Префиксы в 1С В Смоленске в Легасофт.
В 1С реализована автоматическая нумерация документов и других основных объектов конфигурации, с назначением префиксов базы 1С. Префикс представляет собой набор символов, который указывается перед номером документа для обеспечения уникальности сквозной нумерации документов. Структура номера документа представлена на рисунке 1.
Рис. 1. Структура номера документа
Важно! После установки префикса нумерация в базе начнется сначала.
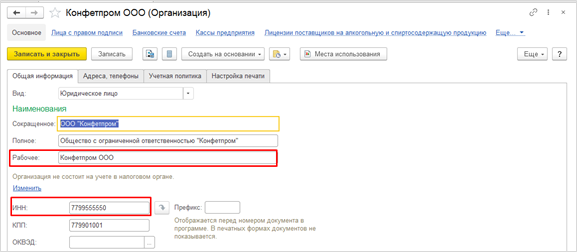
Префикс организации
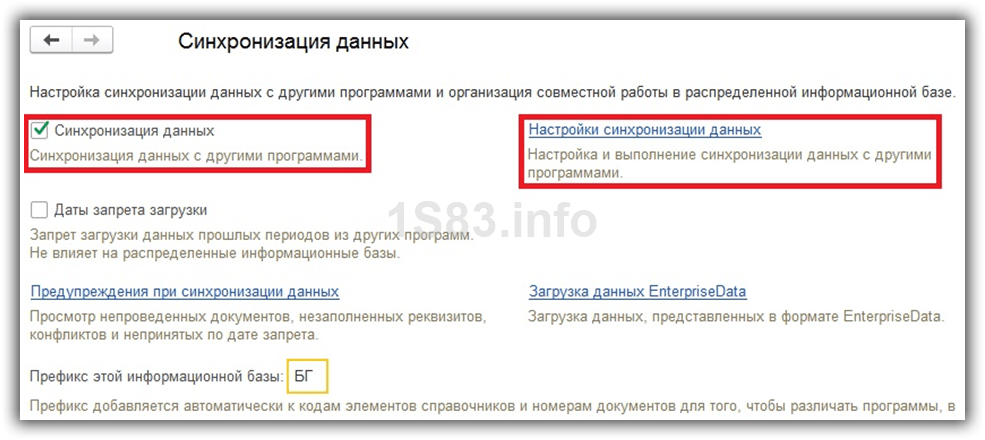
Префикс организации используется для разделения диапазонов нумерации документов, которые принадлежат разным организациям. Для Установки данного префикса нужно зайти в раздел Главное — Настройки — Организации. Затем открыть карточку организации и заполнить реквизит «Префикс», после чего префикс будет настроен (Рисунок 2).
Обратите внимание! Префикс нужно брать такой, чтобы он соответствовал названию организации, то есть посмотрев на номер документа стало сразу понятно, к какой организации он принадлежит.
Рис. 2. Настройка префикса организации на примере «Магазин №23»
Если распечатать документ, содержащий данный префикс, то он не будет выведен. Так как при печати выбранного документа данный префикс автоматически будет удален из номера документа, поскольку в печатные формы в отдельное поле выводится наименование организации (рисунок 3).
Рис. 3. Пример печатной формы без префикса организации
Важно! Данный префикс устанавливается в том случаем, если ведется учет в базе по нескольким организациям. И префиксы организаций совпадать не должны!
Префикс информационной базы
Префикс информационной базы (ИБ) используются в том случае, если применяется синхронизация с другими базами 1С для предотвращения дублирования номеров документов и кодов элементов справочников, создаваемых в процессе работы в разных информационных базах.
Рис. 4. Настройка префикса ИБ
При печати документа данный префикс отображается в номере. Например, распечатаем расходную накладную (рисунок 5).
Рис. 5. Пример печатной формы
Данный префикс можно настроить так, чтобы он не выводился на печать. Рассмотрим способы его отключения на примере баз: 1С: Управление нашей фирмой (УНФ), 1С: Зарплата и управление персоналом (ЗУП), 1С: Бухгалтерия предприятия (БП).
В базе УНФ можно настроить печать номер документа, убрав или оставив тот или иной префикс. Данная настройка происходит в окне, чтобы его открыть нужно зайти в раздел «Настройки» — Еще больше возможностей — Общее или воспользоваться командой «Перейти по ссылке» и вставить следующую ссылку: e1cib/command/Обработка.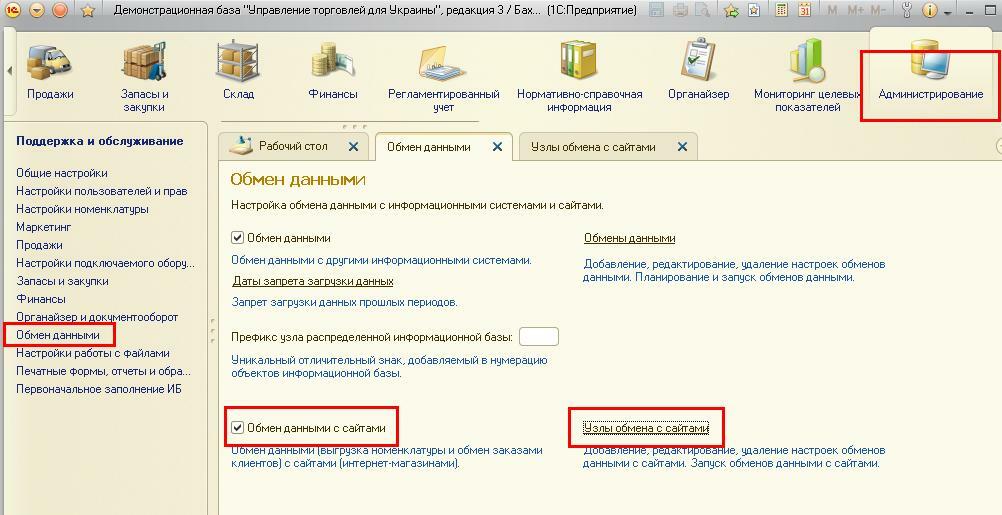 НастройкаПрограммы.Команда.ЕщеБольшеВозможностей (рисунок 6).
НастройкаПрограммы.Команда.ЕщеБольшеВозможностей (рисунок 6).
Рис. 6. Окно настройки префиксов в УНФ
В базе ЗУП также можно убрать при печати префиксы организации и информационной базы. Окно этой настройки находится по следующему пути: раздел «Настройка» ® Дополнительные настройки или воспользоваться командой «Перейти по ссылке» и вставить следующую ссылку: e1cib/command/РегистрСведений.ДополнительныеНастройкиЗарплатаКадры.Команда.ДополнительныеНастройкиЗарплатаКадры
(рисунок 7).
Рис. 7. Окно настройки префиксов в ЗУП
В базе БП дело обстоит иначе. В ней есть регистр сведений «Префиксы информационных баз», который можно открыть из Сервис и настройки ® Функции технического специалиста, и затем выбрать нужный регистр или воспользоваться командой «Перейти по ссылке» и вставить следующую ссылку: e1cib/list/РегистрСведений.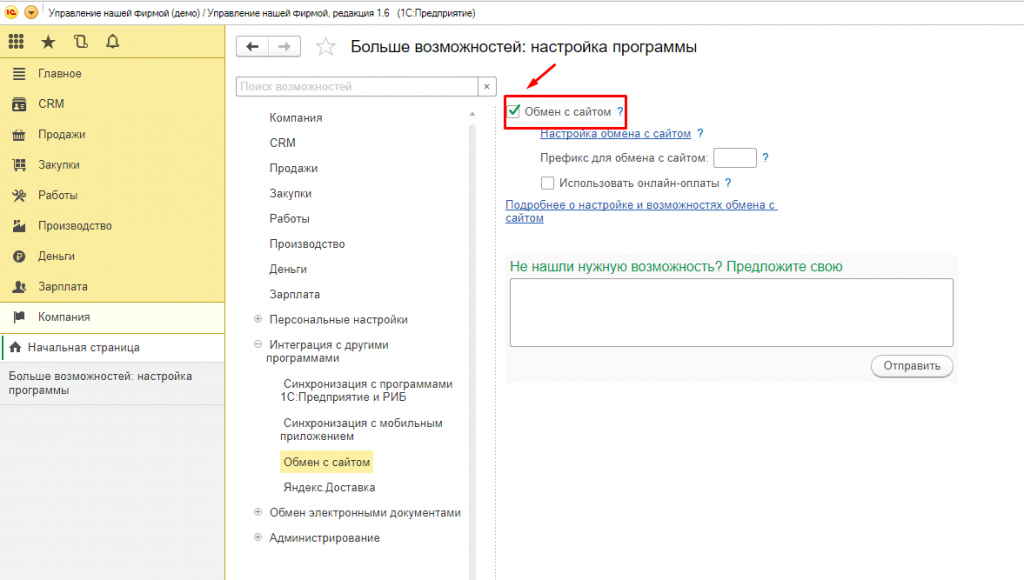 ПрефиксыИнформационныхБаз. После чего открыть нужный префикс и снять галку напротив «Печатать префикс», если не нужно выводить его на печать, записать настройки и перезайти в базу (рисунок 8).
ПрефиксыИнформационныхБаз. После чего открыть нужный префикс и снять галку напротив «Печатать префикс», если не нужно выводить его на печать, записать настройки и перезайти в базу (рисунок 8).
Рис. 8. Окно настройки префикса в БП
Для примера работы настроек в базе БП был напечатана реализация товаров с номером в базе «23БП-000001». Если стоит в регистре, описанном выше галка, то префикс выведется, а если не стоит – то его не будет (рисунок 9).
Рис. 9. Сравнение работы настроек
Для более наглядного представления о виде префиксов в номере документа и на печати была составлена таблица 1.
|
Префикс организации |
Префикс ИБ |
Номер |
Номер на печати |
|
– |
– |
|
|
|
– |
БП |
|
|
|
23 |
– |
|
|
|
23 |
БП |
|
|
Хочется отметить, что если только начали в базе вести учет, то сразу установите описанные выше в этой статье префиксы.
Но если Вы всё-таки ведете учет и решили использовать префиксы, то нужно обязательно проследить за работой автонумерации, то есть чтобы нумерация продолжилась с нужного номера. Если нумерация сбилась, то для того, чтобы в дальнейшем при создании нового документа программа знала, какой номер должен быть следующим, задайте ему номер вручную.
Нужна помощь с 1С?
Специалисты компании «Легасофт» помогут Вам выбрать необходимое программное обеспечение и современное торговое оборудование, которое будет отвечать всем потребностям Вашего бизнеса. Торговая автоматизация помогает вести учет и контроль товара, гарантирует улучшение уровня обслуживания покупателей и повышает скорость работы персонала! Чтобы получить бесплатную консультацию по автоматизации своего бизнеса Вы можете пообщаться с нашими специалистами в офисе компании или позвонив по телефону: 8-800-707-01-02.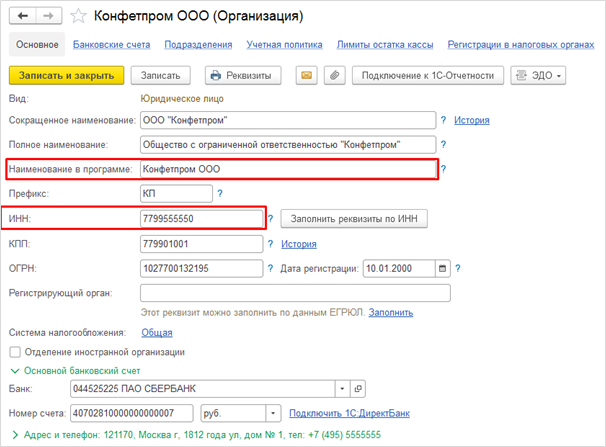
Мне нужна консультация
Наш специалист
Ирина Иванова
Специалист отдела разработки
+7 (920) 325-60-14
Чем мы можем быть вам полезны?
Внедрение 1С, доработка и сопровождение 1С.
Продаем ПО: на базе 1С и не только.
Автоматизация бизнеса: продаем и устанавливаем оборудование для торговли.
Обслуживаем онлайн-кассы: продаем и ремонтируем Эвотор и АТОЛ.
Исправление автонумерации документов в 1С
При создании нового документа система 1С использует встроенный механизм автонумерации объектов. Номера содержат заранее назначенную разработчиком длину и тип значения. Например, при использовании только численных значений – число, при использовании буквенных и численных значений – строка. В данной статье разберём исправление автонумерации документов в 1С.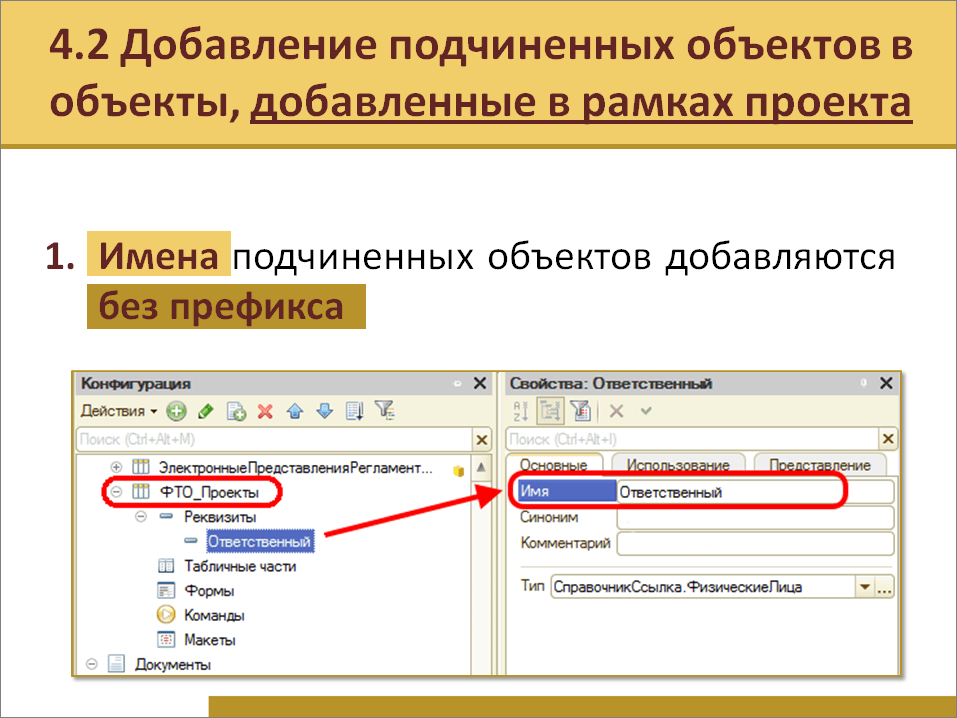
Буквенные обозначения в номере в типовом варианте работы с базой данных 1С нужны, чтобы новосозданные элементы по принадлежности отличались. Для документов это соответствие определённой организации (префикс организации в первых двух символах номера) или базе (префикс базы данных в третьем и четвёртом символе номера, вводимый при наличии обмена с другими базами).
Механизм автонумерации интуитивно понятен, но не лишён своих особенностей.
При записи элемента в базу (программным или ручным методом) механизм автонумерации 1С присваивает номер, равный максимальному номеру элемента в этом пространстве имён + 1.
Под пространством имён подразумевается та область применения нумерации, в которой находится этот элемент.
Например: создаётся новый документ реализации, база проверяет последний максимальный номер среди всех реализаций, пусть он будет 000-000785, новому документу назначается номер 0000-000786. Если же создаётся новый документ в банковских выписках, то 1С уже анализирует весь журнал документов (и поступления на р/с и списания с р/с) на предмет максимального номера, так как у всех банковских выписок одно пространство имён.
Пространство имён не ограничивается подчинением единому журналу документов. Среди границ использования номеров выступают:
- Период, если задана периодичность использования номеров.
Например: у документа, введённого 31 декабря, номер ААБП-000456, следующий введённый документ уже следующим годом от 1 января будет иметь номер ААБП -000001, так как у документов по умолчанию периодичность задана в пределах года.
- Префиксы организации или другой базы данных.
Например: последний документ, созданный до введения префикса для организации, содержит номер 0000-000005, после установки префикса «ПК» в организации и ввода последующих документов код начнётся с ПК00-000001. При этом не важно, будет ли редактироваться префикс в номере в документах вручную, автонумератор в кодах создаваемых документов будет указывать префикс «ПК» этой организации *.
С точки зрения работы механизма автонумерации полный анализ номеров элементов в одном пространстве происходит единожды, когда создаётся первичный элемент, а далее этот максимальный номер запоминается базой и обновляется при записи нового элемента или удалении (изменении) номера уже записанных элементов.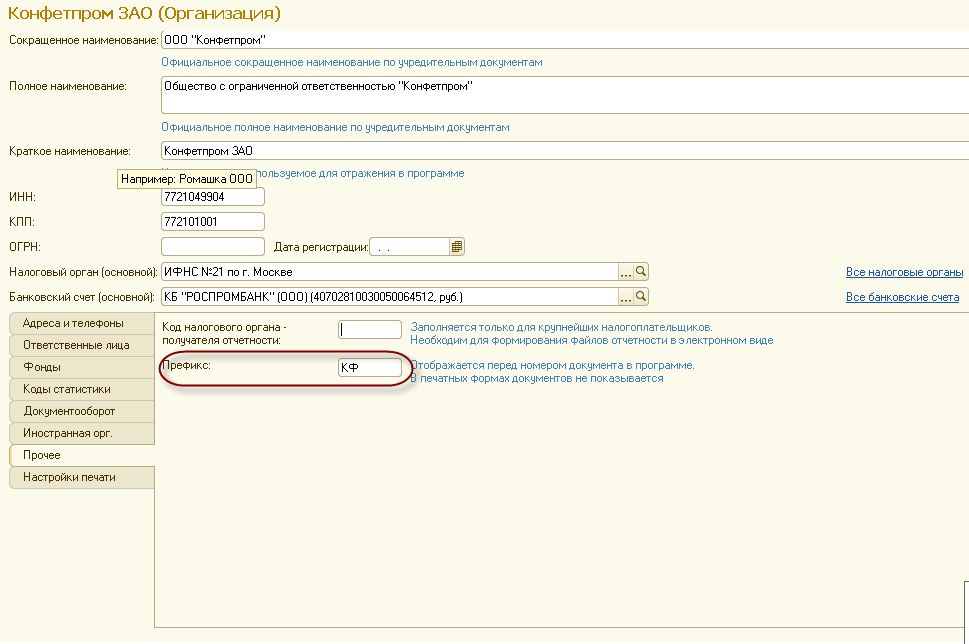 Однако в некоторых сценариях редактирования номеров (при использовании спецсимволов в номере элемента и прочее) возникают ситуации, когда этот максимальный номер не обновляется или обновляется некорректно. Рассмотрим исправление на примере.
Однако в некоторых сценариях редактирования номеров (при использовании спецсимволов в номере элемента и прочее) возникают ситуации, когда этот максимальный номер не обновляется или обновляется некорректно. Рассмотрим исправление на примере.
Использовался спецсимвол «/» вместо 0 в нумерации в реализациях.
1) Исправить некорректные номера в этом пространстве имён.
2) Перезапустить текущий сеанс работы 1С**.
В 1С также поддерживается сквозная нумерация для различных объектов, то есть помещение номеров отличающихся типов элементов в одно пространство имён. В типовых конфигурациях это используется для документов группы «Персонифицированный учёт» с одноимённым названием нумератора. Реализован этот механизм через объект конфигурации «Нумератор», который отвечает за вид («маску») номера документов в группе, а уже присвоение новых номеров и контроль уникальности лежит на механизме автонумерации.
Если у вас остались вопросы по теме материала, то можете их задать на нашей Линии консультаций 1С. Первое обращение совершенно бесплатно!
Первое обращение совершенно бесплатно!
* Стоит отметить, что префиксы созависимы по частичному указанию: если ввести префикс АБ, то документы с указанным префиксом А будут получать номера АБ, так как с точки зрения базы префикс А относится к группе префикса АБ.
** Либо нетиповыми способами вызвать функцию глобального контекста ОбновитьНумерациюОбъектов с указанием в качестве параметра типа объектов метаданных.
Свидетельство о регистрации СМИ: Эл № ФС77-67462 от 18 октября 2016 г. Контакты редакции: +7 (495) 784-73-75, [email protected]
Самый длинный общий префикс (с решением)
Содержание
show
- Постановка задачи
- Подход с горизонтальным сканированием
- Реализация на C++ Горизонтальное сканирование
- Реализация на языке Java
- Вертикальное сканирование Подход
- Реализация вертикального сканирования на C++
- Реализация вертикального сканирования на Java
- Реализация вертикального сканирования Python
- Подход «разделяй и властвуй»
- Реализация C++
- Реализация Java
- Реализация Python
- Подход бинарного поиска 7 Реализация бинарного поиска
- Java-реализация подхода бинарного поиска
- Реализация бинарного поиска на Python
Учитывая массив строк S[], вам нужно найти самую длинную строку S, которая является префиксом ВСЕХ строк в массиве.
Самый длинный общий префикс (LCP) для пары строк S1 и S2 — это самая длинная строка S, которая является префиксом как для S1, так и для S2.
Например: самый длинный общий префикс «abcdefgh» и «abcefgh» равен «ABC» .
Не знаете, что делать дальше?
За 3 простых шага вы БЕСПЛАТНО найдёте свой персональный карьерный план в сфере разработки программного обеспечения
Развернуть в новой вкладке
Примеры:
Ввод: S[] = {“abcdefgh”, “abcefgh”}
Вывод: 90 7 Explanation: 0 0 90 58 Объяснение на изображении описание выше
Ввод: S[] = {«abcdefgh», «aefghijk», «abcefgh»}
Вывод: «a»
Подход горизонтального сканирования
Идея состоит в горизонтальном сканировании всех символов из массива строк одну за другой и найти Самый длинный общий префикс среди них. LCP можно получить следующим образом:
LCP можно получить следующим образом:
LCP(S1…SN) = LCP(LCP(LCP(S1, S2), S3),…., SN)
Подход горизонтального сканированияАлгоритм
- Перебрать строку по очереди от S1 до SN.
- Для каждой итерации до с индексом можно получить LCP(S1…Si) .
- В случае, если LCP представляет собой пустую строку, завершить цикл и вернуть пустую строку.
- В противном случае продолжить и после сканирования строк N можно получить LCP(S1…SN) .
Горизонтальное сканирование реализации C++
Горизонтальное сканирование реализации Java
Горизонтальное сканирование реализации Python
Временная сложность: O(N), где N — размер массива S[] .
Space Сложность: O(1), так как дополнительное пространство не используется.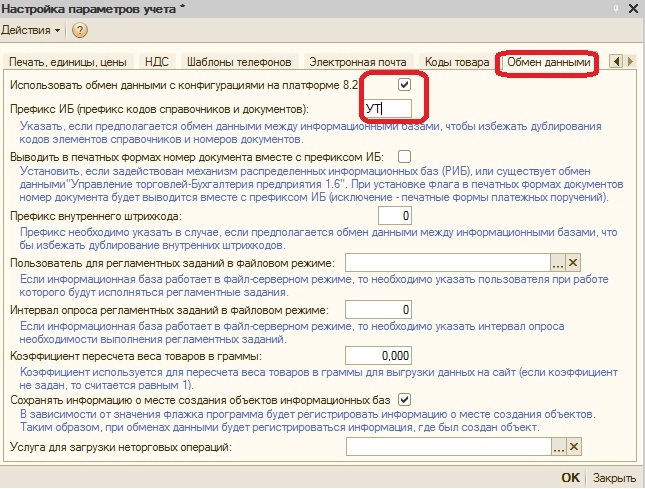
Метод вертикального сканирования
Идея состоит в том, чтобы сканировать и сравнивать символы от сверху вниз до i-го индекса для каждой строки.
Этот подход эффективен в случаях, когда строка LCP очень мала. Следовательно, нам не нужно выполнять K сравнений.
Подход с вертикальным сканированиемАлгоритм
- Итерация строки одна за другой от S1 до SN.
- Начать сравнение 0-й индекс , 1st index … ith index одновременно для каждой строки.
- В случае, если какой-либо из символов индекса и не совпадает, алгоритм завершается и возвращается LPS(1,i) S1…SN) .
Реализация вертикального сканирования на C++
Реализация вертикального сканирования на Java
Реализация вертикального сканирования на Python
Временная сложность: O(K), где K — сумма всех символов во всех строках.
Space Сложность: O(1), так как дополнительное пространство не используется.
Подход «разделяй и властвуй»
Подход состоит в том, чтобы разделить заданный массив строк на различные подзадачи и объединить их для получения LCP(S1..SN) .
Сначала разделите заданный массив на две части. Затем по очереди разделить полученный левый и правый массивы на две части и рекурсивно делить их до тех пор, пока их нельзя будет делить дальше.
Математически LCP(S1….SN) = LCP(S1….Sk) + LCP(Sk+1…SN), , где LCP(S1..SN) — это LCP массива строк и 1 < k < N.
Подход «разделяй и властвуй»Алгоритм:
- Рекурсивно разделить входной массив строк на две части.
- Для каждого подразделения найдите LCP , полученные на данный момент.
- Объединить полученный LCP из обоих подмассивов и вернуть его.

- Т.е. LCP(LCP(S[left…mid], LCP(S[mid + 1, right])) и вернуть его. (K) где K — сумма всех символов во всех строках
Пространственная сложность: O(M log N), поскольку имеется log N рекурсивных вызовов, и каждому требуется пробел M .Двоичный поиск Подход
Еще один способ подойти к проблеме — использовать концепцию бинарного поиска.0003
Алгоритм:
- Рассмотрим строку наименьшей длины. Пусть длина будет L .
- Рассмотрим переменную low = 0 и high = L – 1 .
- Выполнить бинарный поиск:
- Разделить строку на две половины, т.е. младшая – середина и середина + 1 до высшая .
- Сравните подстроку до середины этой наименьшей строки с каждым другим символом остальных строк с этим индексом.
- Если подстроение от 0 до Середина — 1 встречается среди всех подстроков, обновление Низкий с MID + 1 , иное обновление High с Mid — 1
- , если Low = Low = Low = Mid — 1
- , если = high , завершить алгоритм и вернуть подстроку от 0 до mid.
Реализация двоичного поиска на C++
Реализация двоичного поиска на Java
Python Реализация бинарного поиска
Временная сложность: O(K. logN), где K — сумма всех символов во всех строках.
Пространственная сложность: O(1)Практический вопрос
Самый длинный общий префикс
Часто задаваемые вопросы
Какова наилучшая временная и пространственная сложность поиска самой длинной строки префикса?
Наилучшая временная сложность — O(N), а пространственная сложность — O(1) при использовании подхода горизонтального и вертикального сканирования.Чем бинарный поиск лучше других подходов?
Нет, бинарный поиск занимает время сложности O(K*logN). Следовательно, это не самый эффективный способ.COS 126: префиксные коды
COS 126: префиксные кодыCOS 126 Префикс-коды
Задание по программированию 7 Срок выполнения : Среда, 23:59
Напишите программу для расшифровки закодированных сообщений используя код префикса , учитывая дерево кодировки.
 Такие коды широко используются в приложениях, которые сжимают данные,
включая JPEG для изображений и MP3 для музыки.
Такие коды широко используются в приложениях, которые сжимают данные,
включая JPEG для изображений и MP3 для музыки.Коды префикса. Префиксный код проще всего представить бинарным деревом, в котором внешние узлы помечаются одиночными символами, которые объединяются, чтобы сформировать сообщение. Кодировка символа определяется следуя по пути вниз от корня дерева к внешнему узлу, который содержит этот символ: бит 0 идентифицирует левую ветвь в путь, а 1 бит идентифицирует правую ветвь. На следующем дереве черные кружки — внутренние узлы, а серые квадраты — внешние узлы. Код на
bэто111, потому что внешний узел, содержащийb, достигается из корня путем принимая 3 последовательные правые ответвления. Остальные коды указаны в таблицу ниже.кодировка символов -------------------- 0 б 111 с 1011 д 1010 р 110 ! 100
Обратите внимание, что каждый символ кодируется (потенциально) разное количество бит.
 В приведенном выше примере символ «а» закодирован
с одним битом, а символ ‘d’
кодируется 4 битами.
Это фундаментальное свойство префиксных кодов.
Для того, чтобы эта схема кодирования уменьшила число
битов в сообщении, мы используем короткие кодировки для часто используемых
символы и длинные кодировки для нечастых.
В приведенном выше примере символ «а» закодирован
с одним битом, а символ ‘d’
кодируется 4 битами.
Это фундаментальное свойство префиксных кодов.
Для того, чтобы эта схема кодирования уменьшила число
битов в сообщении, мы используем короткие кодировки для часто используемых
символы и длинные кодировки для нечастых.Вторым фундаментальным свойством префиксных кодов является то, что сообщения может быть образован простым соединением битов кода из слева направо. Например, битовая строка
0111110010110101001111100100
кодирует сообщение «
абракадабра!«. Первый 0 должен кодировать'a', затем следующие три единицы должны кодировать'b', тогда110должны кодироватьrи т. д. следующим образом:|0|111|110|0|1011|0|1010|0|111|110|0|100 а б р а к а д а б р а !
Коды могут быть запущены вместе, потому что никакая кодировка не является префикс другого.
 Это свойство определяет код префикса и позволяет нам представлять
кодировки символов с помощью двоичного дерева, как показано выше.
Чтобы декодировать заданную битовую строку:
Это свойство определяет код префикса и позволяет нам представлять
кодировки символов с помощью двоичного дерева, как показано выше.
Чтобы декодировать заданную битовую строку: - Начните с корня дерева.
- Повторяйте, пока не дойдете до внешнего конечного узла.
- Прочитано один бит сообщения.
- Взять левую ветвь дерева, если бит равен 0; брать правая ветвь, если это 1.
- Напечатать символ в этом внешнем узле. Весь этот процесс повторяется, начиная с корня, пока все биты в сжатое сообщение исчерпано. Ваша основная задача — прочитать бинарное дерево и реализовать эту процедуру.
Представление бинарного дерева. Чтобы декодировать битовую строку, вам нужно двоичное дерево, которое хранит кодировки символов. Мы используем обход бинарного дерева в прямом порядке, чтобы представить само дерево. Внутренние узлы помечены специальным характер ‘*’. (Мы ограничимся сообщения, не содержащие этот специальный символ.) Предварительный обход вышеуказанного дерева:
* а * * ! * д в * р б
Формат ввода. Входные данные будут состоять из обхода предварительного порядка
двоичное дерево, за которым сразу следует сжатое сообщение.
В приведенном выше примере входной файл
является
Входные данные будут состоять из обхода предварительного порядка
двоичное дерево, за которым сразу следует сжатое сообщение.
В приведенном выше примере входной файл
является абра.пре :
*а**!*дк*рб 0111110010110101001111100100
Часть 1: Построение дерева. Напишите (рекурсивную) функцию maketree() , которая читает в прямом обходе и восстанавливает соответствующее дерево. Используйте стандартный тип данных двоичного дерева ниже, чтобы представить дерево.
узел структуры typedef *link;
структурный узел {
харизматичный персонаж;
ссылка слева;
ссылка справа;
};
Часть 2. Обход дерева. Напишите функцию length() , которая проходит через бинарное дерево и выводит список символов дерева, а длина (количество бит) их кодирования. Для приведенного выше примера ваша программа должна производить следующий вывод (хотя для этого нужно не производить его в этом точном порядке):
биты символов --------------- 1 ! 3 д 4 с 4 р 3 б 3
Часть 3: Расшифровка.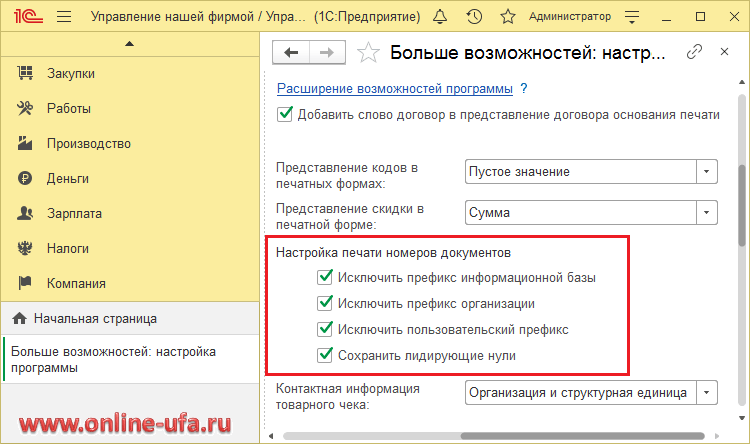 Напишите функцию uncompress() , которая считывает
сжатое сообщение из стандартного ввода и записывает несжатое
сообщение на стандартный вывод.
Он также должен отображать количество считанных битов,
количество символов в исходном сообщении,
и коэффициент сжатия .
Напишите функцию uncompress() , которая считывает
сжатое сообщение из стандартного ввода и записывает несжатое
сообщение на стандартный вывод.
Он также должен отображать количество считанных битов,
количество символов в исходном сообщении,
и коэффициент сжатия .
Например, исходное сообщение выше
содержит 12 символов, для которых обычно требуется 96 бит
памяти (8 бит на символ).
Сжатое сообщение использует только 28 бит или 29 бит.% площади
требуется без компрессии. Коэффициент сжатия зависит
от частоты символов в сообщении, а соотношения
около 50% являются общими для английского текста.
Обратите внимание, что для больших сообщений
количество места, необходимое для хранения описания дерева
пренебрежимо мал по сравнению с хранением самого сообщения, поэтому мы имеем
не учитывал эту величину в расчетах.
Также для простоты сжатое сообщение представляет собой последовательность
символов '0' и '1' .
В реальном приложении эти биты будут упакованы по восемь в байт,
таким образом, используя 1/8 пространства.