Как мы научили ABBYY FineReader PDF редактировать целые абзацы / Хабр
Сегодня мы обновили ABBYY FineReader 15 и выпустили его под брендом ABBYY FineReader PDF, потому что он объединяет все инструменты для работы с PDF. По этому поводу публикуем первый пост из серии материалов о фичах программы. В нем мы расскажем об одной интересной возможности, которая не первый месяц есть в программе, но, возможно, не все о ней знали.
Давно ли вы открывали PDF-файлы? Готовы поспорить, что совсем недавно. Скорее всего, на вашем компьютере точно найдется пара сканов, а может, еще и макет презентации, аналитическое исследование или техническая инструкция. Для каких задач обычно используют эти документы? По данным опроса ABBYY, 62% респондентов ищут информацию в PDF, 60% — копируют текст из документа, а 52% — редактируют: вносят в файл правки, исправляют ошибки и опечатки.
Даже сейчас не все знают, что можно редактировать текст в PDF. Да, изменение таких файлов устроено не так, как редактирование обычного текстового документа.
В этом посте мы раскроем технические подробности редактирования многострочных фрагментов текста в FineReader: как мы изменили движок программы, как редактирование устроено изнутри и как оно выглядит для пользователя. Поехали!
Форматом PDF пользуются по всему миру: его содержимое одинаково отображается на любых компьютерах, смартфонах и планшетах с разными операционными системами. Это удобно и помогает избежать неловких ситуаций. Например, когда вы написали текст в MS Word, отправили коллегам, а они открывают его LibreOffice’ом или Wordpad’ом, и все поехало
 В 70% всех существующих PDF-документов текст есть, а в 30% — нет, так как это изображения.
В 70% всех существующих PDF-документов текст есть, а в 30% — нет, так как это изображения.Поговорим сначала о PDF, в которых текст есть. Чтобы редактировать PDF, надо понимать, как в нем записан текст. Открывали когда-нибудь PDF в блокноте? Если да, то вы видели такое:
Чтобы все это отображалось понятно для пользователя, нужно проделать большую работу.
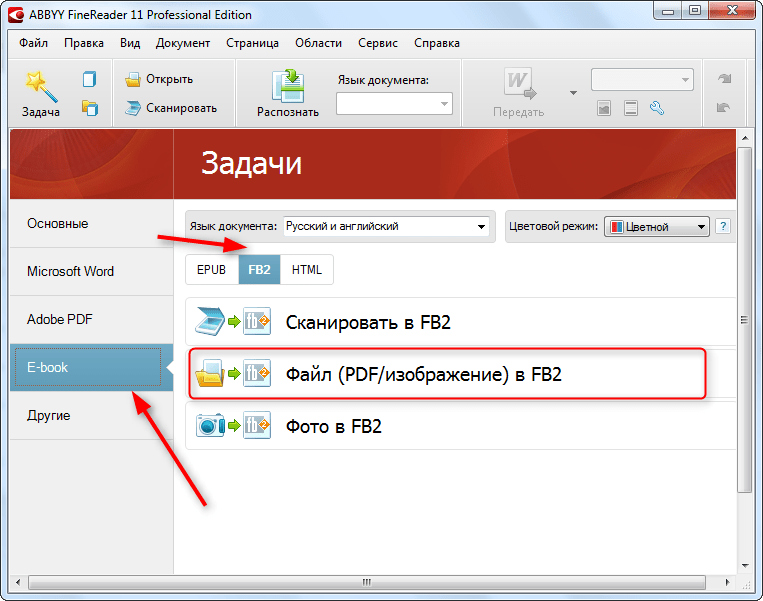
Задача: понять PDF
Содержимое каждой страницы в PDF-файле хранится в виде потоков команд для отрисовки документа – это могут быть текст, изображения или векторная графика. Структуру файла определяют PDF-объекты, например, страница, картинка, комментарий (а абзацы, строчки текста и буквы – это всего лишь части объекта). Символ в PDF представляется  Каждый символ хранится отдельно: у него есть шрифт, код символа в шрифте и координаты его расположения на странице. То, где глифы расположены, определяется как раз потоком команд. Кроме того, буквы объединены в потоки текста (text run), но они не смысловые.
Каждый символ хранится отдельно: у него есть шрифт, код символа в шрифте и координаты его расположения на странице. То, где глифы расположены, определяется как раз потоком команд. Кроме того, буквы объединены в потоки текста (text run), но они не смысловые.
В PDF нет ни строк, ни абзацев, которые есть в документах текстовых форматов. Даже порядок текста не всегда определен. То есть вы видите текст, но на самом деле текста не существует. Это хаос из трудно понятных инструкций (как на изображении выше), которые нужно правильно отобразить в конкретных местах документа, с соответствующим форматированием.
«А как же текст?» – спросите вы.
Текст в PDF все же существует, и его даже получится редактировать. Для этого мы учим наши технологии понимать структуру текста, например, определять и выделять строки. Расскажем об этом подробнее.
Библиотеки PDF и как мы их поменяли
Чтобы сделать возможным редактирование целых абзацев, мы сильно поменяли нашу внутреннюю подсистему (библиотеку), которую мы называем PdfTools. Она занимается тем, что открывает PDF-файлы, парсит потоки команд (т.е. понимает, где расположен текст, где картинки, и воссоздает структуру документа) и помогает пользователям оперировать этими данными: прочитать, изменить, сохранить в PDF.
Она занимается тем, что открывает PDF-файлы, парсит потоки команд (т.е. понимает, где расположен текст, где картинки, и воссоздает структуру документа) и помогает пользователям оперировать этими данными: прочитать, изменить, сохранить в PDF.
Подсистема PdfTools содержит все необходимые инструменты, чтобы прочитать содержимое и обернуть его в объекты (страница, картинка, комментарий), с которыми удобно работать программе. С этими объектами уже могут работать наши продукты, в частности ABBYY FineReader PDF и другие.
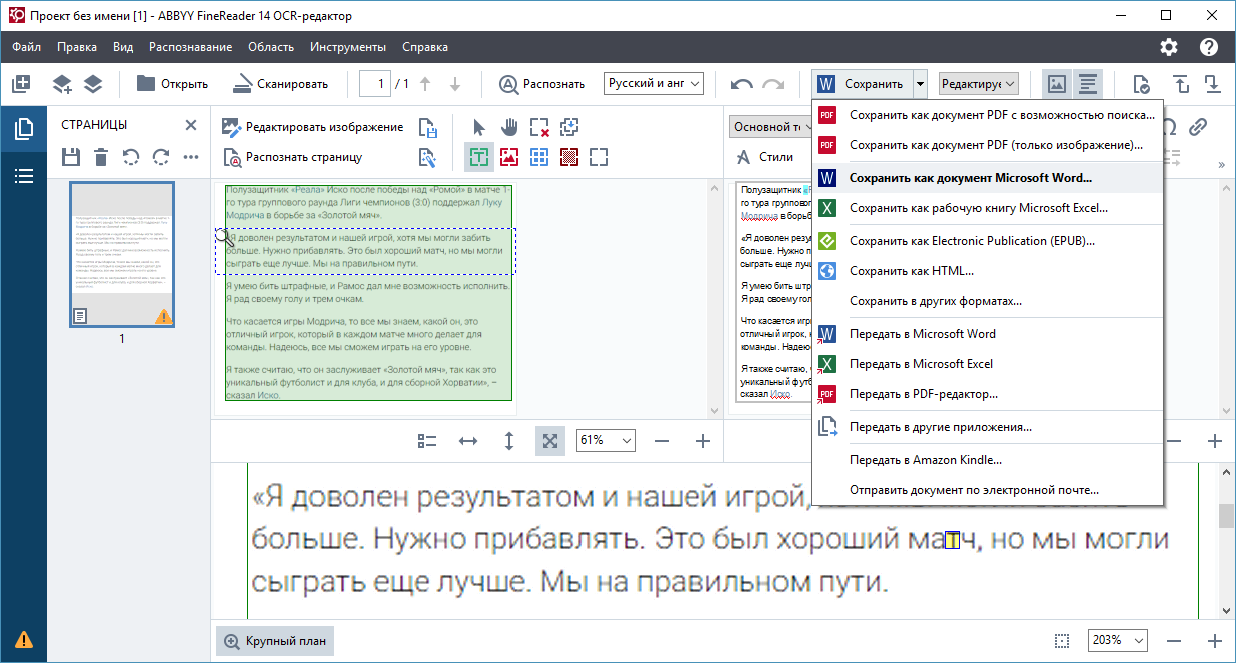
Как было раньше. В FineReader 14 мы умели редактировать текст только в рамках одной строчки. После редактирования необходимо было выполнить «рендеринг» — расставить глифы на свои новые места.
Вообще рендеринг — это визуализация. Но мы вкладываем в это слово иное понятие — расположение объектов в PDF на своих местах. Для PDF-специалистов это и есть визуализация, которую больше никто не видит. Когда мы говорим о визуализации в привычном понимании, то используем слово «растеризация».

Весь этот процесс располагался в подсистеме PdfTools. Она помогала нам собирать содержимое PDF в строчки и редактировать их. Например, надо поставить на 5-ое месте глиф «А». FineReader передавал подсистеме PdfTools, что на пятое место нужно поставить глиф «А» с заданным размером и шрифтом, а PdfTools вставляла «А» и перемещала на нужное место в строчке все глифы, которые следовали за буквой «А». Построчное редактирование довольно легкое: текст просто смещался вправо или, например, влево, если он записан на иврите или арабском языке. Это позволяло внести небольшие корректировки, например, исправить опечатку, но не давало возможность сделать более глобальные изменения в тексте PDF-документа.
Что решили изменить. Когда появилась задача многострочного редактирования, мы поняли, что в рамках одной библиотеки PdfTools это будет проблематично делать. Нам необходимо было научиться автоматически находить в тексте PDF более крупные фрагменты, например, «видеть» абзацы, понимать, где находятся их границы, какое форматирование должно быть у целого фрагмента текста и что происходит при переходе с одной строки на другую.
Document Analysis и Synthesis
Чтобы определять в тексте блоки, ABBYY FineReader PDF использует технологию Document Analysis. Она позволяет найти абзацы, таблицы, картинки. Программа подсвечивает найденные блоки небольшими бледными рамками, чтобы пользователю удобнее было вносить правки:
Далее мы усовершенствовали другую подсистему нашей программы – Synthesis. Мы уже рассказывали на Хабре, зачем она нужна. Если вкратце, именно она определяет структуру и все характеристики распознанного текста: какие используются шрифты и размеры, какое начертание (bold, italic, underline), где заголовки, списки, отступы и многие другие параметры, которые можно настраивать в том же MS Word. Мы доработали Synthesis для того, чтобы при распознавании и воссоздании страницы очень точно восстанавливать исходные параметры текста.
Особенности подчеркнутого текста
В PDF нет такого атрибута текста как подчеркивание, привычного, например, пользователям MS Word. Подчеркивание в PDF – это векторная графика, никак не связанная с текстом. Без дополнительной доработки продукта при редактировании «подчеркнутого» текста символы бы перемещались привычным образом, а линии, обозначающие подчеркивания, оставались бы на месте. ABBYY FineReader PDF умеет определять и редактировать подчеркнутый текст привычным пользователю образом.
Редактирование таблиц в PDF
Изменилось и редактирование таблиц. Раньше программа «видела» таблицу, как отдельные строки, и редактировала ее так же. Теперь при работе с таблицами ABBYY FineReader PDF определяет содержимое каждой ячейки, умеет извлекать из них текст и работать с ним. Это удобно, когда надо исправить ошибку в цифре, поменять точку на запятую и при этом сохранить структуру таблицы, сделать это быстро и без конвертации PDF-документа в другие форматы.
Как отредактировать скан?
Возможность многострочного редактирования доступна и для сканов. Кстати, пользователю даже не надо задумываться, скан перед ним или нет. ABBYY FineReader PDF сам определит это и запустит нужные механизмы. Например, в дате договора — опечатка, или ФИО контрагента поменялось: оно стало длиннее и должно «перетечь» на следующую строчку.
В программе скан сначала распознается, а потом происходит подготовка к редактированию. Когда скан распознали, то текст получается не в нашем исходном документе, а в его виртуальном «двойнике». И именно в нем происходят все операции по редактированию.
Когда пользователь закончил редактировать документ, программа автоматически собирает все изменения со страницы и заменяет эти фрагменты в исходном документе. Наша задача — встроить текст обратно в PDF-документ, не повредив все то остальное, что уже есть в нем.
Редактирование скана позволяет не тратить время на конвертацию документа в другие форматы и обратно.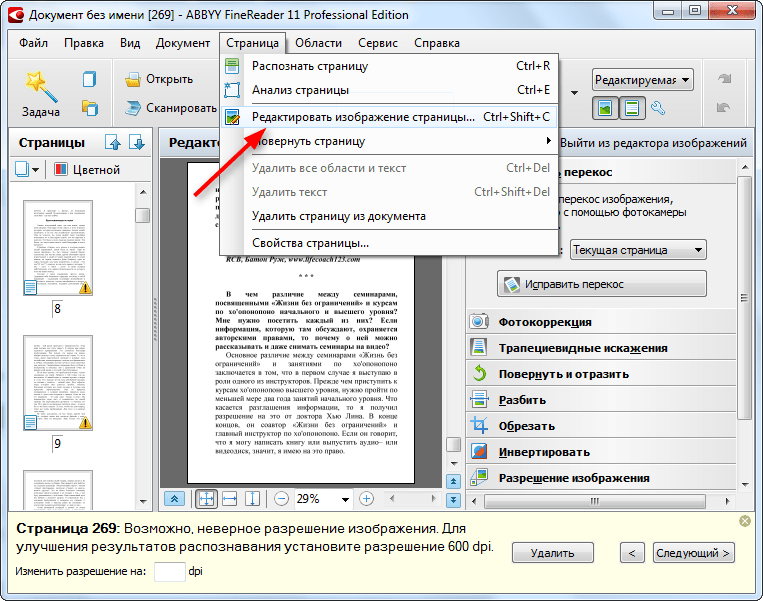 Это удобно, когда нужно быстро внести забытую правку в дату или другой фрагмент текста.
Это удобно, когда нужно быстро внести забытую правку в дату или другой фрагмент текста.
Пример многострочного редактирования. Текст автоматически перераспределяется по строкам по мере добавления слов и предложений внутри абзаца.
Вместо заключения
Исправить опечатку в листовке, поменять местами текстовые блоки в инструкции, изменить целый абзац в скане договора или добавить несколько новых, поправить форматирование всего текста – все эти задачи теперь возможно решить:
- быстро,
- без конвертации документа,
- с помощью одной программы.
Попробовать можно прямо сейчас – скачайте триал-версию ABBYY FineReader PDF бесплатно.
В следующем посте через неделю мы расскажем о том, как научили ABBYY FineReader PDF еще одной интересной фиче и для чего может пригодиться новая функциональность.
Пишите в комментариях, о каких еще технологических особенностях нашей программы вам было бы интересно узнать?
Функция OCR ABBYY FineReader for ScanSnap
ABBYY FineReader for ScanSnap является приложением, используемым исключительно с ScanSnap. Его можно использовать для распознавания текста на изображении в формате PDF документа, сканированного с помощью ScanSnap, и преобразования изображения в файл Word, Excel или PowerPoint.
Его можно использовать для распознавания текста на изображении в формате PDF документа, сканированного с помощью ScanSnap, и преобразования изображения в файл Word, Excel или PowerPoint.
В данном разделе описываются функции преобразования текстовой информации в изображение с помощью ABBYY FineReader for ScanSnap и примечания к ним.
Свойства функции OCR ABBYY FineReader for ScanSnap
Параметры могут не воспроизвестись как они есть в исходном документе
Документы и символы, которые могут быть распознаны неверно
Другие примечания
Свойства функции OCR ABBYY FineReader for ScanSnap
Функция OCR ABBYY FineReader for ScanSnap имеет следующие свойства. Проверьте содержимое изображение для преобразования перед преобразованием изображения.
Приложение, используемое для преобразования |
Документы, доступные для преобразования |
Документы, не доступные для преобразования |
|---|---|---|
Scan to Word |
Документы, созданные с использованием простого макета страницы с одной или двумя колонками. |
Документы, такие как брошюры, журналы и газеты, созданные с использованием сложной компоновки страницы, включая:
|
Scan to Excel |
Документы с простыми таблицами, в которых каждая граница связана с внешней рамкой. |
Документы, содержащие следующее:
|
Scan to PowerPoint(R) |
Документы, содержащие только символы и простые графики, или таблицы с белым или светлым монохромным фоном. |
|


Параметры могут не воспроизвестись как они есть в исходном документе
Следующие параметры могут не воспроизвестись как они есть в исходном документе. Проверьте преобразованные файлы с помощью Word, Excel или PowerPoint и измените их при необходимости.
Шрифт и размер символа
Символ и межстрочный интервал
Подчеркнутые, полужирные и написанные курсивом символы
Надстрочные/подстрочные символы
Документы и символы, которые могут быть распознаны неверно
Следующие типы документов и символов могут быть неправильно распознаны.
Они могут быть распознаны при сканировании путем изменения режима цвета или улучшения качества изображения в настройках профиля.
Документы, включающие рукописные символы
Документы с малыми символами с размером менее 10 пт.
Перекошенные документы
Документы, написанные на языке, отличного от заданного языка
Документы с символами на неравномерном закрашенном фоне, например символы с тенью.
Документы с большим количеством декоративных символов, например с тиснением или подчеркиванием
Документы с символами на узорном фоне, например символы с наложенным иллюстрациями или диаграммами
Документы с большим количеством символов, контактирующие с подчеркиваемой линией или границей
Документы с комплексной компоновкой и документы с помехами изображения (может потребоваться дополнительное время для процесса распознания текста для данных документов.
 )
)
Другие примечания
Когда документ, который больше размера бумаги, преобразуется в файл Word, он может быть преобразован в файл с максимально допустимым размером бумаги для Word.
Когда документ преобразовывается в файл Excel, если результат опознавания превышает 65536 линий, линии после 65536-ой линии не сохраняются.
Когда документ преобразовывается в файл Excel, структура всего документа, диаграммы, графики, и высота и ширина таблиц не воспроизводится. Воспроизводятся только таблицы и символы.
Когда документ преобразовывается в файл PowerPoint, цвета фона и шаблонов не воспроизводятся.
При сканировании документа сверху вниз или с боковых сторон изображение невозможно преобразовать правильно. Установите [Вращение] в [Сканировать] в Окно [Расширенные настройки] или загрузите документ правильно и сканируйте документ.

Когда функция сокращения проступания включена, скорость распознавания текста может снизиться. Для отключения функции сокращения проступания снимите флажок [Сократить проступание] в окне [Опции сканирования] в настройках профиля.
Когда функция сокращения проступания включена, скорость распознавания текста может снизиться. Для отключения функции сокращения проступания снимите флажок [Сократить проступание] на вкладке [Качество изображения] в окне [Опции сканирования] в настройках профиля.
OCR Функция ABBYY FineReader для ScanSnap
ABBYY FineReader для ScanSnap — это приложение, используемое исключительно со ScanSnap. Его можно использовать для распознавания текста текстовой информации в изображении в формате PDF документа, отсканированного с помощью ScanSnap, и преобразования изображения в файл Word, Excel или PowerPoint.
В этом разделе описаны возможности и примечания к функции преобразования текстовой информации в изображение с помощью ABBYY FineReader for ScanSnap.
Особенности функции оптического распознавания символов ABBYY FineReader для ScanSnap
Параметры, которые нельзя воспроизвести в том виде, в каком они представлены в исходном документе
Документы и символы, которые могут быть неправильно распознаны
Прочие примечания
Особенности функции OCR программы ABBYY FineReader для ScanSnap
Функция OCR программы ABBYY FineReader для ScanSnap имеет следующие особенности. Перед преобразованием изображения проверьте содержимое изображения, которое необходимо преобразовать.
Приложение, используемое для преобразования | Документы, подходящие для преобразования | Документы, не подходящие для преобразования |
|---|---|---|
Сканировать в Word | Документы, созданные с использованием простого макета страницы с одним или двумя столбцами. | Документы, такие как брошюры, журналы и газеты, созданные с использованием сложной компоновки страниц, состоящей из следующего:
|
Сканировать в Excel | Документы с простыми таблицами, в которых каждая граница соединяется с внешней рамкой. | Документы, содержащие следующее:
|
Сканировать в PowerPoint(R) | Документы, состоящие только из символов и простых графиков или таблиц на белом или светлом одноцветном фоне. |
|

Параметры, которые не могут быть воспроизведены в исходном документе
Следующие параметры не могут быть воспроизведены в исходном документе. Проверьте преобразованные файлы с помощью Word, Excel или PowerPoint и при необходимости отредактируйте их.
Шрифт и размер символов
Междустрочный и межстрочный интервал
Подчеркнутые, полужирные и курсивные символы
Символы верхнего/нижнего индекса
Документы и символы, которые могут распознаваться неправильно
Следующие типы документов и символов могут распознаваться неправильно.
Их можно распознать, если отсканировать их, изменив цветовой режим или улучшив качество изображения в настройках профиля.
Документы, содержащие рукописные символы
Документы с мелкими символами размером менее 10 pt.
Перекошенные документы
Документы, написанные на языках, отличных от указанного языка
Документы с символами на неравномерно окрашенном фоне, например, с заштрихованными символами.
Документы с большим количеством декоративных символов, таких как рельефные или контурные символы
Документы с символами на узорчатом фоне, такими как символы, перекрывающие иллюстрации или диаграммы
Документы, в которых много символов касается подчеркивания или границ
Документы со сложной компоновкой и документы с шумом изображения (Может потребоваться дополнительное время для обработки распознавания текста для этих документов.
 )
)
Другие примечания
Когда документ большого размера на бумаге преобразуется в файл Word, он может быть преобразован в файл с максимальным размером бумаги, допустимым для Word.
При преобразовании документа в файл Excel, если результаты распознавания превышают 65536 строк, строки после 65536-й строки не сохраняются.
При преобразовании документа в файл Excel макет всего документа, диаграммы, графики, а также высота и ширина таблиц не воспроизводятся. Воспроизводятся только таблицы и символы.
При преобразовании документа в файл PowerPoint фоновые цвета и узоры не воспроизводятся.
При сканировании документа в перевернутом или боковом положении изображение не может быть правильно преобразовано. Установите [Поворот] в [Сканирование] в окне [Подробные настройки] или правильно загрузите документ, а затем отсканируйте документ.
Если включена функция уменьшения проступания, скорость распознавания текста может снизиться.
 Чтобы отключить функцию уменьшения проступания, снимите флажок [Уменьшить проступание] в окне [Параметры сканирования] в настройках профиля.
Чтобы отключить функцию уменьшения проступания, снимите флажок [Уменьшить проступание] в окне [Параметры сканирования] в настройках профиля.Если включена функция уменьшения проступания, скорость распознавания текста может снизиться. Чтобы отключить функцию уменьшения проступания, снимите флажок [Уменьшить проступание] на вкладке [Качество изображения] в окне [Параметры сканирования] в настройках профиля.
ABBYY FineReader PDF — Soluma
Узнайте, как FineReader PDF помогает решать ежедневные проблемы с документами на цифровом рабочем месте.
Оптимизация процессов обработки документов
Оцифровывайте, извлекайте, редактируйте, защищайте, делитесь и совместно работайте над всеми видами документов в рамках одного рабочего процесса.
Получите максимум от PDF-файлов
Редактируйте цифровые и отсканированные PDF-файлы с новой легкостью: исправляйте целые предложения и абзацы или даже изменяйте макет.
Оцифровка документооборота
Включите бумажные документы в цифровое рабочее место с помощью технологии OCR на основе искусственного интеллекта, чтобы упростить повседневную работу.
Оптимизация затрат на ИТ
Воспользуйтесь преимуществами единовременного платежа и прогрессивных оптовых скидок, чтобы максимально увеличить эффективность вашей организации.
Стандартизация программных активов
Разверните единое решение PDF во всей организации, чтобы обеспечить беспрепятственную совместную работу нескольких заинтересованных сторон.
Упрощение управления лицензиями
Снижение рабочей нагрузки на ИТ благодаря автоматическому развертыванию и простому управлению лицензиями.
Типы лицензий, адаптированные к потребностям организации
НА МЕСТО
Стандартная или Корпоративная
Одна лицензия, одно устройство, неограниченное использование
Отличный выбор для компаний, которым приходится ежедневно обрабатывать и редактировать документы.
СОВМЕСТНАЯ
Корпоративная
Сетевая лицензия
Отличный выбор для компаний, которые только изредка обрабатывают и редактируют документы.
Каждый сотрудник имеет возможность доступа и использования ABBYY FineReader PDF 15
Количество одновременных лицензий ограничивает количество пользователей, которые могут работать с FineReader PDF
одновременно.
УДАЛЕННЫЙ ПОЛЬЗОВАТЕЛЬ
Стандартная или корпоративная
Лицензия, назначенная физическому лицу
Для компаний и организаций. Для использования FineReader PDF с решениями виртуализации.
Поддерживает виртуализацию рабочих столов и приложений.
Пользователь может получить доступ к лицензии через использование виртуального рабочего стола «удаленно».
Индивидуальные лицензии
Стандарт
- Простое, быстрое и интерактивное редактирование
- Удаление конфиденциальных данных, защита безопасности, цифровая подпись
- Преобразование документа в PDF и из PDF в выбранный формат
- Оцифровка физических документов с использованием передовой технологии OCR
- Базовая поддержка клиентов *
Корпоративный
- Сравнение документов разных форматов
- Автоматизация процессов преобразования
+
- Простое, быстрое и интерактивное редактирование
- Удаление конфиденциальных данных, защита безопасности, цифровая подпись
- Преобразование документа в PDF и из PDF в выбранный формат
- Оцифровка физических документов с использованием передовой технологии OCR
- Базовая поддержка клиентов *
FineReader PDF для Mac®
- Преобразование файлов PDF
- Оцифровка физических документов с использованием передовой технологии OCR
- Захват документов через iPhone®
- Комплексный пользовательский интерфейс с учетом продуктов Apple
- Базовая поддержка клиентов *
*Мы отвечаем на ваши вопросы по возможности в рабочее время (мы стараемся ответить вам как можно скорее, но не обещаем немедленных ответов)
Если у вас есть какие-либо вопросы относительно ABBYY FineReader PDF или цен на лицензии, пожалуйста, свяжитесь с нами и нашим команда ответит вам как можно скорее.
Свяжитесь с нами
Партнеры
Недавно мы работали с компанией Soluma, которая показала отличные результаты в сценариях извлечения отдельных позиций. Их знания и опыт помогли в сборе данных исследований по оценке затрат и выгод и позволили нам определить ключевые показатели эффективности для процессов реализации проекта. Профессионализм Soluma был исключительным и обеспечил максимальное удовлетворение и успех для нашего клиента. Мы более чем счастливы работать с SOLUMA и очень рекомендуем их.
Лаура Стэнсфилд, директор по работе с клиентами UiPathМы нашли надежного партнера для проектов сбора данных в SOLUMA. Их компетентность и опыт дают ответы на все требования бизнеса. SOLUMA с ABBYY Flexi Capture — это эффективная комбинация для различных проектов сбора данных, особенно для автоматизации процесса расчетов с поставщиками. Это твердый продукт!
Милан Бабич, менеджер по продукту РКЛ Интерн. д.о.о.
д.о.о.Мы искали решение для автоматического извлечения заголовков и отдельных позиций из сложных немецких счетов. SOLUMA добилась потрясающих результатов с помощью конструктора шаблонов Soluma, и я с радостью рекомендую его. SOLUMA имеет важное значение для наших усилий по развитию.
Мартин Бачик, управляющий директор Ancore ServicesДизайнер шаблонов SOLUMA — это эффективный инструмент для разработки и распространения шаблонов. Я определенно рекомендую этот инструмент всем системным интеграторам или поставщикам профессиональных услуг, которые хотели бы сократить затраты на разработку и выделиться среди других на рынке.
Михал Грепл, портфельный менеджер ITS Konica Minolta CEEМы очень довольны SOLUMA. Это сотрудничество позволило нам предоставлять бизнес-решения с добавленной стоимостью нашим премиальным клиентам в государственном и финансовом секторах. Индивидуальные решения SOLUMA, интегрированные со сканирующими устройствами Konica Minolta, могут удовлетворить практически любой бюджет и бизнес-требования клиента.
 Мирза Мерзич, генеральный директор
Konica Minolta Business Solutions Босния и Герцеговина
Мирза Мерзич, генеральный директор
Konica Minolta Business Solutions Босния и ГерцеговинаМы выбрали SolumaInvoiceReader.com в качестве платформы для чтения счетов и преобразования документов для решения SOLARIA BPM SaaS. Процесс интеграции прошел гладко, и решение очень простое в использовании. Надежность системы и отличные результаты распознавания представляют собой дополнительную ценность для наших клиентов и способствуют продвижению нашего решения на конкурентном рынке BPM. Спасибо СОЛУМА!
Горазд Бизжак, генеральный директор BizisОни знают все секреты технологии Flexi Capture. Назовите требования, и они разработают решение. SOLUMA — надежный партнер с многолетним опытом работы в проектах по сбору данных. Мы очень рады работать с SOLUMA.
Офек Рон, генеральный директор Источники программного обеспеченияДавайте поговорим, вместе мы сможем изменить мир к лучшему.
