Иллюстрированный самоучитель по введению в экспертные системы › Рассуждения, основанные на прецедентах › База прецедентов [страница — 312] | Самоучители по программированию
База прецедентов
Приведенная выше аналогия с библиотекой удобна, но является далеко не полной. Прецеденты – это не книги; хотя их и связывают с книгами некоторые общие абстрактные свойства, имеются и существенные отличия.
- Прецеденты напоминают книги (конечно же, не из разряда беллетристики) тем, что содержат определенную специфическую информацию, «вставленную» в некоторый контекст. Содержимое прецедента – это знание, а контекст описывает некоторое состояние внешнего мира, в котором это знание применяется. Однако прецедент содержит знание в такой форме, которая может быть воспринята программой. Другими словами, знания, содержащиеся в описании прецедента, «готовы к употреблению» в том же смысле, в каком порождающие правила готовы к применению.
- Прецедент должен представлять решение проблемы в определенном контексте и описывать то состояние мира, которое получится, если будет принято предлагаемое в нем решение. Это свойство часто можно встретить и в содержимом книг, но, опять же, разница состоит в том, что информация не представлена в форме, удобной для восприятия программой.
- Хотя описания прецедентов и варьируются по размеру, они все-таки значительно уступают книгам в этом смысле. Информация в описаниях прецедентов значительно более сжата и представляется на каком-либо формальном языке.
Если прецедент – это модуль знаний, который может быть считан программой, то в чем его отличие от других способов представления знаний, множество которых мы уже рассмотрели в этой книге? Самый короткий ответ на этот вопрос – прецедент, как правило, реализуется в виде фрейма (см. главу 6), в котором структурированы информация о проблеме, решение и контекст.
Так же, как фрейм или порождающее правило, описание прецедента может быть сопоставлено с данными или описанием цели. Но для извлечения описания прецедента из базы таких описаний используется совсем другой механизм, чем для извлечения фрейма или порождающего правила. Первое, что делается в процессе применения прецедента, – его адаптируют к текущей ситуации. Поэтому поиск описания прецедента требует использования достаточно сложного механизма индексирования.
samoychiteli.ru
Исследование вывода на основе прецедентов для базы знаний в среде JENA
Постоянный рост информации, низкая интероперабельность систем предъявляют более жесткие требования к информационным технологиям. На сегодняшний день большая часть информации в интернете представлена в непригодном для машинной обработки виде. Даже информация, полученная из структурированных баз данных, не определена достаточно для того, чтобы иметь возможность понимать и использовать ее машинами. Для решения этих проблем было предложено вести обработку информации на семантическом уровне. Semantic web является видением будущего Web. В этом видении машина выдает более точные значения, которые позволяют выполнять интеграцию, обработку и понимание информации в интернете.
Важнейшим компонентом Semantic web, позволяющим представлять в явно выраженном виде знания о предметной области, являются онтологии. Более того, онтологии определяют отношения между понятиями, что позволяет создавать программы, учитывающие семантику этих отношений [5].
Консорциум всемирной паутины (W3C) определил некоторые стандарты и языки, такие как RDF (Resource Description Framework), в качестве представления модели данных, RDF Schema, в качестве языка описания лексики и OWL (Web Ontology Language) для определения смысла терминов и их отношений, используемых в словарях. В Semantic web знания описываются триплетом – субъект, предикат, объект. Субъект и предикат являются сущностями, обладающими URI ( Uniform Resource Identifier). Объект может быть как литералом, так и сущностью. Для получения информации из RDF графов используется язык запросов SPARQL, который предоставляет возможность получения информации из различных форм, таких как URI, узлы, простые и типизированные литералы [3] .
База знаний в сочетании с системой логического вывода могут находить новые факты из уже имеющихся. Применение правил к фактам могут порождать новые знания. Для извлечения знаний применяются интеллектуальные агенты, которые используют готовые факты либо порождают новые с помощью логического вывода из правил.
Задачей любой информационной системы, основанной на знаниях, является предоставление требуемых результатов поиска, будь то простой или сложный запрос. Semantic web использует достаточно средств для ответа на конкретный запрос, а так же обладает необходимой гибкостью, позволяющей менять структуру данных без ущерба для них, позволит приложениям автоматически обрабатывать, интегрировать, формировать информацию из различных источников, обеспечивать поиск по содержимому, а не только по ключевым словам, работать с другими приложениями и сервисами, которые позволят агентам манипулировать соответствующей информацией. Эффективность таких программных агентов будет расти экспоненциально по мере увеличения количества доступного машинно-воспринимаемого контента и автоматизированных сервисов [4].
Увеличение глубины вложенности правил, рост сложности логического вывода являются основным препятствием применения продукционной модели в практических задачах.
Одним из решений данной проблемы является применение метода сопоставления списка вторичных фактов, позволяющие уменьшить сложность извлечения знаний.
Ускорить выполнение правил можно при условии запоминания результатов применения правил к базе знаний в виде вторичных фактов (прецедентов). Данный метод позволяет избежать необходимости углубления по дереву поиска и сократить время извлечения нового факта [1].
Пусть база первичных фактов составляет множество триплетов (s,p,o), где s – субъект, p- предикат, определяющий отношение «отец/мать» , o- объект. Субъекты и объекты идентифицируются случайными числами в диапазоне (0-1000), (1000-2000), (2000-3000),(3000-4000),(4000-5000), представляющие четыре поколения[2].
База прецедентов представляет собой работу правила, представляющее отношение «прапрабабушка/прапрадедушка» и «брат/сестра». Ускорение извлечение факта, осуществляется за счет запоминания результатов применения правила в предыдущих обращениях в виде вторичных фактов. Первичными фактами являются факты, которые не являются результатом работы правила. Выполняется сравнение времени, затраченное на извлечение нового факта, используя базу прецедентов и базу первичных фактов.
Применение метода, использующего базу прецедентов, позволяет устранить необходимость углубления по дереву поиска, избежав необходимости использования повторяющихся фрагментов, путем обращения к прецедентам.
Предполагаемый метод был реализован с помощью фреймворка Jena.
Прецеденты «прапрабабушка/прапрадедушка» (grandgrandparentOf) и «брат/сестра»
(siblingOf) были найдены и сохранены в базе прецедентов на основе правил:
@prefix rel: <http://relationship/> [sibling:
(?a rel:parentOf ?b)
(?a rel:parentOf ?c), notEqual(?b,?c)
->
(?b rel:siblingOf ?c)
]
[grandgrandparent: (?a rel:grandgrandparentOf ?d)
<-
(?a rel:parentOf ?b) (?b rel:parentOf ?c) (?c rel:parentOf ?d)
]
Правило, которое использовалось для измерения времени вывода новых фактов на основе прецедентов, описывает отношение «троюродный брат» (thirdcousinOf):
@prefix fam: <http://family/> [thirdcousin: (?c3 rel:thirdcousinOf ?d3)
<-
(?a3 rel:siblingOf ?b3)
(?a3 rel:grandgrandparentOf ?c3) (?b3 rel:grandgrandparentOf ?d3)
]
Для сравнения времени вывода новых фактов на основе первичных фактов использовалось правило, так же описывающее отношение «троюродный брат» (thirdcousinOf):
@prefix rel: <http://relationship/>
[sibling: (?b rel:siblingOf ?c)
<-
(?a rel:parentOf ?b)
(?a rel:parentOf ?c), notEqual(?b,?c)
]
[grandparent: (?a1 rel:grandparentOf ?c1)
<-
(?a1 rel:parentOf ?b1) (?b1 rel:parentOf ?c1)
]
[grandgrandparent: (?a2 rel:grandgrandparentOf ?c2)
<-
(?b2 rel:parentOf ?c2)
(?a2 rel:grandparentOf ?b2)
]
[thirdcousin: (?c3 rel:thirdcousinOf ?d3)
<-
(?a3 rel:siblingOf ?b3)
(?a3 rel:grandgrandparentOf ?c3) (?b3 rel:grandgrandparentOf ?d3)
]
В табл. 1 представлены результаты исследования времени создания, извлечения прецедентов в зависимости от числа фактов, а также время извлечения фактов, определяющие отношение
«thirdcousinOf» с использованием базы первичных фактов и прецедентов.
Таблица 1. Результаты исследования
|
Количество первичных фактов |
Время создания базы первичных фактов |
Время создания одного прецедента |
Время извлечения одного факта на основе базы прецедентов |
Суммарное время создания прецедента и извлечения факта |
Время извлечения одного факта на основе базы первичных фактов |
|
2000 |
1 |
0,0015 |
0,0005 |
0,002 |
0,006 |
|
4000 |
2 |
0,0019 |
0,0006 |
0,0025 |
0,0295 |
|
8000 |
2 |
0,0031 |
0,0008 |
0,0039 |
0,0874 |
|
10000 |
2 |
0,0034 |
0,0017 |
0,0051 |
1,0483 |
|
20000 |
2 |
0,0099 |
0,0245 |
0,0344 |
2,0037 |
|
30000 |
2 |
0,0162 |
0,0384 |
0,0546 |
2,9472 |
|
40000 |
2 |
0,0407 |
0,1347 |
0,1754 |
3,7345 |
|
50000 |
2 |
0,0813 |
0,6477 |
0,729 |
5,6782 |
|
60000 |
3 |
0,1974 |
1,4623 |
1,6597 |
8,864 |
|
70000 |
3 |
1,4278 |
2,3745 |
3,8023 |
10,1422 |
|
80000 |
3 |
2,4271 |
3,9758 |
6,4029 |
15,1256 |
|
90000 |
3 |
2,7854 |
5,4768 |
8,2622 |
19,4578 |
|
100000 |
3 |
3,5647 |
6,2471 |
9,8145 |
23,7812 |
|
100 |
|||||
|
10 |
|||||
|
1 |
|||||
|
0 |
20000 |
40000 60000 80000 |
100000 |
120000 |
|
|
0,1 |
|||||
|
0,01 |
|||||
|
0,001 |
|||||
|
Количество фактов |
|||||
|
Время извлечения одного факта на основе базы первичных фактов Суммарное время создания прецедента и извлечения факта. |
|||||
Рис.1. Время обработки фактов на основе прецедентов и базы первичных фактов
На рис. 1 представлены графики времени обработки фактов на основе прецедентов и базы первичных фактов. Показано, что время извлечения фактов на основе прецедентов существенно меньше времени обработки правил.
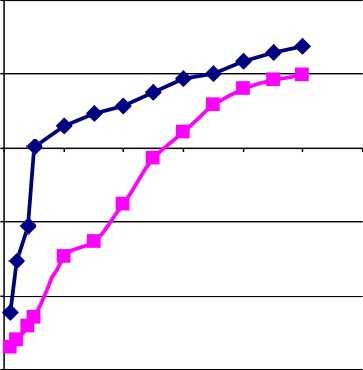 Время, с
Время, с
Представленная модель может быть использована в экспертных системах, логических агентах и в технологиях Semantic web. Проведенное исследование позволяет сделать вывод, что данный метод позволяет ускорить логический вывод в продукционной модели знаний. Увеличения времени извлечения факта по мере роста базы прецедентов является более приемлемым, нежели время, затраченное на работу правила с применением базы первичных фактов.
ЛИТЕРАТУРА
- Бессмертный И.А. Управление интеллектуальными навыками в базах знаний // Теория и системы управления. -Санкт-Петербург, 2011
- Бессмертный И.А. Теоретико-множественный подход к логическому выводу в базах знаний // Научно-технический вестник СПбГУИТМО. — Санкт-Петербург: СПбГУИТМО, 2010. — Т. 66, вып. 2. — С. 43- 48. — 128 с. — ISSN 1819-222Х.
- Hammad H.R. Semantic Web Solutions//final thesis – IT University of Copenhagen, 2007, — С. 7-12- 100с.
- Rezara J.M. A System for Management of Semantic Data (OntologyComponents) in Semantic Web//Royal Institute of Technology -Sweden, 2007 –C. 5-27. – 167 с.
- Рассел, С., Норвиг, П. Искусственный интеллект: Современный подход. 2-е изд. // пер. с англ. – М.: Изд. дом «Вильямс», 2006.
Фамилия автора: И.А. Бессмертный, А.С. Балгайракова, Д.В. Ковбаско
articlekz.com
Иллюстрированный самоучитель по введению в экспертные системы › Рассуждения, основанные на прецедентах › Методы извлечения и адаптации прецедентов [страница — 314] | Самоучители по программированию
Методы извлечения и адаптации прецедентов
В системах формирования суждений на основе прецедентов используются разные схемы извлечения прецедентов и их адаптации к новым проблемам.
В таких программах, как CHEF, сопоставляются описания имеющихся прецедентов и полученная спецификация цели, причем в качестве основного средства сопоставления выступает семантическая сеть (см. главу 6). В примере, рассмотренном в предыдущем разделе, модулям извлечения и модификации известно, что и брокколи, и зеленый горошек – это свежие овощи. Модуль извлечения использует эту информацию для вычисления оценки степени близости прецедента и целевой спецификации, а модуль модификации использует эту же информацию для подстановки в рецепт одного ингредиента вместо другого. Это фоновое знание играет весьма существенную роль в решении обеих задач.
Сложность поиска решения и выявления различий между прецедентами в значительной степени зависит от используемых термов индексации. По сути, прецеденты в базе прецедентов конкурируют, пытаясь «привлечь» к себе внимание модуля извлечения, точно так же, как порождающие правила конкурируют за доступ к интерпретатору. В обоих случаях необходимо использовать какую-то стратегию разрешения конфликтов. С этой точки зрения прецеденты должны обладать какими-то свойствами, которые, с одной стороны, связывают прецедент с определенными классами проблем, а с другой – позволяют отличить определенный прецедент от его «конкурентов». Например, в программе CHEF прецеденты индексируются по таким атрибутам, как основной ингредиент блюда, гарнир, способ приготовления и т.п., которые специфицируются в заказе.
Механизм сопоставления должен быть достаточно эффективным, поскольку исчерпывающий поиск можно применять только при работе с базами прецедентов сравнительно небольшого объема. Одним из популярных методов эффективного индексирования является использование разделяемой сети свойств (shared feature network). При этом прецеденты, у которых какие-либо свойства совпадают, включаются в один кластер, в результате чего формируется таксономия типов прецедентов. Сопоставление в такой разделяемой сети свойств выполняется с помощью алгоритма поиска в ширину без обратного прослеживания. Поэтому время поиска связано с объемом пространства логарифмической зависимостью. Индивидуальное сопоставление, как правило, выполняется следующим образом.
Каждому свойству (или размерности) присваивается определенный вес, соответствующий степени «важности» этого свойства. Если, например, прецеденты включают счета пользователей, то имя пользователя, скорее всего, не имеет значения при поиске группы прецедентов с похожими счетами. Следовательно, свойство имя может иметь вес 0. А вот остаток на счете (в долларах) имеет очень существенное значение и ему следует придать вес 1.0. Чаще всего значения весов – это действительные числа в интервале [0.1].
Из всех этих рассуждений вытекает простой алгоритм сопоставления прецедентов, представленный ниже.
Присвоить MATCH = 0.0;
Для каждого свойства в исходной спецификации
{
2. Найти соответственное свойство в хранимых прецедентах.
3. Сравнить два значения и вычислить степень близости т.
4. Умножить эту оценку на вес свойства с.
5. Присвоить MATCH = MATCH + cм.
}
Возвратить MATCH.
Базовая процедура называется сопоставлением с ближайшим соседом (Nearest-Neighbor matching), поскольку прецеденты, которые имеют близкие значения свойств, и концептуально ближе друг другу. Это может найти отражение и в структуре сети, где степень близости прецедентов будет соответствовать близости их свойств.
Вычисленное по этому алгоритму значение MATCH обычно называется агрегированной оценкой совпадения (aggregate match score). Естественно, что из базы прецедентов выбирается тот, который «заслужил» самую высокую оценку. Если же алгоритм работы системы предполагает и исследование альтернативных прецедентов, то оставшиеся должны быть ранжированы по полученным оценкам. Большинство доступных на рынке программ, имеющих дело с базами прецедентов, использует именно этот простой алгоритм.
Применяемый на шаге (2) метод вычисления степени близости зависит от типа данных в каждом конкретном случае. При качественном сопоставлении свойств достаточно будет использовать двоичные оценки или вычислять расстояние в абстрактной иерархии. Так, в абстрактной иерархии ингредиентов кулинарных рецептов «брокколи» ближе к «горошку», чем к «цыплятам», и вычисленное значение должно отражать этот неоспоримый факт. Количественное сопоставление будет включать и шкалирование.
Для адаптации найденного прецедента к текущим целевым данным программы также используют разные методы. В большинстве случаев можно обойтись заменой некоторых компонентов в имеющемся решении или изменением порядка операций в плане. Но существуют и другие подходы, которые перечислены ниже.
- Повторная конкретизация переменных в существующем прецеденте и присвоение им новых значений. Например, сопоставление переменной овощи со значением брокколи вместо прежнего значения горошек.
- Уточнение параметров. Некоторые прецеденты могут содержать числовые значения, например время выполнения какого-либо этапа плана. Это значение должно быть уточнено в соответствии с новым значением другого свойства. Например, если в рецепте требуется заменить один ингредиент другим, то, вероятно, придется соответственно изменить и время его обработки.
- Поиск в памяти. Иногда требуется найти способ преодоления затруднения, возникшего как побочный эффект замены одних компонентов решения другими. Примером может послужить уже упоминавшийся выше эффект нежелательного изменения свойств брокколи при обжаривании вместе с кусочками баранины. Такой способ можно отыскать в той же базе прецедентов или в специальной базе знаний.
Большинство из перечисленных методов жестко связано со способом представления иерархии абстракций, который используется в конкретной программе. Это может быть система фреймов или семантическая сеть, и в каждом из этих вариантов подстановка одних концептов вместо других должна быть организована по-своему.
В следующем разделе мы рассмотрим систему, в которой используется довольно специфический способ представления знаний для моделирования предметной области. Для организации базы прецедентов в этой системе используется не разделяемая сеть свойств, а факторы более высокого уровня абстракции, связанные со спецификой предметной области. Такое представление требует применения более сложного механизма индексирования прецедентов и их поиска, чем тот, который использовался в модуле извлечения программы CHEF.
samoychiteli.ru
Описание прецедентов
«include»
«include»
«include»
Прием в ремонт
Выполнение ремонта
Выдача из ремонта
Идентификация
Идентификация

Рисунок 1 – Диаграмма прецедентов
Прецедент
“Выполнение ремонта” описывает процесс
получение заявки, выявления неисправности
электрооборудования, составление списка
необходимых комплектующих, заказ
комплектующих у поставщика, составление
акта о выполненном ремонте. Так же
включает в себя идентификацию пользователей
системы.
Актеры:
Секретарь ─ составляет заявку на ремонт и заносит ее в базу, составляет заказ на комплектующие.
Мастер ─ получает заявку на ремонт, выявляет неисправность, составляет список запчастей, составляет акт о выполненном ремонте.
Главный актер: Мастер.
Основной успешный сценарий
“Мастер” получает заявку на ремонт электрооборудования из базы данных.
“Мастер” определяет причину неисправности.
“Мастер” составляет список необходимых для ремонта комплектующих и заносит его в базу данных.
“Мастер” получает необходимые комплектующие со склада.
“Мастер” оформляет акт о выполненном ремонте и заносит его в базу данных.
Альтернативные сценарии:
3(а) Не все комплектующие из списка доступны на складе ─ “Секретарь” составляет заявку на закупку недостающих элементов.
3(б) “Мастер” принимает заказанные комплектующие.
2.2 Модели потоков данных dfd
На DFD диаграмме отображена модель потоков данных разрабатываемой системы. На первом уровне отображена схема работы системы.

Рисунок 2 – Первый уровень DFD диаграммы
На втором уровне DFD диаграммы отображаются основные потоки данных.
Рисунок 3 – Второй уровень DFD диаграммы


Рисунок 4 – Детализация деятельности “работа с клиентами”
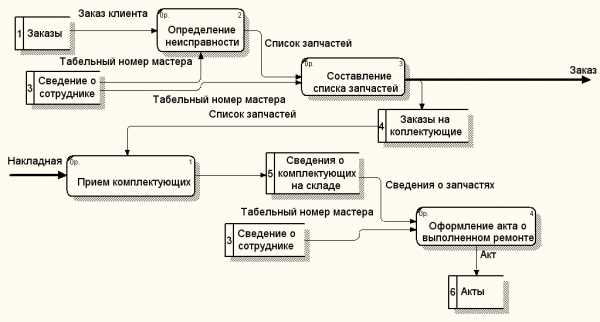
Рисунок 5 – Детализация деятельности “выполнение ремонта”
2.3 Концептуальная инфологическая модель интегрированной базы данных
Концептуальная инфологическая модель данных отображает основные сущности и типы связей между ними без атрибутов и ключей. Такая модель позволяет отразить содержимое предметной области и облегчает процесс дальнейшей разработки модели данных.

Рисунок 6 – Концептуальная инфологическая модель
3 Разработка моделей системы учета ремонта электрооборудования
3.1 Разработка моделей процессов
В данном курсе (согласно выбору средств решения технического задания) разработку проектируемой информационной системы будем осуществлять с использованием структурного подхода. В рамках данного подхода разрабатываем модель процессов (функциональную модель) по методологии IDEF0.
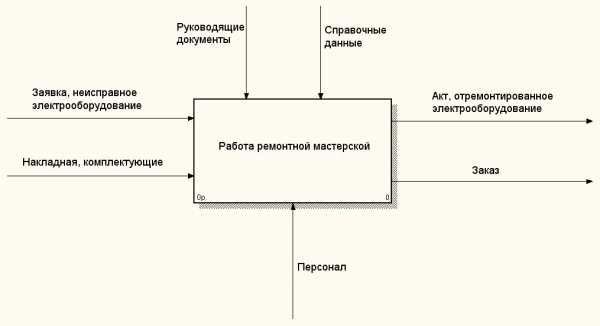
Рисунок 7 – Контекстная модель
Данная модель показывает всю проектируемую систему в качестве единственного процесса, взаимосвязанного с внешним миром через входные и выходные данные, внешнее управление и механизмы.
На следующем уровне модель процессов раскрывается следующим образом (рисунок 8): выделяются два основных вида деятельности, выполняемых в системе и соответствующих ранее описанным прецедентам. На данном уровне кроме входных и выходных данных, управляющих потоков выделены механизмы, представленные пользователями, взаимодействующими с системой. Разграничение пользователей по правам и выполняемым в системе задачам осуществляется путем разветвления общей стрелки на отдельные и присвоением им различных наименований. Аналогичным образом осуществляется разграничение других потоков данных.
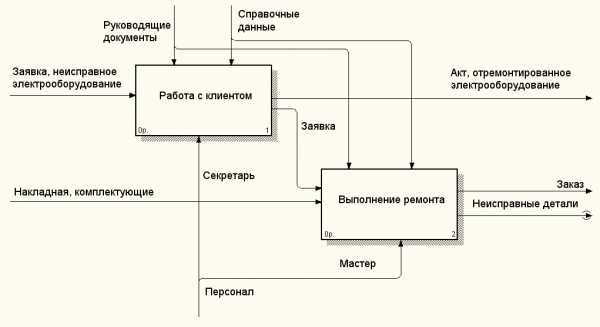

Рисунок 8 – Второй уровень модели

Рисунок 9 – Детализация “работа с клиентом”

Рисунок 10 – Детализация “выполнение ремонта”
studfiles.net
Разработка структуры и алгоритма работы базы прецедентов в интеллектуальной системе расчета нормы расхода инструмента
Афлятунова Венера Алмасовна
магистр, ГОУ ВПО «Камская государственная инженерно-экономическая академия», г. Набережные Челны
E-mail: [email protected]
Симонова Лариса Анатольевна
профессор, д. т. н., ГОУ ВПО «Камская государственная инженерно-экономическая академия», г. Набережные Челны
Важная роль в бесперебойном обеспечении предприятия необходимыми инструментами принадлежит инструментальному хозяйству. Сложность организации, планирования производства и эксплуатации инструментов обуславливается огромной номенклатурой, высоким требованиям к качеству и стойкости и большим влиянием инструментального хозяйства на экономику предприятия. Значительный объем анализируемых данных требует немалого времени для их ручной обработки и принятия решения в сложившейся ситуации. Этим и обусловлена необходимость использования автоматизированной системы поддержки принятия решений, предназначенной для формирования точных данных расхода инструмента. В основе таких систем могут лежать различные методы обработки информации, в частности, использование интеллектуальной системы поддержки принятия решений. В области проектирования и реализации программных систем искусственного интеллекта весьма актуальными являются задачи моделирования правдоподобных рассуждений на основе прецедентов в интеллектуальных системах поддержки принятия решений [1], в том числе задачи организации представления и хранения данных и знаний (прецедентов), а также разработки эффективных методов работы с распределенными данными.
Для разработки начального состояния базы прецедентов необходимо взять за основу данные, полученные из опытного исследования. За основу были взяты 3 вида деталей и опытным путем определено вид и количество расходуемых инструментов на 1000 деталей. Опытные данные приведены в таблице 1.
Таблица 1. Экспериментальные данные
Технологические операции (материал) | Инструмент (материал) | Фактическое кол-во расхода инструмента | |
Отливка: Патрубок (740.11-1115075-10, 740.11-1115075-20, 740.11-1115074) | |||
обрезка | Фреза ф550 16-2256-4012 | 2 | |
Зачистка машинная | Дисковая шарошка 06-2290-4028 | 2 | |
Зачистка ручная | Борфреза ф22 ГОСТ18949-73 | 2 | |
Отливка: Колено отводящего патрубка (6520-1303028, 5460-1303028, 5320-130328) | |||
обрезка | Пила ленточная 35х1,3х10мм | 7-8 | |
Зачистка машинная | Дисковый напильник 06-2290-4028 | 1-2 | |
Лента шлифовальная 40х800 | 10 | ||
Зачистка ручная | Пневматический ленточный напильник | 1 | |
Шлифовальная лента 250х20 | 5 | ||
Напильник 0071 ГОСТ1465-80 | 1-2 | ||
Отливка: Тройник (5411-1109050) | |||
обрезка | Пила ленточная 35х1,3х10мм | 5-6 | |
Зачистка машинная | Дисковый напильник 06-2290-4028 | 1 | |
Зачистка ручная | Пневматический ленточный напильник | 1 | |
дисковая шарошка 330.137 | 1 | ||
Согласно полученным данным, в первоначальном состоянии база прецедентов будет содержать следующие прецеденты [2; 3]:
1. если патрубок из сплава АК9ч обрабатывается в техоперации обрезка, то инструмент Фреза ф550 и расход инструмента на 1000 отливок составляет 2шт.;
2. если патрубок из сплава АК9ч обрабатывается в техоперации Зачистка машинная, то инструмент Дисковой напильник и расход инструмента на 1000 отливок составляет 2шт.;
3. если патрубок из сплава АК9ч обрабатывается в техоперации зачистка ручная, то инструмент Зубило и расход инструмента на 1000 отливок составляет 1шт.;
4. если колено из сплава Ак9пч обрабатывается в техоперации зачистка машинная, то инструмент Дисковой напильник и расход инструмента на 1000 отливок составляет 5шт.;
5. если колено из сплава Ак9пч обрабатывается в техоперации зачистка машинная, то инструмент Дисковой напильник и расход инструмента на 1000 отливок составляет 5шт.;
6. если колено из сплава Ак9пч обрабатывается в техоперации зачистка машинная, то инструмент Дисковой напильник и расход инструмента на 1000 отливок составляет 5шт.
Учитывая приведенные выше опытные данные и специфику работы интеллектуальной системы (сложность получения ответа при помощи логического рассуждения) база прецедентов была разделена на следующие классы:
· исходные данные, т.е. данные получаемые с интерфейса пользователя;
· опытные решения, т.е. решения, которые получены, но не подтверждены экспертом;
· эталонные решения, решения, которые подтверждены экспертом и являются прецедентами.
Рисунок 1. Классы и алгоритм формирования прецедента

Алгоритм работы базы прецедентов состоит в модификации исходных данных следующим образом [1; 2]:
· анализируются данные детали – ее форма, вид обработки и сплав, из которого состоит деталь;
· далее данные сравниваются с уже существующими прецедентами;
· определяется эталонное решение с тем же параметрами, в котором заложен метод расчета нормы расхода инструмента;
· исходные данные и метод расчета передается в блок вычисления, т.е. происходит модификация эталонного решения;
· в результате данной модификации получаем опытное решение, которое идет на подтверждение эксперту;
· после подтверждения эксперта, формируется прецедент, сохраняющийся в базе.
Список литературы:
1.Бредихин К.Н., Варшавский П.Р. Распределенный вывод на основе прецедентов в интеллектуальных системах поддержки принятия решений // Теория и практика системного анализа: тр. I Всерос. науч. конф. молодых ученых. Рыбинск: РГАТА им. П.А. Соловьева, 2010. Т. 1. С. 57–62.
2.Варшавский П.Р., Еремеев А.П. Моделирование рассуждений на основе прецедентов в интеллектуальных системах поддержки принятия решений // Искусственный интеллект и принятие решений. 2009. №2. С. 45–47.
3.Гречишников В.А. Моделирование систем инструментального обеспечения автоматизированных производств. Москва, 1988, серия 8 (Инструментальное и технологическое оснащение металлообрабатывающего производства: ВНИИТЭМР. Вып.4).
sibac.info
Разработка базы прецедентов для поиска аналогов проектных решений
УДК 004.81
Разработка базы прецедентов для поиска аналогов
проектных решений
Е.С. Яшина, к.т.н., доцент, С.Н. Маркова, студент
Национальный аэрокосмический университет им. Н.Е.Жуковского «ХАИ»
Разработка сложной технической системы — длительный и трудоемкий процесс, основная часть времени которого затрачивается на стадию проектирования. Поэтому приоритетной является задача уменьшения сроков этапа проектирования без увеличения рисков.
Поскольку сокращение времени при создании новой системы «с нуля» влечет существенное увеличение рисков и сроков проектирования, а накопленный к настоящему времени опыт показывает, что проектирование — логически сложная, трудоемкая и длительная по времени работа, требующая высокой квалификации участвующих в ней специалистов — возникает необходимость проектировать технические системы, основываясь на практическом опыте, экспертных оценках или дорогостоящих экспериментальных проверка качества
функционирования системы. Одним из перспективных направлений развития методов проектирования является использование опыта создания аналогичных систем, поскольку в этом случае используются апробированные проектные решения, надёжность и эффективность которых подтверждена на практике.
Актуальность работы заключается в том, что она позволяет автоматизировать процесс поиска аналогов проектных решений для их последующего использования в построении проектов.
Целью данной работы является снижение сроков и затрат на проектирование за счет повторного использования проектных решений.
Для достижения поставленной цели предлагается применять метод вывода по прецедентам. Для этого разработана методика определения компонентов проекта путем поиска в базе прецедентов. Разработана база прецедентов по компонентам летательных аппаратов. Построена модель меры близости прецедентов с учётом критериев поиска, заданных пользователем. Изучено применение различных метрик для определения меры близости образца и аналогов по множеству характеристик. Спроектировано и создано необходимое программное обеспечение.
Результатом является информационная система, позволяющая накапливать опыт решения проектных задач в виде базы прецедентов и осуществлять поиск в этой базе для выбора компонентов нового технологического изделия.
k504.khai.edu
Разработка модели бизнес-прецедентов
12. Этапы проектирования ИС с применением UML |
UML обеспечивает поддержку всех этапов жизненного цикла ИС и предоставляет для этих целей ряд графических средств – диаграмм. На этапе создания концептуальной модели для описания бизнес-деятельности используются модели бизнес-прецедентов и диаграммы видов деятельности, для описания бизнес-объектов – модели бизнес-объектов и диаграммы последовательностей. На этапе создания логической модели ИС описание требований к системе задается в виде модели и описания системных прецедентов, а предварительное проектирование осуществляется с использованием диаграмм классов, диаграмм последовательностей и диаграмм состояний. На этапе создания физической модели детальное проектирование выполняется с использованием диаграмм классов, диаграмм компонентов, диаграмм развертывания. Ниже приводятся определения и описывается назначение перечисленных диаграмм и моделей применительно к задачам проектирования ИС (в скобках приведены альтернативные названия диаграмм, использующиеся в современной литературе). Диаграммы прецедентов (диаграммы вариантов использования, use case diagrams) – это обобщенная модель функционирования системы в окружающей среде. Диаграммы видов деятельности (диаграммы деятельностей, activity diagrams) – модель бизнес-процесса или поведения системы в рамках прецедента. Диаграммы взаимодействия (interaction diagrams) – модель процесса обмена сообщениями между объектами, представляется в виде диаграмм последовательностей (sequence diagrams) или кооперативных диаграмм (collaboration diagrams). Диаграммы состояний (statechart diagrams) – модель динамического поведения системы и ее компонентов при переходе из одного состояния в другое. Диаграммы классов (class diagrams) – логическая модель базовой структуры системы, отражает статическую структуру системы и связи между ее элементами. Диаграммы базы данных (database diagrams) — модель структуры базы данных, отображает таблицы, столбцы, ограничения и т.п. Диаграммы компонентов (component diagrams) – модель иерархии подсистем, отражает физическое размещение баз данных, приложений и интерфейсов ИС. Диаграммы развертывания (диаграммы размещения, deployment diagrams) – модель физической архитектуры системы, отображает аппаратную конфигурацию ИС. На рис. 12.1 показаны отношения между различными видами диаграмм UML. Указатели стрелок можно интерпретировать как отношение «является источником входных данных для…» (например, диаграмма прецедентов является источником данных для диаграмм видов деятельности и последовательности). Приведенная схема является наглядной иллюстрацией итеративного характера разработки моделей с использованием UML.
Рис. 12.1. Взаимосвязи между диаграммами UML Ниже приводятся описания последовательных этапов проектирования ИС с использованием UML. |

Модель бизнес-прецедентов описывает бизнес-процессы с точки зрения внешнего пользователя, т.е. отражает взгляд на деятельность организации извне.
Проектирование системы начинается с изучения и моделирования бизнес-деятельности организации. На этом этапе вводится и отображается в модели ряд понятий, свойственных объектно-ориентированному подходу:
Исполнитель (Действующее лицо, Actor) – личность, организация или система, взаимодействующая с ИС; различают внешнего исполнителя (который использует или используется системой, т.е. порождает прецеденты деятельности) и внутреннего исполнителя (который обеспечивает реализацию прецедентов деятельности внутри системы). На диаграмме исполнитель представляется стилизованной фигуркой человека.
Прецедент – законченная последовательность действий, инициированная внешним объектом (личностью или системой), которая взаимодействует с ИС и получает в результате некоторое сообщение от ИС. На диаграмме представляется овалом с надписью, отражающей содержание действия.
Класс — описание совокупности однородных объектов с их атрибутами, операциями, отношениями и семантикой. На диаграмме представляется прямоугольником, содержащим описания атрибутов и операций класса.
Ассоциация – связь между двумя элементами модели. На диаграмме представляется линией.
Обобщение – связь между двумя элементами модели, когда один элемент (подкласс) является частным случаем другого элемента (суперкласса). На диаграмме представляется стрелкой.
Агрегация – отношение между элементами модели, когда один элемент является частью другого элемента (агрегата). На диаграмме представляется стрелкой с ромбовидным концом.
Для иллюстрации этапов разработки проекта использованы адаптированные материалы проекта ИС медицинского центра (рис. 12.2). Назначение ИС – автоматизация ведения и использования клинических записей о пациентах. В настоящее время эта работа производится вручную персоналом центра. На рис. 12.2 представлена общая модель деятельности центра в виде диаграммы прецедентов. Прецедент «Обслуживание пациента» реализуется через множество других, более ограниченных прецедентов (рис. 12.3), отражающих детализацию представления функционирования центра.
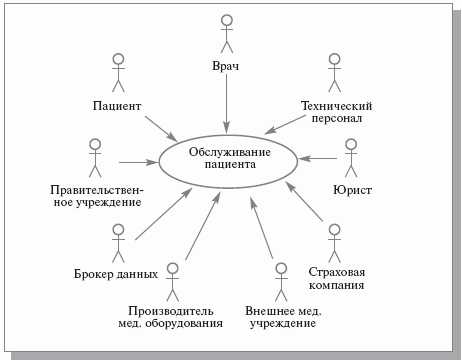
Рис. 12.2. Общая диаграмма деятельности медицинского центра по обслуживанию пациента
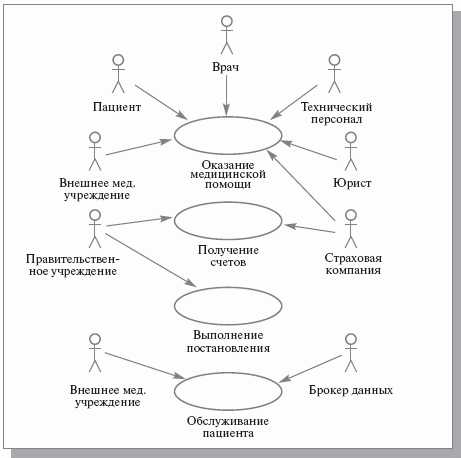
Рис. 12.3. Модель бизнес-прецедентов, составляющих обслуживание пациента
Для включения в диаграмму выбранные прецеденты должны удовлетворять следующим критериям:
прецедент должен описывать, ЧТО нужно делать, а не КАК;
прецедент должен описывать действия с точки зрения ИСПОЛНИТЕЛЯ;
прецедент должен возвращать исполнителю некоторое СООБЩЕНИЕ;
последовательность действий внутри прецедента должна представлять собой одну НЕДЕЛИМУЮ цепочку.
Исходя из цели создания системы, для дальнейшего исследования и моделирования отбираются только те бизнес-прецеденты, которые связаны с использованием клинических записей.
Выполнение прецедента описывается с помощью диаграмм видов деятельности, которые отображают исполнителей и последовательность выполнения соответствующих бизнес-процессов (рис. 12.4).
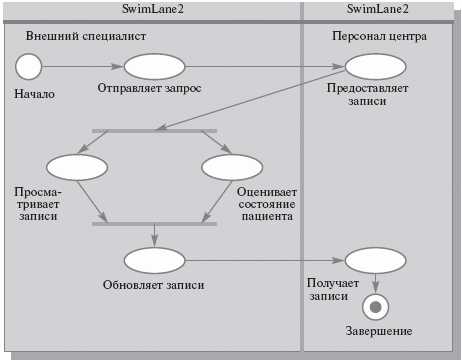
Рис. 12.4. Диаграмма видов деятельности для прецедента «Оказание медицинской помощи»
Несмотря на то, что оказание медицинской помощи предусматривает множество разнообразных действий исполнителей, для нашей задачи существенными являются только процессы обмена информацией между этими исполнителями, и именно они отображаются в создаваемых моделях. Поэтому на диаграмме отражен процесс оценки состояния пациента на основании имеющейся в центре информации о нем.
Общее поле диаграммы деятельности делится на несколько «плавательных дорожек», каждая из которых содержит описание действий одного из исполнителей. Основными элементами диаграмм видов деятельности являются обозначения состояния («начало», «конец»), действия (овал) и момента синхронизации действий (линейка синхронизации, на которой сходятся или разветвляются несколько стрелок).
Диаграмма подходит для описания действий как внешнего, так и внутреннего специалиста центра.
Этап завершается после разработки диаграмм видов деятельности для всех выделенных в модели бизнес-прецедентов. Естественно, на последующих этапах анализа и проектирования будут выявлены какие-то важные подробности в описании деятельности объекта автоматизации. Поэтому разработанные на данном этапе модели будут еще неоднократно корректироваться.
studfiles.net