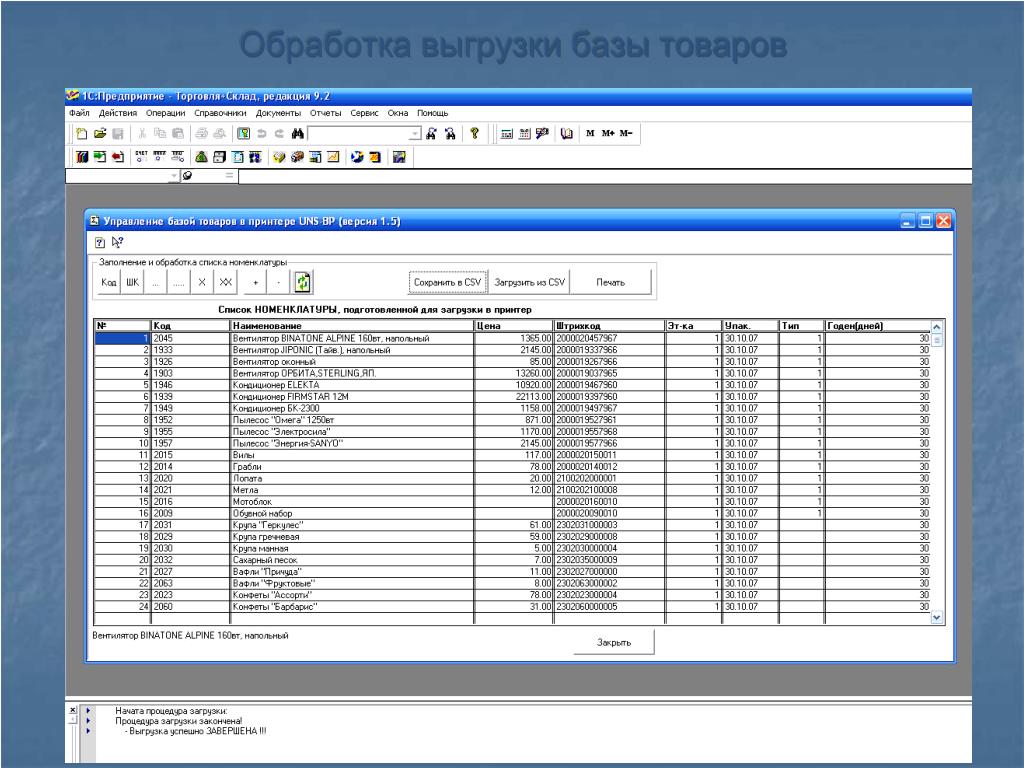
Вопросы и ответы на портале 1С:Предприятие
Назначение продукта
«1С:Предприятие 8. 1С-Логистика:Управление складом 3.0» – это система автоматизированного принятия решений, «мозг» современного складского комплекса. Она позволяет существенно повысить эффективность его работы, а именно:
- оптимизировать использование площади склада
- сократить затраты на хранение товара на складе
- сократить время проведения всех складских операций
- сократить количество ошибочных складских операций
- повысить точность учета товара
- избежать потерь, связанных с ограниченным сроком реализации товара
- уменьшить зависимость от «человеческого фактора»
«1C-Логистика: Управление складом 3.0» позволяет в реальном времени осуществлять управление складами любого размера и типа:
- интенсивными складами (более 1000 заказов в сутки) с подключением большого количества радиотерминалов
- небольшими складами-магазинами
- крупными распределительными центрами
- складами готовой продукции крупных промышленных предприятий в самых разных отраслях
- складами ответственного хранения
- и др
Достоинства программы «1C-Логистика: Управление складом 3. 0»:
0»:
- легкость и простота адаптации к условиям работы практически любого складского комплекса, специфике его технологических и организационных требований
- поддерживает работу с различными типами торгового оборудования: принтерами этикеток, сканерами штрих-кода, бэтч – и радиотерминалами сбора данных
- интеграция с различными системами управления предприятием. Наиболее тесная интеграция достигается с программными продуктами фирмы «1С».
«1C-Логистика: Управление складом 3.0» реализована в среде «1С:Предприятие 8.1» и содержит все преимущества этой технологической платформы: масштабируемость, открытость, простоту администрирования и конфигурирования, наличие сервис-инженеров практически в любом городе и т.д.
Описание функционала
Задание топологии склада и учет товара на складе
Программный продукт «1C-Логистика: Управление складом 3. 0» позволяет вести учет любого количества складов и зон внутри склада. Каждая зона склада состоит из ячеек. Под ячейкой может пониматься любое место хранения товара: ячейка, проезд, комната. Для каждой ячейки задаются габариты и максимальный вес, который она выдерживает.
0» позволяет вести учет любого количества складов и зон внутри склада. Каждая зона склада состоит из ячеек. Под ячейкой может пониматься любое место хранения товара: ячейка, проезд, комната. Для каждой ячейки задаются габариты и максимальный вес, который она выдерживает.
Каждая ячейка на складе имеет свой адрес, по которому она идентифицируется. Такая система адресного хранения позволяет в любой момент точно определить местонахождение товара на складе.
Для складов паллетного хранения существует возможность учета паллет и товара на паллетах. Под паллетой может пониматься любая тара или транспортная единица: поддон, коробка, контейнер и т.д.
В системе присутствует точная информация о наличии на складе товара во всех возможных единицах измерения. Для каждой единицы измерения задаются габаритные, объемные и весовые характеристики.
Кроме этого, в системе предусмотрена возможность учета товара в разрезе дополнительных характеристик (цвет, размер, полнота и т. п.), партий, сроков годности, сертификатов и серийных номеров.
п.), партий, сроков годности, сертификатов и серийных номеров.
При проведении складских операций контролируется вместимость ячеек и паллет по объему, количеству и весу товара.
Планирование и приемка товара
Возможными источниками поступления товара могут быть поставщики (в случае прихода товара от поставщика), клиенты (в случае возврата товара от клиента), другие склады (в случае перемещения между складами одного предприятия), производственные площадки (в случае поступления готовой продукции из производства).
При этом в «1C-Логистика: Управление складом 3.0» присутствует механизм подготовки склада к приемке и размещению товара. Информация о планируемой приемке заносится и хранится системой.
Планирование приемки позволяет:
- ввести информацию о товаре или его штрих-коде
- распечатать этикетки на товар или паллеты
- подготовить паллеты
- привлечь дополнительные ресурсы (сотрудники, оборудование) для приемки товара
- подготовить складские площади к размещению товара как в зоне приемки , так и в основной зоне хранения (например, компрессия склада или подпитка активной зоны)
Существует возможность автоматического получения информации о планируемой приемке из таких систем, как «1С:Управление производственным предприятием 8» и «1С:Управление торговлей 8» или в формате XML из любой другой информационной системы.
Процедура приемки товара может включать в себя следующие операции:
- разгрузка в зоне приемки
- идентификация и маркировка
- приведение товара к стандарту складского хранения
- контроль качества поступившего товара
- пересчет товара и т.д.
Система позволяет осуществлять приемку товара как «по факту» поступления товара, так и на основе информации о планируемом поступлении. В последнем случае система может отследить расхождения между запланированным и фактически принятым товаром. При наличии расхождений, можно получить список несоответствий.
Размещение товара на складе
После приемки товара происходит его размещение на складе в зоне основного хранения. Формирование задания на размещение товара может происходить в автоматическом режиме.
Размещение товара происходит таким образом, чтобы его дальнейший отбор происходил наиболее оптимально. Обычно склад делится на области, в которых товар размещается в соответствии с АВС – классификацией или особенностями хранения (негабаритный товар, требования к температурному режиму, брак и т.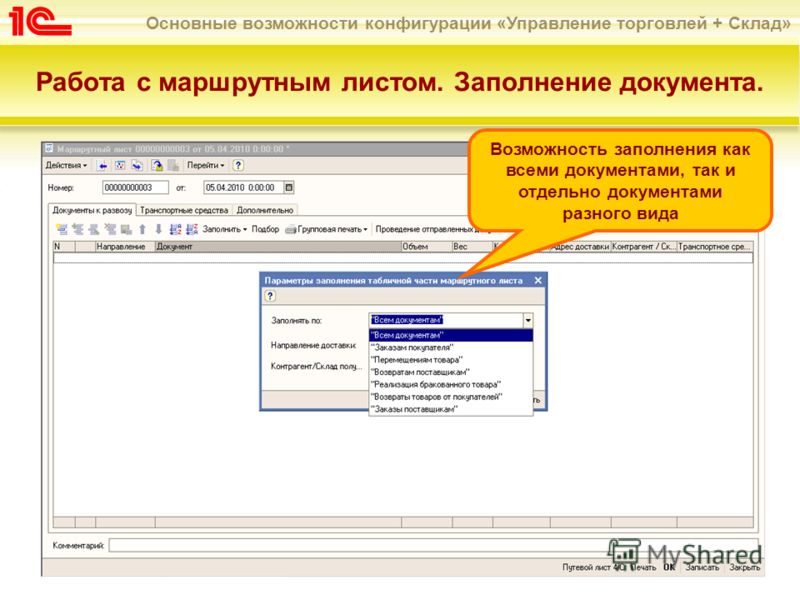 д.).
д.).
Для каждого товара задаются индивидуальные приоритеты размещения:
- размещение товара в свободные ячейки
- размещение товара в занятые ячейки к такому же товару
- размещение товара в занятые ячейки к другому товару
- закрепление определенной ячейки за конкретным товаром
При размещении контролируются весогабаритные характеристики товара. Исходя из этой информации, система выбирает только те ячейки, куда этот товар физически можно разместить.
Также может контролироваться совместимость товаров на складе. Например, можно исключить возможность нахождения одного и того же товара с разными сроками годности в одной и той же ячейке для уменьшения вероятности ошибки при его отборе.
Отбор, упаковка и отгрузка товара
Возможными получателями товара со склада могут быть клиенты (в случае отгрузки товара клиенту), поставщики (в случае возврата товара поставщику), другие склады (в случае перемещения между складами одного предприятия), производственные площадки (в случае выдачи материалов и комплектующих в производство) и т.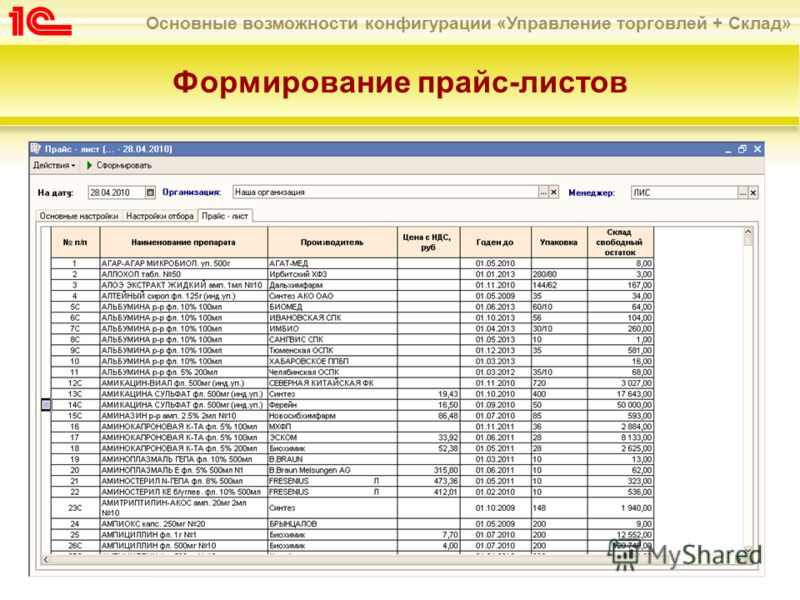 д.
д.
В «1C-Логистика: Управление складом 3.0» хранится информация о планируемых отгрузках товара. Эта информация может являться основанием для проведения подготовительных мероприятий (например, подпитка ячеек активной зоны или подготовка зоны отгрузки к принятию собранного заказа) и самого отбора.
На основании планирования отгрузки производится отбор товара. Отбор одного заказа может производиться одновременно как одним, так и нескольким сотрудникам. Также предусмотрена возможность одновременного сбора нескольких заказов одним сотрудником.
Автоматическое формирование задания на отбор товара может выполняться по следующим принципам:
- отбор с учетом партии товара (FIFO, LIFO, вручную)
- отбор с учетом сроков годности товара (FEFO, LEFO, вручную)
- отбор товара из ячеек в порядке их рейтинга
- отбор товара по принципу максимального высвобождения ячеек
- отбор товара по принципу минимизации времени
- отбор товара с возможной заменой единиц измерения на более крупные или мелкие
- паллетный отбор товара
- автоматическая подпитка активной зоны при выполнении отбора (в случае отсутствия товара в активной зоне отбора)
Система поддерживает операцию сборки товара (комплекта) из комплектующих.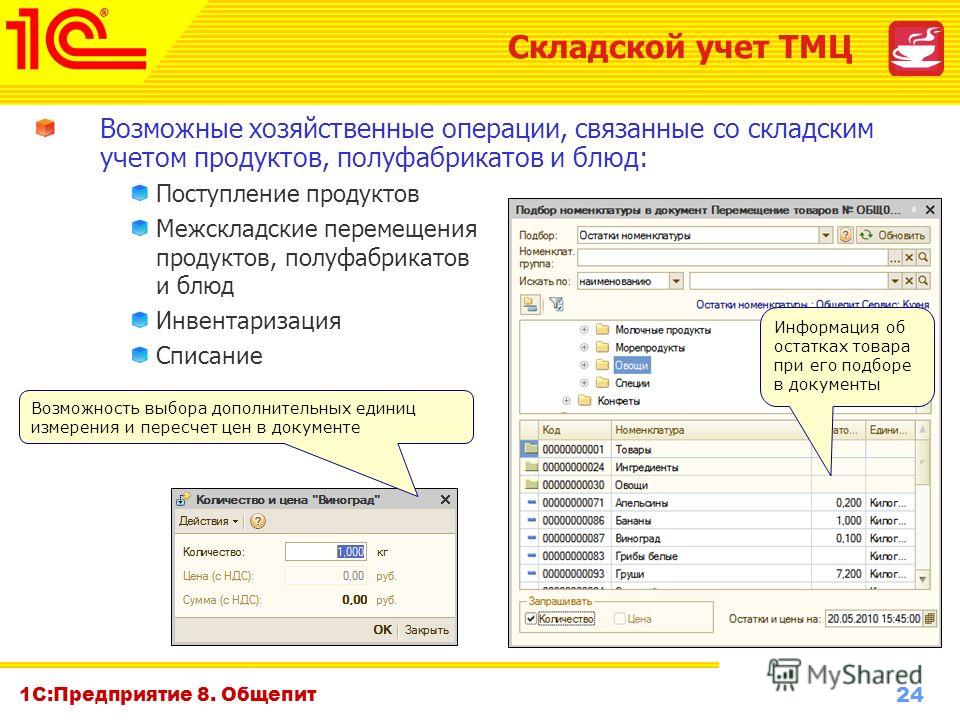
После отбора товара может быть проведена операция сборки, в результате которой на складе появляется комплект, а комплектующие будут списаны со склада. Возможно также проведение обратной операции – разукомплектации.
Перед отгрузкой также может быть проведена операция упаковки или переупаковки товара. При этом товар может быть переупакован в единицы хранения, требуемые клиентом, а также переложен на другие паллеты или в другую тару.
После выполнения операций отбора, сборки и упаковки товар попадает в зону отгрузки и может быть отгружен клиенту. В случае отказа клиента от всего товара или его части можно провести разукомплектацию заказа и повторное размещение товара на складе.
Инвентаризация
Проведение полной инвентаризации может привести к полной остановке работы склада и, соответственно, прекращению отгрузки товаров заказчикам. Поэтому в большинстве случаев инвентаризация производится без остановки основной работы.
Избирательный пересчет товара на складе во время рабочего цикла позволяет сократить или полностью избежать остановки в работе.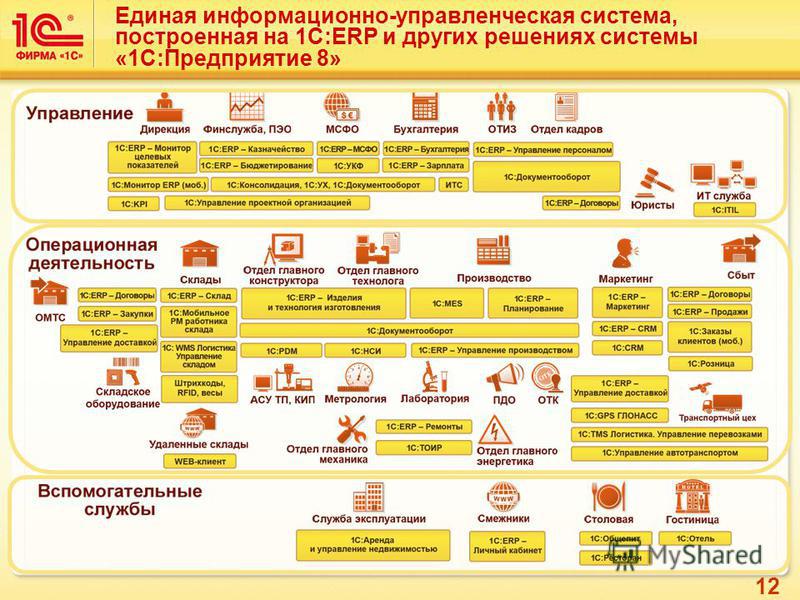
В «1C-Логистика: Управление складом 3.0» предусмотрены следующие типы инвентаризации:
- инвентаризация определенной товарной позиции на складе (проводится в тех ячейках, где присутствует указанный товар)
- инвентаризация произвольной области склада (проводится по ячейкам данной области)
- инвентаризация пустых ячеек (проводится визуальный контроль ячеек на отсутствие в них какого-либо товара)
При проведении инвентаризации ячейки, в которых проводится пересчет товара, блокируются. Возможна блокировка как ячейки целиком, так и определенного товара в ячейке. После проведения инвентаризации блокировка снимается, и ячейки становятся доступными для складских операций.
Управление задачами и ресурсами
Управление задачами и ресурсами включает в себя планирование, выдачу иконтроль выполнения задач ресурсами (персоналом и оборудованием). Под задачей понимается любая операция или группа операций, которая должна быть выполнена на складе.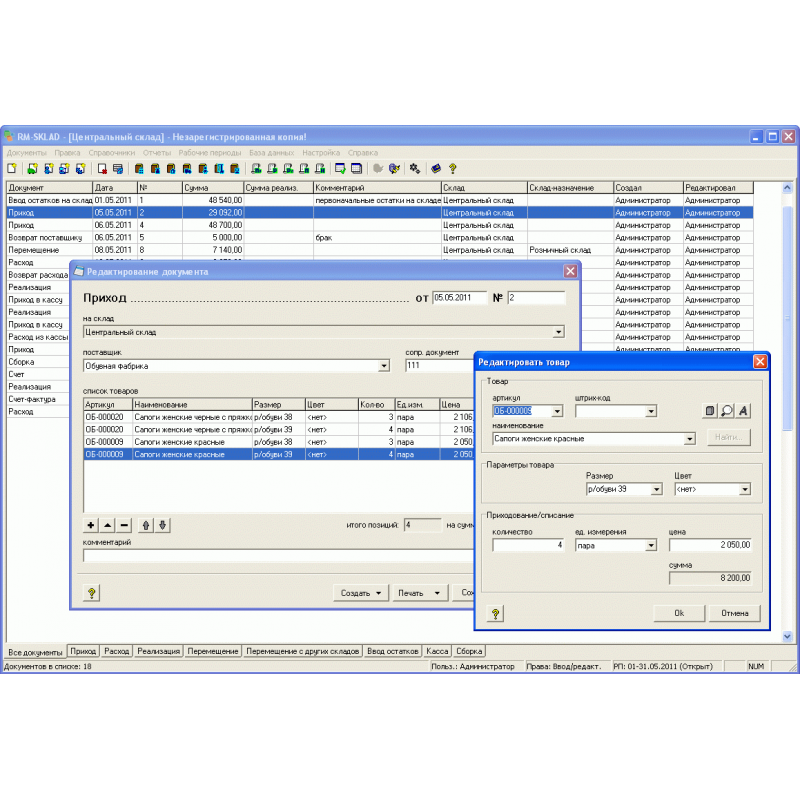 Управление задачами производится диспетчером склада в реальном времени.
Управление задачами производится диспетчером склада в реальном времени.
Планирование задач производится исходя из доступности ресурсов, требуемых для ее выполнения. Существует возможность установки приоритета выполнения задачи. Для каждой операции может быть создан список ресурсов с указанием наиболее желательных ролей складских работников или типов оборудования (в порядке убывания приоритета). Таким образом, если наиболее желательный ресурс в данный момент не доступен, то может использоваться ресурс более низкого приоритета.
При выдаче задачи фиксируется время ее выдачи и ресурс, ответственный за выполнение. «1C-Логистика: Управление складом 3.0» поддерживает 2 способа выдачи задач:
- «Бумажная» технология. Задачи выдаются на бумажных носителях, и складской работник делает отметку о ее выполнении вручную. Контроль выпонения задач осуществляется оператором также в ручном режиме.
- Радиотерминалы. Использование радиотерминалов также подразумевает безбумажную технологию.
 Радиотерминалы имеют on-line подключение к системе, что обеспечивает работу в режиме реального времени, которая является обязательным требованием для крупных складов с большим товарооборотом.
Радиотерминалы имеют on-line подключение к системе, что обеспечивает работу в режиме реального времени, которая является обязательным требованием для крупных складов с большим товарооборотом.
Задачи, в процессе выполнения, могут перераспределяться между ресурсами, быть приостановлены или отменены. По каждому складскому работнику фиксируется вся история его работы: задачи, которые он выполнял, время их выполнения, объем товара, простои и т.д. Это позволяет реализовать гибкую систему мотивации складского персонала при выполнении должностных обязанностей.
Штрих-кодирование
«1C-Логистика: Управление складом 3.0» поддерживает штрих-кодирование товаров, ячеек и паллет с использованием любых типов штрих-кодов.
Штрих-коды для товаров могут формироваться с учетом артикула, серии, партии, единицы измерения, характеристики. Таким образом, по штрих-коду можно идентифицировать и проследить товар, все его свойства и характеристики.
Любой штрих-код может быть распечатан на обычном принтере или же на специализированном принтере этикеток.
Работа в системе с использованием радиотерминалов сбора данных
Одной из самых важных функций системы является возможность использования широкого спектра радиотерминалов сбора данных в режиме терминального клиента Windows.
Для входа складского работника в систему необходимо пройти процедуру идентификации. Пройдя эту процедуру, складской работник считается активным и доступным для выполнения задач. Тем работникам, которые не вошли в систему, задачи выдаваться не будут. Активным сотрудникам задачи выдаются на радиотерминал сбора данных в виде всплывающих окон.
В «1C-Логистика: Управление складом 3.0» существуют преопределенные последовательности выполнения задач (бизнес-процессы):
- пересчет (выполняется при проведении операций приемки, инвентаризации, отгрузки товара)
- транспортировка
- штучная (выполняется при проведении операций штучного отбора, перемещения товара между паллетами или ячейками)
- паллетная (выполняется при проведении операций размещения, отбора, подпитки и перемещения целыми паллетами)
Задачи формулируются таким образом, чтобы складской работник, не имеющий навыков обращения с техникой, мог быстро и безошибочно выполнять элементарные операции – подойти к ячейке, взять, положить, пересчитать товар и т. д. Все операции подтверждаются путем сканирования штрих-кода ячейки, товара, паллеты или нажатием горячей клавиши.
д. Все операции подтверждаются путем сканирования штрих-кода ячейки, товара, паллеты или нажатием горячей клавиши.
В системе задач существуют действия, инициируемые складским работником либо автоматически при сканировании штрих-кода, либо вручную по нажатию сочетания клавиша на радиотерминале сбора данных.
Существуют следующие действия:
- далее (переход к следующей задаче)
- проблема (отмена текущей задачи по причине возникшей проблемы)
- отказ (отказ от выполнения задачи, например, если сотрудник временно не доступен)
- завершение (завершение выполнения операции, действие может быть инициировано автоматически при выполнении всех задач)
Система может оказать помощь складскому работнику – прислать контекстную подсказку для выполнения текущей задачи.
После выполнения задач складским работником результаты передаются напрямую в электронный документ, по которому была спланирована задача. Таким образом, оператор может отслеживать ход работ по документу, просто открыв его.
Расчет услуг ответственного хранения
Склад ответственного хранения оказывает услуги по хранению и грузопереработке товара, принадлежащего другим организациям.
Модуль «Расчет услуг ответственного хранения» обеспечивает выполнение следующих функций:
В «1C-Логистика: Управление складом 3.0» ведется список владельцев товара, для каждого из которых создается уникальный товарный каталог. Правила работы и совершения операций с товаром могут задаваться индивидуально для каждого владельца.
Тарифы на услуги ответственного хранения могут задаваться сразу для всего склада или же индивидуально для каждого владельца. Они задаются исходя их количества упаковок товара, участвовавших в операции, веса или объема товара, количества паллет или фиксированной суммы за операцию.
При расчете услуг по разовым операциям результаты заносятся сразу в документ, и при необходимости их можно скорректировать, например, добавить дополнительную услугу, которая оказывалась во время проведения операции.
Для расчета периодической услуги, например, хранения, используется регламентный документ. Данный расчет можно производить с любой периодичностью.
Отчеты по оказанным услугам могут быть сформированы в любом виде.
Особенности лицензирования
Программный продукт «1С:Предприятие 8. 1С-Логистика:Управление складом 3.0» обеспечивает работу прикладного решения на одном рабочем месте в один момент времени.
Для работы в многопользовательском режиме необходимо наличие у пользователей лицензий на конфигурацию «1С-Логистика:Управление складом 3.0» иклиентских лицензий «1С:Предприятие 8» на соответствующее количество рабочих мест.
Для работы в клиент-серверном режиме необходимо наличие у пользователей лицензий на сервер.
1с торговля и склад 8.3 в Чебоксарах: 500-товаров: бесплатная доставка, скидка-70% [перейти]
Партнерская программаПомощь
Чебоксары
Каталог
Каталог Товаров
Одежда и обувь
Одежда и обувь
Стройматериалы
Стройматериалы
Текстиль и кожа
Текстиль и кожа
Здоровье и красота
Здоровье и красота
Детские товары
Детские товары
Продукты и напитки
Продукты и напитки
Электротехника
Электротехника
Дом и сад
Дом и сад
Мебель и интерьер
Мебель и интерьер
Промышленность
Промышленность
Сельское хозяйство
Сельское хозяйство
Все категории
ВходИзбранное
1с торговля и склад 8. 3
3
А. А. Гладкий «1С. Управление торговлей 8.3. 100 уроков для начинающих»
ПОДРОБНЕЕЕще цены и похожие товары
Переход с 1С 7.7 на 1С 8.3 Производитель: 1С, Категория: СУБД
ПОДРОБНЕЕЕще цены и похожие товары
1С:Управление торговлей 8.3 1С 1С:Управление торговлей Производитель: 1С, Категория: торговля,
ПОДРОБНЕЕЕще цены и похожие товары
Куправа Т. А. «Управление торговлей 1С:8.3» Издательство: ДМК Пресс, Год издания: 2015
ПОДРОБНЕЕЕще цены и похожие товары
30 000
1С 8.3 Снабжение и склад в Москве
ПОДРОБНЕЕЕще цены и похожие товары
Т. А. Куправа «Управление торговлей 1С:8.3. Редакция 11.1. Функционал развития» Издательство: ДМК
ПОДРОБНЕЕЕще цены и похожие товары
1С. Управление торговлей 8.3. 100 уроков для начинающих | Гладкий Алексей Анатольевич
Управление торговлей 8.3. 100 уроков для начинающих | Гладкий Алексей Анатольевич
ПОДРОБНЕЕЕще цены и похожие товары
1С:Управление торговлей 8. Базовая версия
ПОДРОБНЕЕЕще цены и похожие товары
15 239
Mobile SMARTS: Склад 15, базовый для конфигурации на базе «1С:Предприятия 8.3» (Wh25A-1C83)
ПОДРОБНЕЕЕще цены и похожие товары
49 000
1С 8.3 Управление складом Производитель: 1С, Категория: складские программы
ПОДРОБНЕЕЕще цены и похожие товары
1С 8.3 УТ 11
ПОДРОБНЕЕЕще цены и похожие товары
Куправа Т.А. «Управление торговлей 1С:8.3. Редакция 11.1. Функционал развития» Издательство: ДМК
ПОДРОБНЕЕЕще цены и похожие товары
66 175
Для терминалов сбора данных Cleverence Лицензия Mobile SMARTS: Кировка, «зарубежный склад» оффлайн, интеграция с конфигурацией на базе «1С:Предприятия 8. 3», без обмена с «Маркировкой» KRVW-1C83
3», без обмена с «Маркировкой» KRVW-1C83
ПОДРОБНЕЕЕще цены и похожие товары
26 649
Программное обеспечение Mobile SMARTS: Склад 15, расширенный для конфигурации на базе «1С:Предприятия 8.3» (Wh25B-1C83)
ПОДРОБНЕЕЕще цены и похожие товары
26 117
Mobile SMARTS: Склад 15, расширенный для конфигурации на базе «1С:Предприятия 8.3» (Wh25B-1C83)
ПОДРОБНЕЕЕще цены и похожие товары
1С:Предприятие 8.3. Бухгалтерия предприятия. Управление торговлей. Управление персоналом | Филатова Виолетта Олеговна
ПОДРОБНЕЕЕще цены и похожие товары
37 749
Программное обеспечение Mobile SMARTS: Склад 15, омни для конфигурации на базе «1С:Предприятия 8.3» (Wh25C-1C83)
ПОДРОБНЕЕЕще цены и похожие товары
63 649
Программное обеспечение Mobile SMARTS: Склад 15 продуктовый, расширенный для конфигурации на базе «1С:Предприятия 8.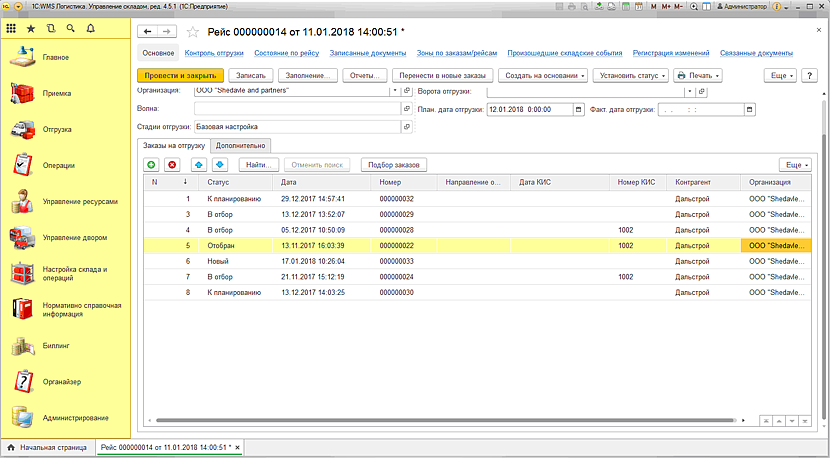 3» (Wh25BG-1C83)
3» (Wh25BG-1C83)
ПОДРОБНЕЕЕще цены и похожие товары
49 000
1С:Предприятие 8. 1С-Логистика:Управление складом 3.0 (USB) Производитель: 1С, Категория:
ПОДРОБНЕЕЕще цены и похожие товары
22 600
1С: Управление торговлей 8.3 Производитель: 1С, Категория: торговля
ПОДРОБНЕЕЕще цены и похожие товары
48 365
1С: Предприятие 8. Управление Торговлей (USB) + 1С-Битрикс: Управление сайтом. Малый Бизнес
ПОДРОБНЕЕЕще цены и похожие товары
22 600
1С:Предприятие 8. Управление торговлей
ПОДРОБНЕЕЕще цены и похожие товары
Mobile SMARTS: Склад 15 для «1С:Предприятия 8.3» Производитель: 1С, Категория: управление
ПОДРОБНЕЕЕще цены и похожие товары
Управление торговлей 1С:8. 3. Редакция 11.1. Функционал развития | Куправа Тенгиз Арвелодович
3. Редакция 11.1. Функционал развития | Куправа Тенгиз Арвелодович
ПОДРОБНЕЕЕще цены и похожие товары
1С:Управление торговлей 8. Базовая версия Производитель: 1С, Название программы: 1С:Управление
ПОДРОБНЕЕЕще цены и похожие товары
1С:Управление торговлей 8.3 онлайн Категория: торговля, Название программы: 1С:Управление торговлей
ПОДРОБНЕЕЕще цены и похожие товары
Севостьянов А.Д., Севостьянова Ю.М. «1С:Управление торговлей 8. Редакция 11.1. Практика применения»
ПОДРОБНЕЕЕще цены и похожие товары
1С 8.3 Управление торговлей 11.1 Производитель: 1С, Категория: торговля
ПОДРОБНЕЕЕще цены и похожие товары
2 страница из 18
Корпоративное хранилище данных (EDW) Определение — что такое хранилище данных?
Решения Precisely для интеграции данных помогут вам извлечь ценные данные из устаревших систем
УЗНАТЬ БОЛЬШЕЧто такое корпоративное хранилище данных или EDW?
Хранилище данных предприятия (EDW) — это база данных или совокупность баз данных, которая централизует бизнес-информацию из нескольких источников и приложений и делает ее доступной для аналитики и использования во всей организации. EDW могут размещаться на локальном сервере или в облаке.
EDW могут размещаться на локальном сервере или в облаке.
Данные, хранящиеся в этом типе цифрового хранилища, могут быть одним из самых ценных активов бизнеса, поскольку они представляют большую часть того, что известно о бизнесе, его сотрудниках, его клиентах и многом другом.
Преимущества организации EDW
Обслуживание корпоративного хранилища данных выгодно для организации по многим причинам. Обычно такой сбор и хранение данных рассматривается с точки зрения маркетинга или отношений с клиентами, и это, безусловно, одна часть головоломки.
Однако это не единственная функция хранилища данных. Это также может помочь разобраться в кажущихся случайными фрагментах данных, которые поступают в организацию через различные входные данные, и может сэкономить драгоценное время за счет автоматического агрегирования этой информации. Организации, скорее всего, окажутся в лучшем положении для будущего роста, если их данные будут организованы таким систематическим, автоматизированным способом.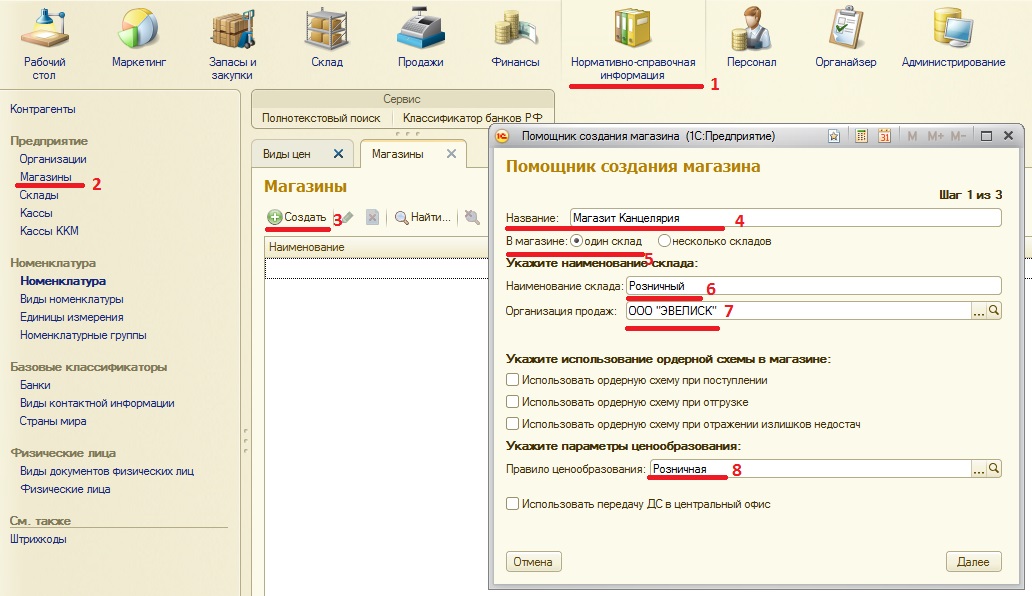
Структурирование данных
Даже для компаний, работающих в относительно небольших масштабах, организация и структура чрезвычайно важны, когда речь идет о создании и обслуживании EDW.
Чтобы данные были полезными, они должны храниться логично и непротиворечиво. Знание того, где и какие данные можно искать, и уверенность в том, что возвращаемые данные точны, является огромной частью задачи.
Для чего подходит хранилище данных… и для чего оно не подходит
Для создания качественного EDW часто внедряется система «извлечение, преобразование, загрузка» (ETL). Популярность ETL обусловлена тем, что она может помочь организациям успешно создавать корпоративные хранилища данных и управлять ими. Однако по мере того, как объемы данных начали расти в 2000-х годах, появилась тенденция использовать базу данных для более масштабируемой интеграции данных, что привело к «ELT», когда данные извлекались (из исходных приложений), загружались (в EDW).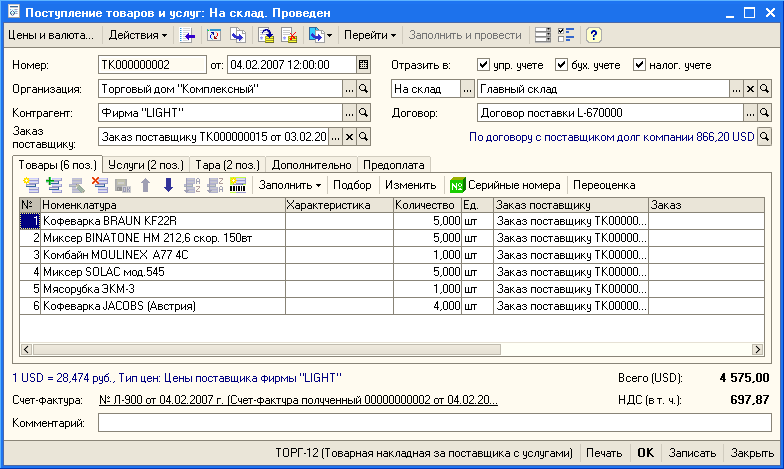 а затем Преобразованный (внутри EDW).
а затем Преобразованный (внутри EDW).
Использование EDW для преобразования больших объемов данных может иметь непредвиденные последствия, включая увеличение затрат и сложности, а также узкие места в обработке и несоблюдение соглашений об уровне обслуживания, из-за чего бизнес-пользователям приходится ждать дни, недели или даже месяцы для получения необходимых им отчетов.
Чтобы реализовать первоначальную цель Data Warehouse — улучшенную аналитику и бизнес-аналитику — и первоначальную цель ELT (повышение масштабируемости), многие компании используют распределенные платформы для работы с большими данными, такие как Hadoop MapReduce и Apache Spark plus. Инструменты ETL, специально разработанные для этих сред больших данных. Это освобождает хранилище данных для того, для чего оно предназначено, предоставляет более своевременную информацию и может снизить затраты.
Компания Precisely, пионер на рынке программного обеспечения для работы с большими данными, предлагает высокопроизводительное программное обеспечение для интеграции данных, изначально предназначенное для работы в Hadoop и Spark. Их продукты и эксперты помогли некоторым из крупнейших организаций в мире получить максимальную отдачу от их EDW, перенеся обработку ELT/ETL на платформы больших данных.
Их продукты и эксперты помогли некоторым из крупнейших организаций в мире получить максимальную отдачу от их EDW, перенеся обработку ELT/ETL на платформы больших данных.
Как Precisely может помочь
Precisely предлагает решения для интеграции данных и качества данных, которые помогут вам управлять корпоративным хранилищем данных.
- Precise Connect поможет вам оптимизировать и разгрузить хранилище данных.
- Spectrum Data Federation помогает вам получать доступ, интегрировать, виртуализировать и синхронизировать данные из самых разных приложений и систем для более эффективного бизнес-анализа, аналитики, обслуживания клиентов и операционной эффективности.
Корпоративное хранилище данных: концепции и архитектура
Время чтения: 14 минут
В течение дня мы принимаем множество решений, опираясь на предыдущий опыт. Наш мозг хранит триллионы бит данных о прошлых событиях и использует эти воспоминания каждый раз, когда нам нужно принять решение.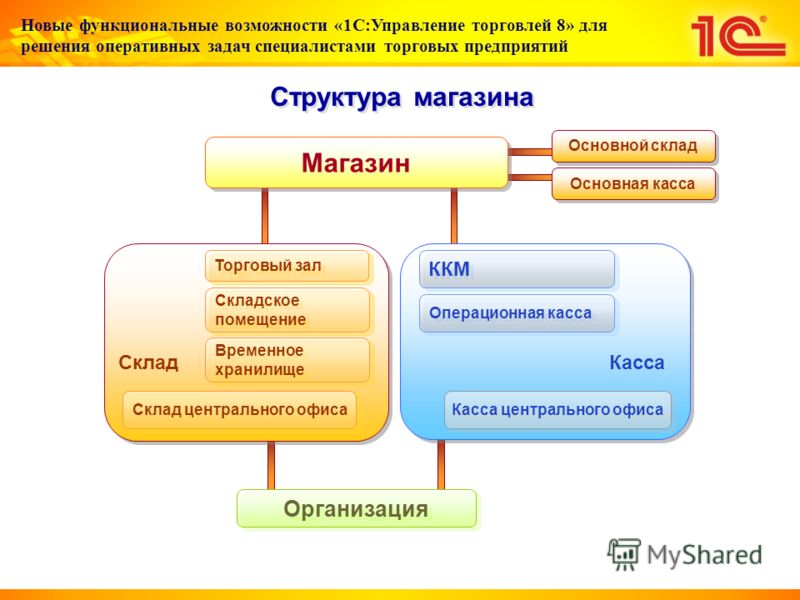 Как и люди, компании генерируют и собирают массу данных о прошлом. И эти данные можно использовать для принятия лучших решений.
Как и люди, компании генерируют и собирают массу данных о прошлом. И эти данные можно использовать для принятия лучших решений.
Хотя наш мозг служит как для обработки, так и для хранения данных, компаниям требуется несколько инструментов для работы с данными. И одним из самых важных является корпоративное хранилище данных или EDW.
В этой статье мы обсудим, что такое корпоративное хранилище данных, его виды и функции, а также как оно используется при обработке данных. Определим, чем корпоративные хранилища отличаются от обычных, какие типы хранилищ данных существуют и как они работают. Основное внимание уделяется предоставлению информации о коммерческой ценности каждого архитектурного и концептуального подхода к созданию склада.
Что такое корпоративное хранилище данных?
Корпоративное хранилище данных (EDW) — это форма централизованного корпоративного репозитория, в котором хранятся и управляются все исторические бизнес-данные предприятия. Информация обычно поступает из разных систем, таких как ERP, CRM, физические записи и другие плоские файлы. Для подготовки данных для дальнейшего анализа их необходимо поместить в единое хранилище. Таким образом, различные бизнес-подразделения могут запрашивать и анализировать информацию с разных точек зрения. Но чтобы любые данные стали полезными для понимания, они должны пройти долгий путь. Подробнее о том, как данные попадают из источников в инструменты бизнес-аналитики, вы можете узнать в нашем видео об инженерии данных.
Информация обычно поступает из разных систем, таких как ERP, CRM, физические записи и другие плоские файлы. Для подготовки данных для дальнейшего анализа их необходимо поместить в единое хранилище. Таким образом, различные бизнес-подразделения могут запрашивать и анализировать информацию с разных точек зрения. Но чтобы любые данные стали полезными для понимания, они должны пройти долгий путь. Подробнее о том, как данные попадают из источников в инструменты бизнес-аналитики, вы можете узнать в нашем видео об инженерии данных.
С помощью хранилища данных предприятие может управлять огромными наборами данных без администрирования нескольких баз данных. Такая практика является перспективным способом хранения данных для бизнес-аналитики (BI) , которая представляет собой набор методов/технологий для преобразования необработанных данных в полезные идеи. Поскольку EDW является важной частью этой системы, система похожа на человеческий мозг, хранящий информацию, но на стероидах.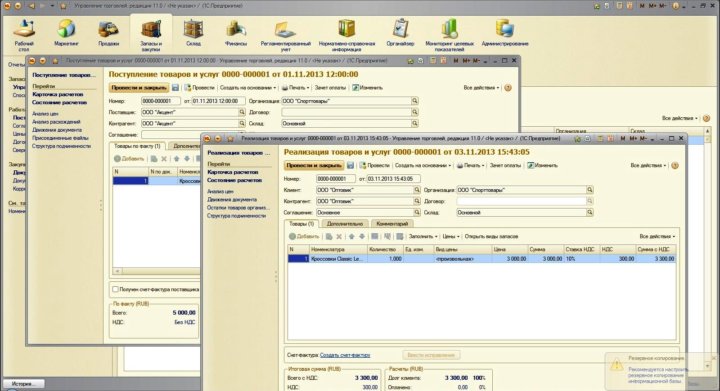
Компоненты корпоративного хранилища данных
Существует множество инструментов, используемых для настройки платформы корпоративного хранилища данных. Давайте взглянем с высоты птичьего полета на назначение каждого компонента и его функции.
Компоненты EDW
Источники данных . Это все источники данных, в которых исходные данные берутся и/или хранятся. Они могут варьироваться от простых электронных таблиц до плоских файлов, реляционных баз данных SQL, систем IoT и многого другого.
Уровень приема . Существует два основных подхода к извлечению данных из источников и доставке их в хранилище. Инструменты извлечения, преобразования, загрузки (ETL) и извлечения, загрузки, преобразования (ELT) подключаются ко всем исходным данным и выполняют их извлечение, преобразование и загрузку в централизованную систему хранения для легкого доступа и анализа. Различие между подходами ETL и ELT заключается в порядке событий. В ETL преобразование происходит в промежуточной области — до того, как данные попадут в EDW. Более современный подход: ELT выполняет все работы по преобразованию внутри склада. Здесь плацдарм отсутствует.
В ETL преобразование происходит в промежуточной области — до того, как данные попадут в EDW. Более современный подход: ELT выполняет все работы по преобразованию внутри склада. Здесь плацдарм отсутствует.
Промежуточная зона (опционально) . В случае ETL промежуточная область — это место, где данные преобразовываются перед EDW. Здесь он будет очищен, дедуплицирован, разделен, объединен и преобразован в унифицированный формат, чтобы соответствовать заданной модели данных хранилища. Промежуточная область может также включать инструменты для управления качеством данных.
Уровень хранения . Данные, наконец, загружаются в пространство для хранения. С подходом ELT здесь все еще может потребоваться некоторое преобразование. Но на этом этапе будут применены все общие изменения, поэтому данные будут загружены в его окончательную(ые) модель(и). Как мы уже упоминали, хранилища данных чаще всего представляют собой реляционные базы данных. DW также будет включать систему управления базами данных и дополнительное хранилище для метаданных.
Модуль метаданных . Проще говоря, метаданные — это данные о данных. Это пояснения, которые подсказывают пользователям/администраторам, к какому субъекту/домену относится эта информация. Эти данные могут быть техническими (например, исходный источник) или бизнес-мета (например, регион продаж). Вся мета хранится в отдельном модуле EDW и управляется менеджером метаданных. В некоторых случаях поверх всей инфраструктуры может быть создан дополнительный уровень для управления метаданными, например уровень виртуализации данных или уровень структуры данных.
Витрины данных (дополнительно). В некоторых случаях EDW может иметь набор небольших подразделов, называемых витринами данных, созданных специально для определенной предметной области, бизнес-функции или группы пользователей. Например, может быть отдельная витрина данных для маркетинговых целей и витрина данных для финансового отдела.
Уровень представления . Последний строительный блок EDW включает инструменты, которые предоставляют конечным пользователям доступ к данным. Этот уровень, также называемый интерфейсом BI, будет служить панелью инструментов для визуализации данных, бизнес-отчетности и извлечения отдельных фрагментов информации для таких задач, как машинное обучение.
Этот уровень, также называемый интерфейсом BI, будет служить панелью инструментов для визуализации данных, бизнес-отчетности и извлечения отдельных фрагментов информации для таких задач, как машинное обучение.
Теперь разберемся, почему такое хранилище называется хранилищем данных предприятия, а не просто хранилищем данных.
Корпоративное хранилище данных и обычное хранилище данных: ключевые отличия
По своей сути любое хранилище данных представляет собой базу данных, которая всегда связана с источниками необработанных данных с помощью инструментов интеграции данных с одной стороны и аналитических интерфейсов с другой. Они предоставляют возможности хранения, а также механизмы для преобразования данных, их перемещения и представления конечному пользователю. Если да, то почему мы изолируем корпоративную форму для обсуждения?
Отличие обычного хранилища данных от корпоративного заключается в гораздо более широком архитектурном разнообразии и функциональности. Из-за сложной структуры и размера EDW часто разбиваются на более мелкие базы данных, поэтому конечным пользователям удобнее обращаться к этим небольшим базам данных. Учитывая это, мы ориентируемся на корпоративный склад, чтобы охватить весь спектр функциональности.
Из-за сложной структуры и размера EDW часто разбиваются на более мелкие базы данных, поэтому конечным пользователям удобнее обращаться к этим небольшим базам данных. Учитывая это, мы ориентируемся на корпоративный склад, чтобы охватить весь спектр функциональности.
Однако размер хранилища — не единственное, что определяет его техническую сложность, требования к возможностям аналитики и отчетности, количество моделей данных и сами данные. Итак, чтобы понять, что делает склад тем, чем он является, давайте углубимся в его основные концепции и функциональные возможности.
Концепции и функции корпоративных хранилищ данных
Со всеми прибамбасами, в основе каждого хранилища лежат базовые концепции и функции. Эти столпы определяют склад как технологический феномен.
Служит в качестве конечного хранилища . Хранилище корпоративных данных — это унифицированный репозиторий для всех корпоративных бизнес-данных, когда-либо имевших место в организации.
Отражает исходные данные . EDW получает данные из своих исходных хранилищ, таких как Google Analytics, CRM, устройства IoT и т. д. Если данные разбросаны по нескольким системам, ими невозможно управлять. Итак, цель EDW — обеспечить подобие исходных исходных данных в едином репозитории. Поскольку как внутри компании, так и за ее пределами всегда генерируются новые актуальные данные, поток данных требует специальной инфраструктуры для управления ими до того, как они попадут на склад.
Хранит структурированные данные . Данные, хранящиеся в EDW, всегда стандартизированы и структурированы. Это позволяет конечным пользователям запрашивать его через интерфейсы BI и формировать отчеты. И это то, что отличает хранилище данных от озера данных . Озера данных используются для хранения неструктурированных данных в аналитических целях. Но, в отличие от хранилищ, озера данных больше используются инженерами данных и специалистами по данным для работы с большими наборами необработанных данных.
Предметно-ориентированные данные . Основное внимание в хранилище уделяется бизнес-данным, которые могут относиться к разным областям. Чтобы понять, к чему относятся данные, они всегда структурированы вокруг определенного предмета, называемого моделью данных . Примером темы может быть регион продаж или общий объем продаж данного товара. Кроме того, добавляются метаданные, чтобы подробно объяснить, откуда берется каждая часть информации.
Зависит от времени . Собранные данные обычно представляют собой исторические данные, поскольку они описывают прошлые события. Чтобы понять, когда и как долго имела место та или иная тенденция, преобладающую часть хранимой информации принято разбивать на периоды времени.
Энергонезависимая . После помещения в хранилище данные никогда не удаляются из него. Данными можно манипулировать, изменять или обновлять их из-за изменений в источнике, но они никогда не предназначены для удаления, по крайней мере, конечными пользователями.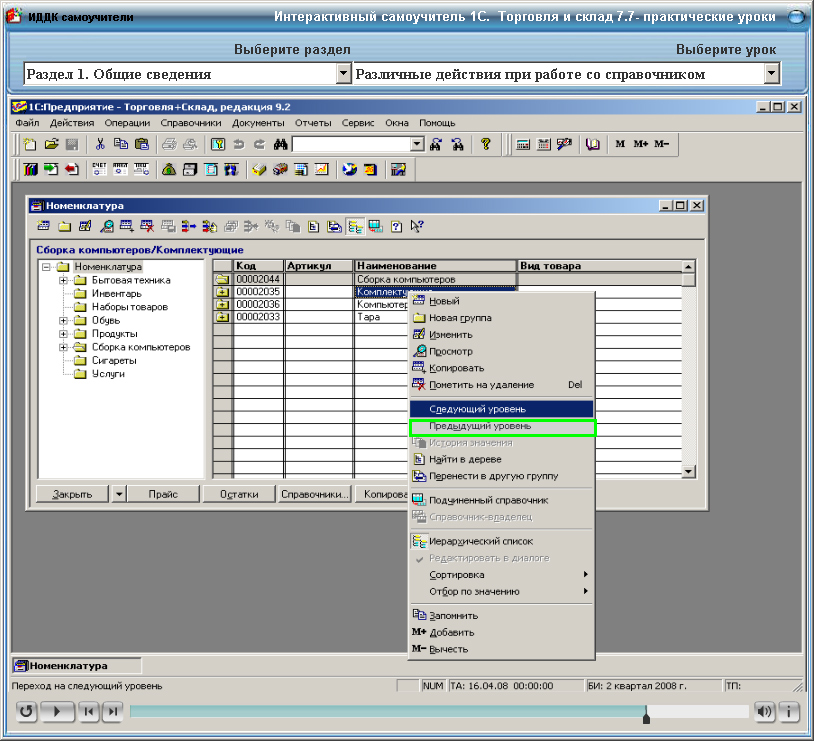 Поскольку мы говорим об исторических данных, удаления контрпродуктивны для аналитических целей. Тем не менее, общий пересмотр может происходить раз в несколько лет, чтобы избавиться от нерелевантных данных.
Поскольку мы говорим об исторических данных, удаления контрпродуктивны для аналитических целей. Тем не менее, общий пересмотр может происходить раз в несколько лет, чтобы избавиться от нерелевантных данных.
Используя базовые принципы, мы рассмотрим типы реализации EDW.
Типы корпоративных хранилищ данных
Принимая во внимание функции EDW, всегда есть место для обсуждения того, как его спроектировать технически. В случае хранения и обработки данных они специфичны и различны для разных видов бизнеса. В зависимости от объема данных, аналитической сложности, вопросов безопасности и бюджета, конечно, всегда есть вариант настройки вашей системы.
Локальное хранилище данных
Локальное хранилище данных считается классическим вариантом для EDW, который имеет свои локальные выделенные аппаратные и программные возможности для унифицированного хранения данных. Когда данные хранятся на физических серверах, вам не нужно настраивать инструменты интеграции данных между несколькими базами данных. Вместо этого EDW можно подключить к источникам данных через API, чтобы постоянно получать информацию и преобразовывать ее в процессе. Итак, вся работа выполняется либо в staging area (место, где данные преобразовываются перед загрузкой в ХД), либо в самом хранилище.
Вместо этого EDW можно подключить к источникам данных через API, чтобы постоянно получать информацию и преобразовывать ее в процессе. Итак, вся работа выполняется либо в staging area (место, где данные преобразовываются перед загрузкой в ХД), либо в самом хранилище.
Классическое хранилище данных считается превосходным по сравнению с виртуальным (о котором мы поговорим ниже), поскольку в нем отсутствует дополнительный уровень абстракции. Это упрощает работу дата-инженеров и упрощает управление потоком данных на стороне предварительной обработки, а также фактическую отчетность.
Недостатки классического склада зависят от фактической реализации, но для большинства предприятий это:
- дорогая технологическая инфраструктура (как аппаратная, так и программная) и
- необходимость нанять команду дата-инженеров и специалистов DevOps для настройки и обслуживания всей платформы данных.
Когда использовать : Такой тип EDW подходит для организаций любого размера, которые хотят безопасно обрабатывать свои данные и максимально эффективно их использовать. Классические хранилища позволяют трансформироваться в различные архитектурные стили платформы данных и целенаправленно масштабироваться вверх и вниз, сохраняя при этом заботу о конфиденциальности данных.
Классические хранилища позволяют трансформироваться в различные архитектурные стили платформы данных и целенаправленно масштабироваться вверх и вниз, сохраняя при этом заботу о конфиденциальности данных.
Виртуальное хранилище данных
Виртуальное хранилище данных — это тип EDW, используемый в качестве альтернативы классическому хранилищу. По сути, это несколько баз данных, соединенных виртуально, поэтому к ним можно обращаться как к единой системе.
Схема отношений между абстракцией виртуального ХД и базами данных-источниками
Данные могут оставаться в своих источниках: физически никуда не перемещаются, но могут быть извлечены с помощью аналитических инструментов. Виртуальные хранилища можно использовать, если вы не хотите возиться со всей базовой инфраструктурой или если ваши данные легко управляемы сами по себе. Однако такой подход имеет много недостатков:
- Несколько баз данных потребуют постоянного обслуживания программного и аппаратного обеспечения и затрат.
- Для данных, хранящихся в виртуальном хранилище данных, по-прежнему требуется программное обеспечение для преобразования, чтобы сделать их удобными для конечных пользователей и средств создания отчетов.
- Сложные запросы данных могут занимать слишком много времени, так как необходимые фрагменты данных могут быть размещены в двух отдельных базах данных.
Когда использовать : Виртуальные хранилища данных подходят для предприятий, которые имеют необработанные данные в стандартизированной форме, не требующей сложной аналитики. Он также подходит организациям, которые не используют BI систематически или хотят начать с него.
Облачное хранилище данных
Облачное хранилище данных — это центральный репозиторий различной информации, размещенной в облаке. В этом случае база данных предоставляется облачным провайдером как управляемая услуга и оптимизирована для аналитики, масштабирования и удобства использования.
Облачные хранилища обычно состоят из уровней вычислений, хранения и клиентского (сервисного) уровня. На уровне вычислений имеется несколько вычислительных кластеров с узлами, обрабатывающими запросы параллельно. Уровень хранения, как следует из названия, хранит все типы информации. Уровень клиента отвечает за действия по управлению данными.
В этом случае архитектура облачного хранилища имеет те же преимущества, что и любая другая облачная служба. Его инфраструктура обычно обслуживается за вас, а это означает, что вам не нужно настраивать собственные серверы, базы данных и инструменты для управления ею. Цена такой услуги будет зависеть от объема памяти и вычислительных мощностей, необходимых для выполнения запросов.
Единственный аспект, который может вас беспокоить с точки зрения платформы облачного хранилища, — это безопасность данных. Ваши бизнес-данные являются конфиденциальной вещью. Итак, вы хотите проверить, можно ли доверять выбранному вами поставщику, чтобы избежать нарушений. Это не обязательно означает, что локальное хранилище более безопасно, но в этом случае безопасность ваших данных находится в ваших руках.
Это не обязательно означает, что локальное хранилище более безопасно, но в этом случае безопасность ваших данных находится в ваших руках.
Когда использовать : Платформы облачных хранилищ данных — отличный выбор для организаций любого размера. Если вам нужно настроить все за вас, включая интеграцию управляемых данных, обслуживание хранилища данных и поддержку бизнес-аналитики.
Архитектура корпоративного хранилища данных
Хотя существует множество архитектурных подходов, которые тем или иным образом расширяют возможности хранилища, мы сосредоточимся на наиболее важных из них. Не вдаваясь в технические подробности, весь конвейер данных можно разделить на три уровня:
- Уровень необработанных данных (источники данных)
- Склад и его экосистема
- Пользовательский интерфейс (аналитические инструменты)
Инструменты, связанные с извлечением, преобразованием и загрузкой данных в хранилище, представляют собой отдельную категорию инструментов, известную как ETL . Кроме того, под эгидой ETL инструменты интеграции данных выполняют манипуляции с данными до того, как они будут помещены в хранилище. Эти инструменты работают между слоем необработанных данных и хранилищем.
Кроме того, под эгидой ETL инструменты интеграции данных выполняют манипуляции с данными до того, как они будут помещены в хранилище. Эти инструменты работают между слоем необработанных данных и хранилищем.
Когда данные загружаются в хранилище, их также можно преобразовать. Итак, на складе потребуется определенный функционал по очистке/стандартизации/размеризации. Эти и другие факторы будут определять сложность архитектуры. Мы рассмотрим архитектуру EDW с точки зрения растущих потребностей организации.
Одноуровневая архитектура
Учитывая, что интеграция данных хорошо настроена, мы можем выбрать наше хранилище данных. В большинстве случаев хранилище данных представляет собой реляционную базу данных с модулями, позволяющими хранить многомерные данные, или базу данных, которая может отделять некоторую информацию, относящуюся к предметной области, для облегчения доступа. В своей самой примитивной форме складское хозяйство может иметь только одноуровневую архитектуру .
Уровень отчетности напрямую связан со всей базой данных EDW
Одноуровневая архитектура для EDW означает, что у вас есть база данных, напрямую связанная с аналитическими интерфейсами, где конечный пользователь может делать запросы. Установка прямой связи между EDW и аналитическими инструментами сопряжена с рядом проблем:
- Традиционно вы можете считать свое хранилище хранилищем, начиная со 100 ГБ данных. Работа с ним напрямую может привести к запутанным результатам запроса, а также к низкой скорости обработки.
- Запрос данных прямо из DW может потребовать точного ввода, чтобы система могла отфильтровать ненужные данные. Что делает работу с инструментами презентации немного сложной.
- Ограниченная гибкость/аналитические возможности.
Кроме того, одноуровневая архитектура накладывает некоторые ограничения на сложность отчетов. Такой подход редко используется для крупномасштабных платформ данных из-за его медлительности и непредсказуемости. Для выполнения расширенных запросов данных хранилище может быть расширено низкоуровневыми экземплярами, упрощающими доступ к данным.
Для выполнения расширенных запросов данных хранилище может быть расширено низкоуровневыми экземплярами, упрощающими доступ к данным.
Двухуровневая архитектура (уровень киоска данных)
В двухуровневой архитектуре между пользовательским интерфейсом и EDW добавляется уровень киоска данных. Киоск данных — это низкоуровневый репозиторий, содержащий информацию, относящуюся к предметной области. Проще говоря, это еще одна база данных меньшего размера, которая дополняет EDW специальной информацией для ваших отделов продаж/операций, маркетинга и т. д.
В двухуровневой архитектуре EDW расширяется за счет киосков данных для предоставления данных, специфичных для предметной области
Для создания уровня киоска данных потребуются дополнительные ресурсы для установки оборудования и интеграции этих баз данных с остальной частью платформы данных . Но такой подход решает проблему с запросами: каждый отдел будет легче получать доступ к необходимым данным, потому что конкретная витрина будет содержать только информацию, относящуюся к предметной области. Кроме того, витрины данных ограничат доступ к данным для конечных пользователей, что сделает EDW более безопасным.
Кроме того, витрины данных ограничат доступ к данным для конечных пользователей, что сделает EDW более безопасным.
Трехуровневая архитектура (онлайн-аналитическая обработка)
Помимо уровня киоска данных предприятия также используют кубы онлайн-аналитической обработки (OLAP). Куб OLAP — это особый тип базы данных, который представляет данные из нескольких измерений. В то время как реляционные базы данных представляют данные только в двух измерениях (вспомните Excel или Google Sheets), OLAP позволяет вам компилировать данные в нескольких измерениях и перемещаться между измерениями.
Уровень кубов OLAP может получать информацию из распределенных витрин или непосредственно из EDW
Это довольно сложно объяснить словами, поэтому давайте посмотрим на этот удобный пример того, как может выглядеть куб.
OLAP-куб, демонстрирующий многомерные данные о продажах
Источник: oreilly.com
Итак, как видите, куб добавляет измерения к данным. Вы можете думать об этом как о нескольких таблицах Excel, объединенных друг с другом. Передняя часть куба представляет собой обычную двухмерную таблицу, где по вертикали указан регион (Африка, Азия и т. д.), а по горизонтали — цифры продаж и даты. Магия начинается, когда мы смотрим на верхнюю грань куба, где продажи сегментированы по маршрутам, а нижняя указывает период времени. Это известно как многомерные данные.
Вы можете думать об этом как о нескольких таблицах Excel, объединенных друг с другом. Передняя часть куба представляет собой обычную двухмерную таблицу, где по вертикали указан регион (Африка, Азия и т. д.), а по горизонтали — цифры продаж и даты. Магия начинается, когда мы смотрим на верхнюю грань куба, где продажи сегментированы по маршрутам, а нижняя указывает период времени. Это известно как многомерные данные.
Бизнес-ценность OLAP заключается в том, что он позволяет пользователям нарезать и нарезать данные для составления подробных отчетов. Поскольку кубы оптимизированы для работы с хранилищами, их можно использовать как напрямую с EDW для предоставления доступа ко всем корпоративным данным, так и конкретно с каждой витриной данных. С точки зрения внедрения, почти все поставщики хранилищ предлагают OLAP как услугу. Например, проверьте документацию Microsoft по их предложению OLAP.
На этом этапе мы обсудили высокоуровневый дизайн EDW, применяемый для нужд организации. Теперь мы собираемся углубиться в технические компоненты, которые может включать склад.
Теперь мы собираемся углубиться в технические компоненты, которые может включать склад.
Хранилище данных vs Data Lake vs Data Mart
Говоря об архитектуре хранения данных, нельзя не упомянуть такие варианты, как использование data mart или Data Lake вместо хранилища. Часто смешиваются, мы подробнее остановимся на определениях.
Сравнительная таблица хранилищ данных, озер данных и киосков данных
Хранилища данных в их традиционной форме предназначены для хранения структурированных данных, представленных в столбцах и строках, чтобы упростить запросы инструментов и конечные пользователи могут получить исчерпывающие результаты. Хранилища, в основном используемые для BI, обычно имеют размер от 100 ГБ до бесконечности. Они получают данные из большого количества внешних и внутренних источников, охватывающих разные сферы бизнеса. Что касается локальных хранилищ данных, то их настройка может занять месяцы.
Озера данных , с другой стороны, используются для хранения огромных объемов различной информации, включая структурированные, неструктурированные и полуструктурированные данные в необработанных форматах. Озера часто используются для машинного обучения, обработки больших данных или интеллектуального анализа данных. Последние пару лет для бизнес-аналитики используются озера данных: необработанные данные загружаются в озеро и преобразуются, что является альтернативой процессу ETL. Хотя у этого подхода есть свои плюсы и минусы, озера данных могут быть слишком беспорядочными для доступа к структурированным данным. Кстати, есть также новый гибридный вариант, который называется хранилище данных .
Озера часто используются для машинного обучения, обработки больших данных или интеллектуального анализа данных. Последние пару лет для бизнес-аналитики используются озера данных: необработанные данные загружаются в озеро и преобразуются, что является альтернативой процессу ETL. Хотя у этого подхода есть свои плюсы и минусы, озера данных могут быть слишком беспорядочными для доступа к структурированным данным. Кстати, есть также новый гибридный вариант, который называется хранилище данных .
Также может быть некоторая путаница со всем хранилищем данных и киоском данных.
Сравнение трех форм хранения данных. . Их также можно использовать в качестве альтернативы DW. Но из-за небольшого размера (обычно менее 100 ГБ) витрины данных вряд ли могут использоваться предприятиями. Чаще всего витрины данных используются для сегментации большого хранилища данных на более функциональные сегменты. Витрины данных получают информацию из относительно небольшого числа источников, обычно содержат структурированные данные и требуют меньше времени для настройки — обычно от 3 до 6 месяцев для локальных решений.
Технологии корпоративного хранилища данных
Понимание того, какие инструменты корпоративного хранилища данных существуют, поможет вам понять, что действительно соответствует требованиям вашей платформы данных. Планирование создания склада может занять годы планирования и тестирования из-за его масштаба в самой базовой форме.
Вас как владельца бизнеса может смутить количество используемых опций и технологий, поэтому очень важно проконсультироваться со специалистами в области складского хранения, ETL и BI. Пока специалисты могут помочь вам с технической стороной, определить бизнес-цель, поговорите с теми, кто будет использовать актуальные данные в своей работе.
В последнее время облачные/безоблачные технологии стали скорее стандартом для настройки технологий на уровне организации. На рынке вы найдете множество провайдеров, которые предлагают хранилище данных как услугу, а это означает, что вы будете использовать вычислительную мощность и пространство, предоставляемые облачными провайдерами. И в большинстве случаев такие провайдеры предлагают полностью управляемое масштабируемое хранилище как часть своих инструментов BI.
И в большинстве случаев такие провайдеры предлагают полностью управляемое масштабируемое хранилище как часть своих инструментов BI.
Вот несколько самых популярных облачных хранилищ данных.
Amazon Redshift — это облачное корпоративное хранилище данных, которое является частью платформы облачных вычислений Amazon. Это позволяет одновременно обрабатывать большие объемы данных в зависимости от потребностей компании. Будучи поставщиком общедоступного облака, Redshift более самоуправляемый, а это означает, что вам потребуются специалисты по данным для управления ресурсами и серверами. Что касается цены, вы можете начать с 0,25 доллара в час и увеличить масштаб до петабайт данных и тысяч одновременных пользователей.
Google BigQuery — это многооблачное хранилище данных, которое предоставляет возможности для одновременного запроса большого объема данных разными пользователями. Это бессерверная технология, что означает, что все управление осуществляется за вас, и она имеет отдельные уровни вычислений и хранения.