Delphi ascii код символа — Dudom
How can i convert string character (123-jhk25) to ASCII in Delphi7
2 Answers 2
If you mean the ASCII code for the character you need to use the Ord() function which returns the Ordinal value of any «enumerable» type
In this case it works on character values, returning a byte:
It depends on your Delphi version. In Delphi 2007 and before, strings are automatically in ANSI string format, and anything below 128 is an ASCII character.
In D2009 and later, things become more complicated since the default string type is UnicodeString. You’ll have to cast the character to AnsiChar. It’ll perform a codepage conversion, and then whatever you end up with may or may not work depending on which language the character in question came from. But if it was originally an ASCII character, it should convert without trouble.
Not the answer you’re looking for? Browse other questions tagged delphi or ask your own question.

Related
Hot Network Questions
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
site design / logo © 2020 Stack Exchange Inc; user contributions licensed under cc by-sa 4.0 with attribution required. rev 2020.1.10.35756
Этот список может помочь при использовании функций Asc и Chr . Таблица основана на ASCII Character Set
Управляющие символы (большинство непечатные; наиболее важные подсвечены жёлтым)
| Символ (Обознач.) | Dec | Hex | Oct | Описание |
|---|---|---|---|---|
| NUL | 0 | 00 | 000 | Пустой символ |
| SOH | 1 | 01 | 001 | Начало заголовка, = console interrupt |
| STX | 2 | 02 | 002 | Начало текста, maintenance mode on HP console |
| ETX | 3 | 03 | 003 | Конец текста |
| EOT | 4 | 04 | 004 | Конец передачи, не тоже самое, что ETB |
| ENQ | 5 | 05 | 005 | Запрос, связан с ACK; old HP flow control |
| ACK | 6 | 06 | 006 | Подтверждение, очищает ENQ logon hand |
| BEL | 7 | 07 | 007 | Звуковой сигнал (Воспроизводит стандартный «бииип» системным динамиком ПК в Windows ) |
| BS | 8 | 08 | 010 | Backspace, works on HP terminals/computers |
| HT | 9 | 09 | 011 | Горизонтальная табуляция, перемещает к следующей позиции табуляции |
| LF | 10 | 0a | 012 | Перенос строки |
| VT | 11 | 0b | 013 | Вертикальная табуляция |
| FF | 12 | 0c | 014 | Смена страницы, извлекает страницу |
| CR | 13 | 0d | 015 | Возврат каретки |
| SO | 14 | 0e | 016 | Shift Out, включает альтернативные символы |
| SI | 15 | 0f | 017 | Shift In, возобновляет символы по умолчанию |
| DLE | 16 | 10 | 020 | Экранирует управляющий символ |
| DC1 | 17 | 11 | 021 | XON, with XOFF to pause listings; «:okay to send».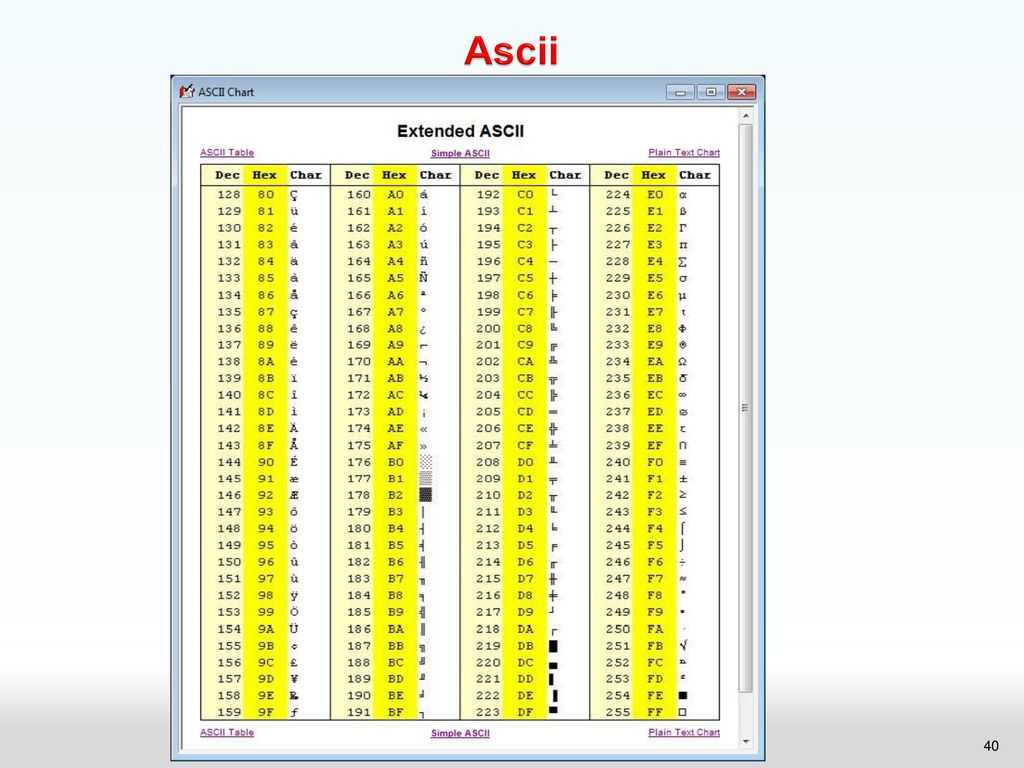 |
| DC2 | 18 | 12 | 022 | Управление устройством, код 2, block-mode flow control |
| DC3 | 19 | 13 | 023 | XOFF, with XON is TERM=18 flow control |
| DC4 | 20 | 14 | 024 | Управление устройством, код 4 |
| NAK | 21 | 15 | 025 | Отрицательное подтверждение |
| SYN | 16 | 026 | Пустой символ для синхронного режима передачи | |
| ETB | 23 | 17 | 027 | Конец передаваемого блока данных, не тоже самое, что EOT |
| CAN | 24 | 18 | 030 | Отмена строки, MPE echoes . |
| EM | 25 | 19 | 031 | Конец носителя, Control-Y interrupt |
| SUB | 26 | 1a | 032 | Замена |
| ESC | 27 | 1b | 033 | Экранирует, следующий символ не отображается |
| FS | 28 | 1c | 034 | Разделитель файлов |
| GS | 29 | 1d | 035 | Разделитель групп |
| RS | 30 | 1e | 036 | Разделитель записей, block-mode terminator |
| US | 31 | 1f | 037 | Разделитель полей |
| DEL | 127 | 7f | 177 | Delete (rubout), cross-hatch box |
Печатные символы (стандартные)
| Символ | Dec | Hex | Oct | Описание |
|---|---|---|---|---|
| 32 | 20 | 040 | Пробел | |
| ! | 33 | 21 | 041 | Восклицательный знак |
| « | 34 | 22 | 042 | Кавычка (» в HTML) |
| # | 35 | 23 | 043 | Решётка (знак числа) |
| $ | 36 | 24 | 044 | Доллар |
| % | 37 | 25 | 045 | Проценты |
| & | 38 | 26 | 046 | Амперсанд |
| ‘ | 39 | 27 | 047 | Закрывающая одиночная кавычка (апостроф) |
| ( | 40 | 28 | 050 | Открывающая скобка |
| ) | 41 | 29 | 051 | Закрывающая скобка |
| * | 42 | 2a | 052 | Звёздочка, умножение |
| + | 43 | 2b | 053 | Плюс |
| , | 44 | 2c | 054 | Запятая |
| — | 45 | 2d | 055 | Дефис, минус |
. | 46 | 2e | 056 | Точка |
| / | 47 | 2f | 057 | Наклонная черта (слеш, деление) |
| 0 | 48 | 30 | 060 | Ноль |
| 1 | 49 | 31 | 061 | Один |
| 2 | 50 | 32 | 062 | Два |
| 3 | 51 | 33 | 063 | Три |
| 4 | 52 | 34 | 064 | Четыре |
| 5 | 53 | 35 | 065 | Пять |
| 6 | 54 | 36 | 066 | Шесть |
| 7 | 55 | 37 | 067 | Семь |
| 8 | 56 | 38 | 070 | Восемь |
| 9 | 57 | 39 | 071 | Девять |
| : | 58 | 3a | 072 | Двоеточие |
| ; | 59 | 3b | 073 | Точка с запятой |
| 62 | 3e | 076 | Знак больше | |
| ? | 63 | 3f | 077 | Знак вопроса |
| @ | 64 | 40 | 100 | эт, собака |
| A | 65 | 41 | 101 | Заглавная A |
| B | 66 | 42 | 102 | Заглавная B |
| C | 67 | 43 | 103 | Заглавная C |
| D | 68 | 44 | 104 | Заглавная D |
| E | 69 | 45 | 105 | Заглавная E |
| F | 70 | 46 | 106 | Заглавная F |
| G | 71 | 47 | 107 | Заглавная G |
| H | 72 | 48 | 110 | Заглавная H |
| I | 73 | 49 | 111 | Заглавная I |
| J | 74 | 4a | 112 | Заглавная J |
| K | 75 | 4b | 113 | Заглавная K |
| L | 76 | 4c | 114 | Заглавная L |
| M | 77 | 4d | 115 | Заглавная M |
| N | 78 | 4e | 116 | Заглавная N |
| O | 79 | 4f | 117 | Заглавная O |
| P | 80 | 50 | 120 | Заглавная P |
| Q | 81 | 51 | 121 | Заглавная Q |
| R | 82 | 52 | 122 | Заглавная R |
| S | 83 | 53 | 123 | Заглавная S |
| T | 84 | 54 | 124 | Заглавная T |
| U | 85 | 55 | 125 | Заглавная U |
| V | 86 | 56 | 126 | Заглавная V |
| W | 87 | 57 | 127 | Заглавная W |
| X | 88 | 58 | 130 | Заглавная X |
| Y | 89 | 59 | 131 | Заглавная Y |
| Z | 90 | 5a | 132 | Заглавная Z |
| [ | 91 | 5b | 133 | Открывающая квадратная скобка |
| 92 | 5c | 134 | Обратная наклонная черта (обратный слеш) | |
| ] | 93 | 5d | 135 | Закрывающая квадратная скобка |
| ^ | 94 | 5e | 136 | Циркумфлекс, возведение в степень, знак вставки |
| _ | 95 | 5f | 137 | Нижнее подчёркивание |
| ` | 96 | 60 | 140 | Открывающая одиночная кавычка, гравис, знак ударения |
| a | 97 | 61 | 141 | Строчная a |
| b | 98 | 62 | 142 | Строчная b |
| c | 99 | 63 | 143 | Строчная c |
| d | 100 | 64 | 144 | Строчная d |
| e | 101 | 65 | 145 | Строчная e |
| f | 102 | 66 | 146 | Строчная f |
| g | 103 | 67 | 147 | Строчная g |
| h | 104 | 68 | 150 | Строчная h |
| i | 105 | 69 | 151 | Строчная i |
| j | 106 | 6a | 152 | Строчная j |
| k | 107 | 6b | 153 | Строчная k |
| l | 108 | 6c | 154 | Строчная l |
| m | 109 | 6d | 155 | Строчная m |
| n | 110 | 6e | 156 | Строчная n |
| o | 111 | 6f | 157 | Строчная o |
| p | 112 | 70 | 160 | Строчная p |
| q | 113 | 71 | 161 | Строчная q |
| r | 114 | 72 | 162 | Строчная r |
| s | 115 | 73 | 163 | Строчная s |
| t | 116 | 74 | 164 | Строчная t |
| u | 117 | 75 | 165 | Строчная u |
| v | 118 | 76 | 166 | Строчная v |
| w | 119 | 77 | 167 | Строчная w |
| x | 120 | 78 | 170 | Строчная x |
| y | 121 | 79 | 171 | Строчная y |
| z | 122 | 7a | 172 | Строчная z |
| < | 123 | 7b | 173 | Открывающая фигурная скобка |
| | | 124 | 7c | 174 | Вертикальная черта |
| > | 125 | 7d | 175 | Закрывающая фигурная скобка |
Расширенный набор символов (ANSI) в русской кодировке Win-1251
Да, мы говорим о кодах ASCII.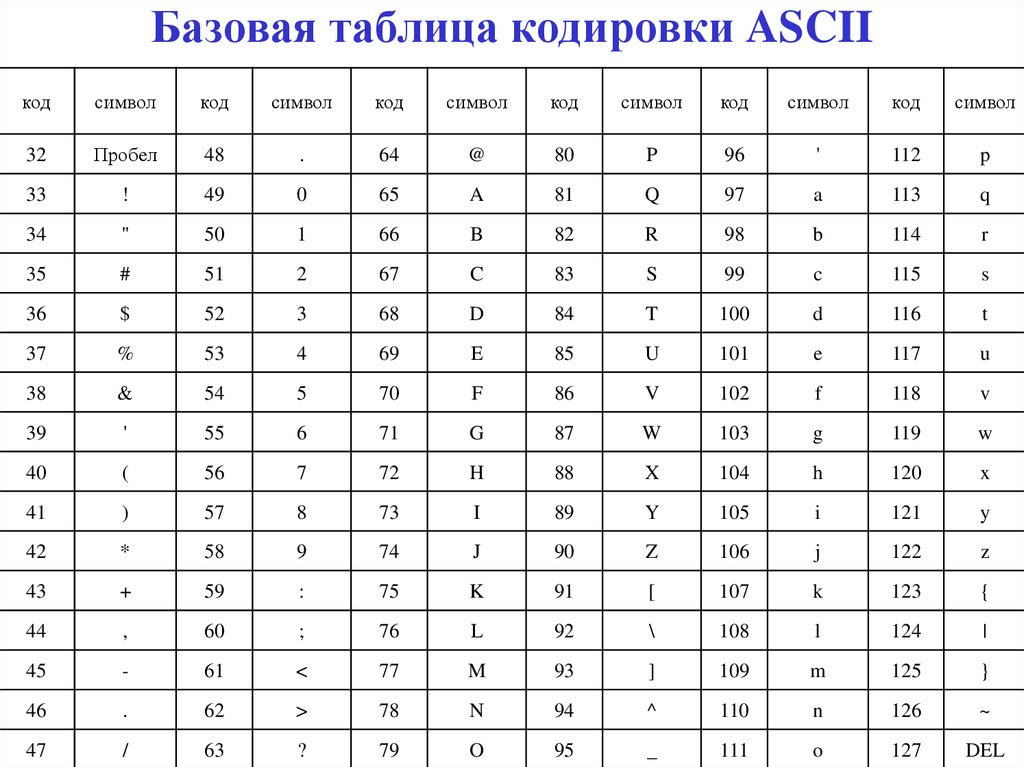 Мои пристрастия, я здесь не Дельфи.
Мои пристрастия, я здесь не Дельфи.
unicode delphi ascii
7 ответов
6 Решение lkessler [2008-11-21 04:04:00]
В libary включено множество функций преобразования для перехода в Unicode и из него, поэтому вы можете использовать те, которые имеют наибольший смысл в вашем приложении.
Или вы можете перейти на Delphi 2009, который имеет встроенные процедуры кодирования и собственную библиотеку функций преобразования.
Позвольте получить несколько вещей прямо. Набор символов (кодировка) и кодировка символов — это две связанные, но разные концепции. Набор символов представляет собой абстрактный список символов с определенным кодом целочисленного символа. Затем существуют кодировки символов, которые в основном представляют собой алгоритм, описывающий, как символы представлены в байтах.
ASCII действует как набор символов и кодировка. Он использует 7 бит для выражения 128 символов (94 для печати). Unicode, с другой стороны, это набор символов, выражающий 1,114,112 кодовых точек.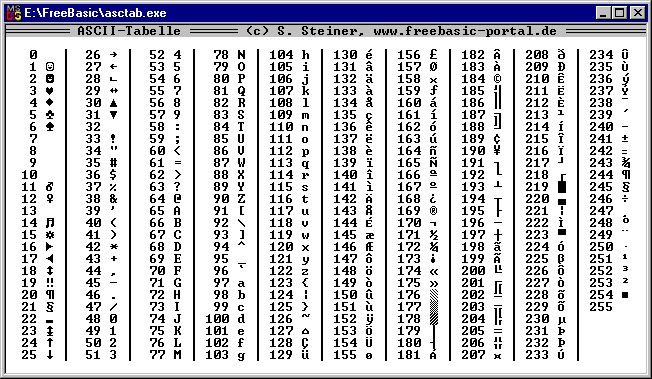 Существует несколько кодировок для представления строк Unicode, но наиболее примечательными являются UTF-8, UTF-16, UTF-16LE и UTF-32. Другими словами, один символ Unicode может быть представлен различными способами в зависимости от кодировок.
Существует несколько кодировок для представления строк Unicode, но наиболее примечательными являются UTF-8, UTF-16, UTF-16LE и UTF-32. Другими словами, один символ Unicode может быть представлен различными способами в зависимости от кодировок.
Как преобразовать символы Unicode в ascii-коды в delphi 7?
Я думаю, что этот вопрос можно было бы интерпретировать двумя способами.
У меня есть строка Unicode в некоторой кодировке, которая включает только символы ASCII для печати. Как преобразовать строку в байтовый массив ASCII-кодирования?
У меня есть строка Unicode в некоторой кодировке, которая также включает символы, не содержащие ASCII, такие как китайские символы. Как я могу кодировать строку в кодировку ASCII без потери информации, а затем декодировать ее обратно в исходную строку Unicode?
Если вы имеете в виду первое, вы можете загрузить строку Unicode в WideString, как говорит Осман, и
Если вы имеете в виду второй, вам понадобится общий алгоритм кодирования, например Base64. Вы можете использовать DCPBase64.pas, включенный в David Barton DCPcrypt v2 Beta 3.
Вы можете использовать DCPBase64.pas, включенный в David Barton DCPcrypt v2 Beta 3.
Как работать с спец символами Delphi? — Хабр Q&A
Думаю, ваша задача более высокого уровня такова. Пользователи разрисовывают свои имена всякими там картинками, задача — убрать их.
Немного непонятно, с какой версией Delphi вы работаете, но, предположим, с 2010+.
Там string эквивалентно UnicodeString, 16-битной строке неограниченной длины, управляемой подсчётом ссылок средствами Delphi.
Юникод очень велик и будет расширяться, в идеале там может быть 1,15 млн. символов. Из них 120 тыс. уже занято.
Поэтому лучшим решением будет делать не чёрный список символов, а белый.
Качаем базу символов Unicode (есть где-то на unicode.org).
Делаем из неё фильтр по каким-нибудь признакам: например, буква/цифра/знак/комбинирующий/пробел и направление письма — либо слева направо, либо адаптирующееся.
Также для простоты исключаем символы с кодом 65536+ (с дополнительных плоскостей, они кодируются двумя WideChar).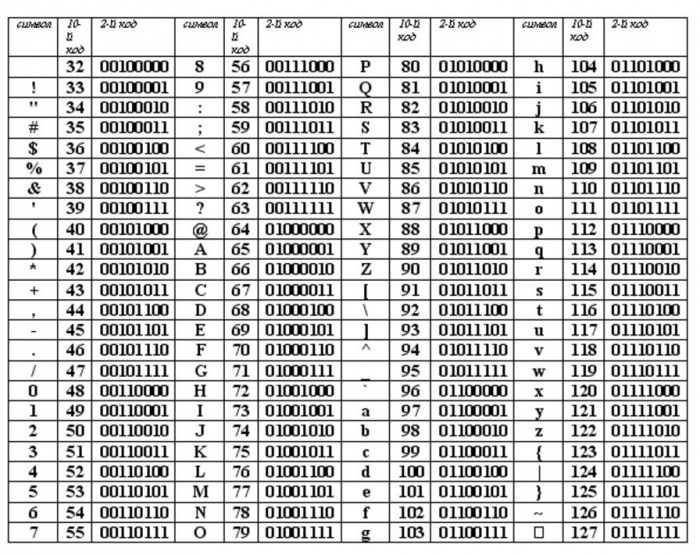
Вот этим белым списком и пользуемся. Проходимся по строке и убираем все лишние.
Ответ написан
Судя по всему вы работаете с широкими символами типа WideString. Доподлинно мне такая функция не известна. Да и подобный финкционалитет тоже не требуется. Но вот следющий сценарий мог бы помочь.
1. Присвоить переменной типа AnsiString.
2. С помощью StringReplace() заменить все вопросы на пустую строку.
3. Обратное преобразование в Wide.
Ответ написан
Комментировать
если уже есть строка то, можно создать новую строку и посимвольно скопировать только те что входят в белый список, затем заменить всю строку, вот и получается спец символов нет, а вместо замены символа — замена строки.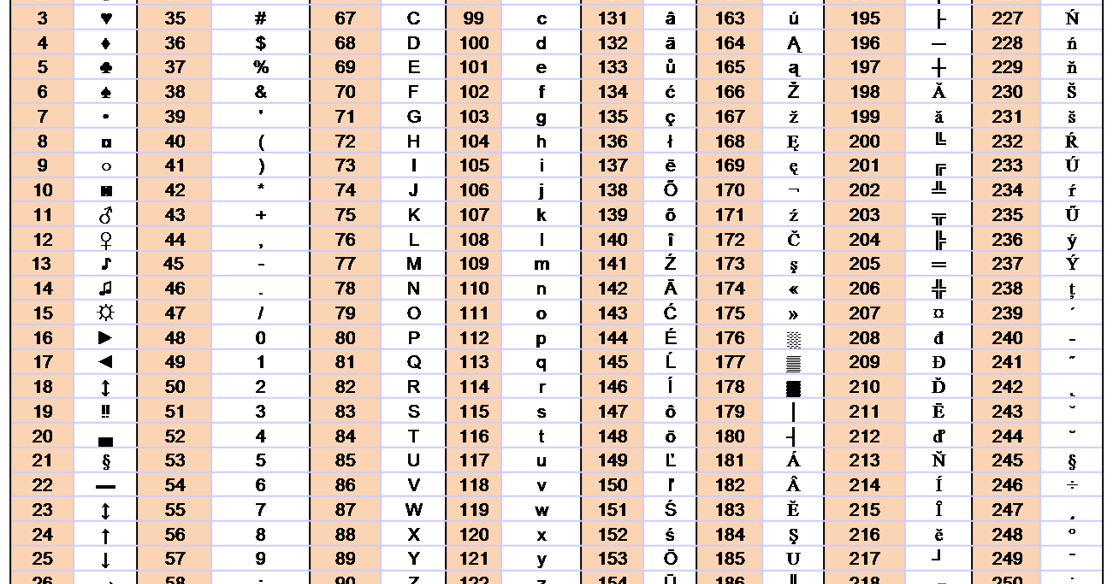
если ввод в форму, то можно отсечь символы ещё на этапе введения хотя формально там получается тоже замена.
Ответ написан
Комментировать
нечитабельные символы имеют ASCII код < 32 . Получить код символа можно функцией Ord, остальные символы можно по ASCII таблице глянуть. Среди них есть псевдографика, но почти всё читабельное.
Короче, пробежаться в цикле и добавить все символы с кодом больше 32. В FAR или cmd можно набрать Alt+0 на дополнительной клавиатуре (вот не помню там намлок выключен или включен должен быть) alt+1, alt + 2… как раз отобразятся Ваши символы 🙂
Буби это alt + 4, ASCII код символа равен 4
Ответ написан
Комментировать
unicode — Получение значения char в Delphi 7
спросил
Изменено 8 лет, 11 месяцев назад
Просмотрено 3к раз
Я делаю программу в Delphi 7, которая должна кодировать строку Unicode в строку объекта html.
Например, « ABCģķī » приведет к » ABCģķī »
Теперь две основные вещи:
- Delphi 7 не поддерживает Unicode, поэтому я не могу просто писать символы Unicode непосредственно в коде для их кодирования.
- Кодовые страницы состоят из 255 записей, каждая из которых содержит символ, характерный для данной кодовой страницы, кроме первых 127, одинаковых для всех кодовых страниц.
Итак — Как мне получить значение символа в диапазоне 1-255?
Пробовал Ord(Integer) , но он также возвращает значения далеко за пределы 255. В принципе, все в порядке (A возвращает 65 и так далее), пока моя строка не достигнет нелатинского юникода.
Есть ли другой способ возврата значения char? Любая помощь приветствуется
- delphi
- unicode
- delphi-7
- html-entities
- html-encode
9
Советую избегать кодовых страниц как чумы.
Я бы рассмотрел два подхода к Unicode: WideString и UTF-8.
Широкие строки имеют то преимущество, что они являются «родными» для Windows, что помогает, если вам нужно использовать вызовы Windows API. Недостатками являются пространство для хранения и то, что они (как и UTF-8) могут потребовать нескольких WideChars для кодирования полного пространства Unicode.
UTF-8 обычно предпочтительнее. Как и WideStrings, это многобайтовая кодировка, поэтому для конкретной «кодовой точки» Unicode может потребоваться несколько байтов в строке для ее кодирования. Это проблема только в том случае, если вы выполняете много посимвольной обработки своих строк.
@DavidHeffernan комментирует (правильно), что WideStrings может быть более компактным в некоторых случаях. Однако я бы рекомендовал UTF-16 только в том случае, если вы абсолютно уверены, что ваш закодированный текст будет более компактным (не забывайте о разметке!), и эта компактность очень важна для вас.
4
В HTML 4 числовые ссылки на символы относятся к кодировке, используемой HTML. Указана ли эта кодировка в самом HTML через или внеполосно через заголовок HTTP/MIME Content-Type или другими способами, это не имеет значения. Таким образом, "ABCģķī" будет точным представлением "ABCģķī" , только если HTML использует UTF-16. Если бы HTML использовал UTF-8, правильным представлением было бы либо
Если бы HTML использовал UTF-8, правильным представлением было бы либо "ABCģķī" или "ABCģķī" вместо этого. Большинство других кодировок не поддерживают эти конкретные символы Unicode.
В HTML 5 числовые ссылки на символы содержат исходные значения кодовых точек Unicode независимо от кодировки, используемой HTML. Таким образом, "ABCģķī" будет представлен как "ABC#291;ķī" или "ABCģķī" .
Итак, чтобы ответить на ваш вопрос, первое, что вам нужно сделать, это решить, нужно ли вам использовать семантику HTML 4 или HTML 5 для числовых ссылок на символы. Затем вам нужно назначить данные Unicode для WideString (это единственный тип строки Unicode, изначально поддерживаемый Delphi 7), который использует UTF-16, затем:
, если вам нужен HTML 4:
A. Если кодировка HTML отличается от UTF-16, используйте
WideCharToMultiByte()(или эквивалентную) для преобразованияWideStringв этот набор символов, затем циклически перебирайте полученные значения, выводя незарезервированные символы как есть, и ссылки на символы для зарезервированные значения, используяIntToStr()для десятичной записи илиIntToHex()для шестнадцатеричной записи.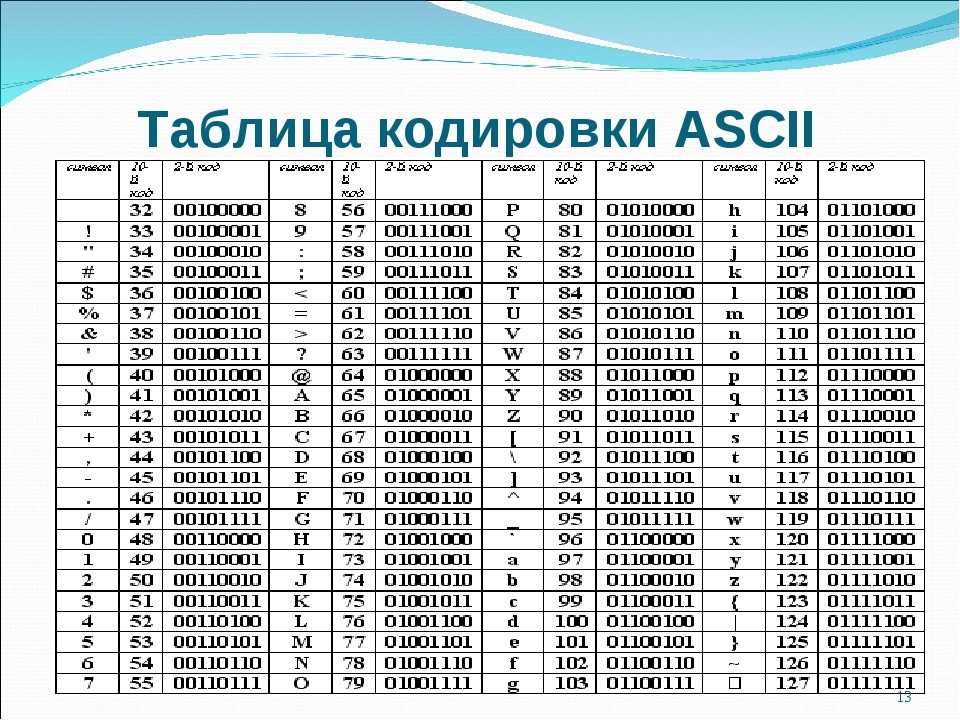
B. если кодировка HTML — UTF-16, то просто прокручивайте каждый
WideCharвWideString, выводя незарезервированные символы как есть и ссылки на символы для зарезервированных значений, используяIntToStr()для десятичной записи илиIntToHex()для шестнадцатеричной записи.Если вам нужен HTML 5:
A. Если
WideStringне содержит суррогатных пар, то просто перебрать всеWideCharвWideString, вывод незарезервированных символов как есть и ссылок на символы для зарезервированных значений с использованиемIntToStr()для десятичной записи илиIntToHex()для шестнадцатеричной записи.B. в противном случае преобразуйте
WideStringв UTF-32 с помощьюWideStringToUCS4String(), затем выполните цикл по полученным значениям, выводя незарезервированные кодовые точки как есть и ссылки на символы для зарезервированных кодовых точек, используяIntToStr()для десятичной записи илиIntToHex()для шестнадцатеричной записи.
Если я правильно понял OP, я просто оставлю это здесь.
функция Entitties(const S: WideString): строка;
вар
I: целое число;
начинать
Результат := '';
для I := 1 до длины (S) сделать
начинать
если Word(S[I]) > Word(High(AnsiChar)) тогда
Результат: = Результат + '#' + IntToStr(Word(S[I])) + ';'
еще
Результат := Результат + S[I];
конец;
конец;
2
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Delphi — проверить, встречается ли символ Unicode в наборе символов?
Этот код хорошо работает с Delphi-7 (до тех пор, пока в Delphi не появилась поддержка Unicode):
Значение := edit1.Text[1]; если Значение в ['м', 'ж'] то ...
‘м’, ‘ж’ — символы кириллицы
Но эта конструкция не работает с символами Unicode.
Пробую много чего, но не работает.
Я также попытался изменить типы значений на «Char» и «AnsiChar».
Не работает :
константа
MySet : набор WideChar = [WideChar('м'), WideChar('ж')];
начинать
Значение: = edit1.Text[1];
если Значение в MySet, то...
Не работает :
если AnsiChar(Value) в ['м', 'ж'] то ...
Не работает :
если CharInSet(Value, ['м', 'ж']) то ...
Но это работает хорошо:
если (Значение = 'м') или (Значение = 'ж') то...
Есть ли возможность проверить символ UNICODE с помощью SET в современных версиях Delphi?
Или нужно проверять каждый символ отдельно?
Моя версия Delphi — 10.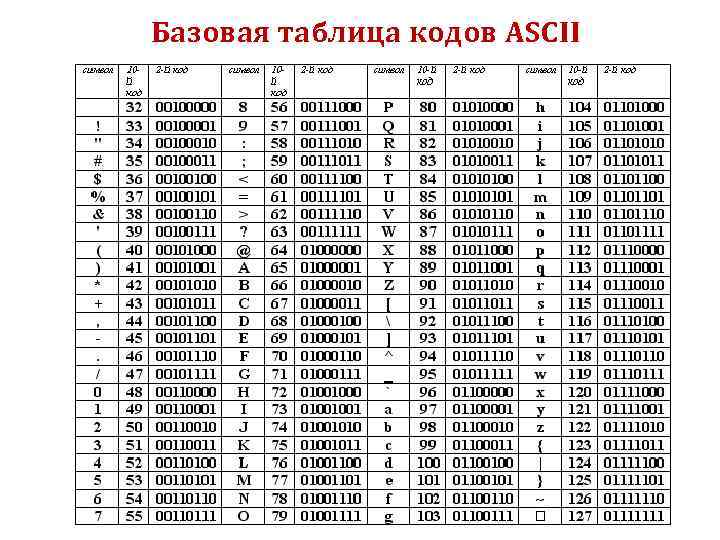 4, обновление 2 Community Edition
4, обновление 2 Community Edition
- Делфи
- Юникод
- Делфи-7
0
Тип набора Delphi может обрабатывать не более 256 значений, поэтому его нельзя использовать для обработки символов Unicode. Для обработки Unicode модуль System.Character предоставляет различные методы и помощники.
Для этого конкретного случая есть помощник IsInArray() символов, который вы можете использовать. Вместо объявления набора символов вам нужно будет объявить массив символов:
вар
ч: Чар;
а: массив символов;
с: строка;
начинать
а := ['м', 'ж'];
s := 'abcж';
для ch in s do
если ch.IsInArray(a), то...
конец;
Примечание. В Delphi XE7 появилась дополнительная языковая поддержка для инициализации и работы с динамическими массивами, а квадратные скобки также можно использовать для более простой инициализации массива. В контексте приведенного выше примера ['м', 'ж'] — это не набор, а массив расширенных символов.
10
проверить, встречается ли символ Unicode в наборе символов?
Вы имеете в виду набор Delphi?
В общем, невозможно иметь набор X , где базовый тип X имеет более 256 возможных различных значений. Таким образом, набор байта в порядке, но набор слова невозможен. Поскольку существует 256 * 256 различных значений широких символов, поэтому невозможно иметь набор широких символов. (Если бы это действительно было возможно, переменная такого типа набора имела бы размер 8 КБ. Это была бы необычно большая переменная.)
Поскольку не существует такого понятия, как «набор символов Unicode Delphi», вопрос «Как узнать, принадлежит ли символ набору символов Unicode Delphi» не имеет смысла.
Или вы просто имеете в виду математический набор?
Если это так, конечно, это возможно, но вы не можете использовать набор Delphi для представления математического набора символов.