Функция Формат() в 1с 8 формирует требуемое представление значений простых типов
Формирует требуемое представление значений простых типов (Число, Дата и Булево)
Синтаксис
Функция Формат() имеет следующий синтаксис:
Строка Формат(Значение, [ФорматнаяСтрока])
А также альтернативный англоязычный синтаксис:
string Format(Value, [FormatString])
Параметры
Описание параметров функции Формат():
| Имя параметра | Тип | Описание |
|---|---|---|
| Значение | Число, Дата, Булево | Форматируемое значение. |
| ФорматнаяСтрока | Строка | Форматная строка определенной структуры, содержащая параметры форматирования, перечисленные через точку с запятой. Если параметры не указаны, то используется форматирование по умолчанию (как если бы происходило преобразование к строке). |
| Жирным шрифтом выделены обязательные параметры | ||
Возвращаемое значение
Описание
Функция Формат() формирует удобное для чтения представление значений простых типов (Число, Дата или Булево). Данная функция востребована при создании отчетов и при прочем визуальном отображении значений.
Данная функция востребована при создании отчетов и при прочем визуальном отображении значений.
Внимание! Для пустых значений (Число = 0 и Дата = 01.01.0001 00:00:00) функция возвращает пустую строку
Доступность
Тонкий клиент, веб-клиент, мобильный клиент, сервер, толстый клиент, внешнее соединение, мобильное приложение(клиент), мобильное приложение(сервер).
Пример использования
Пример кода с использованием функции Формат():
//форматирование чисел
Сообщить(Формат(123456.789, "ЧЦ=10; ЧДЦ=2"));
//Результат:
// 123 456,79
//форматирование дат
Сообщить(Формат('20190111153309', "ДЛФ=ДД"));
//Результат:
// 11 января 2019 г.
//форматирование логических выражений
Сообщить(Формат(Истина, "БЛ=Нет; БИ=Да"));
//Результат:
// Да
Читайте также:
Венера. Неукротимая планета -веб версия / Хабр
Добрый день. Я решил начать публиковать мою книгу про исследование Венеры в веб формате. Это первая часть из опубликованного (первая глава). Если все будет хорошо, то попробую выложить книгу целиком. Если же здесь решат, что это не формат, готов все удалить. Поехали!
Я решил начать публиковать мою книгу про исследование Венеры в веб формате. Это первая часть из опубликованного (первая глава). Если все будет хорошо, то попробую выложить книгу целиком. Если же здесь решат, что это не формат, готов все удалить. Поехали!
Несколько таинственных линий
За двадцатый век наши представления о Венере изменились кардинально. Благодаря совместным усилиям учёных многих стран с нашей ближайшей спутницы был сорван ореол неизвестности. История изучения Утренней Звезды напоминает хороший детектив.
У неё есть завязка, запутанный клубок тайн, кульминация и развязка. Свидетели, которые указывали в неверном направлении, и факты, которые изначально не воспринимались всерьёз. Что же послужило первым шагом к разгадке тайн нашей соседки?
Если посмотреть на картину в целом, современная история изучения Венеры – история, с которой началось понимание того, что же собой представляет планета, – началась в апреле 1932 года, в чистую и ясную ночь.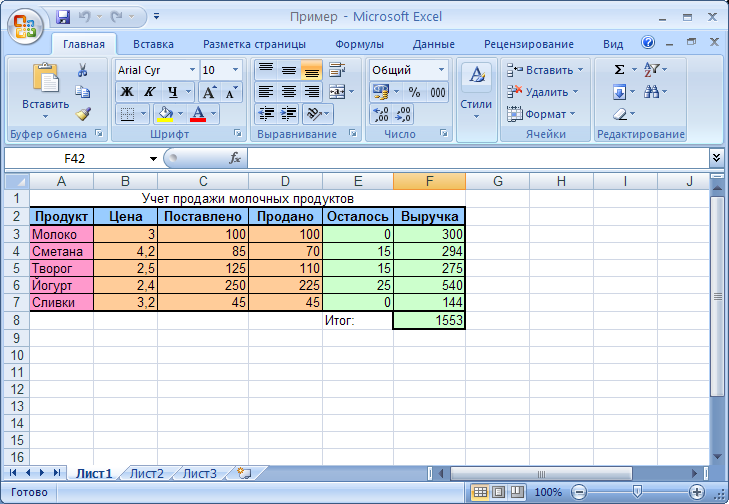 На юго-западе Калифорнии есть красивая горная цепь – Сан-Габриэль. Одной из её достопримечательностей является высокогорная астрономическая обсерватория Маунт-Вилсон. Она располагается на высоте около 1740 метров над уровнем моря. На момент описываемых событий на её основном телескопе был смонтирован новенький инфракрасный спектрограф, и сотрудники обсерватории проводили бессонные ночи, получая спектральные характеристики небесных тел. Очередной эксперимент, поставленный астрономами Теодором Данхэмом и Уолтером Адамсом, был направлен на поиск воды в атмосфере Венеры. Для увеличения точности решили ограничиться изучением небольшой полосы спектра в ближней инфракрасной области.
На юго-западе Калифорнии есть красивая горная цепь – Сан-Габриэль. Одной из её достопримечательностей является высокогорная астрономическая обсерватория Маунт-Вилсон. Она располагается на высоте около 1740 метров над уровнем моря. На момент описываемых событий на её основном телескопе был смонтирован новенький инфракрасный спектрограф, и сотрудники обсерватории проводили бессонные ночи, получая спектральные характеристики небесных тел. Очередной эксперимент, поставленный астрономами Теодором Данхэмом и Уолтером Адамсом, был направлен на поиск воды в атмосфере Венеры. Для увеличения точности решили ограничиться изучением небольшой полосы спектра в ближней инфракрасной области.
К тому моменту спектрометрическая теория была хорошо разработана и успешно применялась как на Земле, так и для изучения ярких астрономических объектов вроде Солнца. Более того, ещё в XIX веке удалось выявить полосы поглощения аммиака у Юпитера и других планет-гигантов. А вот в определении состава атмосфер ближайших к нам Венеры или Марса она пока не могла помочь.
После проявки пластинки следы поглощения воды найти не удалось, зато совершенно чётко проступили линии поглощения какого-то газа (рис. 21). Неизвестного газа. Подобных линий не было в справочниках. Никто не видел его в земных экспериментах, но этот газ явственно проступил в атмосфере Венеры.
К счастью, спектральный анализ основывается не только на сравнении полученных полос с уже известными. Он основан на фундаментальных свойствах вещества, и даже по расположению линий можно многое сказать о молекуле, вызвавшей поглощение. Неизвестный газ по своим характеристикам оказался похож на обычную углекислоту.
Возникал новый вопрос – почему этих линий не было видно в обычных экспериментах? Одним из вариантов ответа было то, что линии поглощения в этом диапазоне очень слабы и плохо видны при тех концентрациях СО2, с которыми обычно работают. Для проверки этой гипотезы в обсерватории Маунт-Вилсон изготовили герметичную трубу длиной 21 метр. Воздух из трубы был выкачан, и под давлением в неё стали закачивать двуокись углерода.
Вплоть до 10 атмосфер поглощения в изучаемом диапазоне не наблюдалось. При ещё большем увеличении давления появилась очень слабая и размытая линия, чрезвычайно близкая к линии, наблюдаемой в спектре Венеры. Гипотеза получила подтверждение – поглощение вызывал углекислый газ.

В 1940 году астроном Руперт Вильдт сделал ещё один шаг. Он рассмотрел окна поглощения и излучения СО2 и, зная коэффициент отражения Венеры по телескопическим наблюдениям, получил, что температура на поверхности может достигать 135° С. По сути, именно он и является автором теории парникового эффекта, но в те годы его статья прошла практически незамеченной. Вторую жизнь она получила в 1952 году, когда Джерард Койпер готовил к переизданию свою книгу «Атмосферы Земли и планет». Найдя эту статью, он заново пересмотрел расчёты и, используя более современные данные по Венере, вывел, что температура должна составить около 77° С.
В 1956 году было проведено первое наблюдения собственного радиоизлучения Венеры МакКлауфом, Майером и Слонейкером в диапазоне 3,15 см на 15-метровом радиотелескопе Морской исследовательской лаборатории США. Результат всех поразил. По полученному результату температура Венеры оказалась порядка 287° С для теневой стороны планеты, что заметно превышало любые другие расчёты и измерения. Решили изменить длину радиоволны на 9,4 см.
Решили изменить длину радиоволны на 9,4 см.
Было проведено два наблюдения и получены показатели – 157° С и 467° С соответственно. Следующий эксперимент, проведённый Гибсоном и МакИваном в январе 1958 года, на длине волны 8,6 мм дал температуру 137° С 160° С. Но когда в сентябре 1959 года Кузьмин и Саломонович решили провести подобный эксперимент на только что запущенном в строй советском 22-метровом радиотелескопе, для 8 мм получили заметно более «холодный» результат – 42° С.
Данные радиолокации пришлись весьма вовремя. К концу 50-х годов XX века спектроскопические методы изучения Венеры испытывали кризис. К тому моменту были известны несколько десятков линий поглощения в атмосфере Венере, но все они принадлежали углекислоте. Никаких других газов долго не удавалось выявить.
Сообщения об открытии новых газов в венерианской атмосфере порой вспыхивали, как искорки, но быстро перегорали. Например, советский астроном Козырев в 1954 году при изучении пепельного света Венеры получил большое число новых линий поглощения, американский астроном Ньюкирк подтвердил его данные. Часть линий Козырев отождествил с линиями сильно ионизированного азота, и если бы это оказалось правдой, то стало бы первым открытием азота в атмосфере другой планеты. Потом часть линий пытались объяснить ионизированным кислородом. В результате выяснилось, что это была ионизированная углекислота.
Часть линий Козырев отождествил с линиями сильно ионизированного азота, и если бы это оказалось правдой, то стало бы первым открытием азота в атмосфере другой планеты. Потом часть линий пытались объяснить ионизированным кислородом. В результате выяснилось, что это была ионизированная углекислота.
Самое неприятное, что никак не удавалось уверенно доказать наличие в атмосфере Венеры воды. Все наблюдения, направленные на это, показывали либо отрицательный результат, либо концентрацию, которую могли дать и следы влаги в земной атмосфере. Причём её нельзя было выявить даже косвенными методами. Например, под воздействием ультрафиолетового излучения Солнца вода и углекислота могли образовать формальдегид, но выявить формальдегид в атмосфере Венеры тоже не удалось. Или такой факт: высокое содержание углекислоты указывало на то, что в атмосфере Венеры нарушено так называемое равновесие по Юри. В условиях Земли углекислый газ активно связывается мировым океаном, преобразуясь в осадочные породы.
С этой ситуацией нужно было что-то делать. Скажем, попробовать так поставить эксперимент, чтобы вода из земной атмосферы не могла влиять на результат. В 1959 году была предпринята весьма занятная попытка. В 50-х годах научно-исследовательский центр ВМС США проводил обширную программу по запуску пилотируемых стратостатов (рис. 22). Изначально в полётах производилось изучение атмосферы Земли, но группа учёных из Университета Джона Хопкинса предложила проект получения инфракрасных спектров Марса и Венеры – для поиска на них воды. Предложение было принято, и началась работа. На стратостат установили специально модифицированный телескоп со спектрографом. Предварительное наведение должен был осуществлять человек, затем наведение телескопа на планету контролировалось специальной автоматической следящей системой. Первая попытка состоялась в 1958 году, её целью был Марс. Из-за неисправной оболочки стратостата полёт пришлось отложить, и возможность изучить Марс в этом году была потеряна. В 1959 году пришла очередь Венеры.
Предварительное наведение должен был осуществлять человек, затем наведение телескопа на планету контролировалось специальной автоматической следящей системой. Первая попытка состоялась в 1958 году, её целью был Марс. Из-за неисправной оболочки стратостата полёт пришлось отложить, и возможность изучить Марс в этом году была потеряна. В 1959 году пришла очередь Венеры.
В конце ноября 1959 года стратостат с пилотом Россом и наблюдателем Муром достиг высоты 24 км. На этой высоте количество водяных паров в атмосфере Земли не превышало 0,1% от общего значения. Росс и Мур направили телескоп на цель и смогли получить несколько инфракрасных спектров Венеры. Задача оказалась непростой. Колебания гондолы порой были так резки, что приходилось полностью прекращать работу. По мнению постановщиков эксперимента, даже то, что удалось получить хоть какие-то результаты, было само по себе удивительно. Но результат имелся: получилось выявить несколько линий поглощения воды. К сожалению, разброс значений оказался слишком велик, что ставило под большие сомнения полученные данные.
Также в 1959 году произошло ещё одно знаменательное событие, благодаря которому появился ещё один кусочек в венерианской мозаике: так называемое покрытие (затмение) Венерой одной из ярчайших звёзд на небе – Регула (Альфа Льва). Такие затмения происходят крайне редко. В XX веке на тот момент было зафиксировано всего три подобных события. Покрытие Венерой Регула было рассчитано заранее, и крупные обсерватории готовились к нему. Большой удачей явилось то, что во многих пунктах наблюдения была хорошая погода. Как известно, когда звезда подходит к самому краю планетного диска, её свет начинает ослабляться. При этом ослабление вызывается не рассеиванием, а рефракцией света. Проходя через атмосферу Венеры, свет отклоняется от прямой траектории. Зная физические основы рефракции, можно очень точно вычислить параметры верхней атмосферы планеты. Правда, есть одно «но»: эти данные могут дать только некий коэффициент (абсолютную плотность атмосферы), связанный как с температурой, так и с молекулярным весом газа, вызывающим рефракцию. И только точно зная состав атмосферы, можно без особого труда вычислить её температуру и плотность на той высоте, на которой происходило покрытие.
И только точно зная состав атмосферы, можно без особого труда вычислить её температуру и плотность на той высоте, на которой происходило покрытие.
В качестве основного газа атмосферы Венеры был принят азот; взяв его молярную массу, получили распределение плотности и температуры в верхних слоях. Эти данные вошли в первые модели атмосферы Венеры.
Автоматические межпланетные аппараты могли при правильном использовании дать ответы на многие загадки. Для оценки текущих знаний и анализа экспериментов Совет по исследованию космического пространства Национальной Академии наук США 24 июля 1960 года решил провести специальную конференцию по обсуждению параметров атмосфер Марса и Венеры. Именно к этим планетам в первую очередь предстояло отправить земные аппараты. Ввиду важности вопроса также было решено провести в Пасадене дополнительную конференцию в конце декабря 1960 года – начале февраля 1961 года. Эта конференция, на которой присутствовал весь цвет американских планетологов, интересна тем, что по докладам, прозвучавшим на ней, хорошо видны представления о планетах в начале космической эры. По Марсу особых сомнений не возникало, чего нельзя сказать о Венере. Конференция наглядно выявила: непротиворечивой теории, описывающей структуру венерианской атмосферы, нет! Каждый планетолог отстаивал свою версию, и ни одна гипотеза не была свободна от внутренних проблем. Среди научных предположений порой были весьма занятные. В частности, хотелось бы упомянуть об очень экстравагантной теории доктора Хойла. По ней Венера была покрыта океаном, в котором вода находилась под громадным слоем нефти.
По Марсу особых сомнений не возникало, чего нельзя сказать о Венере. Конференция наглядно выявила: непротиворечивой теории, описывающей структуру венерианской атмосферы, нет! Каждый планетолог отстаивал свою версию, и ни одна гипотеза не была свободна от внутренних проблем. Среди научных предположений порой были весьма занятные. В частности, хотелось бы упомянуть об очень экстравагантной теории доктора Хойла. По ней Венера была покрыта океаном, в котором вода находилась под громадным слоем нефти.
И эта гипотеза тоже была хорошо проработана и неплохо объясняла часть имеющихся данных.
Основными на тот момент можно считать три теории структуры атмосферы Венеры. Все они были разработаны для объяснения высокой радиояркостной температуры, полученной радиоастрономами. Здесь нужно чётко понимать, о чём шла речь. До той поры имелось всего восемь точек на графике радиоизлучения Венеры в зависимости от длины волны. Точность этих измерений, к сожалению, была низка из-за собственных шумов приёмника, эксперименты проводились на пределе чувствительности приборов. Но они в целом показывали, что излучение Венеры на разных частотах радиоизлучения различно.
Но они в целом показывали, что излучение Венеры на разных частотах радиоизлучения различно.
В миллиметровом диапазоне температура была относительно невелика, градусов 50–70 по Цельсию, но могла существенно превышать значение 300° С в сантиметровом диапазоне. Нужно было понять, откуда идёт это излучение. Для объяснения вырисовывающейся картины были разработаны два типа гипотез: горячего низа и холодного верха и, соответственно, горячего верха и холодного низа (рис. 23).
Под горячим низом подразумевалась поверхность планеты. И именно она, по теории первого типа, была раскалена до чудовищных температур; холодное излучение шло с более высоких слоёв атмосферы – например, от облаков. Классическим представителем первого типа была парниковая гипотеза. Её весьма тщательно проработал Карл Саган. Углекислый газ сам по себе, казалось бы, не мог вызвать такой нагрев, это выходило из расчётов Вильдта и Койпера. Карл Саган тщательно повторил расчёты и показал, что поглощение только в углекислоте никак не могло объяснить экспериментальные данные. Но если добавить в атмосферу Венеры хоть немного водяных паров – всё менялось. Водяной пар очень хороший парниковый газ. Он мог задержать излучение в инфракрасном диапазоне, что и вызывало сильный нагрев поверхности.
Но если добавить в атмосферу Венеры хоть немного водяных паров – всё менялось. Водяной пар очень хороший парниковый газ. Он мог задержать излучение в инфракрасном диапазоне, что и вызывало сильный нагрев поверхности.
Парниковая гипотеза рисовала весьма скучный мир. Температура на поверхности – более 300° С, давление могло достигать нескольких атмосфер. На Венере должно быть сухо, безветренно, темно и жарко. Солнце можно было бы наблюдать только в виде красноватого диска. Надежд на венерианскую жизнь парниковая гипотеза почти не оставляла. На начало 1960-х годов именно она была проработана лучше любой другой, хотя и у неё имелось несколько недостатков.
Например, тот факт, что с водой на Венере были проблемы. Эрнст Эпик раскритиковал парниковую гипотезу и предложил свою. Он назвал её эолосферной, в честь Эола – древнегреческого бога ветра. Дело в том, что поляриметрическая кривая облаков была похожа куда больше на кривую пыли, нежели воды. Согласно этой гипотезе, облака, которые все наблюдали, были не облаками, а грандиозной пылевой бурей, охватившей всю планету. Она закрывала поверхность Венеры гигантской мантией, а за счёт трения песчинок о поверхность повышалась температура.
Она закрывала поверхность Венеры гигантской мантией, а за счёт трения песчинок о поверхность повышалась температура.
Впрочем, при расчёте данных по давлению и температуре на поверхности Венеры они оказывались похожи на результаты, получаемые при парниковой гипотезе. Так же, как и в парниковой гипотезе, получалось, что температура на поверхности – более 300° С, давление до 4-х атмосфер. Сухо, но очень пыльно и ветрено. Увы, обе эти теории не оставляли надежд на наличие на Венере жизни.
Впрочем, была ещё теория «горячего верха» – ионосферная. По ней более низкая температура принадлежала поверхности, а высокая – вызывалась излучением ионосферы планеты. В этом случае на Венере действительно была бы вполне сносная температура – около 27-ми градусов Цельсия. А вполне возможно, и жизнь. Во многом эта гипотеза основывалось на более раннем предположении, построенном на теории возникновения планет в Солнечной системе.
Венера представлялась облачным двойником Земли, находящимся в той ситуации, которая сложилась на нашей планете миллионы лет назад, в каменноугольный период. Тёплый и влажный климат с изобилием влаги, пасмурным небом и органическим миром, похожим на тот, что был в конце палеозойской эры. Там, думали романтически настроенные учёные, растут тропические сады и гуляют предки динозавров. Затерянный мир, который ждёт своих профессоров Челленджеров. Ведь это была целая неизведанная планета! Писатели и художники изображали будоражащий воображение мир во всем полноцветии красок.
Тёплый и влажный климат с изобилием влаги, пасмурным небом и органическим миром, похожим на тот, что был в конце палеозойской эры. Там, думали романтически настроенные учёные, растут тропические сады и гуляют предки динозавров. Затерянный мир, который ждёт своих профессоров Челленджеров. Ведь это была целая неизведанная планета! Писатели и художники изображали будоражащий воображение мир во всем полноцветии красок.
В 1961 году в СССР вышел художественный фильм «Планета Бурь» режиссёра Павла Клушанцева (рис. 24). Клушанцев был очень успешным режиссером-документалистом и отличался дотошным научным подходом. Это был его единственный художественный фильм по одноимённой повести Александра Казанцева. В начале фильма он честно предупреждал зрителей: «Научные сведения о планете Венера скудны и противоречивы. Лишь фантазия способна заглянуть в неоткрытый мир. Он может оказаться и не таким, как в нашем фильме. Но мы верим в грядущий подвиг советских людей, которые воочию увидят планету бурь».
В кинокартине зрители увидели инопланетные пейзажи, подводные путешествия, агрессивную флору и фауну. Они путешествовали и спасались вместе с героями от вулкана… И не было тогда на всей нашей планете человека, который мог уверенно доказать, что это не так. Три предположения. Три разных мира. Ни одна гипотеза не могла вместить в себя все имеющиеся данные. Каждая из них хорошо объясняла одни факты и полностью опровергалась другими. Нужны были более детальные данные, чтобы понять, какая из гипотез верна.
Это фрагмент моей книги «Венера. Неукротимая планета». Также сейчас идет сбор на мою новую книгу. Его можно поддержать здесь.
5 трендов цифровой трансформации в 2021 году
2020 год выдался незабываемым. Во всех смыслах. Столкнувшись с беспрецедентным вызовом в виде пандемии, бизнес был поставлен перед выбором: адаптируйся или уходи. И именно технологии стояли во главе глобальных изменений, помогая преодолевать трудности и прогнозировать возможные сценарии развития в условиях неопределенности.
Согласно данным McKinsey, бизнес обгоняет прогнозы по оцифровке взаимодействия с клиентами на 3-4 года, по доле цифровых продуктов – на 7 лет. В Cisco, формируя технологические тренды, обратили особое внимание на темпы развития сетей связи и признали, что уже в нынешнем году могут быть достигнуты показатели, которые предполагались к 2024.
Давление на бизнес очевидно. Чтобы оставаться конкурентоспособными, нужно меняться, и вполне логичный шаг – начать цифровую трансформацию. Пандемия ускорила этот процесс.
Сегодняшние реалии – это фундаментальное переосмысление и преобразование бизнеса, изменение подходов к управлению/маркетингу/корпоративной культуре благодаря внедрению технологий. Главная задача таких изменений – повысить эффективность компании и ее жизнеспособность на длительный срок.
Важность цифровой трансформации уже не требует лишних доказательств, а из наиболее значимых трендов, которые обязательно стоит учитывать при формировании стратегий, можно выделить следующие пять.
1. RPA
Robotic process automation или роботизированная автоматизация на слуху уже не один год, но особое развитие технология получила в последние 2-3 года. Банковский и финансовый сектора, телеком, медицина, промышленность, логистика, маркетинг – список сфер, где применяются роботы, растет с каждым днем. Еще в 2018 Deloitte прогнозировали, что в течение 5 лет стоит ожидать почти всеобщей роботизации бизнес-процессов, а в Everest Group отмечают, что повышенный интерес к рынку RPA будет активно расти до конца 2022 года.
Светлана Анисимова, генеральный директор UiPath в России и СНГ
Используя возможности ИИ и роботизации для получения максимального эффекта, инструменты RPA позволяют уменьшить количество повторяющихся операций и высвободить рабочее время сотрудников для выполнения творческих или стратегически важных задач. Кроме того, технология исключает влияние человеческого фактора и вызванных им ошибок.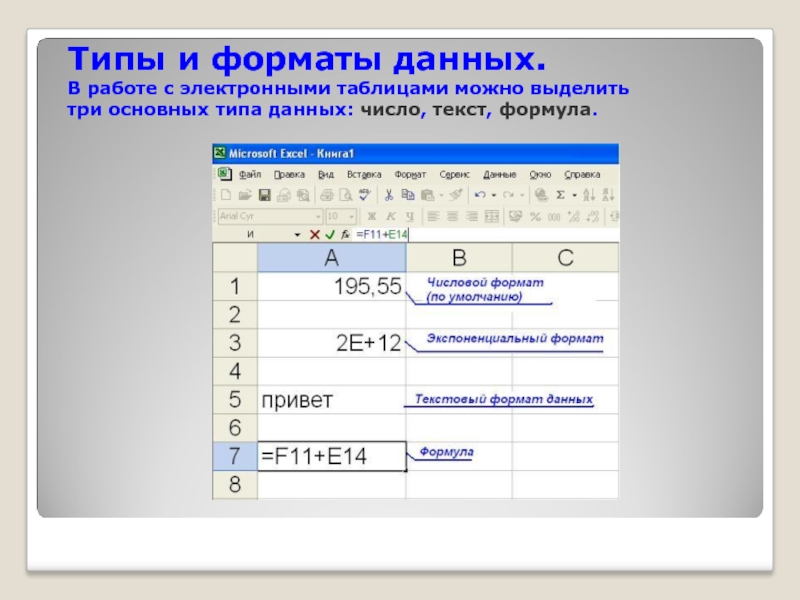 Такие технологии связывают разрозненные автоматизированные процессы компании «поверх» уже существующих IT-систем, создавая единую цифровую экосистему. Это помогает значительно оптимизировать внутренние процессы, сократить издержки и повысить общую прибыль.
Такие технологии связывают разрозненные автоматизированные процессы компании «поверх» уже существующих IT-систем, создавая единую цифровую экосистему. Это помогает значительно оптимизировать внутренние процессы, сократить издержки и повысить общую прибыль.
Сергей Путятинский, заместитель председателя правления МКБ
Роботизация бизнес-процессов позволяет сократить риск выгорания сотрудников, вызванного монотонным ручным трудом, повысить скорость выполнения самих процессов и контроль над ними.
Не зная броду, не лезьте в воду – еще никогда русский фольклор не был так близок к миру технологий. Многие компании выбирают для роботизации операции неизученных процессов, реальное протекание которых не соответствует регламентированному. Допустим, некий процесс должен длиться 5 часов, а по факту выполняется 7,5 часов. Все это будет влиять на производительность RPA, снижая степень положительного влияния технологии на бизнес и рентабельность инвестиций.
В качестве решения подобной проблемы может выступать процессная аналитика (process mining), которая на основе данных из внутренних журналов визуализирует процесс «as is», выявляя все «узкие места». Понимая действительный расклад, различные тонкости и нюансы, можно определить наиболее подходящие для роботизации операции, получая максимальный эффект от внедрения RPA.
Еще одна интересная технология, которая набирает популярность – task mining, акцент которой смещен на выявление и определение многократно повторяющихся рутинных операций. Ее результат – обнаружение самых трудоемких и «тяжелых» шагов, которые могут быть автоматизированы и нормированы. Напоминает process mining, но тут есть принципиальное отличие: если в процессной аналитике источником данных выступают логи информационных систем организации, то в task mining – агенты мониторинга.
2. Оптимизация собственных процессов
Мер «со стороны» недостаточно. В рамках внедрения инициатив по цифровой трансформации необходимо понимать, что изменения будут касаться не только каких-то технических и технологических аспектов, но и общих управленческих.
Денис Реймер, советник по продуктам b2b «ЭР-Телеком Холдинг»
Чтобы оставаться конкурентными на рынке, компаниям придется наращивать свои собственные цифровые компетенции для удовлетворения ожиданий клиентов и оптимизировать сложившиеся внутренние бизнес-процессы. Сегодня выигрывает тот, кто сможет быстрее реагировать на происходящие на рынке изменения. А для этого, с одной стороны, необходимо автоматическое принятие решений, с другой – новые источники данных и знаний для формирования таких решений. Поэтому из технологий на первый план выходит искусственный интеллект, задача которого высвободить человеческие ресурсы и время, затрачиваемое в бизнес-процессах компаний. ИИ в 2021 году должен стать полноценным сотрудником в компаниях, забирая на себя существенную часть рутинных операций.
Олег Громов, генеральный директор IT-продакшна Extyl
Одним из трендов мы видим смещение фокуса внимания с внешней цифровизации для клиента на внутреннюю – оптимизацию процессов компании.
Поясню: в 2020 мы повсюду слышали о том, как цифровизируется клиентский сервис. Например, автосалоны впервые стали делать онлайн-продажи через мобильные приложения. Клиентские сайты тоже давно соответствуют всем канонам UX-дизайна и выверены до мелочей. Но неоптимизированные внутренние процессы по-прежнему сжигают рабочее время сотрудников и деньги собственников. Я уверен, что в тех же автосалонах еще есть менеджеры, задачи которых – заполнять заявки на тест-драйв и оформлять покупку. Каждый раз они тратят по 15 минут на форму, которая постоянно зависает. И делают это много раз в день. А еще им приходится дублировать отчетность в нескольких системах, потому что они не интегрированы друг с другом.
3. Customer journey
В классическом понимании customer journey map – это путь, который проходит клиент с момента возникновения потребности в том или ином товаре/услуге до момента покупки. В проектах по цифровой трансформации CJM призваны оценить уровень проникновения технологий на каждом этапе.
Как яркий образец: Netflix, Amazon и множество других организаций изменили конкурентную среду, установив новые стандарты взаимодействия с клиентами за счет использования сложных аналитических данных о клиентах. Эти компании получают точную и максимально полную карту, полностью интегрированную с основной деятельностью, что становится очевидным, почему они постоянно находятся на вершине списка лидеров.
Денис Бурлаков, генеральный директор финтех-компании RBK.money
Уверен, что в 2021 году нас ждут новые интересные цифровые разработки в направлении customer journey, клиентского пути и поведения. Компании, которые смогут предложить клиенту максимум пользы в несколько кликов и по привлекательной цене, получат большое конкурентное преимущество.
В 2020 году мы увидели бум экосистем: Яндекс, Mail.ru, Сбер, Тинькофф стали развиваться по этому пути, собирать комплекс сервисов из разных сфер для своих клиентов. Конкурировать в плане продуктов сейчас уже довольно сложно – уникальных идей на рынке мало, когда появляется что-то действительно новое, оно очень быстро копируется.
Поэтому в текущем году мы увидим дальнейшее развитие экосистемных приложений в формате SuperApp и активную работу с уже имеющейся клиентской базой. Это будут программы лояльности самого разного вида – в сервисах В2В и В2С, внутри экосистем и внутри отдельно развивающихся компаний. Потому что работа со своей аудиторией практически всегда требует меньше затрат, чем привлечение новой, тем более в условиях жесткой конкуренции. И в этом смысле управление customer journey станет очень ценным, и именно здесь нас ждут новые цифровые решения и подходы.
4. Облачные архитектуры
Константин Чумаченко, генеральный директор NGENIX
Облачные сервисы (IaaS/PaaS) благодаря своим неограниченным возможностям в масштабировании и подписной модели упраздняют необходимость содержать и обслуживать собственную IT-инфраструктуру — это важно для быстрого роста бизнеса.
Популярность облачных сервисов продолжает расти быстрыми скачками, ведь именно подобные технологии помогли многим компаниям справиться с последствиями пандемии и остаться на рынке. По данным IDC, корпоративные расходы на облака выросли почти на 35% в сравнении с 2019 годом. Как сообщил Леонид Аникин, директор по развитию Mail.ru Цифровые технологии, в 2020 году спрос на PaaS на платформе Mail.ru Cloud Solutions увеличился в 3,4 раза.
Александр Иванников, директор по развитию mClouds
Именно из-за трансформации рабочей среды сильно вырос спрос на облачные инструменты. Они позволяют быстро и гибко обеспечить работу персонала практически с любых устройств, будь то домашний ПК или рабочее место в офисе. При этом нет необходимости в дополнительных инвестициях в собственную IT-инфраструктуру.
Популярность облачных решений привела к тому, что компании стали переходить от однопользовательских частных облаков к мультиоблачным средам. То есть к использованию более одной облачной службы – общедоступной или частной – от нескольких поставщиков.
Наличие мультиоблачной среды помогает повысить отказоустойчивость и производительность бизнеса, поскольку активы компании равномерно распределены по разным облачным средам и в случае сбоя одного облака производственный процесс не остановится. К тому же мультиоблака помогают предприятиям избежать зависимости от одного поставщика, чтобы получить максимальную выгоду от каждой услуги.
Однако существует тонкий момент: растет сложность управления инфраструктурой. Здесь организации должны искать решения для управления облаком и автоматизации для управления своими многочисленными облачными средами. Это также поможет удовлетворить требования к гибкости и изучить новые модели.
5. LowCode
LowCode – технология, созданная несколько десятилетий назад, но получившая «второе дыхание» в условиях пандемии. Для быстрой разработки и интеграции приложений, автоматизации рабочих процессов бизнес обратился именно к LowCode.
Константин Чумаченко, генеральный директор NGENIX
«Топливом» для успешной цифровой трансформации станут платформенные технологии, которые позволяют сократить или исключить разработку и дают возможность создавать IT-продукты людям, сфокусированным на потребностях пользователей. Low-code/No-code-платформы и инструменты, доступные пользователям без технического бэкграунда, помогут ускорить выпуск новых продуктов.
Дмитрий Голубовский, генеральный директор TagesJump
Фактически LowCode – это графический интерфейс, в котором без труда может разобраться человек с базовыми навыками работы с данными. Это позволит часть рутинной работы переложить на плечи системных аналитиков и освободить хардкорных разработчиков для того, чтобы они могли заниматься более сложными интеграциями.
Согласно отчету OutSystems 2019/2020, 41% компаний используют ту или иную форму LowCode, и это число увеличивается с каждым годом, что вполне естественно в условиях цифровой трансформации.
Лично я вижу большие перспективы для успешной реализации проектов Digital Transformation в прогнозной аналитике и цифровых двойниках (digital twin), которые помогут моделировать различные ситуации и превентивно ликвидировать остановку рабочих процессов. Однако прежде, чем сделать выбор в пользу любой из технологий, нужно понимать, что цифровая трансформация выходит за рамки программного обеспечения и методик. Необходимо ставить конкретные цели, чтобы определить цифровую стратегию. Затем – сконцентрироваться на изменении мышления сотрудников. Именно они помогут вам в достижении целей цифровой трансформации бизнеса.
Читайте также:
Яндекс.Практикум — сервис онлайн-образования от Яндекса
Привет всем читающим отзыв 🙂 Начну издалека. Программированием я интересовался давно, но никогда на нем не зацикливался. Пробовал разные вещи, интерес пропадал, пробовал что-то другое. Однажды даже сделал игру на Unity (C#). Но ни разу это не перешло во что-то более-менее серьезное.
И одновременно с этим я начал осознавать что попал в, как я ее назвал, «ловушку работы чуть выше среднего». Отличная зарплата, отличный коллектив и руководство, но абсолютно никаких перспектив. Года шли, цены и потребности постепенно росли, а зарплата из отличной постепенно начала превращаться в «ну в целом очень хорошо», потом в просто «хорошо»…
А потом я наткнулся на рекламу Яндекс.Практикума в инстаграме 🙂 Что называется, реклама попала в цель. Учитывая предысторию и мои размышления, посомневавшись неделю я решился и оплатил курс.
Что я могу сказать по курсу. Мне очень понравилась подача материала. Он идет последовательно, все объяснено очень доступно, и почти ничего лишнего. Требуются ли какие-то знания чтобы его пройти? Вряд ли… Если вы хотя бы играете в игры на компьютере, проблем у вас возникнуть не должно. Кроме того, если возникают сложности, всегда можно написать вопрос в чат или наставнику в личку.
Коллектив студентов подобрался очень разный, это было даже забавно. Кто-то имел опыт программирования, а кто-то, по-моему, даже компьютер включал не каждый месяц. Тем не менее все старались и помогали друг другу.
В конце курса был создан чат с помощью в трудоустройстве. Хоть мне это и почти не пригодилось, но с информацией из того чата я ознакомился, узнал много полезного.
Были ли минусы? Были. Их немного и я бы не назвал их критичными.
— Местами материал мне казался легковат (но при этом я видел людей в чате которым было очень сложно, так что видимо со сложностью все же все в порядке).
— Кое-какие материалы все же были лишними. Например, в тренажере был довольно большой блок материала по шрифтам. Em,rem, и всякое такое. Я, подумав что так и надо, целый день переделывал размеры шрифтов с пикселей на «em», а ревьюер просто завернул работу, сказав что не может проверить верстку, из-за шрифтов все перекошено. Потом целый день переделывал на пиксели обратно. И я такой был не один, я видел вопрос в чате об этом 🙂
-Слишком много внимания вебпаку. Это отличный инструмент, мощный и полезный, но от нас требовалась его доскональная настройка. Мое мнение таково — если я приду в компанию, там будет свой билд. Для личного использования можно найти что-то попроще. Или найти предустановленные настройки.
В целом, вебпак небольшая проблема — хоть и было сложно, через боль справившись с настройкой, я в дальнейшем использовал свой билд почти без изменений и это было действительно удобно.
-Мелкие баги в тренажере. Многих учеников они возмущали, но мы же были всего третьим потоком. Бывало такое что предложение от кого-то из учеников реализовывалось буквально в течение недели, это круто.
Итак, вердикт.
Стоит ли учиться? Да, определенно. Вероятность изменить профессию очень высока.
Будет ли интересно? О да, думаю вам понравится. И верстать и программировать на JS лично мне очень понравилось (программировать больше).
9 месяцев назад я даже представить не мог что создам свой новостной мини-сервис, с бэкендом, авторизацией, сохранением новостей и личным кабинетом.
Будет ли сложно? О да 🙂 В кое-каких моментах у меня был прям ступор и я всерьез раздумывал об академ-отпуске (спойлер — JS на классах и вебпак).
Но ничего непреодолимого. В блоке по JS нас разделили на более мелкие чаты, где было более плотное взаимодействие с наставниками — опытными программистами, которые всегда помогали и подсказывали в чем проблема.
Отдельное спасибо наставнику по JS Владиславу и комьюнити-менеджеру Варе 🙂 Всегда отвечали быстро и помогали.
echo 123.4567 | awk ‘{printf «% .3f \ n», $ 1}’ 123,457 echo 123.4567 | awk ‘{printf «% .1f \ n», $ 1}’ 123,5 echo 123.4567 | awk ‘{printf «% 2.1f \ n», $ 1}’ 123,5 echo 123.4567 | awk ‘{printf «% 5.1f \ n», $ 1}’ 123,5 echo 123.4567 | awk ‘{printf «% 8.1f \ n», $ 1}’ 123,5 echo 123.4567 | awk ‘{printf «% 8.6f \ n», $ 1}’ 123,456700 echo 123.4567 | awk ‘{printf «% .2e \ n», $ 1}’ 1.23e + 02 echo 123.4567 | awk ‘{printf «% .4e \ n», $ 1}’ 1.2346e + 02 echo 123.4567 55.2 | awk ‘{printf «% .3f», $ 1; распечатать $ 2} ‘ 123.45755,2 echo 123.4567 55.2 | awk ‘{printf «% .3f», $ 1; распечатать $ 2} ‘ 123,457 55,2 echo 123.4567 55.2 | awk ‘{printf «% -20.7f% d \ n», $ 1, $ 2}’ 123.4567000 55 echo 123.4567 55.2 | awk ‘{printf «% 20.7f% d \ n», $ 1, $ 2} 123.4567000 55 Вот список букв управления форматом: `c ‘Это печатает число как символ ASCII. Таким образом, `printf»% c «, 65 ‘выводит букву` A’. Вывод для строкового значения — это первый символ строки. `d ‘Выводит десятичное целое число.`i ‘Это также выводит десятичное целое число. `e ‘Печатает число в научном (экспоненциальном) представлении. Например, printf «% 4.3e», 1950 выводит «1.950e + 03», всего четыре значащих цифры, три из которых следуют за десятичной точкой. «4.3» — это модификаторы, обсуждаемые ниже. `f ‘Печатает число в нотации с плавающей запятой. `g ‘Это печатает число либо в экспоненциальной нотации, либо в нотации с плавающей запятой, в зависимости от того, что использует меньше символов.`o ‘Выводит восьмеричное целое число без знака. `s ‘Это печатает строку. `x ‘Выводит шестнадцатеричное целое число без знака. `X ‘Выводит шестнадцатеричное целое число без знака. Однако для значений с 10 по 15 он использует буквы от «A» до «F» вместо «a» до «f». `% ‘На самом деле это не буква управления форматом, но она имеет значение при использовании после`%’: последовательность `%% ‘выводит один`%’. Он не требует аргументов. ######################################### Модификаторы для форматов printf Спецификация формата также может включать модификаторы, которые могут контролировать, сколько значения элемента печатается и сколько места оно получает.Модификаторы располагаются между `% ‘и буквой управления форматом. Вот возможные модификаторы в том порядке, в котором они могут появляться: `- ‘ Знак минус, используемый перед модификатором ширины, указывает на выравнивание аргумента по левому краю в пределах указанной ширины. Обычно аргумент печатается с выравниванием по правому краю указанной ширины. Таким образом, printf «% -4s», «foo» печатает `foo ‘. `ширина ‘ Это число, представляющее желаемую ширину поля. Если вставить любое число между знаком «%» и символом управления форматом, поле будет расширено до этой ширины.По умолчанию это можно сделать с помощью пробелов слева. Например, printf «% 4s», «foo» печатает `foo ‘. Значение ширины — это минимальная ширина, а не максимальная. Если для значения элемента требуется больше символов ширины, оно может быть сколь угодно широким. Таким образом, printf «% 4s», «foobar» печатает `foobar ‘. Знак минус перед шириной приводит к заполнению вывода пробелами справа, а не слева. .prec Это число, указывающее точность, используемую при печати.Это определяет количество цифр, которое вы хотите напечатать справа от десятичной точки. Для строки он определяет максимальное количество символов из строки, которое должно быть напечатано. Примеры использования printf Вот как использовать printf для создания выровненной таблицы: awk ‘{printf «% -10s% s \ n», $ 1, $ 2}’ BBS-список печатает имена досок объявлений ($ 1) файла `BBS-list ‘в виде строки из 10 символов с выравниванием по левому краю. Затем он также печатает телефонные номера (2 доллара США) в строке. Это создает выровненную таблицу из двух столбцов с именами и телефонными номерами: трубкозуб 555-5553 альпо-нетто 555-3412 barfly 555-7685 укусы 555-1675 камелот 555-0542 ядро 555-2912 fooey 555-1234 стопа 555-6699 macfoo 555-6480 sdace 555-3430 sabafoo 555-2127 Вы обратили внимание, что мы не указали, что номера телефонов должны быть напечатаны как числа? Их нужно было печатать строками, потому что числа разделены тире.Это тире было бы интерпретировано как знак минус, если бы мы попытались напечатать телефонные номера как числа. Это привело бы к довольно запутанным результатам. Мы не указали ширину для телефонных номеров, потому что они последние в своих строках. Нам не нужно ставить после них пробелы. Мы могли бы сделать нашу таблицу еще красивее, добавив заголовки в верхнюю часть столбцов. Для этого используйте шаблон BEGIN (см. Раздел Специальные шаблоны BEGIN и END). для принудительной печати заголовка только один раз, в начале awk-программы: awk ‘BEGIN {print «Name Number» Распечатать «—- ——» } {printf «% -10s% s \ n», $ 1, $ 2} ‘BBS-список Вы заметили, что в приведенном выше примере мы смешали операторы print и printf? Мы могли бы использовать только операторы printf для получения тех же результатов: awk ‘BEGIN {printf «% -10s% s \ n», «Имя», «Число» printf «% -10s% s \ n», «—-«, «——«} {printf «% -10s% s \ n», $ 1, $ 2} ‘BBS-список Путем вывода заголовка каждого столбца с той же спецификацией формата, которая используется для элементов столбца, мы убедились, что заголовки выровнены так же, как и столбцы.Тот факт, что одна и та же спецификация формата используется три раза, можно подчеркнуть, сохранив ее в переменной, например: awk ‘BEGIN {format = «% -10s% s \ n» формат printf, «Имя», «Число» формат printf, «—-«, «——«} {printf format, $ 1, $ 2} ‘BBS-список Используйте оператор printf, чтобы выровнять заголовки и данные таблицы f awk ‘BEGIN {print «Name Number» Распечатать «—- ——» } {printf «% -10s% s \ n», $ 1, $ 2} ‘BBS-список Мы смешали операторы print и printf в приведенном выше примере? Мы могли бы использовать только операторы printf для получения тех же результатов: awk ‘BEGIN {printf «% -10s% s \ n», «Имя», «Число» printf «% -10s% s \ n», «—-«, «——«} {printf «% -10s% s \ n», $ 1, $ 2} ‘BBS-список Путем вывода заголовка каждого столбца с той же спецификацией формата, которая используется для элементов столбца, мы убедились, что заголовки выровнены так же, как и столбцы.Тот факт, что одна и та же спецификация формата используется три раза, можно подчеркнуть, сохранив ее в переменной, например: awk ‘BEGIN {format = «% -10s% s \ n» формат printf, «Имя», «Число» формат printf, «—-«, «——«} {printf format, $ 1, $ 2} ‘BBS-список
Устранение неполадок с номерами страниц — Word 2010
- Счетчик страниц начинается с самой первой страницы вашего ETDR.
- Титульная страница до содержания: Нумерация страниц начинается с буквы «i» римскими цифрами в нижнем регистре (i, ii, iii) и НЕ отображается.
- Содержание страницы до главы 1: Римские цифры в нижнем регистре продолжают отсчет и отображаются ЕСТЬ.
- Начиная с главы 1: Нумерация страниц начинается с «1» и отображается арабскими цифрами (1, 2, 3) в остальной части документа.
- Разрывы разделов используются для управления нумерацией страниц. При включенном Word Показать / Скрыть они выглядят следующим образом: ====== Разрыв раздела (следующая страница) ======
Эта система подсчета страниц и отображения номеров страниц встроена в шаблон и не требует внимания.Во время работы с документом непреднамеренное удаление или изменение компонентов нумерации страниц может вызвать некоторые проблемы.
Если номера страниц отображаются неправильно, выберите необходимое решение и выполните следующие действия.
Исправить номера страниц, начинающиеся с «1» в тексте документа
Если вы видите, что номера страниц возвращаются к «1» в теле документа, скорее всего, это происходит при разрыве раздела. Выполните следующие действия, чтобы устранить проблему:
- Щелкните в любом месте страницы, где нумерация начинается с «1.”Если вы не находитесь в режиме верхнего и нижнего колонтитула, выберите вкладку Вставить , нажмите Нижний колонтитул и нажмите Изменить нижний колонтитул .
- Поместите курсор в нижний колонтитул; НЕ выбирайте номер страницы. Щелкните Номер страницы , а затем Форматировать номера страниц .
- В окне Формат щелкните Продолжить с предыдущего раздела , а затем щелкните ОК .
Повторяйте эти шаги при каждом разрыве раздела или когда номера страниц возвращаются к «1».
Исправить номера страниц от начала до главы 1
Выполните следующие шаги A, B, C и D по порядку. Или используйте форму запроса ETDR, чтобы получить помощь от консультанта ETDR (требуется eID / пароль).
Шаг A. Проверьте наличие обязательных разрывов разделов (в содержании, глава 1).
- Откройте документ в Word. Нажмите кнопку Показать / Скрыть (она выглядит как черный символ абзаца), чтобы включить скрытые символы форматирования.
- Непосредственно перед страницей «Содержание» проверьте наличие разрыва раздела. Если присутствует разрыв раздела, перейдите к шагу 4.
- Если разрыв раздела отсутствует, поместите курсор прямо перед буквой «T» в «Таблице». Щелкните вкладку Макет страницы . В разделе Абзац выберите Разрывы . В разделе Разрывы раздела выберите Следующая страница .
- Непосредственно перед началом главы 1 проверьте, нет ли разрыва раздела.Если разрыв раздела присутствует, перейдите к шагу B ниже.
- Если разрыв раздела отсутствует, поместите курсор сразу после «Глава 1 -» и перед первым словом в заголовке. Щелкните вкладку Макет страницы . В разделе Абзац выберите Разрывы . В разделе Разрывы раздела выберите Следующая страница .
Шаг Б. Исправьте номера страниц с титульного листа до перед Оглавлением.
- Поместите курсор в любое место на титульной странице.
- На вкладке Insert выберите Footer и нажмите Edit Footer .
- Если вы видите номер страницы в нижнем колонтитуле (внизу страницы), выберите номер и нажмите клавишу Удалить .
- Поместив курсор в нижний колонтитул, щелкните Номер страницы , а затем Форматировать номера страниц .
- В окне Формат номера страницы установите формат номера на i, ii, iii,… В разделе Номер страницы выберите Начать с и установите номер на « i .Нажмите ОК .
Шаг C. Исправьте номера страниц из содержания до главы 1.
- Прокрутите до первой страницы вашего оглавления. Если вы не находитесь в режиме верхнего и нижнего колонтитула, выберите вкладку Вставить , нажмите Нижний колонтитул и нажмите Изменить нижний колонтитул .
- Если «Как в предыдущем» или «Ссылка на предыдущий» отображается чуть выше нижнего колонтитула, удалите его, нажав Ссылка на Предыдущий код в разделе Navigation вкладки Design .
- Убедитесь, что вкладка Design все еще выбрана. Поместив курсор в нижний колонтитул, щелкните Номер страницы , а затем Форматировать номера страниц .
- В окне Формат номера страницы установите для формата номера значение i, ii, iii,… В разделе Нумерация страниц выберите Продолжить из предыдущего раздела . Нажмите ОК .
- Если номер страницы не отображается, вставьте его: щелкните Номер страницы, , затем Внизу страницы , затем Обычный номер 2 (по центру) или Обычный номер 3 (по правому краю).
Шаг D. Исправьте номера страниц из главы 1.
- Прокрутите до первой страницы главы 1. Если вы не находитесь в режиме верхнего и нижнего колонтитула, выберите вкладку Вставить , нажмите Нижний колонтитул и нажмите Изменить нижний колонтитул .
- Если «Как в предыдущем» или «Ссылка на предыдущий» отображается чуть выше нижнего колонтитула, удалите его, нажав Ссылка на Предыдущий код в разделе Navigation вкладки Design .
- Поместив курсор в нижний колонтитул, щелкните Номер страницы , а затем Форматировать номера страниц .
- В окне Формат номера страницы установите для формата номера значение 1,2,3, … В разделе Нумерация страниц выберите Начать с и установите номер « 1 ». Нажмите ОК .
- Если номер страницы не отображается, вставьте его: щелкните Номер страницы, , затем Внизу страницы , затем Обычный номер 2 (по центру) или Обычный номер 3 (по правому краю).
- Когда все будет готово, на вкладке Design щелкните Закрыть верхний и нижний колонтитулы .
sprintf — Браузер Perldoc
Возвращает строку, отформатированную в соответствии с обычными соглашениями printf функции библиотеки C sprintf . См. Более подробную информацию ниже и см. Sprintf (3) или printf (3) в вашей системе для объяснения общих принципов.
Perl выполняет собственное форматирование sprintf : он эмулирует функцию sprintf (3) языка C, но не использует ее, за исключением чисел с плавающей запятой, и даже в этом случае разрешены только стандартные модификаторы.Поэтому нестандартные расширения в вашем локальном sprintf (3) недоступны в Perl.
В отличие от printf , sprintf не делает то, что вы, вероятно, имеете в виду, когда вы передаете ему массив в качестве первого аргумента. Массиву предоставляется скалярный контекст, и вместо использования 0-го элемента массива в качестве формата Perl будет использовать количество элементов в массиве в качестве формата, что почти никогда не бывает полезно.
Наконец, для обратной (и мы подразумеваем «обратную») совместимости Perl разрешает эти ненужные, но широко поддерживаемые преобразования:
Обратите внимание, что количество цифр экспоненты в экспоненциальной нотации, полученной с помощью , % g и % G для чисел с модулем показателя степени меньше 100 зависит от системы: оно может быть три или меньше (при необходимости дополняется нулями).Другими словами, 1,23 умноженное на десять до 99-го числа может быть либо «1,23e99», либо «1,23e099». Точно так же для % a и % A : экспонента или шестнадцатеричные цифры могут плавать: особенно вариант конфигурации Perl «длинные удвоения» может вызвать сюрпризы.
Между % и буквой формата вы можете указать несколько дополнительных атрибутов, управляющих интерпретацией формата. По порядку это:
Явный индекс параметра формата, например 2 $ .По умолчанию sprintf отформатирует следующий неиспользуемый аргумент в списке, но это позволяет вам выносить аргументы не по порядку:
printf '% 2 $ d% 1 $ d', 12, 34; # отпечатков "34 12"
printf '% 3 $ d% d% 1 $ d', 1, 2, 3; # отпечатки "3 1 1" один или несколько из:
пробел префикс неотрицательное число с пробелом
+ префикс неотрицательного числа со знаком плюс
- выравнивание по левому краю внутри поля
0 используйте нули, а не пробелы, для выравнивания по правому краю
# обеспечить ведущий "0" для любого восьмеричного числа,
префикс ненулевого шестнадцатеричного с помощью "0x" или "0X",
префикс ненулевого двоичного кода с "0b" или "0B" Например:
printf '<% d>', 12; # выводит "<12>"
printf '<% d>', 0; # выводит "<0>"
printf '<% d>', -12; # выводит "<-12>"
printf '<% + d>', 12; # выводит "<+12>"
printf '<% + d>', 0; # выводит "<+0>"
printf '<% + d>', -12; # выводит "<-12>"
printf '<% 6s>', 12; # выводит "<12>"
printf '<% - 6s>', 12; # выводит "<12>"
printf '<% 06s>', 12; # выводит "<000012>"
printf '<% # o>', 12; # выводит "<014>"
printf '<% # x>', 12; # выводит "<0xc>"
printf '<% # X>', 12; # выводит "<0XC>"
printf '<% # b>', 12; # выводит "<0b1100>"
printf '<% # B>', 12; # выводит "<0B1100>" Когда в качестве флагов одновременно используются пробел и знак плюса, пробел игнорируется.
printf '<% + d>', 12; # выводит "<+12>"
printf '<% + d>', 12; # выводит "<+12>" Когда в преобразовании% o задаются флаг # и точность, точность увеличивается, если это необходимо для ведущего «0».
printf '<% #. 5o>', 012; # выводит "<00012>"
printf '<% #. 5o>', 012345; # выводит "<012345>"
printf '<% #. 0o>', 0; # выводит "<0>" Этот флаг указывает Perl интерпретировать предоставленную строку как вектор целых чисел, по одному на каждый символ в строке.V; # Версия Perl
Поставьте звездочку * перед v , чтобы заменить строку, используемую для разделения чисел:
printf "адрес% * vX \ n", ":", $ addr; # IPv6-адрес
printf "биты:% 0 * v8b \ n", "", $ bits; # random bitstring Вы также можете явно указать номер аргумента для использования в строке соединения, используя что-то вроде * 2 $ v ; например:
printf '% * 4 $ vX% * 4 $ vX% * 4 $ vX', # 3 адреса IPv6
@addr [1..3], ":"; Аргументы обычно форматируются так, чтобы иметь ширину, необходимую для отображения данного значения. Вы можете переопределить ширину, поместив здесь число, или получить ширину из следующего аргумента (с * ) или из указанного аргумента (например, с * 2 $ ):
printf "<% s>", "а"; # выводит ""
printf "<% 6s>", "а"; # выводит ""
printf "<% * s>", 6, "а"; # выводит ""
printf '<% * 2 $ s>', «а», 6; # выводит ""
printf "<% 2s>", "long"; # выводит "" (не усекает) Если ширина поля, полученная через * , отрицательна, она имеет тот же эффект, что и флаг - : выравнивание по левому краю.
Вы можете указать точность (для числовых преобразований) или максимальную ширину (для преобразований строк), указав . , за которым следует число. Для форматов с плавающей запятой, за исключением g и G , это указывает, сколько разрядов справа от десятичной точки отображать (по умолчанию 6). Например:
# эти примеры могут изменяться в зависимости от системы
printf '<% f>', 1; # выводит "<1.000000> "
printf '<%. 1f>', 1; # выводит "<1.0>"
printf '<%. 0f>', 1; # выводит "<1>"
printf '<% e>', 10; # выводит "<1.000000e + 01>"
printf '<%. 1e>', 10; # выводит "<1.0e + 01>" Для «g» и «G» это определяет максимальное количество отображаемых значащих цифр; например:
# Эти примеры могут изменяться в зависимости от системы.
printf '<% g>', 1; # выводит "<1>"
printf '<%. 10g>', 1; # выводит "<1>"
printf '<% g>', 100; # выводит "<100>"
printf '<%.1g> ', 100; # выводит "<1e + 02>"
printf '<%. 2g>', 100.01; # выводит "<1e + 02>"
printf '<%. 5g>', 100.01; # выводит "<100.01>"
printf '<%. 4g>', 100.01; # выводит "<100>"
printf '<%. 1g>', 0,0111; # выводит "<0,01>"
printf '<%. 2g>', 0,0111; # выводит "<0.011>"
printf '<%. 3g>', 0,0111; # выводит "<0.0111>" Для целочисленных преобразований указание точности подразумевает, что выходные данные самого числа должны быть дополнены нулями до этой ширины, где флаг 0 игнорируется:
printf '<%.6d> ', 1; # выводит "<000001>"
printf '<% +. 6d>', 1; # выводит "<+000001>"
printf '<% - 10.6d>', 1; # выводит "<000001>"
printf '<% 10.6d>', 1; # выводит "<000001>"
printf '<% 010.6d>', 1; # выводит "<000001>"
printf '<% + 10.6d>', 1; # выводит "<+000001>"
printf '<%. 6x>', 1; # выводит "<000001>"
printf '<% #. 6x>', 1; # выводит "<0x000001>"
printf '<% - 10.6x>', 1; # выводит "<000001>"
printf '<% 10.6x> ', 1; # выводит "<000001>"
printf '<% 010.6x>', 1; # выводит "<000001>"
printf '<% # 10.6x>', 1; # выводит "<0x000001>" Для преобразования строк при указании точности строка обрезается до указанной ширины:
printf '<%. 5s>', "усеченный"; # выводит ""
printf '<% 10.5s>', "усеченный"; # выводит "" Вы также можете получить точность из следующего аргумента, используя .* , или из указанного аргумента (например, с . * 2 $ ):
printf '<%. 6x>', 1; # выводит "<000001>"
printf '<%. * x>', 6, 1; # выводит "<000001>"
printf '<%. * 2 $ x>', 1, 6; # выводит "<000001>"
printf '<% 6. * 2 $ x>', 1, 4; # выводит "<0001>" Если точность, полученная через * , отрицательна, она считается не имеющей точности вообще.
printf '<%. * S>', 7, «строка»; # выводит "<строка>"
printf '<%.* s> ', 3, «строка»; # выводит ""
printf '<%. * s>', 0, «строка»; # вывод "<>"
printf '<%. * s>', -1, «строка»; # выводит "<строка>"
printf '<%. * d>', 1, 0; # выводит "<0>"
printf '<%. * d>', 0, 0; # вывод "<>"
printf '<%. * d>', -1, 0; # выводит "<0>" Для числовых преобразований вы можете указать размер для интерпретации числа, используя l , h , V , q , L или ll .Для целочисленных преобразований ( duox X bi DUO ) обычно предполагается, что числа соответствуют целочисленному размеру по умолчанию на вашей платформе (обычно 32 или 64 бита), но вы можете переопределить это, чтобы использовать вместо него один из стандартных типов C, как поддерживается компилятором, используемым для сборки Perl:
hh интерпретировать целое число как тип C "char" или "unsigned"
char "на Perl 5.14 или новее
h интерпретировать целое число как тип C "короткий" или
"короткое беззнаковое"
j интерпретировать целое число как тип C "intmax_t" на Perl
5.14 или новее; и до Perl 5.30, только с
компилятор C99 (непереносимый)
Я интерпретирую целое число как тип C "длинный" или
"беззнаковый длинный"
q, L или ll интерпретируют целое число как тип C "long long",
"unsigned long long" или "quad" (обычно
64-битные целые числа)
t интерпретировать целое число как тип C "ptrdiff_t" на Perl
5.14 или новее
z интерпретирует целое число как тип C "size_t" или
"ssize_t" на Perl 5.14 или новее По состоянию на 5.14, ни один из них не вызывает исключения, если они не поддерживаются на вашей платформе. Однако, если предупреждения включены, предупреждение класса предупреждений printf выдается при неподдерживаемом флаге преобразования. Если вы предпочитаете исключение, сделайте следующее:
использовать предупреждения FATAL => "printf"; Если вы хотите узнать о зависимости версий до запуска программы, поместите что-то вроде этого вверху:
используйте 5,014; # для модификаторов hh / j / t / z / printf Вы можете узнать, поддерживает ли ваш Perl квадроциклы, через Config:
использовать Config;
if ($ Config {use64bitint} eq "определить"
|| $ Config {longsize}> = 8) {
print "Хорошие четверки! \ n";
} Для преобразований с плавающей запятой ( efg EFG ) обычно предполагается, что числа являются размером с плавающей запятой по умолчанию на вашей платформе (double или long double), но вы можете принудительно использовать «long double» с помощью q , L или ll , если ваша платформа поддерживает их.Вы можете узнать, поддерживает ли ваш Perl длинные дубли, через Config:
использовать Config;
напечатайте "длинные удвоения \ n", если $ Config {d_longdbl} eq "define"; Вы можете узнать, считает ли Perl «long double» размером с плавающей запятой по умолчанию для использования на вашей платформе через Config:
использовать Config;
if ($ Config {uselongdouble} eq "define") {
print "по умолчанию длинные двойники \ n";
} Также может быть, что длинные дублёры и дублёры одно и то же:
использовать Config;
($ Config {doublesize} == $ Config {longdblsize}) &&
print "двойные - длинные двойные \ n"; Спецификатор размера V не влияет на код Perl, но поддерживается для совместимости с кодом XS.Это означает «использовать стандартный размер для целого числа Perl или числа с плавающей запятой», который является значением по умолчанию.
Обычно sprintf принимает следующий неиспользуемый аргумент в качестве значения для форматирования для каждой спецификации формата. Если в спецификации формата используется * , чтобы требовать дополнительных аргументов, они потребляются из списка аргументов в том порядке, в котором они появляются в спецификации формата перед значением для форматирования.Если аргумент указан явным индексом, это не влияет на нормальный порядок аргументов, даже если явно указанный индекс был бы следующим аргументом.
Итак:
printf "<% *. * S>", $ a, $ b, $ c; использует $ a для ширины, $ b для точности и $ c в качестве значения для форматирования; в то время как:
printf '<% * 1 $. * S>', $ a, $ b; будет использовать $ a для ширины и точности и $ b в качестве значения для форматирования.
Вот еще несколько примеров; имейте в виду, что при использовании явного индекса $ может потребоваться экранирование:
printf "% 2 \ $ d% d \ n", 12, 34; # напечатает "34 12 \ n"
printf "% 2 \ $ d% d% d \ n", 12, 34; # напечатает "34 12 34 \ n"
printf "% 3 \ $ d% d% d \ n", 12, 34, 56; # напечатает "56 12 34 \ n"
printf "% 2 \ $ * 3 \ $ d% d \ n", 12, 34, 3; # напечатает "34 12 \ n"
printf "% * 1 \ $. * f \ n", 4, 5, 10; # напечатает "5.0000 \ n" Если использует локаль (включая use locale ': not_characters' ) и был вызван POSIX :: setlocale , на символ, используемый для десятичного разделителя в форматированных числах с плавающей запятой, влияет LC_NUMERIC локаль.См. Perllocale и POSIX.
FAQ: ввод ведущих нулей в вывод
Есть ли способ поместить в вывод ведущие нули?
| Заголовок | Ввод ведущих нулей в вывод | |
| Автор | Гэри Петерсен, RRC Inc. |
Вы можете отформатировать переменные, которые будут сообщаться с начальными нулями, поставив ноль после знака процента в формате % f ; видеть [D] формат .Для пример,
. формат ssn% 09.0f
заполнит левую часть девятизначного числа нулями.
Начальные нули видны на экране, когда вы список переменная и когда вы аутфил данные.
Многие пользователи Stata также хотят преобразовывать числовые данные в строки и сохранять ведущие нули, что подходит для номеров социального страхования США, времени, даты и т. д. Это преобразование может быть выполнено с помощью строка () функция с возможностью выбора формата.
Ниже мы показываем пример; переменная ‘x’ — это числовое значение, а не строка.
. список
+ ----- +
| х |
| ----- |
1. | 55 |
2. | 23 |
3. | 81 |
4. | 144 |
5. | 174 |
| ----- |
6. | 92 |
7. | 84 |
8. | 178 |
9. | 11 |
10. | 135 |
+ ----- +
. gen str3 y = строка (x)
. список
+ ----------- +
| х у |
| ----------- |
1.| 55 55 |
2. | 23 23 |
3. | 81 81 |
4. | 144 144 |
5. | 174 174 |
| ----------- |
6. | 92 92 |
7. | 84 84 |
8. | 178 178 |
9. | 11 11 |
10. | 135 135 |
+ ----------- +
. gen str3 z = строка (x, "% 03.0f")
. список
+ ----------------- +
| x y z |
| ----------------- |
1. | 55 55 055 |
2. | 23 23 023 |
3.| 81 81 081 |
4. | 144 144 144 |
5. | 174 174 174 |
| ----------------- |
6. | 92 92 092 |
7. | 84 84 084 |
8. | 178 178 178 |
9. | 11 11 011 |
10. | 135 135 135 |
+ ----------------- +
Как видите, переменная y была создана и не имела начального нуля. Добавив параметр формата в функцию string () , мы смогли управлять форматом преобразованных данных.
% (Оператор форматирования строк) — Справочник по Python (The Right Way) 0.1 документация
Экспоненциальный формат с плавающей запятой. Альтернативная форма приводит к тому, что результат всегда содержит десятичную точку, даже если за ней нет цифр.
Точность определяет количество цифр после десятичной точки и по умолчанию — 6.
Десятичный формат с плавающей запятой. Альтернативная форма приводит к тому, что результат всегда содержит десятичную точку, даже если за ней нет цифр.
Точность определяет количество цифр после десятичной точки и по умолчанию — 6.
Формат с плавающей запятой.Использует экспоненциальный формат, если показатель меньше -4 или не меньше точности, в противном случае — десятичный формат. Альтернативная форма приводит к тому, что результат всегда содержит десятичную точку, а конечные нули не удаляются, как в противном случае.
Точность определяет количество значащих цифр до и после десятичной точки и по умолчанию — 6.
String (преобразует любой объект Python с помощью repr ()).
Точность определяет максимальное количество используемых символов.
String (преобразует любой объект Python с помощью str ()).
Если предоставленный объект или формат является строкой Unicode, результирующая строка также будет Unicode.
Точность определяет максимальное количество используемых символов.
Преобразование чисел в текст (Microsoft Excel)
Обратите внимание: Эта статья написана для пользователей следующих версий Microsoft Excel: 97, 2000, 2002 и 2003.Если вы используете более позднюю версию (Excel 2007 или новее), , этот совет может вам не подойти . Чтобы ознакомиться с версией этого совета, написанного специально для более поздних версий Excel, щелкните здесь: Преобразование чисел в текст.
Джоселин спросила, есть ли способ легко преобразовать числа в их текстовые эквиваленты.Например, чтобы преобразовать числовое значение 6789 в текстовые цифры «6789.»
Есть несколько способов решения этой проблемы. Один из способов — просто указать Excel, что ячейки должны обрабатываться как текст. Откройте диалоговое окно «Формат ячеек», а затем на вкладке «Число» убедитесь, что выбран текст. Все выбранные ячейки затем форматируются, как если бы они были текстом, и перемещаются в левую часть своих ячеек (если у вас не указан другой формат выравнивания).
Применимость этого решения, однако, зависит от версии Excel, которую вы используете.В некоторых версиях это будет работать, как описано здесь, но в других — нет. Однако вы можете попробовать еще одну вещь:
- Выберите ячейки, которые нужно преобразовать.
- Выберите «Ячейки» в меню «Формат». Excel отображает диалоговое окно «Формат ячеек». (Чтобы отобразить диалоговое окно в Excel 2007, откройте вкладку «Главная» на ленте, нажмите «Форматировать» в группе «Ячейки», а затем выберите «Форматировать ячейки».)
- Убедитесь, что выбрана вкладка Число. (См. Рисунок 1.)
- В списке категорий форматирования выберите Текст.
- Щелкните ОК.
- Нажмите Ctrl + C . Это скопирует ячейки, выбранные на шаге 1.
- Выберите «Специальная вставка» в меню «Правка». Excel отображает диалоговое окно Специальная вставка.
- Выберите переключатель «Значения».
- Щелкните ОК.
Рисунок 1. Вкладка «Число» диалогового окна «Формат ячеек».
Еще вы можете использовать функцию рабочего листа ТЕКСТ.Допустим, у вас есть значение 6789 в ячейке A7. В ячейку B7 вы можете поместить следующее:
= ТЕКСТ (A1; "#, ## 0,00")
Такое использование ТЕКСТА приводит к текстовым цифрам с разделителем тысяч в нужном месте и двумя цифрами справа от десятичной точки, как в «6,789.00». Вы можете указать в качестве второго параметра для TEXT любое желаемое форматирование. Если вы хотите преобразовать число в текст без какого-либо специального форматирования, вы можете использовать следующее:
= ТЕКСТ (A1; «0»)
Результат — текстовый эквивалент целочисленного значения.
ExcelTips — ваш источник экономичного обучения Microsoft Excel. Этот совет (2680) применим к Microsoft Excel 97, 2000, 2002 и 2003. Вы можете найти версию этого совета для ленточного интерфейса Excel (Excel 2007 и более поздних версий) здесь: Преобразование чисел в текст .
Автор биографии
Аллен Вятт
Аллен Вятт — всемирно признанный автор, автор более чем 50 научно-популярных книг и многочисленных журнальных статей.Он является президентом Sharon Parq Associates, компании, предоставляющей компьютерные и издательские услуги. Узнать больше о Allen …
Объединение и центрирование недоступно
Что делать, если вы пытаетесь отформатировать рабочий лист, только чтобы узнать, что один из необходимых вам инструментов не …
Открой для себя большеЯрлык для полноэкранного режима чтения
Хотите избавиться от практически всего на экране, кроме документа? Вот как легко получить максимальную отдачу от того, что вы видите.
Открой для себя большеПереход к разделу
Один из способов навигации по документу — переход от раздела к разделу. Вот традиционный способ быстро получить …
Открой для себя большеТипы данных с плавающей запятой
Типы данных с плавающей запятойДокумент управления двоичным интерфейсом> Двоичный формат Trimble> Типы данных с плавающей запятой
Типы данных с плавающей запятой
Типы данных с плавающей запятой хранятся в форматах IEEE SINGLE и DOUBLE точности.Оба формата имеют поле знаковых битов, поле экспоненты и поле дроби. Поля представляют числа с плавающей запятой следующим образом:
Число с плавающей запятой = <знак> 1. <поле дроби> x 2 (<поле показателя> — смещение)
Поле битов знака
Поле знакового бита — это самый старший бит числа с плавающей запятой. Бит знака равен 0 для положительных чисел и 1 для отрицательных чисел.
Поле дроби
Поле дроби содержит дробную часть нормализованного числа. Нормализованные числа больше или равны 1 и меньше 2. Поскольку все нормализованные числа имеют форму 1.XXXXXXXX, 1 становится неявной и не сохраняется в памяти. Биты в поле дроби — это биты справа от двоичной точки, и они представляют собой отрицательные степени двойки.
Например:
0,011 (двоичный) = 2 -2 + 2 -3 = 0,25 + 0,125 = 0,375
Поле экспоненты
Поле экспоненты содержит смещенную экспоненту; то есть постоянное смещение вычитается из числа в поле экспоненты, чтобы получить фактическую экспоненту. (Смещение делает возможными отрицательные показатели.)
Если и поле экспоненты, и поле дроби равны нулю, число с плавающей запятой равно нулю.
NaN
NaN (не число) — это специальное значение, которое используется, когда результат операции не определен. Например, деление числа на ноль дает NaN.
Тип данных FLOAT
Тип данных FLOAT хранится в формате одинарной точности IEEE длиной 32 бита. Самый старший бит — это знаковый бит, следующие 8 старших битов — это поле экспоненты, а оставшиеся 23 бита — это поле дроби.Смещение экспоненты составляет 127. Диапазон значений формата с одинарной точностью составляет от 1,18 × 10 –38 до 3,4 × 10 38 . Число с плавающей запятой имеет точность до 6 десятичных цифр.
ДВОЙНОЙ
Тип данных DOUBLE хранится в формате двойной точности IEEE, длина которого составляет 64 бита. Самый старший бит — это знаковый бит, следующие 11 старших битов — это поле экспоненты, а оставшиеся 52 бита — это дробное поле.