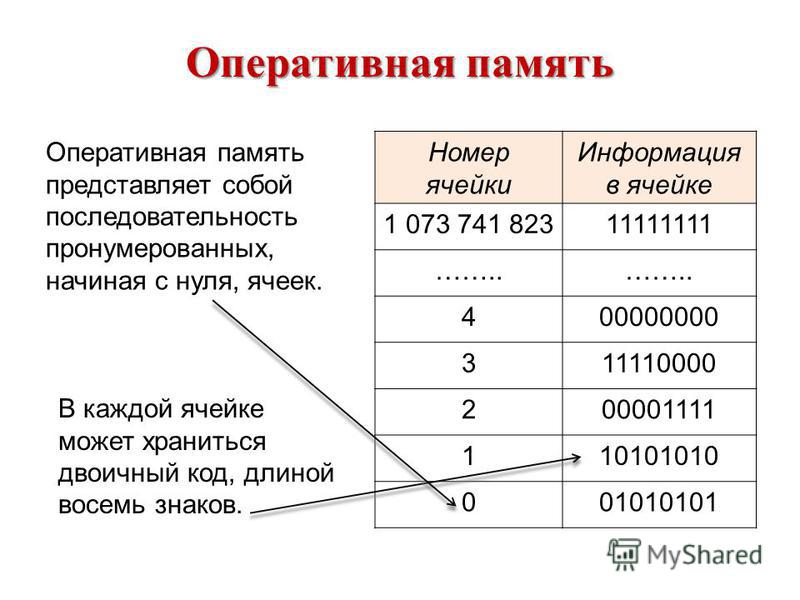
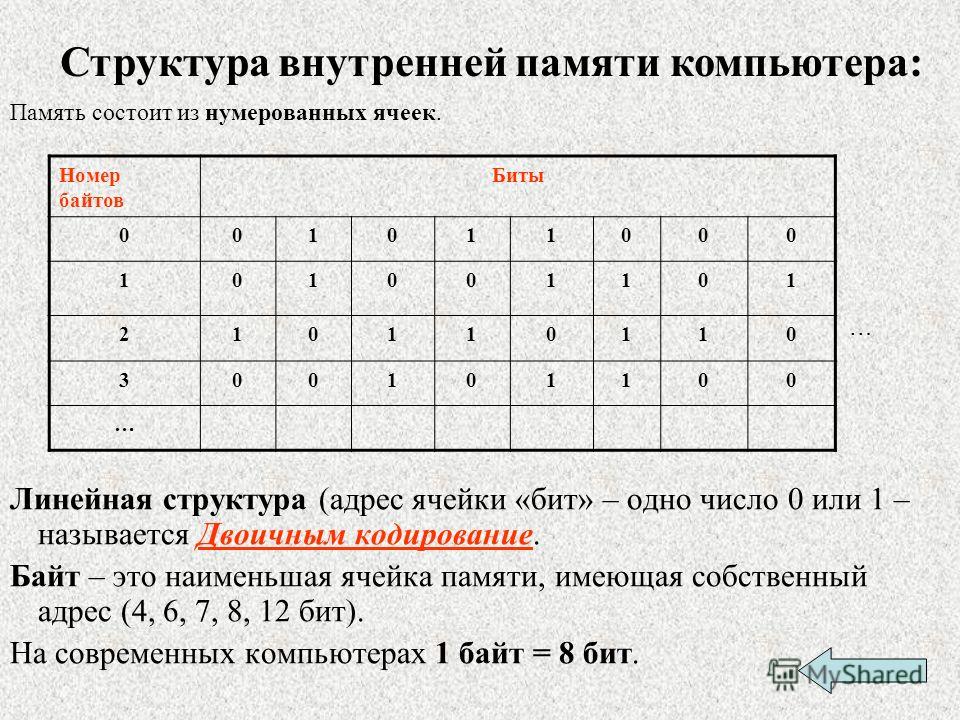
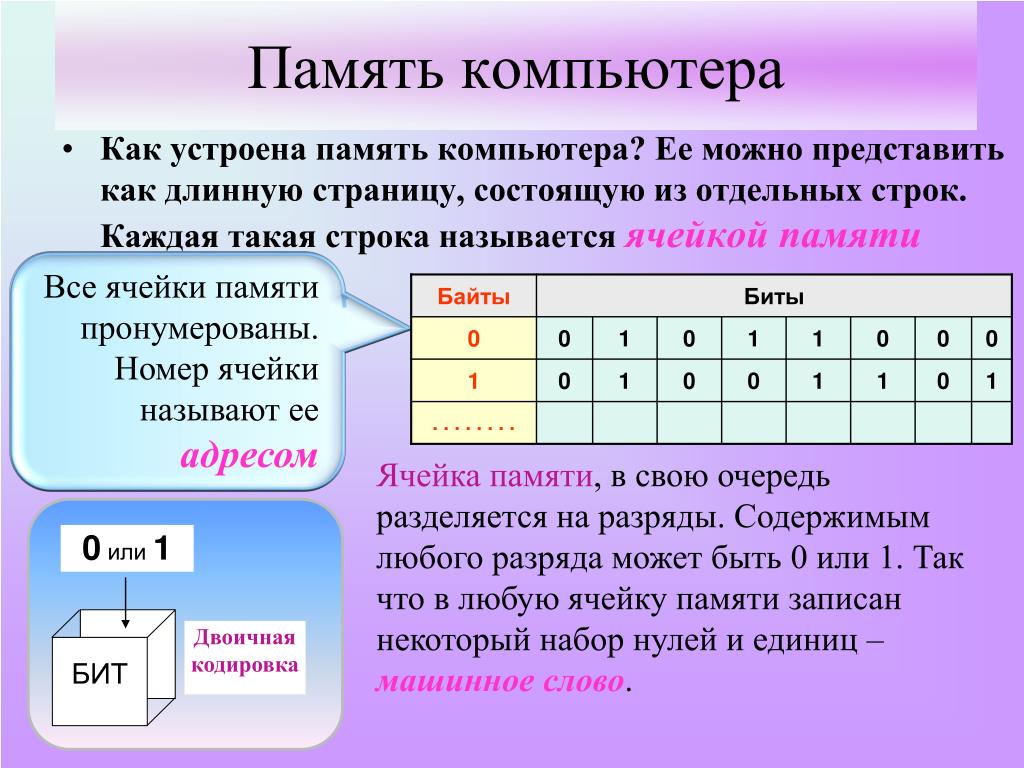
3.4. Адрес ячейки памяти
В компьютерных системах работа с памятью основывается на очень простых концепциях. В принципе, все, что требуется от компьютерной памяти, — это сохранять один бит информации так, чтобы потом он мог быть извлечен оттуда.
Одним из основных элементов компьютера, позволяющим ему нормально функционировать, является память. Внутренняя память компьютера — это место хранения информации, с которой он работает. Внутренняя память компьютера является временным рабочим пространством; в отличие от нее внешняя память, такая как файл на дискете, предназначена для долговременного хранения информации. Информация во внутренней памяти не сохраняется при выключении питания.
Каждая
ячейка памяти имеет адрес, который
используется для ее нахождения. Адреса — это числа, начиная с нуля для первой
ячейки, увеличивающиеся по направлению
к последней ячейке памяти. Поскольку
адреса — это те же числа, компьютер может
использовать арифметические операции
для вычисления адресов памяти.
Архитектура каждого компьютера накладывает собственные ограничения на величину адресов. Наибольший возможный адрес определяет объем адресного пространства компьютера или то, какой объем памяти он может использовать. Обычно компьютер использует память меньшего объема, чем допускается его возможностями адресации. Если архитектура компьютера предусматривает наибольшее адресное пространство, это накладывает суровые ограничения на возможности такого компьютера. Адреса в 8088 имеют длину 20 бит, следовательно, процессор позволяет адресовать два в двадцатой степени байта или 1024 К.
Процессор имеет ряд регистров, используемых для управления выполняющейся программой, адресации памяти и обеспечения арифметических вычислений. Каждый регистр адресуется по имени. Биты регистра принято нумеровать слева направо.
Перечислим основные регистры и кратко определим их назначение.
Сегментные регистры (CS, DS, SS, ES)
. Регистр
сегмента кода (CS) содержит
начальный адрес сегмента кода. Этот
адрес плюс значение смещения в командном
указателе (IP) определяет адрес
команды, которая должна быть выбрана
для выполнения.
Этот
адрес плюс значение смещения в командном
указателе (IP) определяет адрес
команды, которая должна быть выбрана
для выполнения.
Регистр сегмента данных (DS) содержит начальный адрес сегмента данных. Этот адрес плюс значение смещения, определенное в команде, указывают на конкретную ячейку в сегменте данных.
Регистр сегмента стека (SS) содержит начальный адрес сегмента стека.
Регистр ES. Некоторые операции над строками используют дополнительный сегментный регистр для управления адресацией памяти. В этом случае этот регистр связан с индексным регистром DI. Если необходимо использовать регистр ES, ассемблерная программа должна его инициализировать.
Регистры общего назначения
 Например,
двухбайтовый регистр CX состоит из
двух однобайтовых CH и CL, и ссылки
на регистр возможны по любому из этих
трех имен.
Например,
двухбайтовый регистр CX состоит из
двух однобайтовых CH и CL, и ссылки
на регистр возможны по любому из этих
трех имен.Разберем назначение каждого из регистров.
Регистр AX. Он является основным сумматором и применяется для всех операций ввода-вывода, некоторых операций над строками и некоторых арифметических операций. Например, команды умножения, деления и сдвига предполагают использование регистра AX. Некоторые команды генерируют более эффективный код, если они имеют ссылки на регистр AX.
Регистр BX. Он является базовым регистром. Это единственный регистр общего назначения, который может использоваться в качестве «индекса» для расширенной адресации. Также он используется при организации вычислений.
Регистр CX. Это счетчик, используемый
для управления числом повторений циклов
и для операций сдвига влево или вправо.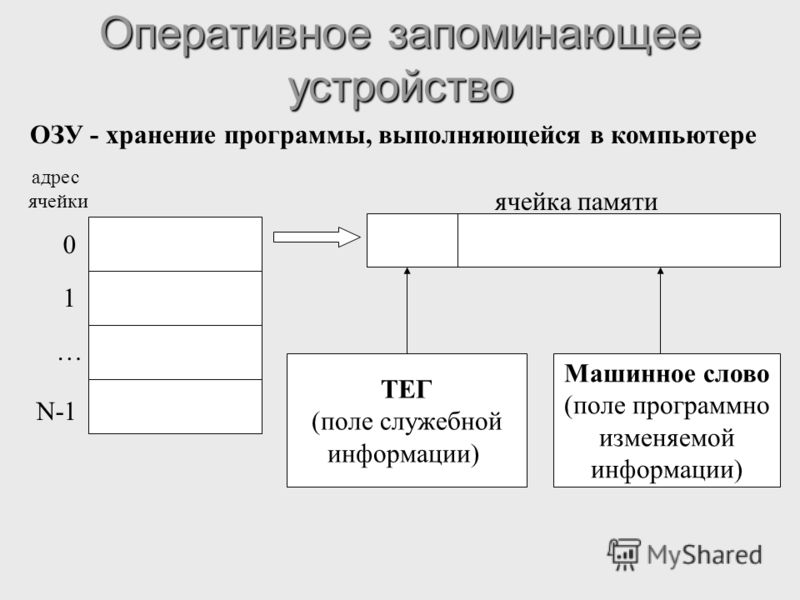 Регистр CX используется также при
вычислениях.
Регистр CX используется также при
вычислениях.
Регистр DX. Он является регистром данных и применяется для некоторых операций ввода-вывода и тех операций умножения и деления над большими числами, которые используют регистровую пару DX:AX.
Регистровые указатели (SP, BP). Они обеспечивают системе доступ к данным в сегменте стека. Реже используются в арифметических операциях.
Регистр SP. Указатель стека обеспечивает использование стека в памяти, позволяет временно хранить адреса и иногда данные. Этот регистр связан с регистром
Регистр BP. Указатель базы облегчает доступ к параметрам (данным и адресам, переданным через стек).
Индексные регистры (SI, DI). Оба индексных регистра могут применяться для расширенной адресации и для использования в арифметических операциях.
Регистр SI. Этот регистр является индексом
источника данных и применяется для
некоторых операций над строками. В этом
случае он адресует память в паре с
регистром DS.
Этот регистр является индексом
источника данных и применяется для
некоторых операций над строками. В этом
случае он адресует память в паре с
регистром DS.
Регистр DI. Этот регистр является индексом назначения и применяется также для строковых операций. В данном случае он используется совместно с регистром ES.
Регистр командного указателя (IP). Он содержит смещение на команду, которая должна быть выполнена. Обычно этот регистр в программе не применяется, но он может изменять свое значение при использовании отладчика в процессе тестирования программы.
Флаговый регистр (иногда мы будем обозначать его через FLAGS). Девять из шестнадцати бит флагового регистра являются активными и определяют текущее состояние машины и результаты выполнения команд:
Адрес ячейки памяти — Студопедия
Поделись
АЛУ
Общая структурная схема процессора
Принцип фон Неймана
Лекция 3
Принцип фон Неймана. АЛУ. Программа как последовательность кодов команд. Адрес ячейки памяти. Регистры процессора. Как процессор складывает два числа.
АЛУ. Программа как последовательность кодов команд. Адрес ячейки памяти. Регистры процессора. Как процессор складывает два числа.
Большинство современных ЭВМ строится на базе принципов, сформулированных американским ученым, одним из отцов кибернетики Джоном фон Нейманом. Впервые эти принципы были опубликованы фон Нейманом в 1945 г. в его предложениях по машине EDVAC. Эта ЭВМ была одной из первых машин с хранимой программой, т.е. с программой, запомненной в памяти машины, а не считываемой с перфокарты или другого подобного устройства. В целом эти принципы сводятся к следующему:
1) Основными блоками фон-неймановской машины являются блок управления, арифметико-логическое устройство, память и устройство ввода-вывода.
2) Информация кодируется в двоичной форме и разделяется на единицы, называемые словами.
3) Алгоритм представляется в форме последовательности управляющих слов, которые определяют смысл операции. Эти управляющие слова называются командами. Совокупность команд, представляющая алгоритм, называется программой.
4) Программы и данные хранятся в одной и той же памяти. Разнотипные слова различаются по способу использования, но не по способу кодирования.
5) Устройство управления и арифметическое устройство обычно объединяются в одно, называемое центральным процессором. Они определяют действия, подлежащие выполнению, путем считывания команд из оперативной памяти. Обработка информации, предписанная алгоритмом, сводится к последовательному выполнению команд в порядке, однозначно определяемом программой.
Компьютеры, построенные на этих принципах, называются машинами фон‑Неймановского типа.
Процессор — центральная микросхема ЭВМ, осуществляющая операции по обработке информации и управляющая работой остальных устройств ЭВМ.
Процессор представляет собой микросхему с большим числом контактов, имеющую прямоугольную или квадратную форму и легко помещающуюся на ладони.
Изобретателем микропроцессора как схемы, в которую собрана практически вся основная электроника компьютера, стала американская фирма INTEL, выпустившая в 1970 году процессор 8008.
В своей работе процессор использует регистры — ячейки памяти, находящиеся внутри процессора. На рисунке приведена общая схема процессора.
Общая структурная схема процессора
Процессор разделен на две части:
операционное устройство (ОУ) и шинный интерфейс (ШИ).
Назначение ОУ — выполнение команд, а ШИ подготавливает команды и данные для выполнения. ОУ содержит:
арифметико-логическое устройство (АЛУ) — «отвечает» за выполнение команд,
устройство управления (УУ) — осуществляет выборку команд из памяти, пересылку их на АЛУ и перемещение полученных результатов в требуемую ячейку памяти;
10 регистров — применяются при вычислениях.
Эти устройства обеспечивают выполнение команд, арифметические вычисления и логические операции.
Три элемента ШИ — блок управления шиной, очередь команд и сегментные регистры — осуществляют следующие функции:
передачу данных на ОУ, в память и на внешние устройства ввода/вывода;
адресацию памяти с помощью четырех сегментных регистров;
выборку команд, требуемых для выполнения, из памяти в очередь команд.
Компьютер имеет два типа внутренней памяти. Постоянная память (ПЗУ или ROM — read-only memory). Она представляет собой специальную микросхему, из которой возможно только чтение, так как данные в ней специальным образом «прожигаются» и не могут быть модифицированы. Ее основное назначение: поддержка процедур начальной загрузки, выполнение различных проверок и т.д. Для целей программирования наиболее важным элементом ПЗУ является BIOS (Basic Input/Output System) — базовая система ввода/вывода.
Память, с которой имеет дело программист, называется ОЗУ (RAM — random access memory) — оперативное запоминающее устройство. Ее содержимое доступно как для чтения, так и для записи. Здесь хранятся программы и данные во время работы компьютера.
Основным устройством обработки информации в ЭВМ является арифметико-логическое устройство (АЛУ). Его основой является электронная схема, составленная из большого числа транзисторов, называемая сумматором. Сумматором выполняются простейшие логические и арифметические операции над данными, представленными в виде двоичных кодов (нулей и единиц). К логическим операциям относятся логическое умножение (операция «И»), логическое сложение (операция «ИЛИ») и логическое отрицание (операция «НЕ»). Результатом операции логического умножения является 1, если все переменные, являющиеся исходными данными равны 1, и 0, если хотя бы одна из них равна 0. Вспоминая, что 1 моделируется электрическим сигналом, а 0 — отсутствием сигнала, можно сказать, что на выходе устройства будет электрический сигнал тогда и только тогда, когда сигнал будет иметься на каждом входе:
К логическим операциям относятся логическое умножение (операция «И»), логическое сложение (операция «ИЛИ») и логическое отрицание (операция «НЕ»). Результатом операции логического умножения является 1, если все переменные, являющиеся исходными данными равны 1, и 0, если хотя бы одна из них равна 0. Вспоминая, что 1 моделируется электрическим сигналом, а 0 — отсутствием сигнала, можно сказать, что на выходе устройства будет электрический сигнал тогда и только тогда, когда сигнал будет иметься на каждом входе:
Результатом операции логического сложения является 0, если все исходные переменные равны нулю, и 1, если хотя бы одна из них равна 1. Результатом операции логического отрицания является 1, если на входе- 0, и 0, если на входе -1.
На основе этих трех операций можно производить арифметические действия над числами, представленными в виде нулей и единиц. Теоретической основой для этого являются законы, разработанные еще в 1847 году ирландским математиком Джорджем Булем, известные как Булева алгебра, в которой используются только два числа- 0 и 1. Ранее считалось, что эти работы Буля никому не нужны, и их автор подвергался насмешкам. Однако, в 1938 году американский инженер Клод Шеннон положил Булеву алгебру в основу теории электрических и электронных переключательных схем- сумматоров, создание которых и привело к появлению ЭВМ, способных автоматически производить арифметические вычисления.
Ранее считалось, что эти работы Буля никому не нужны, и их автор подвергался насмешкам. Однако, в 1938 году американский инженер Клод Шеннон положил Булеву алгебру в основу теории электрических и электронных переключательных схем- сумматоров, создание которых и привело к появлению ЭВМ, способных автоматически производить арифметические вычисления.
Все остальные операции, производимые ЭВМ, сводятся к большому числу простейших арифметических и логических операций, аналогично тому, как операцию умножения можно свести к большому числу операций сложения.
В современных ЭВМ арифметико-логическое устройство объединяется с управляющими устройствами в единую схему — процессор.
В компьютерных системах работа с памятью основывается на очень простых концепциях. В принципе, все, что требуется от компьютерной памяти, — это сохранять один бит информации так, чтобы потом он мог быть извлечен оттуда.
Одним из основных элементов компьютера, позволяющим ему нормально функционировать, является память. Внутренняя память компьютера — это место хранения информации, с которой он работает. Внутренняя память компьютера является временным рабочим пространством; в отличие от нее внешняя память, такая как файл на дискете, предназначена для долговременного хранения информации. Информация во внутренней памяти не сохраняется при выключении питания.
Внутренняя память компьютера — это место хранения информации, с которой он работает. Внутренняя память компьютера является временным рабочим пространством; в отличие от нее внешняя память, такая как файл на дискете, предназначена для долговременного хранения информации. Информация во внутренней памяти не сохраняется при выключении питания.
Каждая ячейка памяти имеет адрес, который используется для ее нахождения. Адреса — это числа, начиная с нуля для первой ячейки, увеличивающиеся по направлению к последней ячейке памяти. Поскольку адреса — это те же числа, компьютер может использовать арифметические операции для вычисления адресов памяти.
Архитектура каждого компьютера накладывает собственные ограничения на величину адресов. Наибольший возможный адрес определяет объем адресного пространства компьютера или то, какой объем памяти он может использовать. Обычно компьютер использует память меньшего объема, чем допускается его возможностями адресации. Если архитектура компьютера предусматривает наибольшее адресное пространство, это накладывает суровые ограничения на возможности такого компьютера. Адреса в 8088 имеют длину 20 бит, следовательно, процессор позволяет адресовать два в двадцатой степени байта или 1024 К.
Адреса в 8088 имеют длину 20 бит, следовательно, процессор позволяет адресовать два в двадцатой степени байта или 1024 К.
Ячейки памяти и их адреса.
Память — часть компьютера, где хранятся программы и данные. Можно также употреблять термин «запоминающее устройство». Без памяти, откуда процессоры считывают и куда записывают информацию, не было бы цифровых компьютеров со встроенными программами.
1.1.Бит
Основной единицей памяти является двоичный разряд, который называется битом. Бит может содержать 0 или 1. Эта самая маленькая единица памяти. (Устройство, в котором хранятся только нули, вряд ли могло быть основой памяти. Необходимы по крайней мере две величины.) Многие полагают, что в компьютерах используется бинарная арифметика, потому что это «эффективно». Они имеют в виду (хотя сами это редко осознают),
что цифровая информация может храниться благодаря различию между разными величинами какой-либо физической характеристики, например напряжения или тока. Чем больше величин, которые нужно различать, тем меньше различий между смежными величинами и тем менее надежна память. Двоичная система требует различения всего двух величин, следовательно, это самый надежный метод кодирования цифровой информации. Если вы не знакомы с двоичной системой счисления, смотрите Приложение А.
Чем больше величин, которые нужно различать, тем меньше различий между смежными величинами и тем менее надежна память. Двоичная система требует различения всего двух величин, следовательно, это самый надежный метод кодирования цифровой информации. Если вы не знакомы с двоичной системой счисления, смотрите Приложение А.
Считается, что некоторые компьютеры, например большие IBM, используют и десятичную, и двоичную арифметику. На самом деле здесь применяется так называемый двоично-десятичный код. Для хранения одного десятичного разряда используется 4 бита. Эти 4 бита дают 16 комбинаций для размещения 10 различных значений (от 0 до 9). При этом 6 оставшихся комбинаций не используются. Ниже показано число 1944 в двоично-десятичной и чисто двоичной системах счисления; в обоих случаях используется 16 битов:
десятичное: 0001 10010100 0100 двоичное: 0000011110011000
16 битов в двоично-десятичном формате могут хранить числа от 0 до 9999, то есть всего 10000 различных комбинаций, а 16 битов в двоичном формате — 65536 комбинаций.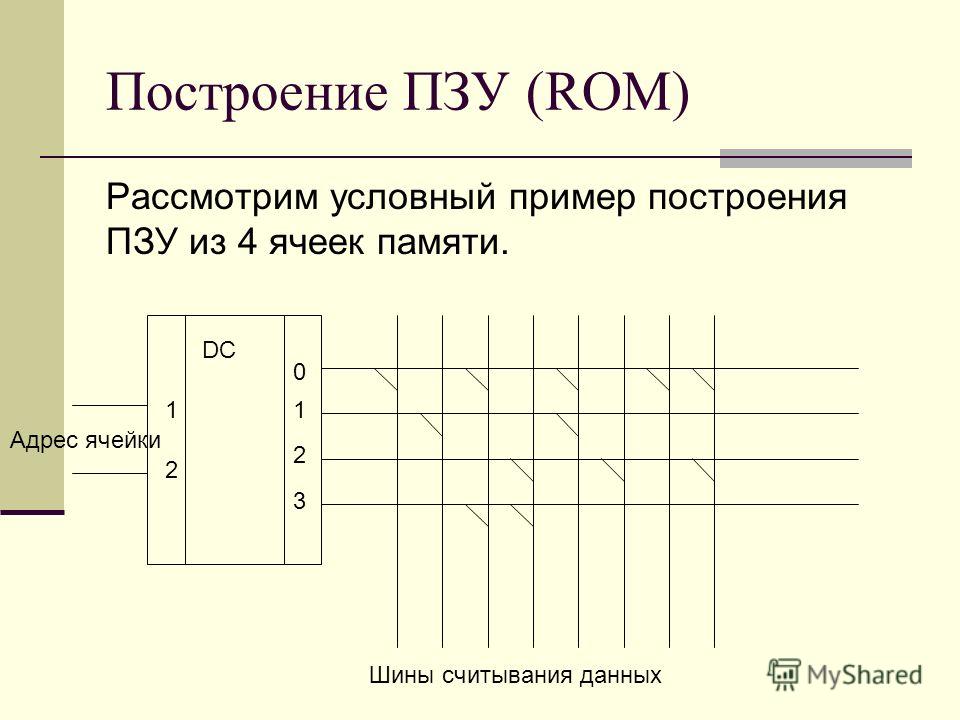 Именно по этой причине говорят, что двоичная система эффективнее.
Именно по этой причине говорят, что двоичная система эффективнее.
Однако представим, что могло бы произойти, если бы какой-нибудь гениаль-
ный молодой инженер придумал очень надежное электронное устройство, которое могло бы хранить разряды от 0 до 9, разделив участок напряжения от 0 до 10 В на 10 интервалов. Четыре таких устройства могли бы хранить десятичное число от 0 до 9999, то есть 10 000 комбинаций. А если бы те же устройства использовались для хранения двоичных чисел, они могли бы содержать всего 16 комбинаций. Естественно, в этом случае десятичная система была бы более эффективной.
1.2.Адреса памяти
Память состоит из ячеек, каждая из которых может хранить некоторую порцию информации. Каждая ячейка имеет номер, который называется адресом, По адресу программы могут ссылаться на определенную ячейку. Если память содержит п ячеек, они будут иметь адреса от 0 до п-1. Все ячейки памяти содержат одинаковое число битов. Если ячейка состоит из к битов, она может содержать любую из 2к комбинаций. На рис. 2.8 показаны 3 различных способа организации 96-битной памяти. Отметим, что соседние ячейки по определению имеют последовательные адреса.
Если ячейка состоит из к битов, она может содержать любую из 2к комбинаций. На рис. 2.8 показаны 3 различных способа организации 96-битной памяти. Отметим, что соседние ячейки по определению имеют последовательные адреса.
В компьютерах, где используется двоичная система счисления (включая восьмеричное и шестнадцатеричное представление двоичных чисел), адреса памяти также выражаются в двоичных числах. Если адрес состоит из m битов, максимальное число адресованных ячеек будет составлять 2П|. Например, адрес для обращения к памяти, изображенной на рис. 2.8, а, должен состоять, по крайней мере, из 4 битов, чтобы выражать все числа от 0 до 11. При устройстве памяти, показанном на рис. 2.8, 6 и 2.8, в, достаточно 3-битного адреса. Число битов в адресе определяет максимальное количество адресованных ячеек памяти и не зависит от числа битов в ячейке. 12-битные адреса нужны и памяти с 212 ячеек по 8 битов каждая, и памяти с 212 ячеек по 64 бита каждая.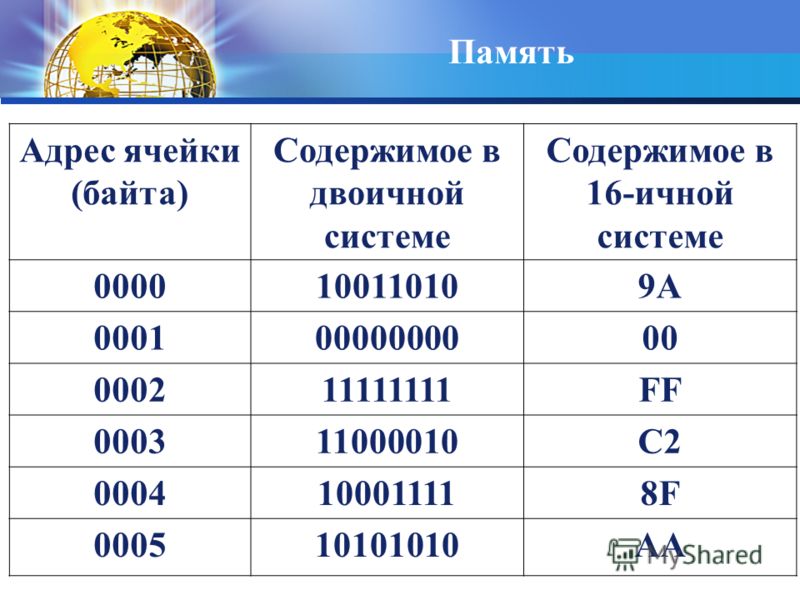
В табл. 2.1 показано число битов в ячейке для некоторых коммерческих компьютеров.
Ячейка — минимальная единица, к которой можно обращаться, В последние
годы практически все производители выпускают компьютеры с 8-битными ячейками, которые называются байтами, Байты группируются в слова. Компьютер с 32-битными словами имеет 4 байта на каждое слово, а компьютер с 64-битными словами — 8 байтов на каждое слово. Такая единица, как слово, необходима, поскольку большинство команд производят операции над целыми словами (например, складывают два слова). Таким образом, 32-битная машина будет содержать 32-битные регистры и команды для манипуляций с 32-битными словами, тогда как 64-битная машина будет иметь 64-битные регистры и команды для перемещения, сложения, вычитания и других операций над 64-битными словами.
1.3.Упорядочение байтов
Байты в слове могут нумероваться слева направо или справа налево. На первый взгляд может показаться, что между этими двумя вариантами нет разницы, но мы скоро увидим, что выбор имеет большое значение. На рис. 2.9, а изображена часть памяти 32-битного компьютера, в котором байты пронумерованы слева направо (как у компьютеров SPARC или больших IBM). Рисунок 2.9,6 показывает аналогичную репрезентацию 32-битного компьютера с нумерацией байтов справа налево (как у компьютеров Intel).
На первый взгляд может показаться, что между этими двумя вариантами нет разницы, но мы скоро увидим, что выбор имеет большое значение. На рис. 2.9, а изображена часть памяти 32-битного компьютера, в котором байты пронумерованы слева направо (как у компьютеров SPARC или больших IBM). Рисунок 2.9,6 показывает аналогичную репрезентацию 32-битного компьютера с нумерацией байтов справа налево (как у компьютеров Intel).
Важно понимать, что в обеих системах 32-битное целое число (например, 6)
представлено битами 110 в трех крайних правых битах слова, а остальные 29 битов представлены нулями. Если байты нумеруются слева направо, биты 110 находятся в байте 3 (или 7, или 11 и т. д.). Если байты нумеруются справа налево, биты 110 находятся в байте 0 (или 4, или 8 и т. д.). В обоих случаях слово, содержащее это целое число, имеет адрес 0.
Если компьютеры содержат только целые числа, никаких сложностей не возникает. Однако многие прикладные задачи требуют использования не только целых чисел, но и цепочек символов и других типов данных. Рассмотрим, например, простую запись данных персонала, состоящую из цепочки символов (имя сотрудника) и двух целых чисел (возраст и номер отдела). Цепочка символов завершается одним или несколькими байтами 0, чтобы заполнить слово. На рис. 2.10, а представлена схема с нумерацией байтов слева направо, а на рис. 2.10, б — с нумерацией байтов
Рассмотрим, например, простую запись данных персонала, состоящую из цепочки символов (имя сотрудника) и двух целых чисел (возраст и номер отдела). Цепочка символов завершается одним или несколькими байтами 0, чтобы заполнить слово. На рис. 2.10, а представлена схема с нумерацией байтов слева направо, а на рис. 2.10, б — с нумерацией байтов
справа налево для записи «Jim Smith, 21 год, отдел 260» (1×256+4=260).
Оба эти представления хороши и внутренне последовательны. Проблемы начинаются тогда, когда один из компьютеров пытается переслать эту запись на Другой компьютер по сети. Предположим, что машина с нумерацией байтов слева направо пересылает запись на компьютер с нумерацией байтов справа налево по одному байту, начиная с байта 0 и заканчивая байтом 19. Для простоты будем считать, что биты, не инвертируются при передаче. Таким образом, байт 0 переносится из первой машины на вторую в байт 0 и т. д., как показано на рис. 2.10, в.
Компьютер, получивший запись, имя печатает правильно, но возраст получа-
ется 21х224, и номер отдела тоже искажается. Такая ситуация возникает, поскольку при передаче записи порядок букв в слове меняется так, как нужно, но при этом порядок байтов целых чисел тоже изменяется, что приводит к неверному результату.
Такая ситуация возникает, поскольку при передаче записи порядок букв в слове меняется так, как нужно, но при этом порядок байтов целых чисел тоже изменяется, что приводит к неверному результату.
Очевидное решение этой проблемы — наличие программного обеспечения, которое инвертировало бы байты в слове после того, как сделана копия. Результат такой операции изображен на рис. 2.10, г. Мы видим, что числа стали правильными, но цепочка символов превратилась в «MIJTIMS», при этом «Н» вообще поместилась отдельно. Цепочка переворачивается потому, что компьютер сначала считывает байт 0 (пробел), затем байт 1 (М) и т. д.
Простого решения не существует. Есть один способ, но он неэффективен. (Нужно перед каждой единицей данных помещать заголовок, информирующий, какой тип данных последует за ним — цепочка, целое число и т. д. Это позволит компьютеру-получателю производить только необходимые преобразования.) Ясно, что отсутствие стандарта упорядочивания байтов является главным неудобством при обмене информацией между разными машинами.
1.4.Код с исправлением ошибок
Память компьютера время от времени может делать ошибки из-за всплесков напряжения на линии электропередачи и по другим причинам. Чтобы бороться с такими ошибками, используются коды с обнаружением и исправлением ошибок. При этом к каждому слову в памяти особым образом добавляются дополнительные биты. Когда слово считывается из памяти, эти биты проверяются на наличие ошибок. Чтобы понять, как обращаться с ошибками, необходимо внимательно изучить, что представляют собой эти ошибки. Предположим, что слово состоит из m битов данных, к которым мы прибавляем г дополнительных битов (контрольных разрядов).
Пусть общая длина слова будет п (то есть п=т+г). n-битную единицу, содержащую m битов данных и г контрольных разрядов, часто называют кодированным словом. Для любых двух кодированных слов, например 10001001 и 10110001, можно определить, сколько соответствующих битов в них различается. В данном примере таких бита три. Чтобы определить количество различающихся битов, нужно над двумя кодированными словами произвести логическую операцию ИСКЛЮЧАЮЩЕЕ ИЛИ и сосчитать число битов со значением 1 в полученном результате. Число битовых позиций, по которым различаются два слова, называется интервалом Хэмминга. Если интервал Хэмминга для двух слов равен d, это значит, что достаточно d битовых ошибок, чтобы превратить одно слово в другое. Например, интервал Хэмминга кодированных слов 11110001 и 00110000 равен 3, поскольку для превращения первого слова во второе достаточно 3 ошибок в битах.
Чтобы определить количество различающихся битов, нужно над двумя кодированными словами произвести логическую операцию ИСКЛЮЧАЮЩЕЕ ИЛИ и сосчитать число битов со значением 1 в полученном результате. Число битовых позиций, по которым различаются два слова, называется интервалом Хэмминга. Если интервал Хэмминга для двух слов равен d, это значит, что достаточно d битовых ошибок, чтобы превратить одно слово в другое. Например, интервал Хэмминга кодированных слов 11110001 и 00110000 равен 3, поскольку для превращения первого слова во второе достаточно 3 ошибок в битах.
Память состоит из m-битных слов, и следовательно, существует 2т вариантов
сочетания битов. Кодированные слова состоят из п битов, но из-за способа подсчета контрольных разрядов допустимы только 2Ш из 2″ кодированных слов. Если в памяти обнаруживается недопустимое кодированное слово, компьютер знает, что произошла ошибка. При наличии алгоритма для подсчета контрольных разрядов можно составить полный список допустимых кодированных слов и из этого списка найти два слова, для которых интервал Хэмминга будет минимальным. Это интервал Хэмминга полного кода.
Это интервал Хэмминга полного кода.
Свойства проверки и исправления ошибок определенного кода зависят от его
интервала Хэмминга. Чтобы обнаружить d ошибок в битах, необходим код с интервалом d+1, поскольку d ошибок не могут изменить одно допустимое кодированное слово на другое допустимое кодированное слово Соответственно, чтобы исправить d ошибок в битах, необходим код с интервалом 2d+l, поскольку в этом случае допустимые кодированные слова так сильно отличаются друг от друга, что даже если произойдет d изменений, изначальное кодированное слово будет ближе к ошибочному, чем любое другое кодированное слово, поэтому его без труда можно будет определить.
В качестве простого примера кода с обнаружением ошибок рассмотрим код, в котором к данным присоединяется один бит четности. Бит четности выбирается таким образом, что число битов со значением 1 в кодированном слове четное (или нечетное). Интервал этого кода равен 2, поскольку любая ошибка в битах приводит к кодированному слову с неправильной четностью. Другими словами, достаточно двух ошибок в битах для перехода от одного допустимого кодированного слова к другому допустимому слову. Такой код может использоваться для обнаружения одиночных ошибок. Если из памяти считывается слово, содержащее неверную четность, поступает сигнал об ошибке. Программа не сможет продолжаться, но зато не будет неверных результатов. В качестве простого примера кода с исправлением ошибок рассмотрим код с четырьмя допустимыми кодированными словами:
Другими словами, достаточно двух ошибок в битах для перехода от одного допустимого кодированного слова к другому допустимому слову. Такой код может использоваться для обнаружения одиночных ошибок. Если из памяти считывается слово, содержащее неверную четность, поступает сигнал об ошибке. Программа не сможет продолжаться, но зато не будет неверных результатов. В качестве простого примера кода с исправлением ошибок рассмотрим код с четырьмя допустимыми кодированными словами:
0000000000,0000011111, ШИОООООи 1111111111
Интервал этого кода равен 5. Это значит, что он может исправлять двойные
ошибки. Если появляется кодированное слово 0000000111, компьютер знает, что изначальное слово должно быть 0000011111 (если произошло не более двух ошибок). При наличии трех ошибок, если, например, слово 0000000000 изменилось на 0000000111, этот метод недопустим.
Представим, что мы хотим разработать код с m битами данных и г контрольных разрядов, который позволил бы исправлять все ошибки в битах. Каждое из 2т допустимых слов имеет п недопустимых кодированных слов, которые отличаются от допустимого одним битом. Они образуются инвертированием каждого из п битов в n-битном кодированном слове. Следовательно, каждое из 2т допустимых слов требует п+1 возможных сочетаний битов, приписываемых этому слову (п возможных ошибочных вариантов и один правильный). Поскольку общее число различных сочетаний битов равно 2П, то (п+1)2га<2п. Так как n-ш+г, следовательно,
Каждое из 2т допустимых слов имеет п недопустимых кодированных слов, которые отличаются от допустимого одним битом. Они образуются инвертированием каждого из п битов в n-битном кодированном слове. Следовательно, каждое из 2т допустимых слов требует п+1 возможных сочетаний битов, приписываемых этому слову (п возможных ошибочных вариантов и один правильный). Поскольку общее число различных сочетаний битов равно 2П, то (п+1)2га<2п. Так как n-ш+г, следовательно,
(т+г+ 1)<2Г. Эта формула дает нижний предел числа контрольных разрядов, необходимых для исправления одиночных ошибок. В табл 2.2 показано необходимое количество контрольных разрядов для слов разного размера.
Этого теоретического нижнего предела можно достичь, используя метод Ричарда Хэмминга. Но прежде чем обратиться к этому алгоритму, давайте рассмотрим простую графическую схему, которая четко иллюстрирует идею кода с исправлением ошибок для 4-битных слов. Диаграмма Венна на рис. 2.11 содержит 3 круга, А, В и С, которые вместе образуют семь секторов. Давайте закодируем в качестве примера слово из 4 битов 1100 в сектора АВ, ABC, AC и ВС, по одному биту в каждом секторе (в алфавитном порядке). Кодирование показано на рис. 2.11, а.
Давайте закодируем в качестве примера слово из 4 битов 1100 в сектора АВ, ABC, AC и ВС, по одному биту в каждом секторе (в алфавитном порядке). Кодирование показано на рис. 2.11, а.
Далее мы добавим бит четности к каждому из трех пустых секторов, чтобы получилась положительная четность, как показано на рис. 2.11, б. По определению сумма битов в каждом из трех кругов, А, В, и С, должна быть четной. В круге А находится 4 числа: 0, 0, 1 и 1, которые в сумме дают четное число 2. В круге В находятся числа 1, 1, 0 и 0, которые также при сложении дают четное число 2. То же имеет силу и для круга С. В данном примере получилось так, что все суммы одинаковы, но вообще возможны случаи с суммами 0 и 4. Рисунок соответствует кодированному слову, состоящему из 4 битов данных и 3 битов четности. Предположим, что бит в секторе АС изменился с 0 на 1, как показано на рис. 2.11, в. Компьютер видит, что круги А и С имеют отрицательную четность. Единственный способ исправить ошибку, изменив только один бит, -возвраще-
ние биту АС значения 0. Таким способом компьютер может исправлять одиночные ошибки автоматически.
Таким способом компьютер может исправлять одиночные ошибки автоматически.
А теперь посмотрим, как может использоваться алгоритм Хэмминга при создании кодов с исправлением ошибок для слов любого размера. В коде Хэмминга к слову, состоящему из m битов, добавляется г битов четности, при этом образуется слово длиной т+г битов. Биты нумеруются с единицы (а не с нуля), причем первым считается крайний левый. Все биты, номера которых — степени двойки, являются битами четности; остальные используются для данных. Например, к 16-битному слову нужно добавить 5 битов четности. Биты с номерами 1, 2, 4, 8 и 16 — биты четности, а все остальные — биты данных. Всего слово содержит 21 бит (16 битов данных и 5 битов четности). В рассматриваемом примере мы будем использовать
положительную четность (выбор произвольный). Каждый бит четности проверяет определенные битовые позиции. Общее число битов со значением 1 в проверяемых позициях должно быть четным. Ниже указаны позиции проверки для каждого бита четности:
Бит 1 проверяет биты 1, 3, 5,7, 9,11, 13,15,17,19, 21.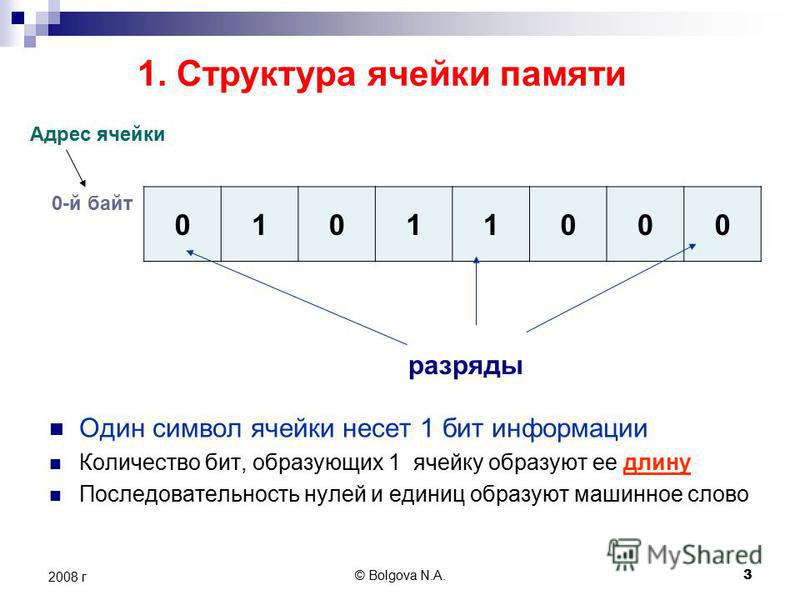
Бит 2 проверяет биты 2, 3, 6, 7,10,11,14,15,18,19.
Бит 4 проверяет биты 4, 5,6, 7,12,13,14,15, 20, 21.
Бит 8 проверяет биты 8,9,10, И, 12,13,14, 15.
Бит 16 проверяет биты 16,17,18,19, 20, 21.
В общем случае бит b проверяется битамиЪи Ь2,…, bJt такими что bi+b2+… +b,=b. Например, бит 5 проверяется битами 1 и 4, поскольку 1+4=5. Бит 6 проверяется битами 2 и 4, поскольку 2+4=6 и т. д.
На рис. 2.12 показано построение кода Хэмминга для 16-битного слова
1111000010101110 Соответствующим 21-битным кодированным словом является 001011100000101101110. Чтобы увидеть, как происходит исправление ошибок, рассмотрим, что произойдет, если бит 5 изменит значение из-за резкого скачка напряжения на линии электропередачи. В результате вместо кодированного слова 001011100000101101110 получится 001001100000101101 ПО. Будут проверены 5 битов четности.
Вот результаты проверки:
Бит четности 1 неправильный (биты 1, 3, 5, 7,9, 11, 13, 15, 17, 19, 21 содержат
пять единиц).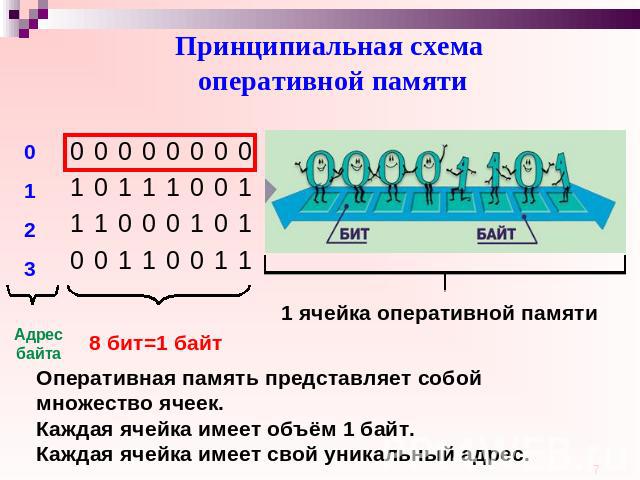
Бит четности 2 правильный (биты 2, 3, 6,7,10,11,14,15,18,19 содержат шесть
единиц).
Бит четности 4 неправильный (биты 4,5,6,7,12,13,14,15,20,21 содержат пять
единиц).
Бит четности 8 правильный (биты 8,9,10,11,12,13,14,15 содержат две единицы).
Битчетности 16 правильный (биты 16,17,18,19,20,21 содержат четыре единицы).
Общее число единиц в битах 1, 3, 5, 7, 9, 11, 13, 15, 17, 19 и 21 должно быть
четным, поскольку в данном случае используется положительная четность. Неправильным должен быть один из битов, проверяемых битом четности 1 (а именно 1,3,5,7,9,11,13,15,17,19 и 21). Бит четности 4 тоже неправильный. Это значит, чтоизменил значение один из следующих битов: 4,5,6,7,12,13,14,15,20,21. Ошибка должна быть в бите, который содержится в обоих списках. В данном случае общими являются биты 5,7,13,15 и 21. Поскольку бит четности 2 правильный, биты 7 и 15 исключаются. Правильность бита четности 8 исключает наличие ошибки в бите 13.
Наконец, бит 21 также исключается, поскольку бит четности 16 правильный. В итоге остается бит 5, в котором и содержится ошибка. Поскольку этот бит имеет значение 1, он должен принять значение 0. Именно таким образом исправляются ошибки.
Чтобы найти неправильный бит, сначала нужно подсчитать все биты четности. Если они правильные, ошибки нет (или есть, но больше одной). Если обнаружились неправильные биты четности, то нужно сложить их номера. Сумма, полученная в результате, даст номер позиции неправильного бита. Например, если биты четности 1 и 4 неправильные, а 2,8 и 16 правильные, то ошибка произошла в бите 5 (1+4).
2.Кэш-память
Процессоры всегда работали быстрее, чем память. Процессоры и память совершенствовались параллельно, поэтому это несоответствие сохранялось. Поскольку на микросхему можно помещать все больше и больше транзисторов, разработчики процессоров использовали эти преимущества для создания конвейеров и суперскалярной архитектуры, что еще больше повышало скорость работы процессоров. Разработчики памяти обычно использовали новые технологии для увеличения емкости, а не скорости, что еще больше усугубляло проблему. На практике такое несоответствие в скорости работы приводит к следующему: после того как процессор дает запрос памяти, должно пройти много циклов, прежде чем он получит слово,
Разработчики памяти обычно использовали новые технологии для увеличения емкости, а не скорости, что еще больше усугубляло проблему. На практике такое несоответствие в скорости работы приводит к следующему: после того как процессор дает запрос памяти, должно пройти много циклов, прежде чем он получит слово,
которое ему нужно. Чем медленнее работает память, тем дольше процессору приходится ждать, тем больше циклов должно пройти.
Как мы уже говорили выше, есть два пути решения этой проблемы. Самый простой из них — начать считывать информацию из памяти, когда это необходимо, и при этом продолжать выполнение команд, но если какая-либо команда попытается использовать слово до того, как оно считалось из памяти, процессор должен приостанавливать работу. Чем медленнее работает память, тем чаще будет возникать такая проблема и тем больше будет проигрыш в работе. Например, если отсрочка составляет 10 циклов, весьма вероятно, что одна из 10 следующих команд попытается использовать слово, которое еще не считалось из памяти.
Другое решение проблемы — сконструировать машину, которая не приостанавливает работу, но следит, чтобы программы-компиляторы не использовали слова до того, как они считаются из памяти. Однако это не так просто осуществить на практике. Часто при выполнении команды загрузки машина не может выполнять другие действия, поэтому компилятор вынужден вставлять пустые команды, которые не производят никаких операций, но при этом занимают место в памяти. В действительности при таком подходе простаивает не аппаратное, а программное обеспечение, но снижение производительности при этом такое же. На самом деле эта проблема не технологическая, а экономическая. Инженеры знают, как построить память, которая будет работать так же быстро, как и процессор, но при этом ее приходится помещать прямо на микросхему процессора (поскольку информация через шину поступает очень медленно). Установка большой памяти на микросхему процессора делает его больше и, следовательно, дороже, и даже если бы стоимость не имела значения, все равно существуют ограничения в размерах процессора, который можно сконструировать. Таким образом, приходится выбирать между быстрой памятью небольшого размера и медленной памятью большого размера. Мы бы предпочли память большого размера с высокой скоростью работы по низкой цене. Интересно отметить, что существуют технологии сочетания маленькой и быстрой памяти с большой и медленной, что позволяет получить и высокую скорость работы, и большую емкость по разумной цене. Маленькая память с высокой скоростью работы называется кэш-памятью (от французского слова cacher «прятать»1;читается «кэш»). Ниже мы кратко опишем, как используется кэш-память и как она работает. Более подробное описание см. в главе 4. Основная идея кэш-памяти проста: в ней находятся слова, которые чаще всего используются. Если процессору нужно какое-нибудь слово, сначала он обращается к кэш-памяти. Только в том случае, если слова там нет, он обращается к основной памяти. Если значительная часть слов находится в кэш-памяти, среднее время доступа значительно сокращается. Таким образом, успех или неудача зависит от того, какая часть слов находится в кэш-памяти.
Таким образом, приходится выбирать между быстрой памятью небольшого размера и медленной памятью большого размера. Мы бы предпочли память большого размера с высокой скоростью работы по низкой цене. Интересно отметить, что существуют технологии сочетания маленькой и быстрой памяти с большой и медленной, что позволяет получить и высокую скорость работы, и большую емкость по разумной цене. Маленькая память с высокой скоростью работы называется кэш-памятью (от французского слова cacher «прятать»1;читается «кэш»). Ниже мы кратко опишем, как используется кэш-память и как она работает. Более подробное описание см. в главе 4. Основная идея кэш-памяти проста: в ней находятся слова, которые чаще всего используются. Если процессору нужно какое-нибудь слово, сначала он обращается к кэш-памяти. Только в том случае, если слова там нет, он обращается к основной памяти. Если значительная часть слов находится в кэш-памяти, среднее время доступа значительно сокращается. Таким образом, успех или неудача зависит от того, какая часть слов находится в кэш-памяти. Давно известно, что программы не обращаются к памяти наугад. Если программе нужен доступ к адресу А, то скорее всего после этого ей понадобится доступ к адресу, расположенному поблизости от А. Практически все команды обычной программы (за исключением команд перехода и вызова процедур) вызываются из последовательных участков памяти. Кроме того, большую часть времени программа тратит на циклы, когда ограниченный набор команд выполняется снова и снова. Точно так же при манипулировании матрицами программа, скорее всего, будет обращаться много раз к одной и той же матрице, прежде чем перейдет к чему-либо другому. То, что при последовательных отсылках к памяти в течение некоторого промежутка времени используется только небольшой ее участок, называется принципом локальности. Этот принцип составляет основу всех систем кэш-памяти. Идея состоит в следующем: когда определенное слово вызывается из памяти, оно вместе с соседними словами переносится в кэш-память, что позволяет при очередном запросе быстро обращаться к следующим словам.
Давно известно, что программы не обращаются к памяти наугад. Если программе нужен доступ к адресу А, то скорее всего после этого ей понадобится доступ к адресу, расположенному поблизости от А. Практически все команды обычной программы (за исключением команд перехода и вызова процедур) вызываются из последовательных участков памяти. Кроме того, большую часть времени программа тратит на циклы, когда ограниченный набор команд выполняется снова и снова. Точно так же при манипулировании матрицами программа, скорее всего, будет обращаться много раз к одной и той же матрице, прежде чем перейдет к чему-либо другому. То, что при последовательных отсылках к памяти в течение некоторого промежутка времени используется только небольшой ее участок, называется принципом локальности. Этот принцип составляет основу всех систем кэш-памяти. Идея состоит в следующем: когда определенное слово вызывается из памяти, оно вместе с соседними словами переносится в кэш-память, что позволяет при очередном запросе быстро обращаться к следующим словам.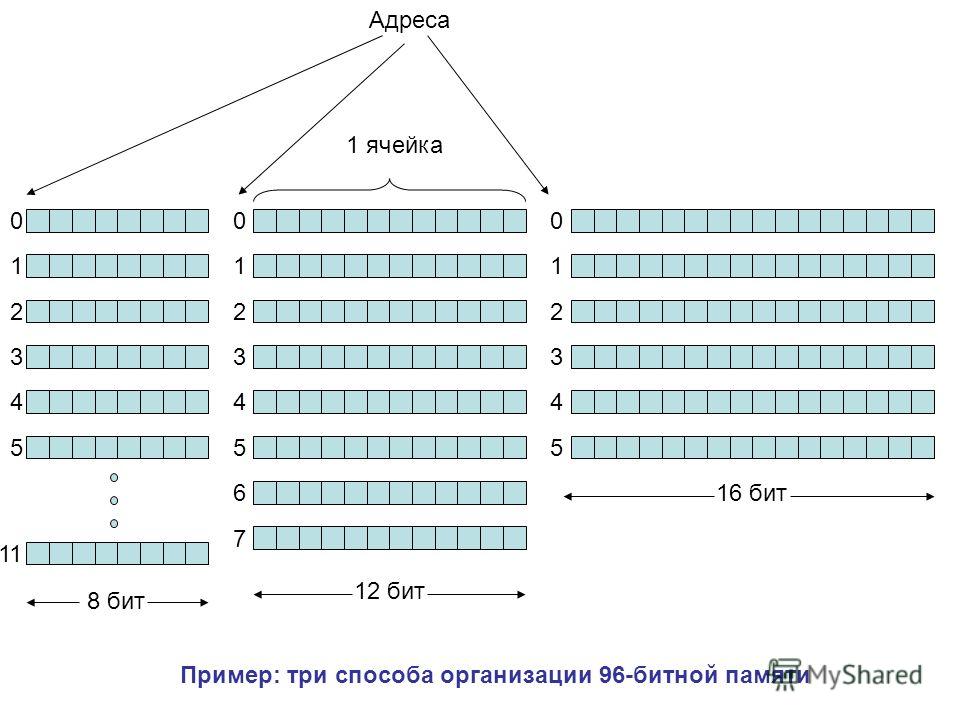 Общее устройство процессора, кэш-памяти и основной памяти показано на рис. 2.13. Если слово считывается или записывается к раз, компьютеру понадобится сделать 1 обращение к медленной основной памяти и к-1 обращений к быстрой кэш-памяти. Чем больше к, тем выше общая производительность.
Общее устройство процессора, кэш-памяти и основной памяти показано на рис. 2.13. Если слово считывается или записывается к раз, компьютеру понадобится сделать 1 обращение к медленной основной памяти и к-1 обращений к быстрой кэш-памяти. Чем больше к, тем выше общая производительность.
Мы можем сделать более строгие вычисления. Пусть с — время доступа к кэш-памяти, m — время доступа к основной памяти и h — коэффициент совпадения, который показывает соотношение числа ссылок к кэш-памяти и общего числа всех ссылок. В нашем примере h=(k~l)/k. Таким образом, мы можем вычислить среднее время доступа:
среднее время доступа =с+( 1 -h)m.
Если h—И и все обращения делаются только к кэш-памяти, то время доступа стремится к с. С другой стороны, если h—»0 и каждый раз нужно обращаться к основной памяти, то время доступа стремится к с+ш: сначала требуется время с для проверки кэш-памяти (в данном случае безуспешной), а затем время m для обращения к основной памяти. В некоторых системах обращение к основной памятиможет начинаться параллельно с исследованием кэш-памяти, чтобы в случае неудачного поиска цикл обращения к основной памяти уже начался. Однако эта стратегия требует способности останавливать процесс обращения к основной памяти в случае результативного обращения к кэш-памяти, что делает разработку такого компьютера более сложной. Основная память и кэш-память делятся на блоки фиксированного размера с учетом принципа локальности. Блоки внутри кэш-памяти обычно называют строками кэш-памяти (cache lines). Если обращение к кэш-памяти нерезультативно, из основной памяти в кэш-память загружается вся строка, а не только необходимое слово. Например, если строка состоит из 64 байтов, обращение к адресу 260 повлечет за собой загрузку в кэш-память всей строки, то есть с 256-го по 319-й байт.
В некоторых системах обращение к основной памятиможет начинаться параллельно с исследованием кэш-памяти, чтобы в случае неудачного поиска цикл обращения к основной памяти уже начался. Однако эта стратегия требует способности останавливать процесс обращения к основной памяти в случае результативного обращения к кэш-памяти, что делает разработку такого компьютера более сложной. Основная память и кэш-память делятся на блоки фиксированного размера с учетом принципа локальности. Блоки внутри кэш-памяти обычно называют строками кэш-памяти (cache lines). Если обращение к кэш-памяти нерезультативно, из основной памяти в кэш-память загружается вся строка, а не только необходимое слово. Например, если строка состоит из 64 байтов, обращение к адресу 260 повлечет за собой загрузку в кэш-память всей строки, то есть с 256-го по 319-й байт.
Возможно, через некоторое время понадобятся другие слова из этой строки. Такой путь обращения к памяти более эффективен, чем вызов каждого слова по отдельности, потому что вызвать к слов 1 раз можно гораздо быстрее, чем 1 слово к раз. Если входные сообщения кэш-памяти содержат более одного слова, это значит, что будет меньше таких входных сообщений и, следовательно, меньше непроизводительных затрат.
Если входные сообщения кэш-памяти содержат более одного слова, это значит, что будет меньше таких входных сообщений и, следовательно, меньше непроизводительных затрат.
Разработка кэш-памяти очень важна для процессоров с высокой производительностью.
Первый вопрос — размер кэш-памяти. Чем больше размер, тем лучше работает память, но тем дороже она стоит.
Второй вопрос — размер строки кэш-памяти. Кэш-память объемом 16 Кбайт можно разделить на 1К строк по 16 байтов, 2К строк по 8 байтов и т. д. Третий вопрос — как устроена кэш-память, то есть, как она определяет, какие именно слова содержатся в ней в данный момент. Устройство кэш-памяти мы рассмотрим подробно в главе 4.
Четвертый вопрос — должны ли команды и данные находиться вместе в общей кэш-памяти. Проще разработать смежную кэш-память, в которой хранятся и данные, и команды. При этом вызов команд и данных автоматически уравновешивается. Тем не менее, в настоящее время существует тенденция к использованию разделенной кэш-памяти, когда команды хранятся в одной кэш-памяти, а данные — в другой. Такая структура также называется Гарвардской (Harvard Architecture), поскольку идея использования отдельной памяти для команд и отдельной памяти для данных впервые воплотилась в компьютере Маге III, который был создай Говардом Айкеном в Гарварде. Современные разработчики пошли по этому пути, поскольку сейчас широко используются процессоры с конвейерами, а при такой организации должна быть возможность одновременного доступа и к командам, и к данным (операндам). Разделенная кэш-память позволяет осуществлять параллельный доступ, а общая — нет. К тому же, поскольку команды обычно не меняются во время выполнения, содержание командной кэш-памяти никогда не приходится записывать обратно в основную память.
Такая структура также называется Гарвардской (Harvard Architecture), поскольку идея использования отдельной памяти для команд и отдельной памяти для данных впервые воплотилась в компьютере Маге III, который был создай Говардом Айкеном в Гарварде. Современные разработчики пошли по этому пути, поскольку сейчас широко используются процессоры с конвейерами, а при такой организации должна быть возможность одновременного доступа и к командам, и к данным (операндам). Разделенная кэш-память позволяет осуществлять параллельный доступ, а общая — нет. К тому же, поскольку команды обычно не меняются во время выполнения, содержание командной кэш-памяти никогда не приходится записывать обратно в основную память.
Наконец, пятый вопрос — количество блоков кэш-памяти. В настоящее время очень часто кэш-память первого уровня располагается прямо на микросхеме процессора, кэш-память второго уровня — не на самой микросхеме, но в корпусе процессора, а кэш-память третьего уровня — еще дальше от процессора.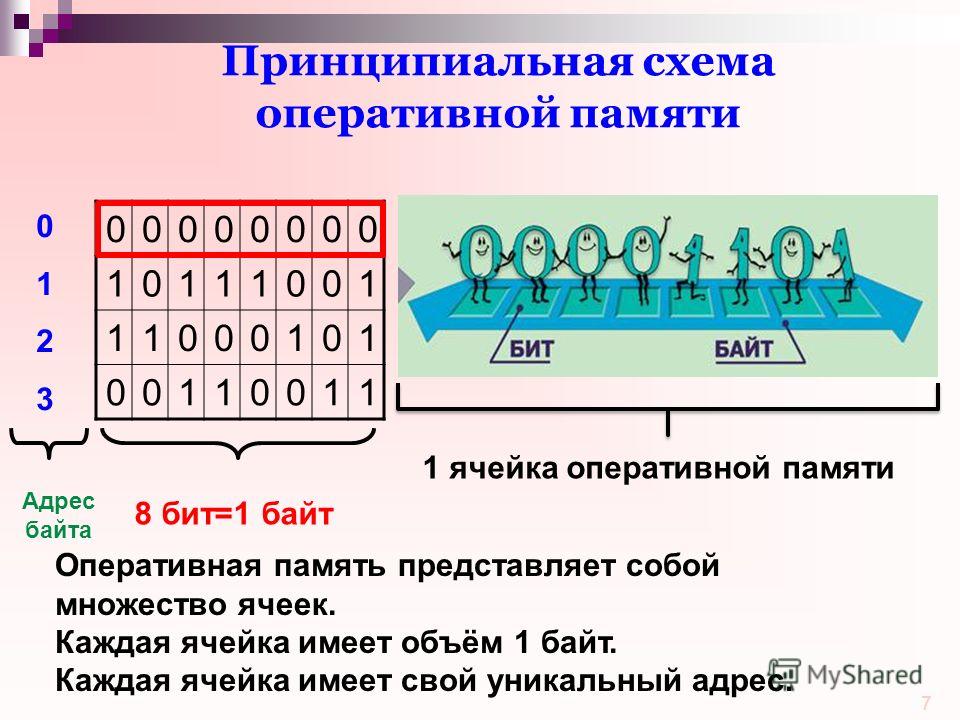
Модульное ОЗУ.
Сборка модулей памяти и их типы
Со времен появления полупроводниковой памяти и до начала 90-х годов все микросхемы памяти производились, продавались и устанавливались на плату компьютера по отдельности. Эти микросхемы вмещали от 1 Кбит до 1 Мбит информации и выше. В первых персональных компьютерах часто оставлялись пустые разъемы, чтобы покупатель в случае необходимости мог вставить дополнительные микросхемы.
В настоящее время распространен другой подход. Группа микросхем (обычно 8 или 16) монтируется на одну крошечную печатную плату и продается как один блок. Он называется SIMM (Single Inline Memory Module — модуль памяти, имеющий выводы с одной стороны) или DIMM (Dual Inline Memory Module — модуль памяти, у которого выводы расположены с двух сторон). У первого из них контакты расположены только на одной стороне печатной платы (выводы на второй стороне дублируют первую), а у второго — на обеих сторонах. Схема SIMM изображена на рис. 2.14.
Схема SIMM изображена на рис. 2.14.
Обычный модуль SIMM содержит 8 микросхем по 32 Мбит (4 Мбайт) каждая. Таким образом, весь модуль вмещает 32 Мбайт информации. Во многие компьютеры встраивается 4 модуля, следовательно, при использовании модулей SIMM по 32 Мбайт общий объем памяти составляет 128 Мбайт. При необходимости данные модули SIMM можно заменить модулями с большей вместимостью (64 Мбайт и выше).
У первых модулей SIMM было 30 контактов, и они могли передавать 8 битов
информации за один раз. Остальные контакты использовались для адресации и контроля. Более поздние модули содержали уже 72 контакта и передавали 32 бита информации за один раз. Для компьютера Pentium, который требовал одновременной передачи 64 битов, эти модули соединялись по два, и каждый из них доставлял половину требуемых битов. В настоящее время стандартным способом сборки является модуль DIMM. У него на каждой стороне платы находится по 84 позолоченных контакта, то есть всего 168. DIMM способен передавать 64 бита данных за раз. Вместимость DIMM обычно составляет 64 Мбайт и выше. В электронных записных книжках обычно используется модуль DIMM меньшего размера, который называется SO-DIMM (Small Outline DIMM). Модули SIMM и DIMM могут содержать бит четности или код исправления ошибок, однако, поскольку вероятность
DIMM способен передавать 64 бита данных за раз. Вместимость DIMM обычно составляет 64 Мбайт и выше. В электронных записных книжках обычно используется модуль DIMM меньшего размера, который называется SO-DIMM (Small Outline DIMM). Модули SIMM и DIMM могут содержать бит четности или код исправления ошибок, однако, поскольку вероятность
возникновения ошибок в модуле 1 ошибка в 10 лет, в большинстве обычных компьютеров методы обнаружения и исправления ошибок не применяются.
Лекция 5. Информационное обеспечение компьютера.
1. Шины информационного обмена.
2. Символьные терминалы.
3. Символьное кодирование информации.
Дата добавления: 2016-10-26; просмотров: 14878; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
Как определяются адреса оперативной памяти
Вопрос
Изменено 1 год, 2 месяца назад
Просмотрено 5k раз
Как на самом деле определяются или «создаются» адреса физической памяти. Что представляет собой процесс, в котором блокам байтов назначен адрес памяти?
Что представляет собой процесс, в котором блокам байтов назначен адрес памяти?
Я так понимаю, что это определяется во время загрузки, перед выполнением BIOS. Но не совсем уверен, как и что это за процесс.
- память
16
Я думаю, что другой ответ немного смутил вас, и снова для вопросов низкого уровня, подобных этому, я предлагаю вам изучить одну из архитектур микрокомпьютера 80-х или современных микроконтроллеров.
говорит о том, что адреса памяти назначаются при изготовлении микросхем ОЗУ
Это в корне неверно. Сами чипы не знают об абсолютных адресах с точки зрения программиста.
Ключ, который вам нужно понять, это «мультиплексор». Представьте, что у вас есть 8-битный компьютер с 8-битными адресами, подключенный к одной микросхеме ОЗУ. Внутри чипа мультиплексор декодирует 8-битный адрес в одно из 256 значений, эффективно включая один из 256 проводов. Это соединяет определенную группу из восьми ячеек в чипе с шиной данных, позволяя процессору считывать или записывать их.
Это соединяет определенную группу из восьми ячеек в чипе с шиной данных, позволяя процессору считывать или записывать их.
Пока все хорошо. Теперь вы решаете, что архитектуре требуется больше оперативной памяти. Таким образом, вы расширяете адресную шину до 12 бит. Но каждый чип RAM принимает только 8 бит адреса. Значит нужно еще один мультиплексор : на этот раз вы берете верхние 4 бита и декодируете их в одно из 16 возможных значений, а затем используете этот сигнал , чтобы решить, с какой из 16 микросхем ОЗУ в компьютере обмениваться данными.
Какой адрес соответствует какому оборудованию определяется логикой декодирования адреса, мультиплексор в середине.
ЦП обычно начинают выполнение с фиксированного адреса памяти, часто ближе к «верху» адресного пространства. Например, наш 12-битный ЦП начинается с 0xF00. В этом случае полезно расположить оборудование вокруг ЦП так, чтобы 0xF00 отображалось на ПЗУ. Это концепция «карты памяти».
откуда компьютер узнает адреса, делает ли он массивный запрос во время загрузки или что происходит?
Обычно используется сочетание методов. Процессор вслепую запустится по какому-то адресу, поэтому материнская плата должна предоставить некоторый код по этому адресу, например, BIOS ПК. Затем этот код , вероятно, срабатывает и сканирует память — у модулей DIMM есть небольшая микросхема ПЗУ на отдельной последовательной шине, которая описывает, насколько они велики и какую скорость они поддерживают.
Процессор вслепую запустится по какому-то адресу, поэтому материнская плата должна предоставить некоторый код по этому адресу, например, BIOS ПК. Затем этот код , вероятно, срабатывает и сканирует память — у модулей DIMM есть небольшая микросхема ПЗУ на отдельной последовательной шине, которая описывает, насколько они велики и какую скорость они поддерживают.
С другой стороны, небольшие системы могут иметь полностью фиксированную структуру памяти, выбранную разработчиком.
Карты PCI также могут быть отображены в пространстве памяти BIOS во время загрузки. Это позволяет процессору найти видеопамять (часто на отдельной карте) и запустить дисплей.
9
Читая другие ответы, я думаю, что одно из недоразумений, с которыми вы работаете, заключается в том, что адреса памяти каким-то образом глобально уникальны, например, IP-адреса, MAC-адреса или номера телефонов. Это не так.
По сути, микросхема ОЗУ имеет следующее:
- Некоторое количество адресных линий, называемых адресной шиной
- (это определяет максимальное количество адресуемых слов в чипе)
- Некоторое количество линий данных, называемых «шиной данных».

- (это определяет размер слова, размер данных, которые можно прочитать с одного адреса)
- Контакт «разрешение записи» (WE)
- Если включено, пульсация часов приведет к тому, что значение адресуемой ячейки памяти будет установлено на значение, считанное с шины данных
- Когда отключено, пульсация часов приведет к тому, что значение шины данных будет установлено на значение, считанное из адресуемой ячейки памяти
- Часовой штифт. В импульсном режиме считывается/записывается значение адресной шины, в зависимости от контакта WE .
- Контакт «включение чипа» (CE), который либо включает чип, либо нет.
При включении микросхема работает, как описано
При отключении шина данных устанавливается в состояние «высокого импеданса».
Это критично. Это позволяет нескольким микросхемам совместно использовать одну и ту же шину данных. Рассмотрим, что произойдет в этом примере: бит 0 шины данных микросхемы 0 может быть низким, а бит 0 микросхемы 1 — высоким (например, 5 В).
 Поскольку микросхема 0 и микросхема 1 совместно используют шину данных, их два контакта бита данных 0 соединены вместе. Если они имеют разные значения, как в этом случае, у вас есть 5 В, подключенные к 0 В. Это короткое замыкание, и появится волшебный дым.
Поскольку микросхема 0 и микросхема 1 совместно используют шину данных, их два контакта бита данных 0 соединены вместе. Если они имеют разные значения, как в этом случае, у вас есть 5 В, подключенные к 0 В. Это короткое замыкание, и появится волшебный дым.Используя контакты включения микросхемы, вы можете сделать так, чтобы отключенные микросхемы эффективно «отключались» от остальной части схемы. Пока активен только один из чипов, к шине данных подключен только один чип, и, таким образом, короткого замыкания не произойдет.
Вы можете себе представить 256-байтовый чип ОЗУ. Адресация 256 значений означает, что адресное пространство этой микросхемы находится в диапазоне от 0b0000_0000 (0) до 0b1111_1111 (255). Но что делать, если хочется иметь компьютер с 512 байт ОЗУ, а чипов на 512 байт в производстве нет?
Ну, вы можете использовать два чипа 256 RAM вместе! Каждый из них имеет 256-байтовые ячейки памяти со своими собственными 8-битными шинами, которые принимают значения от 0 до 255. Теперь обратите внимание, что для адресации 512 байтов потребуется пространство памяти в диапазоне от 9 до 255.0099 0b0_0000_0000 (0) до
Теперь обратите внимание, что для адресации 512 байтов потребуется пространство памяти в диапазоне от 9 до 255.0099 0b0_0000_0000 (0) до 0b1_1111_1111 (511). Для этого нужна 9-битная адресная шина. Но каждый из наших чипов имеет только 8-битную адресную шину!
Вот в чем хитрость: ваш 9-й бит (8-й бит, считая с 0) адресной шины (исходящей от вашего процессора) будет подключен к чипу включения двух чипов RAM.
- CE чипа 0 будет подключен к биту 8 адреса через вентиль НЕ. Это означает, что когда бит 8 адреса низкий, контакт включения чипа активируется, и чип включается. Остальные биты адресной шины подключаются как обычно. Чип видит только адреса в диапазоне от 0 до 255, как и раньше, и работает нормально.
- CE микросхемы 1 будет подключен непосредственно к биту 8 адреса. Это означает, что когда бит 8 адреса имеет высокий уровень, контакт включения микросхемы активируется, и микросхема включается. Остальные биты адресной шины подключаются как обычно.
 Чип видит только адреса в диапазоне от 0 до 255, как и раньше, и работает нормально.
Чип видит только адреса в диапазоне от 0 до 255, как и раньше, и работает нормально.
По сути, бит 8 выбирает, какая из двух микросхем памяти адресована. Другие 8 контактов выбирают, какая ячейка в активном чипе считывается/записывается.
- Вы можете думать о чипе 0 как о «установленном» битах
0b0_0000_0000—0b0_1111_1111адресного пространства ЦП - Вы можете думать о микросхеме 1 как о «установленной» по адресам
0b1_0000_0000—0b1_1111_1111адресного пространства ЦП.
Как видите, адреса памяти — это не что иное, как набор значений на адресной шине каждого чипа. Они не уникальны, но перекрывающиеся значения адресной шины возможны при использовании выводов включения чипа для выбора только одного из чипов.
Вы можете себе представить увеличенную версию этого. У вас может быть две микросхемы памяти, каждая емкостью 65 536 байт (это означает, что они имеют как минимум 16-битную адресную шину). Вы можете использовать два бита адресной шины для адресации одной из 4 микросхем (
Вы можете использовать два бита адресной шины для адресации одной из 4 микросхем ( 00 , 01 , 10 , 11 , используя демультиплексор 2-в-4) и 16 бит адресного пространства, подаваемого прямо на чип. В итоге вы получите:
- Чип 0, смонтированный в адресном пространстве
0b00_0000_0000_0000_0000—0b00_1111_1111_1111_111 - Микросхема 1, смонтированная в адресном пространстве
0b01_0000_0000_0000_0000—0b01_1111_1111_1111_111 - Микросхема 2, смонтированная в адресном пространстве
0b10_0000_0000_0000_0000—0b10_1111_1111_1111_111 - Микросхема 2, смонтированная в адресном пространстве
0b11_0000_0000_0000_0000—0b11_1111_1111_1111_111
Таким образом, теперь у вас есть компьютер с 256 КБ ОЗУ, использующий только 65 КБ микросхем ОЗУ.
8
Блок памяти состоит из ячеек памяти (каждая хранит по одному байту) и дерева логических элементов, которые в основном представляют собой небольшие переключатели. Адрес представляет собой набор битов, которые указывают переключателям, какую ячейку памяти следует читать или обновлять.
Адрес представляет собой набор битов, которые указывают переключателям, какую ячейку памяти следует читать или обновлять.
┌───[байт]
┌─[переключатель]
│ ┊ └───[байт]
ЦП <--> [переключатель] ┊
┊ │ ┌───[байт]
┊ └─[переключатель]
┊ ┊ └───[байт]
┊ ┊
Адрес: бит0 бит1
Выше приведена иллюстрация, показывающая, как одна из четырех ячеек памяти, соединенных переключателями, может быть выбрана двумя битами. Таким образом, два бита 00 дают первый байт, 01 — второй байт и так далее.
Вам просто понадобится один дополнительный переключатель каждый раз, когда вы удваиваете объем памяти, поэтому с 3 битами вы можете адресовать 8 байтов, 4 бита дают вам 16 байтов, а 16 битов дают вам 65 536 байтов.
Таким образом, адрес — это просто набор битов, соответствующих цепочке переключателей, которая приводит нас к определенной ячейке памяти. Набор битов также можно интерпретировать как целое число, и мы называем это число адресом ячеек памяти.
Другими словами, ячейка памяти на самом деле не получает адрес , назначенный . Скорее, адрес логически вытекает из того, где находится ячейка в иерархии коммутаторов.
Конечно, это становится намного сложнее на современных процессорах, где есть многоуровневые кэши, виртуальная память отображается в физическую память и так далее. Но по сути адрес — это просто набор битов, соответствующих набору переключателей, которые позволяют нам выбрать конкретную ячейку памяти.
3
Элемент ОЗУ представляет собой электрическую схему с линиями ввода данных и адреса. Спецификация, которую он реализует, выглядит примерно так:
Если вы выберете конкретный шаблон адресных входов в режиме записи, то тот же шаблон входных данных будет создан в качестве вывода на линиях данных, если вы выберете тот же шаблон на входе. адресные входы в режиме чтения (до тех пор, пока вы продолжаете подавать питание на элемент).
Таким образом, тот факт, что набор битов (например, байт) хранится в определенной части микросхемы, закодирован в физической структуре микросхемы.
Если рассматривать микросхему RAM как электрическую цепь, то она, по сути, является повторителем шаблона. Что вы будете делать с этой возможностью — вопрос к компиляторам и операционным системам. Обычно компилятор видит объявление переменной и выбирает адрес для этой переменной; например, он может знать, что сегмент данных начинается с адреса 10000, мы уже использовали 412 байт для других переменных, поэтому везде, где есть ссылка на эту следующую переменную, он будет вставлять адрес 10412 (двоичный шаблон 0010100010101100) в сгенерированную машину. код.
Очевидно, что конструкция ОС и компилятора намного сложнее, но в реальной жизни принципы практически не меняются.
13
Короче говоря, контроллер памяти должен определить DRAM и создать карту физических адресов. Процесс происходит при помощи кода BIOS. Карта адресов может быть очень сложной из-за чередования разных каналов и банков. Вы можете прочитать этот материал:
https://web.eic.nctu.edu.tw/lpsoc/courses/MS2017Spring/supplemental/5.%20DRAM%20Memory%20Controller%20.pdf
Процесс происходит при помощи кода BIOS. Карта адресов может быть очень сложной из-за чередования разных каналов и банков. Вы можете прочитать этот материал:
https://web.eic.nctu.edu.tw/lpsoc/courses/MS2017Spring/supplemental/5.%20DRAM%20Memory%20Controller%20.pdf
с https://wiki.osdev.org/Detecting_Memory_(x86):
«Как BIOS определяет ОЗУ? Я просто сделаю это так». К сожалению, ответ неутешителен: Большинство BIOS не могут использовать ОЗУ, пока не определят тип установленной ОЗУ, затем не определят размер каждого модуля памяти, а затем не настроят набор микросхем для использования обнаруженной ОЗУ. Все это зависит от конкретных методов чипсета и обычно задокументировано в даташитах на контроллер памяти (северный мост). Оперативная память непригодна для запуска программ во время этого процесса. BIOS изначально запускается из ПЗУ, поэтому может играть в необходимые игры с микросхемами ОЗУ. Но сделать это изнутри любой другой программы совершенно невозможно.
Переменная — это именованная ячейка памяти
Что такое переменная в компьютерном программировании? Как мыслят компьютеры, когда они представляют собой всего лишь набор крошечных электрических токов на чипе? Как числа помещаются в ячейки памяти компьютера? Программирование по сравнению с электронными таблицами
Электрические токи Компьютер — это просто электрические токи на микросхеме. Если электричество проходит через ток, мы называем это 1. Если через него не проходит электричество, мы называем это 0. Все — операционные системы, программы, видео — построено из этих 0 и 1. Каждый «текущий» называется бит . Бит содержит либо 0, либо 1. Мы поговорим о двоичных числах в другой лекции. Компьютеры понимают числа, а не слова. 0 с и 1 с. Но люди не так хороши с нулями и единицами. Языки программирования высокого уровня и переменныеJava, Python, C и Ruby являются примерами языков программирования высокого уровня. Языки программирования высокого уровня позволяют использовать символические имена вместо нулей и единиц.  Переменная — это именованная ячейка памяти. Мы называем это переменной, потому что значение в ячейке может измениться. Ячейки памяти могут быть разного размера: 8 бит, 16 бит, 32 бит, 64 бит. Ячейки разного размера используются для хранения разных типов данных. Ячейка из 8 бит называется байтом . Целое число — целое число. Целое число обычно хранится в 4 байтах или 32 битах.Число с плавающей запятой — это число с десятичными точками, например, 34,56. Число с плавающей запятой хранится в 8 байтах. Символ — это символ на клавиатуре. Символ обычно хранится в 2 байтах. ASCII и Unicode — это протоколы преобразования символов в числа. Компьютеры назначают адреса ячейкам в памяти. Большинство систем памяти имеют адресацию байт.0246 : каждому байту, начиная с 0, присваивается адрес. Вопрос: К какому биту относится адрес 22? Заявления о присвоении Общее заявление программы представляет собой заявление о назначении, например, следующее: Принципал = 10000 «основной» может быть сопоставлен с адресом 8342. Тогда приведенный выше оператор присваивания будет означать: поместить 10000 в ячейку памяти 8342 = в операторе присваивания не означает равенство. Это означает «назначено». Мы говорим: «переменный принцип присваивается 10000». Утверждение типа: принципал = принципал + 1 Частью оценки является выборка значений переменных. Here’s a simplified example of what happens when a program is executed: Program Code principal=10000 Memory
Как работает память
Страница 3 из 3
Звучит очень просто! Хорошая новость заключается в том, что именно так работает типичный чип оперативной памяти. Действительно, если вы посмотрите на изображение микросхемы оперативной памяти, вы даже сможете увидеть прямоугольную сетку и соединительные линии, как описано.
Чип оперативной памяти — в центральной области видны два массива памяти
На практике использование выбора строк и столбцов скрыто от ЦП. Причина в том, что это немного неэффективно. Например, если вы используете однобитный адрес, теоретически вы можете выбрать две ячейки памяти — ячейку 0 и ячейку 1. Если вы используете двухбитный адрес, вы можете выбрать четыре ячейки — 00, 01, 10 и 11. Используя выбор строки и столбца, вам нужно две строки, чтобы выбрать одну ячейку, три строки, чтобы выбрать две, четыре строки, чтобы выбрать четыре, пять строк, чтобы выбрать шесть, и так далее. Таким образом, для подключения ЦП к памяти требуется меньше адресных строк, если вы указываете место в памяти как двоичный адрес, а не как выбор столбца строки. Итак, процессор указывает, какую ячейку памяти он хочет использовать, задавая двоичный адрес. Некоторая простая логическая логика, декодирование адреса, затем преобразует адрес в выбор строки и столбца, а память все еще работает и эффективна.
Строки адреса преобразуются в выбор строки/столбца
Обратите внимание, что в данный момент мы рассматриваем одну микросхему памяти, и такое устройство может хранить только один бит. Если вы хотите сохранить байт, вам потребуется восемь таких микросхем, по одной на каждый бит, и восемь линий ввода данных и восемь линий вывода данных. Восемь линий данных сгруппированы в шину ввода данных и «шину» вывода данных — шина — это просто группа проводов. Ранние компьютеры действительно имели отдельные шины для ввода и вывода, но современные машины имеют единую унифицированную шину данных, которую можно использовать как для ввода, так и для вывода. Если вам нужно больше памяти, чем может обеспечить банк из восьми микросхем, вам нужно добавить еще один банк из восьми микросхем и некоторую дополнительную логику декодирования адреса, чтобы выбрать правильный банк.
Шина данных и адреса В некоторых конструкциях используется одна двунаправленная шина данных, но это в основном вопрос реализации и электронной инженерии. Все это очень просто, но вы видите, как все усложняется на практике. Однако использование двоичного адреса объясняет, почему, например, 1 КБ составляет 1024 байта, а не 1000, как должно быть в любом нормальном K. Чтобы понять, почему это естественно, сначала спросите себя, сколько ячеек памяти можно адресовать с помощью одной адресной строки? Ответ 2. С двумя адресными линиями вы можете адресовать 4. С тремя вы можете адресовать 8, и если вы продолжите таким образом, вы обнаружите следующие естественные размеры памяти:
Обратите внимание, что с десятью адресными строками вы можете адресовать магическое число 1024 ячеек памяти, и это самое близкое к 1000, которое вы можете получить, используя эту систему, следовательно, 1K = 1024. Если вы будете следовать тем же рассуждениям, добавление еще десяти адресных строк позволит вам адресовать ячейки памяти размером 1K x 1K, и это мы называем 1MB, что составляет 1024×1024 или 1048576 байт. Нечетное число, если вы не понимаете, что это ближайшая степень от 2 до одного миллиона. Обратите внимание, что обычно емкость дискового хранилища измеряется в единицах 1000×1024, из-за чего кажется, что на диске хранится больше данных, чем на самом деле. Интересно, почему? Связанные статьиКак работает память Кэш-память Виртуальная память Флэш-память — изменение хранилища ЦП Конструкция процессора — RISC, CISC и ROPS Спинтроника Чарльз Бэббидж
Чтобы получать информацию о новых статьях на I Programmer, подпишитесь на нашу еженедельную рассылку, подпишитесь на RSS-канал и следите за нами в Twitter, Facebook или Linkedin.
|
 w3.org/1999/xhtml» cellspacing=»0″>
w3.org/1999/xhtml» cellspacing=»0″>
 Система отслеживает сопоставление между именем переменной и ячейкой памяти.В языках высокого уровня программисту не нужно беспокоиться о фактическом адресе переменной.
Система отслеживает сопоставление между именем переменной и ячейкой памяти.В языках высокого уровня программисту не нужно беспокоиться о фактическом адресе переменной.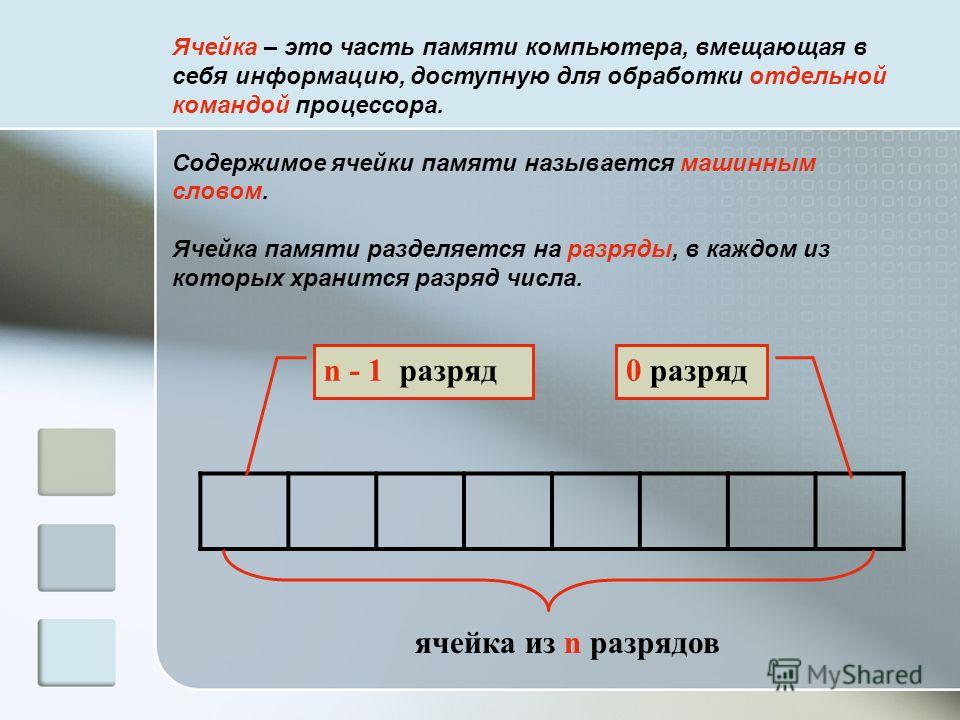 В этом случае текущее значение принципала равно 10000 (из первого оператора присваивания). Итак, мы оцениваем выражение в правой части как 10000+1=10001. Затем это значение помещается в основную переменную.
В этом случае текущее значение принципала равно 10000 (из первого оператора присваивания). Итак, мы оцениваем выражение в правой части как 10000+1=10001. Затем это значение помещается в основную переменную. 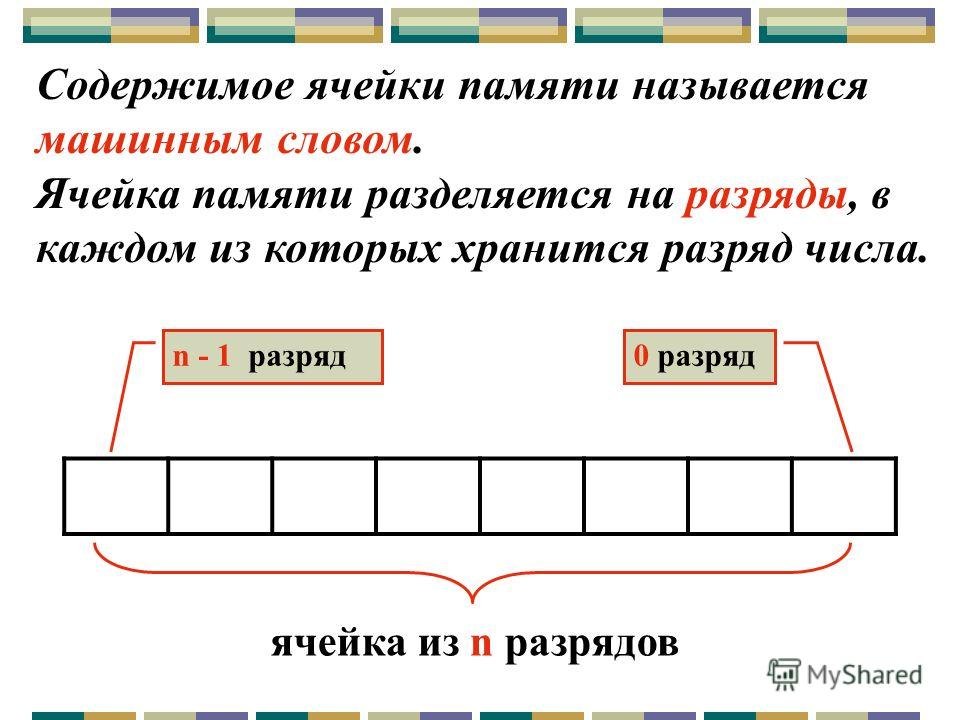 Таким образом, переменная «principal» находится по адресу 0, «interestRate» — по адресу 4, а oneYearReturn — по адресу 12.
Таким образом, переменная «principal» находится по адресу 0, «interestRate» — по адресу 4, а oneYearReturn — по адресу 12. 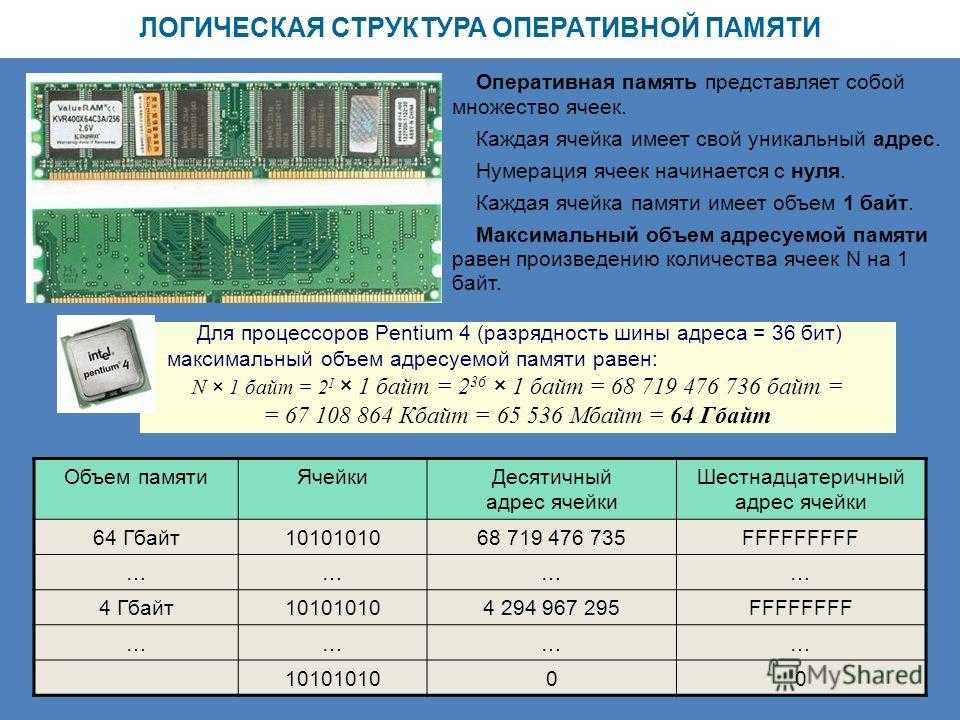 Все, что мы сделали для упрощения, это забыли такие детали, как время, напряжение и другие инженерные факторы.
Все, что мы сделали для упрощения, это забыли такие детали, как время, напряжение и другие инженерные факторы.
 Адресные линии, исходящие от процессора, обычно называют адресной шиной, и теперь у нас есть фундаментальная архитектура простого, но современного компьютера.
Адресные линии, исходящие от процессора, обычно называют адресной шиной, и теперь у нас есть фундаментальная архитектура простого, но современного компьютера.