц, равное количеству классов, которые вы хотите различать. Ваша задача — подготовить окончательный проект архитектуры модели, соответствующий вашим целям.
5.3. Много экспериментируйте
Инженеры по машинному обучению склонны много экспериментировать. Мы любим экспериментировать с несколькими конфигурациями моделей, архитектурами и параметрами. Вероятно, вы не примете полученный базовый результат и не перенесете его в производство. Такой исход редко становится наилучшим из возможных. Итеративный процесс обучения для поиска наилучшей конфигурации модели является обычной практикой среди инженеров по машинному обучению.
На этом этапе вы должны попробовать несколько альтернативных гипотез, которые потенциально могут работать для вашей задачи.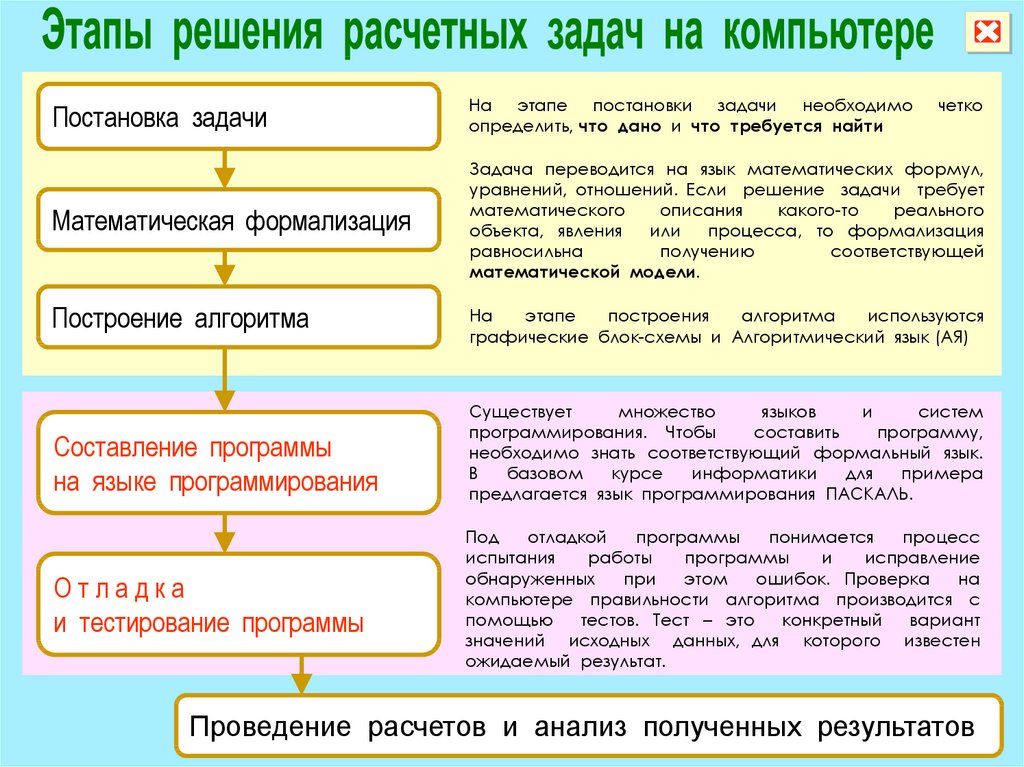 Чтобы сузить список возможных вариантов, вы можете рассмотреть возможность использования методов настройки гиперпараметров, которые предоставляет большинство платформ машинного обучения. Эти методы оценивают производительность для нескольких конфигураций, сравнивают их и позволяют узнать о наиболее эффективных из них. Вам просто нужно указать значения и параметры для выборки.
Чтобы сузить список возможных вариантов, вы можете рассмотреть возможность использования методов настройки гиперпараметров, которые предоставляет большинство платформ машинного обучения. Эти методы оценивают производительность для нескольких конфигураций, сравнивают их и позволяют узнать о наиболее эффективных из них. Вам просто нужно указать значения и параметры для выборки.
Эксперименты — это то, чем мы занимаемся. Если ваши вычислительные ресурсы не ограничены, вы обязательно должны воспользоваться этим. Результаты, которые вы можете получить, могут быть весьма неожиданными. Кто знает, может быть, в результате одного из ваших экспериментов появится новая современная конфигурация модели.
Может быть полезно
Если вы проводите много экспериментов, проверьте, как вы можете их хорошо отслеживать и организовывать.
5.4. Правильно оценивайте
Оценка всегда сопровождается проведением экспериментов. Вам нужно знать, как ведет себя каждая модель, чтобы выбрать самую эффективную. Для сравнения моделей необходимо определить набор показателей.
Для сравнения моделей необходимо определить набор показателей.
В зависимости от проблемы, над которой вы работаете, ваш набор показателей будет отличаться. Например, для задач регрессии мы обычно смотрим на MSE или MAE. С другой стороны, для оценки модели классификации точность может быть хорошим выбором для сбалансированного набора данных. Несбалансированные наборы требуют более сложных метрик. Оценка F1 является хорошей метрикой для таких случаев.
Оценка во время обучения выполняется на отдельном наборе данных проверки. Он отслеживает, насколько хороша наша модель в обобщении, избегая возможной систематической ошибки и переобучения.
Всегда рекомендуется визуализировать прогресс модели во время обучения. Tensorboard — это первый и самый простой вариант для рассмотрения. Кроме того, Neptune.ai — это более продвинутый инструмент, который визуализирует производительность модели с течением времени, а также отслеживает эксперименты. Важно иметь правильный инструмент.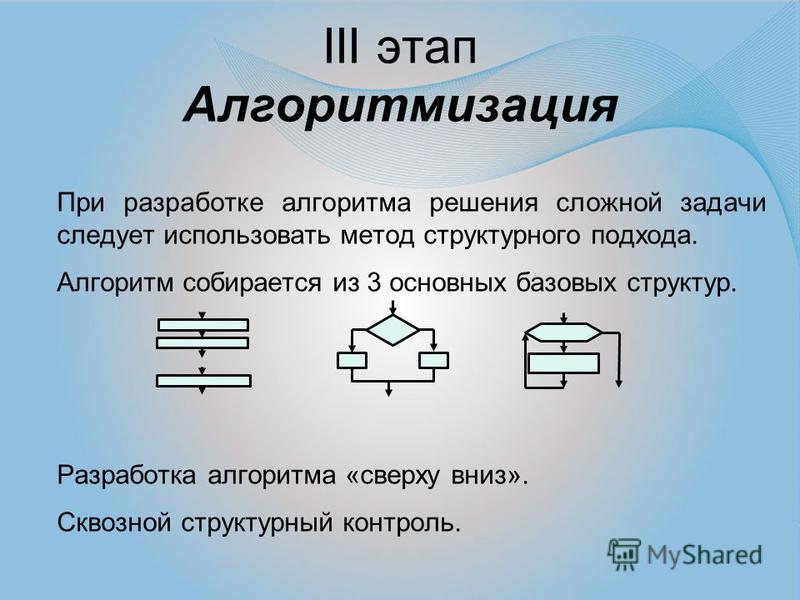 Не торопитесь, чтобы найти инструмент отслеживания экспериментов, который соответствует вашим конкретным потребностям. Вы сэкономите массу времени и улучшите общий рабочий процесс, когда получите его.
Не торопитесь, чтобы найти инструмент отслеживания экспериментов, который соответствует вашим конкретным потребностям. Вы сэкономите массу времени и улучшите общий рабочий процесс, когда получите его.
Шаг 6. Развертывание модели
Отлично! У вас есть блестящая модель, готовая к запуску в производство. Теперь инженеры развертывают модель поезда и делают ее доступной для внешних запросов на вывод.
Это последний шаг в жизненном цикле машинного обучения. Но работа далека от завершения, мы не можем просто расслабиться и ждать новый проект.
Развернутые модели нуждаются в мониторинге . Вам необходимо отслеживать производительность развернутой модели, чтобы убедиться, что она продолжает выполнять работу с качеством, которое требуется бизнесу. Все мы знаем о каком-то негативном эффекте, который может произойти со временем: деградация модели — один из самых распространенных.
Другой хорошей практикой является сбор образцов, которые были неправильно обработаны моделью, чтобы выяснить основные причины, по которым это произошло, и использовать их для повторного обучения модели, чтобы сделать ее более устойчивой к таким образцам. Такое небольшое непрерывное исследование поможет вам лучше понять возможные пограничные случаи и другие неожиданные события, к которым ваша текущая модель не готова.
Такое небольшое непрерывное исследование поможет вам лучше понять возможные пограничные случаи и другие неожиданные события, к которым ваша текущая модель не готова.
Выводы
К этому моменту у вас должно быть четкое представление обо всем жизненном цикле проекта машинного обучения. Позвольте мне еще раз подчеркнуть, что каждый последующий шаг в цикле может резко повлиять на последующие шаги, как в положительную, так и в отрицательную сторону. Очень важно тщательно выполнять каждый шаг .
Моя личная практика показала, что шаг № 2 (сбор данных), шаг № 3 (подготовка данных) и шаг № 4 (аннотация данных) требуют больше всего времени .
Качество данных, которые входят в вашу модель, является ключевым фактором хорошей модели. Не пренебрегайте этими шагами и всегда вкладывайте в них достаточно времени и ресурсов.
ЧИТАТЬ ДАЛЕЕ
MLOps: что это такое, почему это важно и как это реализовать
13 минут чтения | Принц Канума | Опубликовано 14 января 2021 г.
По данным techjury, в 2020 году каждый человек создавал не менее 1,7 МБ данных в секунду. Для специалистов по данным, таких как вы и я, это похоже на раннее Рождество, потому что есть так много теорий / идей для изучения, экспериментов. предстоит сделать множество открытий и разработать модели.
Но если мы хотим быть серьезными и действительно хотим, чтобы эти модели затрагивали реальные бизнес-проблемы и реальных людей, мы должны иметь дело с такими основами, как:
- сбор и очистка больших объемов данных;
- настройка отслеживания и управления версиями для экспериментов и прогонов обучения модели;
- настройка конвейеров развертывания и мониторинга для моделей, которые попадают в рабочую среду.
И нам нужно найти способ масштабировать наши операции машинного обучения в соответствии с потребностями бизнеса и/или пользователей наших моделей машинного обучения.
В прошлом возникали похожие проблемы, когда нам нужно было масштабировать обычные программные системы, чтобы ими могли пользоваться больше людей.